

간만에 리뷰할 논문은 “DnS: Distill-and-Select for Efficient and Accurate Video Indexing and Retrieval” 라는 논문으로, CBVR에서 유명한 방법론인 ViSiL의 저자가 투고한 논문입니다. 저희가 논문을 준비하던 8월 전까지는 arxiv에 preprint로 공개되어 있었으나, 8월 초에 IJCV에 accept이 되어 출판된 것으로 보입니다.
Video retrieval task에서는 두 비디오 사이의 유사도를 계산하는 시점에 따라 frame-level feature 기반 방식과 video-level feature 기반 방식이라는(이 논문에서는 fine-grained 방식과 coarse-grained 방식으로 rename 되었네요) 두 종류의 stream 존재합니다. 전자의 경우, 프레임 사이에서 유사도를 계산하기 때문에 비디오 길이에 영향을 크게 받지 않는 검색 능력을 가질 수 있지만 높은 계산 복잡도로 인하여 프로세스가 느린 편에 속하고, 후자의 경우, 한 비디오를 하나의 feature로 embedding 시킨 후 이것을 활용한 유사도를 계산하기 때문에 비디오가 길수록 손실되는 정보량이 많아지게 됩니다. 따라서, 검색 능력이 상대적으로 낮은 편에 속하지만 계산 복잡도는 낮기 때문에 프로세스가 빠르며, 데이터 베이스에 속하는 비디오들을 feature로 저장할 때의 메모리 비용도 낮아지게 됩니다.
본 논문에서는 이 두 종류 stream의 장점들만을 취합하고자 Knowledge Distillation scheme을 활용하였습니다. 검색 능력은 좋지만 inference가 느린 frame-level feature 기반 방식을 Teacher로 두고 student 모델들을 학습시켰으며, student 모델들 사이에 Selector Network를 두어 reranking 하는 방식 또한 고안해내었습니다.
1. Distill-and-Select (DnS)
1.1. Baseline Teacher (T)
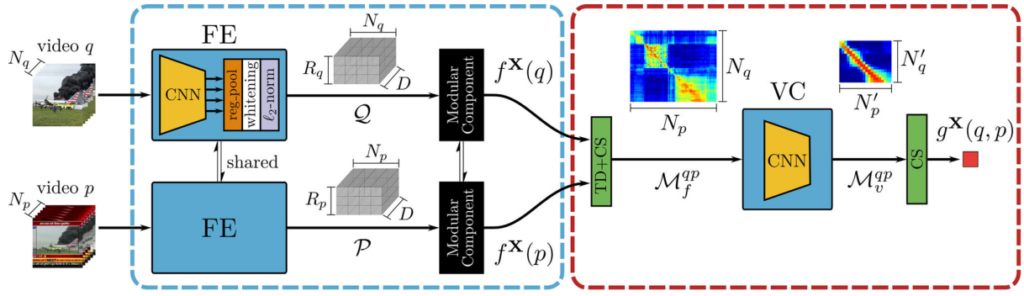
Knowledge Distillation scheme에서 Teacher 모델로는 기존에 좋은 성능을 보여왔던 Frame-level feature 기반 방법론 ViSiL이 사용되었습니다. ViSiL은 SOTA에 해당하는 성능으로 오랜 기간 Video Retrieval 분야에서 이름을 알려왔으며, 이전 제 리뷰와 더불어 많은 연구원들이 했던 리뷰가 있으니 해당 리뷰들을 참고해주시면 감사드리겠습니다. ViSiL 논문과 약간 달라진 점만 말씀드리자면, 원래는 attention layer로 불렸던 layer가 이 논문에서는 Modular Component로 이름만 변경되었으니 읽으실 때 참고하고 읽으시면 좋을 것 같습니다.
1.2 Fine-grained & Coarse-grained Student
Student 모델로는 Fine-grained Student 두 종류 (S^{f}_{\mathcal{A}}, S^{f}_{\mathcal{B}})와 Coarse-graine Student 한 종류 (S^{c})를 제안하였습니다.
먼저 Fine-grained Student는 Teacher Network보다 Modular Component를 deep하게 쌓은 Fine-Grained Attention Student (S^{f}_{\mathcal{A}})와 Teacher Network에서 binariazation output을 가져올 수 있도록 설계뙨 Fine-Grained Binarization Student (S^{f}_{\mathcal{B}})로 나뉩니다.
- Fine-Grained Attention Student (S^{f}_{\mathcal{A}})
Fine-Grained Attention Student (S^{f}_{\mathcal{A}})는 ViSiL과 같은 구조에서 Linear layer(3840×1) 하나로 구성된 attention layer, 즉 Modular component를 h-attention이라는 형태로 변형한 것으로, 여기서 h-attention은 식 (1)과 같습니다.

여기서 r은 Modular component에 들어오는 입력, W_a와 b_a는 3840×3840 크기의 Linear layer, u는 r을 입력으로 기존 attention layer를 태운 뒤의 출력을 의미합니다. 실제로 기존 방식에서 3840×3840 크기의 Linear layer로 projection 하는 과정이 추가된게 h-attention이라고 이해하시면 쉬울 것 같습니다.
- Fine-Grained Binarization Student (S^{f}_{\mathcal{B}})
Fine-Grained Binarization Student (S^{f}_{\mathcal{B}})는 마찬가지로 ViSiL과 같은 구조를 띄며, 식 (2)와 같이 attention layer에 들어가는 입력 값을 binarization 시키고자 하였다고 합니다. 이는 본래 sign 함수로 binarization 시키고자 하였던 것이었으나, sign 함수는 미분이 되지 않기에 이를 근사한 형태로 각 입력에는 gaussian 분포의 작은 uncertainty가 있다 라는 가정하에 설계되었습니다. (이를 유도하는 과정은 논문 9페이지 footnote에 있으니 참고)
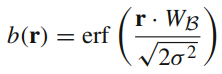
Fine-Grained Attention Student와 Fine-Grained Binarization Student는 유사한 구조를 가지고 있기에 비슷한 계산 비용을 보여줍니다. 그럼에도 불구하고 Fine-Grained Binarization Student를 사용한 이유는 주로 video 검색 시나리오에서 database의 모든 비디오들을 feature로 저장한 채로 활용하게 되는데, 이 과정에서의 메모리 이득을 위함이라 합니다.
- Coarse-graine Student (S^{c})
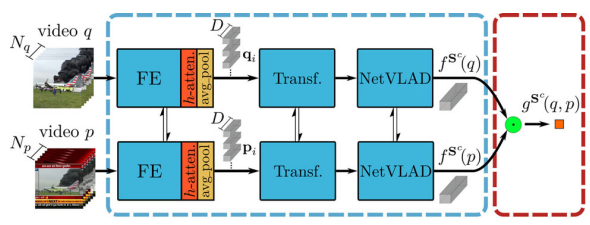
Coarse-graine Student (S^{c})는 앞선 과정들과 유사하게 frame-level feature를 추출하는 과정은 ViSiL을 따르나 이를 입력으로 Transformer와 NetVLAD를 거친다는 차이점이 있습니다. 여기서 Transformer와 NetVLAD는 흔히들 들어보셨던 그 모델들이 맞으며, Transformer의 경우 각 frame-level feature 간의 self-attention을 목적으로, NetVLAD는 frame-level feature들을 모아 video-level feature로 만들기 위해 사용되었습니다.
1.3 Selector Network
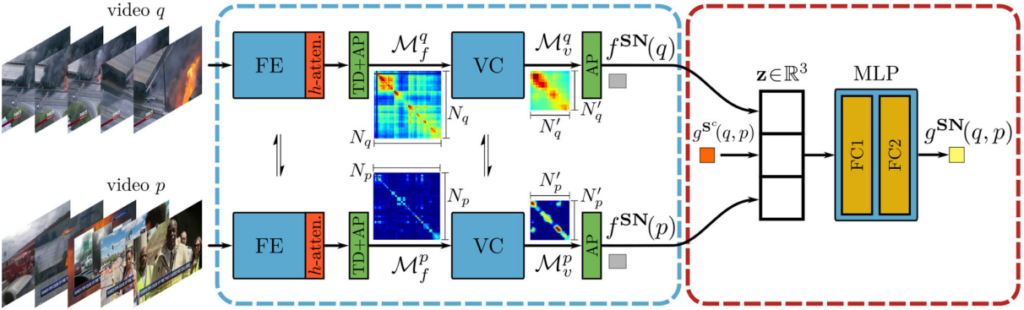
앞선 Student Network 사이에서 Selector Network의 역할은 빠른 계산 속도를 가진 Coarse-grained Student가 충분히 정확한 유사도를 반환하는지 혹은 그렇지 못해서 Fine-grained Student가 필요한지를 판단하는 것입니다. 즉, Selector Network는 Coarse-grained Student output과 Fine-grained Student output 사이의 confidence를 측정합니다. 이 과정은 Fig 4와 같으며, 두 비디오 q, p가 있을 때 기준으로 세 가지의 score를 계산합니다. 먼저 비디오 q, p 각각에 대해 Fine-grained Student 방식으로 유사도를 계산하되, 두 비디오 모두 self-similarity를 계산합니다. 원래처럼 q-p 쌍에 대한 유사도를 계산하는 것이 아닌, q-q, p-p에 대해 각각 계산하는 것으로 한 비디오 내에 프레임들 간 유사도를 계산하는 과정이라고 보시면 될 것 같습니다. 이 두 가지의 유사도 score 뿐만 아니라, 이번에는 q-p 쌍에 대해 Coarse-grained Sutdent를 통한 유사도를 계산합니다. 이렇게 세 가지의 유사도 score는 concat되어 MLP layer를 통과 후 confidence를 산출해내게 되며 이를 기반으로 기존 Coarse-grained Student를 통해 생성되었던 유사도 순위를 재정렬하는 과정을 거치게 됩니다.
1.4 Training Process
Teacher Network, Student Network, Selector Network 순으로 총 세번의 학습 과정을 거치게 됩니다.
- Teacher Network
Teacher Network는 ViSiL에서 하던 방식 그대로 VCDB 데이터 셋에서 학습됩니다. 디테일은 ViSiL 리뷰에서 확인부탁드립니다.
- Student Network
Student network들은 VCDB 데이터 셋과 해당 저자가 Distillation을 위해 따로 제작한 DnS-100k 데이터 셋에서 각각 학습됩니다. 이때 두 데이터 셋에서는 unlabeled 비디오를 활용하며, Teacher의 Knowledge로부터 Student를 학습 시키고자 두 Network의 output을 L1 Loss를 통해 optimize 시킵니다. 여기서 Teacher Network는 freeze 된 상태로 Student Network만 학습시킵니다.
- Selector Network
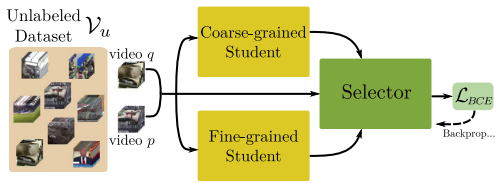
앞서 두 Network가 학습된 이후, Selector Network는 Coarse-grained Student가 충분히 정확한 유사도를 계산하고 있는지 측정하기 위한 Confidence를 생성해내도록 설계되었습니다. 이는 상대적으로 더 높은 성능을 보이는 Fine-grained Student를 기준으로 하며, 학습 과정에서는 특정 pair 사이에서 Coarse-grained Student의 유사도가 Fine-grained Student의 유사도와 크게 달라지지 않도록 식 (3)과 같은 BCE Loss를 통해 학습됩니다. 여기서 g는 유사도, t는 유사도 차이의 임계치로 hyperparameter입니다.
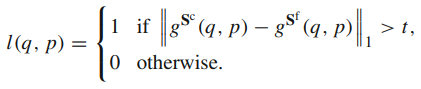
2. Experiments
2.1 Ablation: Retrieval Performance of the Individual Networks
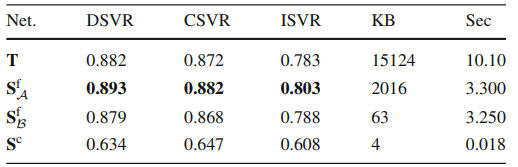
Table 1은 FIVR-5K에서 Teacher Network와 세 종류 Student Network 각각의 성능을 비교한 것입니다. 여기서 Teacher Network는 VCDB에서 supervision으로 학습된 것이며, 나머지 Student들은 Teacher로부터 DnS-100K 데이터 셋에서 distillation 된 성능입니다. 직접적으로 network 구조의 효력을 비교하려면 모두 VCDB에서 학습한 뒤 비교해야되지 않을까라고 생각하긴 하지만, 어쨌든 Fine-grained Attention Student가 가장 높은 성능을 보였다고 합니다.
2.2 Ablation: Distillation Versus Supervision
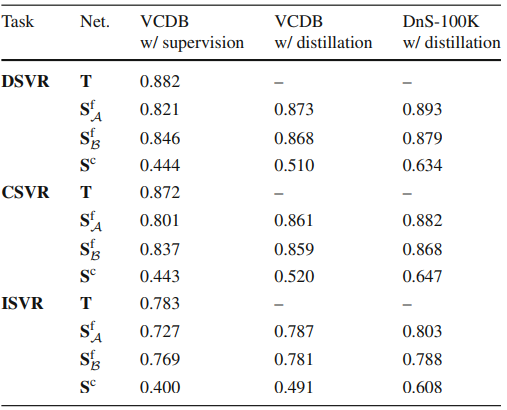
Table 2는 Student Network들에 대해 Supervision과 Disitillation 했을 때의 FIVR-5K ISVR 성능입니다. 방금 전 ablation에서 이야기 했던 모든 방법에 대해 VCDB에서 supervision으로 학습한 성능이 이 테이블에 있으며, Fine-graine Attention Student는 Teacher와 대부분 동일하지만 하나의 Linear Layer를 통해 Projection하는 부분이 추가되었을 뿐인데도 Teacher보다 낮은 성능을 보였습니다. 사실, 저도 이 부분을 ViSiL 코드를 기반으로 실험하면서 알고 있었는데, 이는 VCDB 데이터 셋이 feature representation을 모델에게 학습시키기에는 적합하지 않은 데이터 셋이기 때문이며 (실제로 상당히 주제를 알기 어려운 비디오 다수 존재), 이러한 이유로 직접적으로 feature를 projection 하는 경우 그렇지 않았을 때보다 낮은 성능을 나타내게 됩니다. 이 문제를 본 저자는 DnS-100K에서의 distillation을 통해 해결하고자 한듯합니다.
2.3 Ablation: Impact of Dataset Size
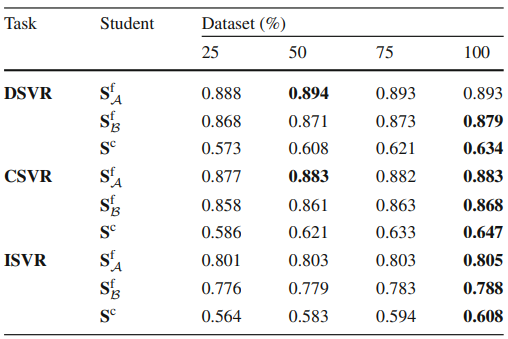
Table 3는 Student Network를 학습시키기 위해 사용된 DnS-100K의 데이터 비율에 대한 Ablation 결과입니다. Distillation에 사용되는 비디오의 비중을 높여감에 따라 특히나 feature를 projection 시키는데 영향을 많이 받는 Coarse-grained Student의 성능이 높아지는 것을 보았을 때, DnS-100K가 VCDB보다는 학습에 도움이 되는 데이터 셋임을 나타냅니다.
2.4 Ablation: Coarse-Grained Student
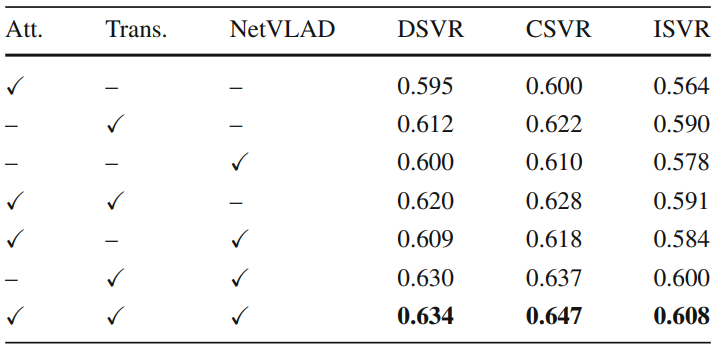
Table 4는 Coarse-grained Student의 구성 요소에 대한 ablation study입니다. 유사한 구조를 가지고 갔던 TCA와 비슷한 경향성을 보여줍니다. 참고로 이 논문의 저자에게는 조금 미안하지만, 저희가 실험해본 결과 저 세 component 없이 frame-level feature를 average pooling 하는 것만으로도 bold 처리된 성능이 나오긴합니다.
2.5 Ablation: Selector Network Performance
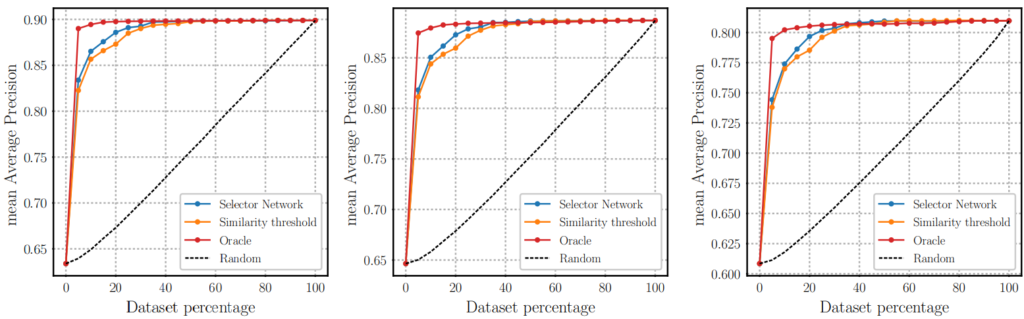
Fig 8은 Selector Network를 통해 Coarse Student로부터 반환된 유사도 순위 중 N%를 re-ranking했을 때의 성능입니다. 여기서 re-ranking되는 순위의 유사도는 Fine-grained Student로부터 가져오게됩니다. 실제로 GT를 알고 re-ranking 하는 Oracle 방식에 가장 근접하게 Selector Network가 작동하는 경향성을 보여줍니다.
2.6 Benchmark
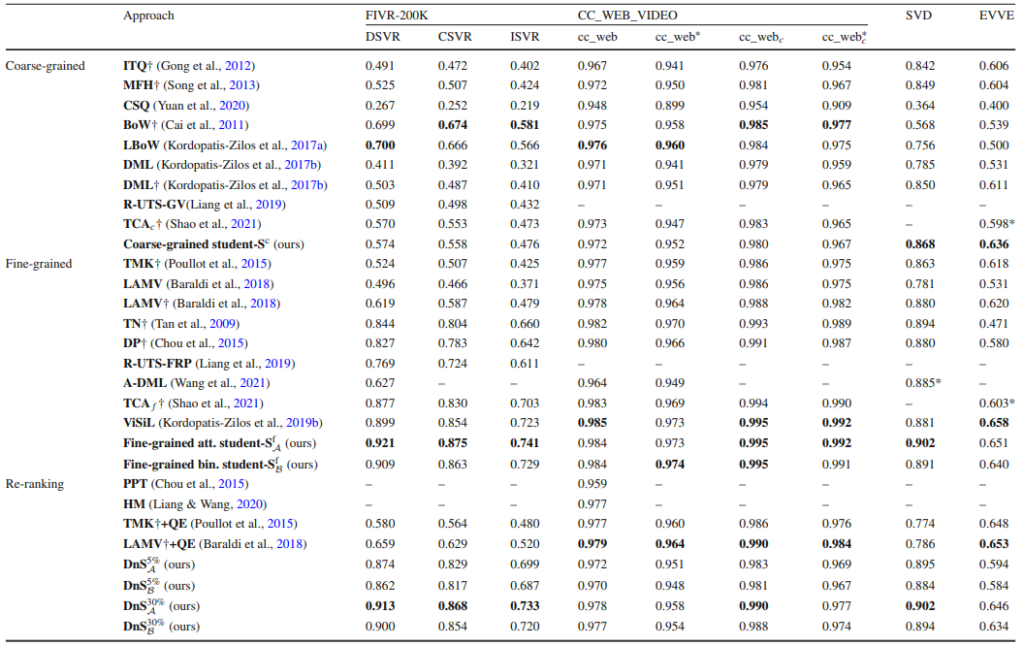
Table 5는 다른 방법론들 사이에서 제안된 방식의 benchmark 성능입니다. 여기서 DnS는 Selector Network를 통한 re-ranking까지 포함했음을 의미하며, %는 confidence 기준 re-ranking한 퍼센티지, 아래첨자는 re-ranking 시 활용한 Fine-grained Student의 종류입니다.
성능만 놓고 보았을 때는 가장 높은 성능을 달성하긴 했으나, 사실 한가지 아쉬운점은 reasonable한 비교인가에 대한 것입니다. 제가 논문을 준비하면서 알게 된게, Coarse-grained 즉 Video-level feature 기반 방식 중 가장 높은 성능을 보이는 것처럼 표시되어 있는 LBoW의 경우, 다른 여러 방법들이 하는 것과 마찬가지로 VCDB 데이터 셋에서 학습된 것이 아닌, FIVR 데이터 셋에서 K-fold를 나눠 학습 및 평가된 성능입니다. 또한 이 논문에서 제안된 Student들은 모두 DnS-100K라는 새로운 데이터 셋에서 Distillation 된 성능이며, 그리고 모든 방법 공통적으로 Backbone network가 다르다는 점입니다. 서로 고정된 세팅을 가지고 하는 것이 아니기에 성능이 높은 방법이 정말로 제안된 방식 때문에 성능이 높은 건지, 혹은 그냥 Backbone network가 좋아서 높은 건지 알 수 없기에 이 테이블 만으로는 reasonable한 비교가 어려워집니다. 때문에 앞으로 이 분야가 계속되려면, 저 포함해 이 분야를 하고 있는 연구자들은 최대한 같은 세팅으로 실험을 하여 reasonable한 비교가 가능하도록 실험하는 것이 필요해보입니다.
3. Reference
[1] https://link.springer.com/content/pdf/10.1007/s11263-022-01651-3.pdf
좋은 리뷰 감사합니다.
1. 물론 backbone network도 고려해야겠지만 학습 데이터셋 기준으로 DnS와 다른 방법론들의 reasonable 한 비교를 하려면 2.2 Ablation: Distillation Versus Supervision의 VCDB w/ distillation 부분의 성능을 보면 되는건가요?
2. knowledge distillation을 위해서라고는 하지만 결국에는 VCDB보다 학습 효과가 더 좋은 데이터셋을 학습에 사용하여 성능이 올라간게 아닌가 하는 생각이 듭니다. 그렇다면 다른 방법론들을 VCDB+DnS-100K로 학습 시키고 성능을 측정, 비교한다면 그때는 reasonable 하다고 할 수 있는 것인가요? knowledge distillation의 과정 자체가 다른 방법론들과 좀 다른 것 같은데, 어떻게 비교해야 reasonable 한 것인지 궁금합니다.
1. 네 맞습니다. 그 부분에서 보이는 네가지 모델 (Teacher, 3종류 Student)는 어차피 모두 동일한 Backbone network를 활용하기에 학습 데이터 셋만 맞춰준다면 reasonable 하게 비교할 수 있습니다.
2. DnS라는 방법론과 Knowledge Distillation을 하지 않는 다른 방법론을 비교하기는 좀 어렵고, 기존 방법론들끼리 (ViSiL, TCA, VRAG …) VCDB+DnS-100K로 학습시켜 비교한다면 reasonable 하다고 할 수 있습니다. 주로 distillation 방법론들은 그 scheme을 따르는 방법들 사이에서 누가 더 지식을 잘 전달했냐를 비교하며, 다른 방법과 비교하고자 한다면 distillation은 하지 않더라도 DnS-100K에서 unsupervision으로 학습할 경우만 비교가 가능할 것 같네요.
Selector Network이 학습에서 어떤 영향을 미치는지가 궁금합니다. Student Network의 경우에는 Coarse / Fine-grained가 각각 따로 학습된 이후에 Selector Network가 Coarse-grained Student의 경향성이 Fine-grained Student와 유사하도록 학습하는 것으로 보이는데요. 학습을 할 때 그럼 Selector Network에서 각 Student network도 학습시키는 방향으로 진행이 되나요?
학습 과정은 Teacher, Student, Selector 따로 직렬적으로 학습되며, 특정 단계가 학습될 시 이전 단계는 freeze 된 상태라고 보시면됩니다. 3-stage 방식이라고도 하는 방식입니다.