
매번 Depth 관련 논문을 리뷰하다가, 이번엔 Image Translation 관련 논문을 가지고 왔습니다.
본 논문은 2017 CVPR에 게재된 논문이고, pix2pix라는 이름으로도 잘 알려져 있는 논문입니다.
매번 Depth 논문을 가져오다가 뜬금없이 Image Tranlation 논문은 웬말이냐~ 라고 하실 수도 있습니다.
이번 KCCV를 통해 다양한 분야의 논문을 읽고자 하는 생각이 커졌고,
연구실 세미나에서 pix2pix 라는 논문을 예전부터 접했었는데, 이에 대해서 좀 더 알아보고 싶다는 생각이 들었기 때문입니다. 또 추가적으로 현재 신정민 연구원과 진행하고 있는 Image Generation 관련 논문 작업과도 관련이 있지 않을까?? 라는 생각에 한번 읽어보게 되었습니다. 그럼 리뷰 시작하겠습니다.
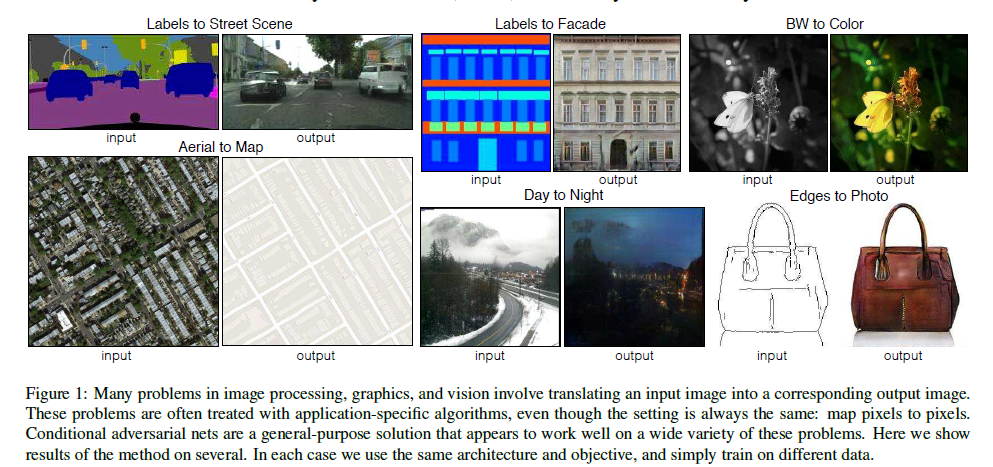
위에 있는 Figure 1 그림을 보시면 Image Translation이 어떤 task인지 직관적으로 이해하실 수 있으실겁니다.
Input image로부터 Output image를 translation 하는 것인데,
우리가 흔히 아는 번역기의 image 버전이라고 생각하시면 됩니다.
Introduction
전통적인 Image Translation task에서는 pixel by pixel 형식으로 output image를 예측 했었습니다.
그리고 우리가 알다시피 통상적으로 CNN은 다양한 image prediction 문제에서 공통적으로 사용되고,
여기서 CNN 은 우리가 설정한 loss function을 최소화하는 방향으로 학습을 진행합니다.
그래서 Image Translation task에서는 loss function으로 pixels 끼리의 Euclidean distance를 적용할 수 있고,
이를 활용 해 왔습니다.
하지만 loss function으로 gt와 predicted pixel의 Euclidean distance를 사용하게 된다면,
모델이 loss값을 단순하게 줄이기 위해 평균화 된 pixel로 학습을 하려고 하게 됩니다.
이러한 이유 때문에 생성된 output image도 되게 blurry 한 결과를 보인다고 합니다.
그리하여 이러한 문제점을 해결하기 위해, 진짜와 같은 이미지를 만드려면
목적에 맞는 loss function을 자동적으로 배우는 network가 필요하다고 주장합니다.
그리고 이는 GAN 에 의해서 완벽히 수행된다고 합니다.
GAN은 생성한 output image가 real인지 fake인지 분류하는 loss를 학습함과 동시에,
이러한 loss를 최소화하기 위해 output image를 생성하는 생성모델을 training 합니다.
본 논문에서는 conditional GAN을 사용합니다.
기존의 GAN이 noise vector 를 input으로 받는데에 반해,
conditional GAN은 noise vector와 함께 observed image 를 추가로 사용합니다.
이를 통해서 conditional GAN은 일종의 condition(조건) 을 추가해 줌으로써
무작위 영상이 아닌 원하는 영상을 출력할 수 있게 됩니다.
출력 결과는 아래 Figure1을 참고하시면 됩니다.
Method

conditional GAN을 통한 Image Translation은
observed image(x) 와 random noise vector(z) 로 부터 output image (y) 로의 mapping을 학습하는 생성 모델입니다.
수식적으로는 ( G : {x, z}→y ) 로도 표현됩니다.
GAN에는 생성자인 Generator와 판별자인 Discriminator 가 있는데, 각각의 역할은 아래와 같습니다.
- 생성자(Generator) G는 적대적으로 train되는 판별자(discriminator) D에 의해 “real” image로 구별되지 않도록 output을 생성하는 방향으로 training됩니다.
- 판별자(discriminator) D는 생성자(Generator) G의 “fake” 를 최대한 잘 감지하는 방향으로 training 됩니다.
(fake와 real을 classification 하는 방식으로 training 됩니다.)
Objective
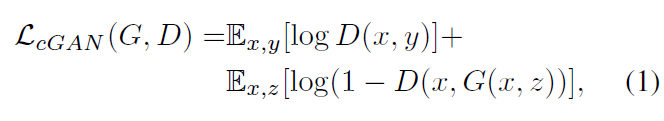
기존의 conditional GAN의 목적함수는 위와 같습니다.
이 식은 위의 Figure 2 와 매칭이 됩니다.
여기서 Discriminator D의 출력값은 0~1 사이의 확률값을 가집니다.
0이면 fake고 1이면 real 이라고 생각하시면 됩니다.
해당 식의 앞쪽 term은 Discriminator가 real한 image를 잘 판별하도록 하는 역할을 하고,
뒤쪽 term은 Generator가 Discriminator를 잘 속이도록 하는 역할을 합니다.
지금까지의 내용을 살짝이나마 정리 해 보면 Generator는 Discriminator를 잘 속이도록 학습이 되는것이고,
Discriminator는 Generator가 만들어낸 image의 real&fake를 최대한 잘 감지하는 방식으로 학습이 되는 것입니다.
하지만 여기서 살짝의 문제가 발생하게 되는데,
위의 objective function을 가지고 학습을 진행하게 되면 Generator는 Discriminator를 속이는 데에만 치중하게 되어서
현실과는 거리가 먼 이미지를 생성해 내게 됩니다.
이러한 이유 때문에, Generator가 gt와 비슷한 이미지를 생성하도록 하는 추가적인 term이 필요하게 됩니다.
단순 L1 loss를 추가로 사용합니다.
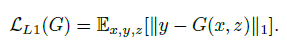
그리고 이 둘을 합친 최종 loss는 아래와 같습니다.
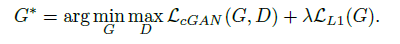
Generator
본 모델의 Generator는 우측 하단에 해당하는 U-Net 구조를 활용하였습니다.
![Pytorch] Pix2Pix 구현하기](https://blog.kakaocdn.net/dn/UqhUK/btqD2cobUJY/PjkvoiKWXbCRZ8KdsuHLm0/img.png)
이전의 모델들은 좌측과 같은 Encoder-decoder 구조를 활용한 Generator를 사용하였습니다.
하지만 downsampling된 feature로 부터 decoder에서 다시 upsampling 과정을 거칠 때에 정보가 손실되는 문제가 발생한다는 문제점이 있습니다.
이를 해결하고자 본 논문은 skip-connection을 활용한 U-Net 구조의 generator를 사용했습니다.
skip-connection을 통해서 low-level의 information을 그대로 decoder쪽으로 전달하게 되는것입니다.
이러한 방식을 사용할 수 있는 이유에 대해 알아봅시다.
예를들어 image colorization task를 수행한다고 가정을 했을 때, encoder-decoder layer를 거치고 우리가 얻게되는 output image는 image edge영역은 큰 변화가 없고 색감만 바뀐 영상만 출력을 하게 될 것입니다.
image translation도 마찬가지로 전체적인 edge 영역에는 큰 변화가 없기 때문에,
edge와 같은 특성은 skip-connection을 사용해서 decoder로 바로 전달하고자 한 것입니다.
각 모델의 정성적 결과는 아래와 같습니다.
U-Net 구조의 성능이 확실히 좋은 것을 알 수가 있습니다.

Discriminator
Image Translation task에서 사용하는 l1, l2 loss는 앞서 말씀드린 것 처럼 blur한 결과를 도출하게 됩니다.
이는 이러한 distance 기반의 loss 를 줄이고자 pixel값을 평균화하기 때문입니다.
이런 단점도 존재하지만, 반대로 장점도 존재합니다.
l1, l2 loss는 고주파 선명도를 높이지는 못하지만, 저주파 정보는 정확하게 포착해 낸다는 장점이 존재합니다.
전체 Objective function에서 L1 loss를 사용함으로써 저주파 정보를 잘 포착할 수 있으니,
우리는 GAN Discriminator를 통해서 고주파 성분만 잘 modeling 하면 됩니다.
이를 위해서 PatchGAN 이라고 하는 Discriminator 모델 구조를 제안하게 됩니다.
이는 이미지 전체에 대해 real, fake를 판별하는 것이 아니라,
이미지를 NxN patch 단위로 나눠서 각 patch에 대해 real, fake를 판별하게 되는 것입니다.
Experiment

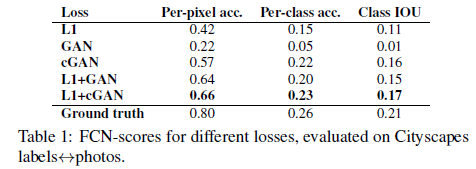
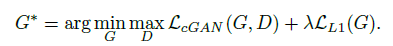
위의 Objective function 에서 어떤 term이 중요한 것인지를 알기위한 ablation study 입니다.
L1 만을 사용했을때 저주파 성분은 잘 생성해 냈지만, egde와 같은 고주파 성분은 잘 생성되지 않은것을 볼 수 있습니다.
반대로 cGAN만을 사용했을때에는 뭔가 저주파 성분이 부족해 보이는 것을 볼 수 있습니다.
그리고 둘을 함께 사용했을때에 비로소 정확한 이미지가 출력되게 되고,
이는 Table 1 의 정량적 평가에서도 확인하실 수 있습니다.

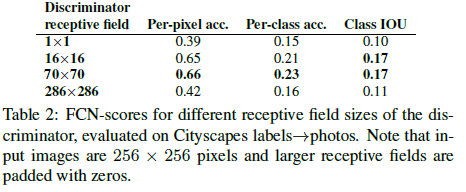
위의 Discriminator 의 설명에서 고주파 영역에 집중을 해야하기 때문에 image를 patch 단위로 나눠서 real, fake를 판별한다고 언급 했습니다. 그에 따른 실험 결과인데, 70×70 patch를 사용할 때에 가장 좋은 성능을 낸다고 합니다.
그리고 아래는 여러 실험 결과들인데, 한번씩 살펴보시면 좋을 거 같아서 첨부합니다.
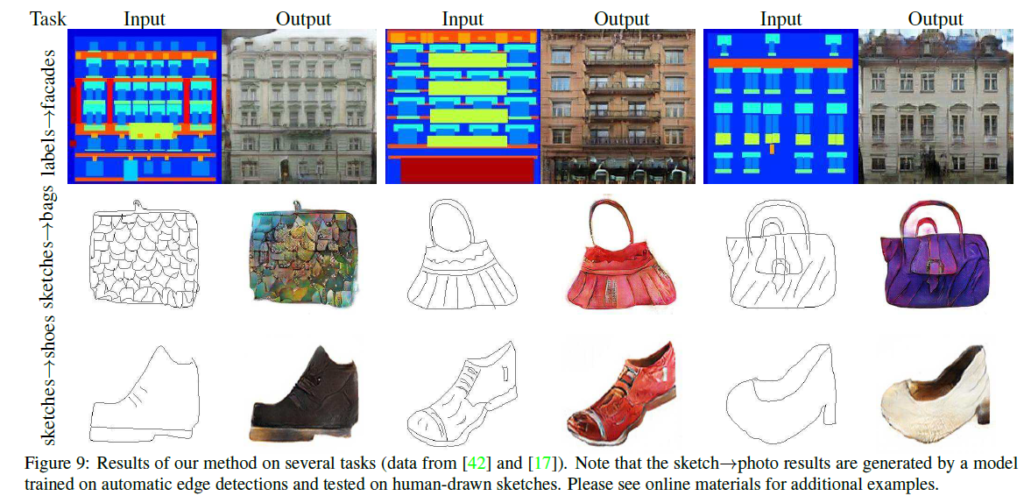

사실 이 논문을 읽기 전에는 몰랐는데 GAN 내용이 꽤나 많이 등장을 하더군요.
이해하기에 많이 어렵지는 않았지만, GAN 관련된 내용을 좀 더 많이 아는 상태였다면
‘이해하고 받아 들이는 데에 더 수월하지 않았을까’ 라는 생각이 듭니다.
다음엔 GAN 관련 논문도 기회가 된다면 한번 읽어 봐야겠습니다.
그럼 이상으로 리뷰 마치도록 하겠습니다.
좋은 리뷰 감사합니다.
리뷰 마지막쯤 patchGAN의 receptive field 별 정성적, 정량적 결과를 첨부해주신 부분에서 질문이 있습니다.
Table 2가 Figure 5에 대한 정량적 결과가 맞나요?
GT가 무엇인진 모르겠지만 시각적으로 보았을 때 16*16은 70*70에 비해 뭔가 깨져있는듯 하기도 하고 이미지 내의 컨텐츠도 서로 많이 다른데, 어떻게 정량적인 수치는 저렇게 차이가 적게 날 수 있는 것인지 궁금합니다.
본 논문에서 평가한 방식은 GT와의 비교가 아닌, pretrain된 semantic segmentation 모델을 활용한 평가를 사용하게 됩니다. 평가방식에 대한 자세한 설명은 아래 댓글의 답글을 참고하시면 될 거 같습니다.
다시말해 output image에 대해 segmentation 성능을 보게 되는것입니다.
의문을 가지신 16*16, 70*70에 대해서, 정성적 비교에 비해 정량적 수치 차이가 너무 적게 나는것이 저도 조금은 의문이긴 합니다만, segmentation 모델을 활용한 분류 성능을 score(FCN-score) 로 표기한 것이므로 정성적으로 결과가 조금 깨져서 보인다고 해도 분류 성능에는 크게 영향이 가지 않은 듯 보입니다.
정성적인 성능을 표현할 때, Pixel accuracy는 이해하겠는데, Class accuracy는 무엇을 뜻하나요?
생성 모델의 성능을 평가하는것은 쉽지 않기 때문에, 본 논문에서는 cityspace dataset으로 pretrain 된 FCN-8s 라는 semantic segmentation 모델을 사용하게 됩니다.
한마디로 말해, 생성모델이 만들어낸 합성 데이터 (synthetic image) 에 대해서 segmantation 분류 정확도를 각각 pixel, class 단위로 평가 한 것입니다. 생성모델이 만들어낸 데이터가 real 에 가깝다면, real dataset(cityspace) 로 학습된 semantic segmentation 모델에서의 성능이 높게 나오겠지요??
안녕하세요. 좋은 리뷰 감사합니다.
석준님의 설명 덕분에 어떻게 학습이 이뤄지는지 잘 이해할 수 있었습니다. 그런데 리뷰 후반부에서 고주파, 저주파 단어가 계속 등장하는데, 이미지에서의 고주파, 저주파가 정확히 무엇이고 둘의 차이가 무엇일까요? 음성 관련해서 고주파 저주파의 차이는 알겠으나 이미지에서의 고주파 저주파 차이가 정확히 무엇을 의미하는 것인지 헷갈려 질문합니다.
이미지를 기준으로 했을때에,
고주파 성분이란 밝기 변화가 크게 발생하는 곳을 말합니다. 이미지의 경계나 모서리 부분에서 픽셀값이 크게 변할테니, 한마디로 고주파 성분이란 물체의 edge라고 생각하시면 됩니다.
반대로 저주파 성분이란 밝기 변화가 거의 없는곳을 뜻하고, 배경이나 물체의 내부 영역을 의미합니다.