이번에 소개드릴 논문은 CVPR2022에 게제된 InstaFormer라는 논문입니다. 제목에서부터 직관적으로 알 수 있듯이, Image to Image Translation 분야이며 이제 Transformer를 곁들인 논문입니다. 추가적으로 Instance level에서의 translation 성능 향상을 보이도록 노력했다고 하네요.
Intro
Image to Image Translation(I2IT)는 제가 예전부터 꾸준히 리뷰를 해온 분야이기 때문에 저의 예전 리뷰들을 살펴보시면 친절하게 설명이 잘 나타나있습니다. 그래서 굳이 디테일하게 다루지는 않고 간략하게 소개만 하면 X라는 도메인과 Y라는 도메인이 있으면 X 도메인을 Y도메인 또는 그 반대로 변환시키기 위한 분야입니다.
이때 도메인을 변환시키는 Generator와 가짜 영상과 진짜 영상을 구분하는 Discriminator를 통한 adversarial loss를 메인으로 학습을 하는 편입니다. 이러한 목적은 Style Transfer, Super Resolution, Colorization, Inpainting 등 정말 다양한 분야에 I2IT framework을 적용할 수 있습니다.
하지만 대부분 기존의 I2IT 방법론들은 영상 전체(whole image)에 대하여 Translation을 하는 방법에 대해 고려했기 때문에, 주행환경과 같이 다양한 크고 작은 사물들이 나오는 영상에 대해서는 Translation 결과가 매우 별로였습니다.
즉 영상 전체로만 봤을 때는 Y 도메인의 분위기(명도 분포, texture, color) 등이 잘 담겨있을지라도, 실제 영상 속 instance 레벨에서 보았을 때는 translation이 잘 되지 않았거나 또는 structure 들이 다 뭉게지는 등의 현상이 자주 발생하곤 했습니다.
그래서 이러한 instance level까지 translation을 잘 해보자라는 논문 분야들이 나오길 시작했고 이러한 분야를 Instance aware I2IT라고 한다고 합니다. Instance-aware I2IT의 가장 대표적인 방법론으로는 Object detection과 I2IT를 동시에 학습하는 DUNIT이라는 방법론이 있다고 합니다.
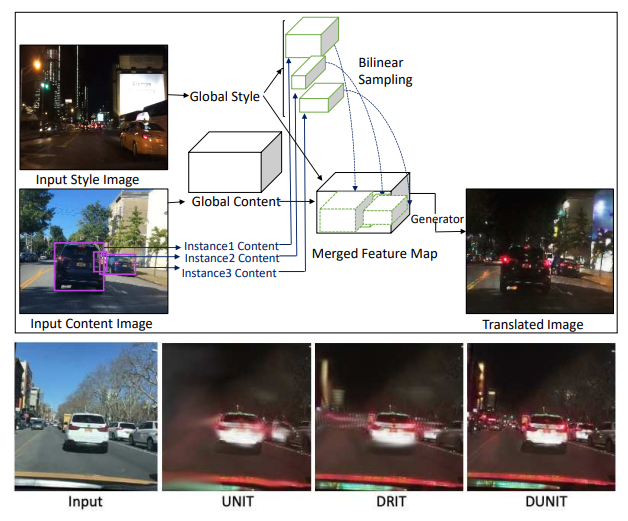
하지만 논문에서는 이러한 DUNIT 같은 방법론들은 CNN 기반으로 구성되어 있어 여러가지 단점들이 있다고 합니다. 근데 사실 이건 뭐 Transformer를 처음 적용했다는 타이틀을 얻기 위해서 흔히들 말하는 CNN의 receptive field의 단점 등을 함께 언급하기 때문에 굳이 Translation을 위한 이점이라고 생각을 하지는 않고 있습니다.
하지만 한가지 유의미하다고 생각이 드는 것은, transformer의 self-attention 연산은 결국 패치들 간에 correlation을 계산할 수 있다는 점에서, instance 영역과 전체 이미지 간의 correlation 뿐만 아니라 서로 다른 instance들 간의 correlation도 함께 고려해서 translation을 하기 때문에 보다 더 선명하고 잘 변환된 영상을 얻을 수 있다고 저자는 주장하고 있습니다.
아무튼 최종적으로 논문에서 제안한건 Transformer의 여러 이점을 살려 instance 레벨에서의 translation 성능을 크게 향상 시켰다고 이해하시면 될 것 같습니다.
Overview
일단 논문에서 하고자하는 것은 Unsupervised I2IT입니다. 즉 X 도메인과 Y 도메인의 영상이 서로 style도 다르고 content도 다른 영상에서 X도메인의 영상을 Y 도메인처럼 만들고자 하는 것이지요.
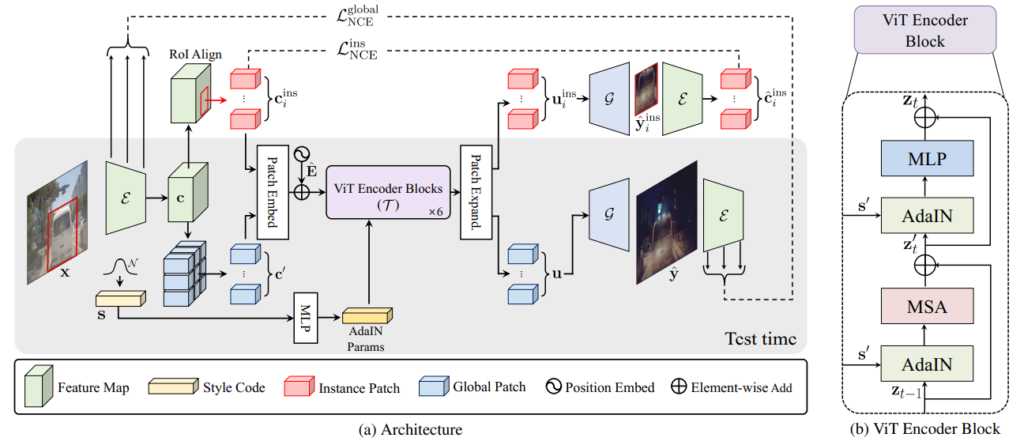
이때 크게 봐야할 부분들은 Content Encoder \mathcal{E} , Generator \mathcal{G} , 그리고 transformer 기반의 encoder \mathcal{T}가 존재하고 있습니다. 여기서 이제 X 도메인의 입력 이미지 x를 content encoder \mathcal{E} 에 넣어서 c라는 content feature map을 생성합니다.
이와 동시에 확률 분포 q(s) ~ N(0,1)을 가지는 Style vector를 MLP를 태워서 새로운 Style latent code를 생성합니다. 이 style code는 multi-modal translation을 수행하는데 있어 필요로 하게 됩니다.
이렇게 구한 c와 s에 대해서 곧바로 generator \mathcal{G} 에 태우는 것이 아닌, instance 영역과 실제 global한 영역에 대하여 두 정보를 잘 섞어주는 과정을 진행을 합니다. 이를 위해 content feature c에 대해 바로 patch 영역을 token으로 쪼개는 global content 구간과 또 GT bounding box를 통해 crop한 region을 tokene으로 만드는 과정으로 나뉘게 됩니다.
이렇게 instance region과 global 영역으로 token들이 나뉘어지면 이 둘을 섞어서 Transformer \mathcal{T} encoder에 입력으로 넣어주면 global embedding vector u과 instance embedding vector u^{ins}_{i} 를 생성할 수 있게 됩니다. 이러한 embedding vector들은 각각 generator에 들어가서 translation 결과를 생성하게 됩니다.
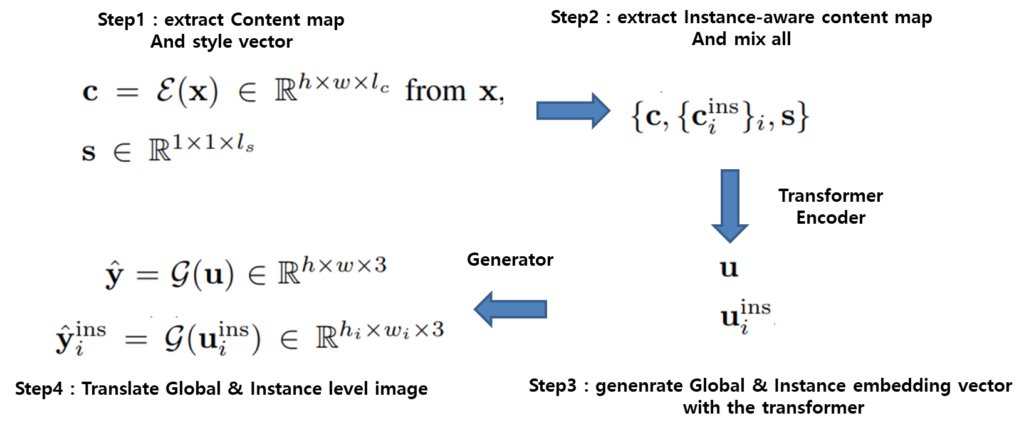
정리하자면 위와 같이 구성이 될 수 있다고 생각하시면 될 것 같습니다. X도메인 이미지에 대해서 content feature를 추출하고 확률 분포에서도 MLp를 태워 style code를 준비합니다. 그리고 content feature map은 GT bounding box를 통해 instance level의 content feature를 따로 준비하여 이 셋을 transformer를 통해 잘 조합하여 연산합니다.
이렇게 생성된 Global & Instance level embedding vector는 generator를 통과하여 instance level의 image과 global level의 transnlated image를 생성하게 됩니다.
이렇게 생성된 각각의 global & instance translated image는 Content loss와 Style loss로 나뉘어져서 학습을 진행하게 됩니다. 이는 Style Transfer 쪽 분야의 논문을 읽어본 분이시라면 매우 쉽게 이해하실 수 있을텐데 다시 말해서 X도메인의 이미지에서 뽑은 content feature와 Translated image에서 뽑은 content feature 끼리 비교하고, reference image에서 뽑은 style vector와 translated 이미지에서 뽑은 style vector가 서로 유사해지도록 학습하는 것이죠.
Patch Embedding & Patch Expanding
자 그럼 조금 더 세부적으로 접근해봅시다. 먼저 Transformer 기반의 encoder를 통해 embedding vector를 생성하게 되는데, 이때 transformer는 아무래도 입력 feature map의 resolution에 따라 연산량이 매우 크게 증가하게 됩니다. 그래서 저자는 이러한 연산량을 줄이고자 Transformer encoder 앞 뒤로 Patch embedding과 expanding 과정을 수행합니다.
근데 사실 패치 임베딩 expanding이라고 해서 딱히 창의적이고 대단한 것은 없습니다. 기존 ViT가 single convolution layer를 통해 16×16 패치로 token을 만들었던 것과 달리 여기서는 overlapped convolution layer를 여러층 쌓아서 token을 만든 것이 patch embedding 과정입니다.
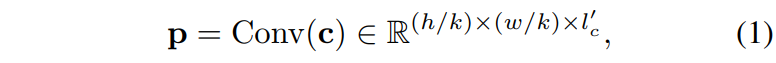
여기서 k는 stride 값으로 stride 값만큼 feature map의 해상도가 줄어들게 될 것이고 이렇게 구한 p를 transformer에 넣어서 z라는 feature를 생성하게 됩니다.
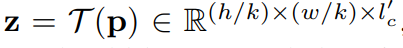
이 z는 역시나 input p와 동일한 해상도를 지니고 있기 때문에 다시 원래의 해상도로 돌려주기 위해서 논문에서는 deconvolution을 적용했다고 합니다. 컨볼루션으로 해상도를 줄였으니 deconvolution으로 해상도를 다시 늘려주는 매우 직관적이면서 단순한 구조입니다 허허..
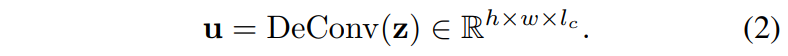
Transformer Aggregator
Transformer 내부에는 사실 ViT와 매우 동일하게 연산이 수행이 됩니다. 먼저 positional encoding vector를 더해주고 그 다음에는 MSA와 FFN을 태워주는 과정을 반복합니다. 여기서 다만 기존의 VIT는 Layer Normalization을 사용하였다면 해당 논문에서는 Image Translation이라는 분야에 맞게끔 Adaptive Instance Normalization으로 대체해주었다고 합니다.
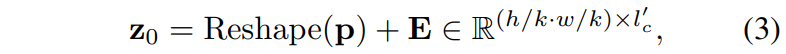
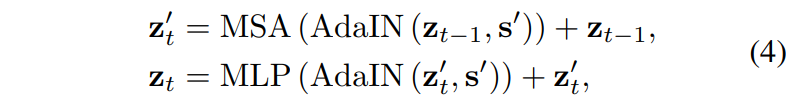
수식으로 표현하면 위와 같습니다. ViT에 대해서 잘 아신다면 위의 수식만 보고도 어떤 의미인지 다 아실거라 생각합니다.
Instance-Aware Content and Style Mixing
지금까지 한 얘기는 약간 기본적인 Transnlation과 ViT의 흐름에 대해서 알아본 것이라면 이제는 본격적으로 Instance level에서 Transnlation의 성능을 향상시키기 위한 부분들에 대해서 알아볼 예정입니다.
일단 instance level에서의 embedding vector를 생성하는 과정은 위에서도 설명했듯이 간단합니다. GT bounding box를 통해 content feature map c에 대해서 ROI Pooling을 수행하는 것이죠.
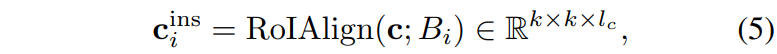
그 후에는 수식1~4까지의 과정을 동일하게 진행하면 instance level에서의 embedding vector u가 생성됩니다.
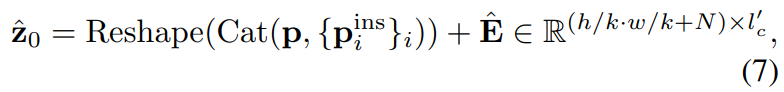
Loss function
일단 모델 학습에 있어 가장 기본적인 loss 함수들에 대해서 다뤄보겠습니다.
먼저 Discriminator를 활용한 Adversarial loss가 존재합니다.
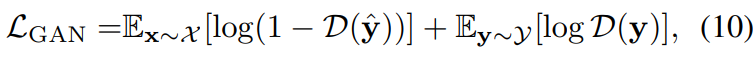
또한 global content loss를 통해 NCE loss를 적용하는 term이 존재합니다.
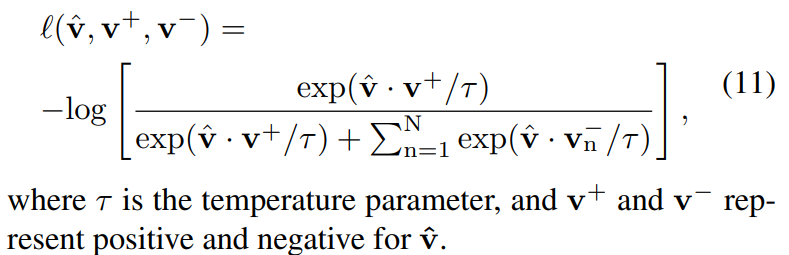
여기서 postive pair의 경우에는 translated 된 patch와 원래의 input content image의 동일 위치상 patch를, negative pair는 그 외에 다른 위치에 존재하는 patch관의 관계를 의미합니다.
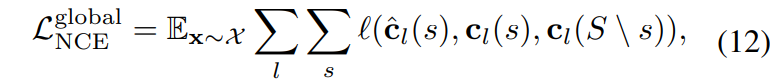
이러한 NCE loss는 Instance level에서도 동일하게 적용이 됩니다.
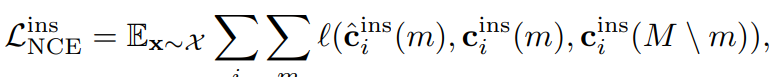
보다 더 직관적으로 이해할 수 있게 그림으로 표현하면 아래와 같습니다.
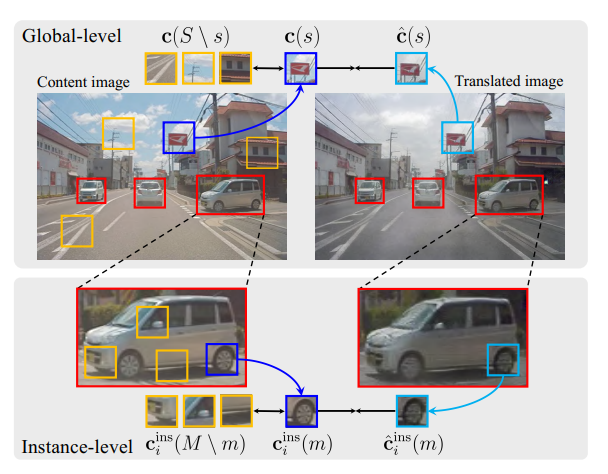
노란색 박스들은 negative, 파랑색은 positive, 하늘색은 query box에 해당합니다.
그 외에도 Content loss, Style loss가 적용되어 최종 모델을 학습하게 됩니다.
Experiments
실험에 사용한 데이터 셋은 Instance-aware I2I, INIT dataset과 Domain Adaptation을 위한 CityScape 및 KITTI dataset을 활용했다고 합니다.

정량적 결과 살펴보시면 sunny, night, cloudy, rainiy 등과 같은 변환에 대해서 제안하는 방법론이 대부분 가장 좋은 성능을 보여주고 있습니다. IS와 CIS는 각각 Inception Score와 Conditional Inception Score라는데 음.. 해당 metric을 잘 몰라서 저정도 차이가 엄청 큰 성능 향상인지는 잘 모르겠습니다.(일단 높으면 높을수록 더 좋다고 합니다.)
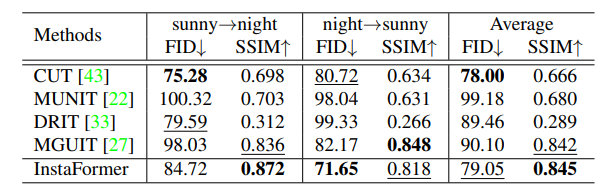
그래서 그런지 FID와 SSIM 평가 메트릭을 활용한 결과표도 함께 있네요. SSIM 지표가 0.8 이상이면 사람의 눈으로 봤을 때 원본 영상과 비교하여 어색함이 전혀 없다고 봐도 무방한 수준인데, 평균이 0.845면 상당히 높다는 생각이 듭니다. 다만 어떤 도메인에서는 FID가 밀리고, 어떤 도메인에서는 SSIM이 밀리는 등의 모습을 보아하니 무언가 해결해야될 부분이 존재해 보입니다.

다음은 정성적 결과인데, 확실히 기존의 I2IT 방법론인 CycleGAN, UNIT, MUNIT같은 경우에는 차량에 대해서 노이즈가 심한 반면에 논문에서 제안하는 방법론은 선명해보입니다. 하지만 보통 I2IT의 정성적 결과는 체리픽이 대부분이니 너무 신뢰하지는 않는게 좋을 듯 합니다.
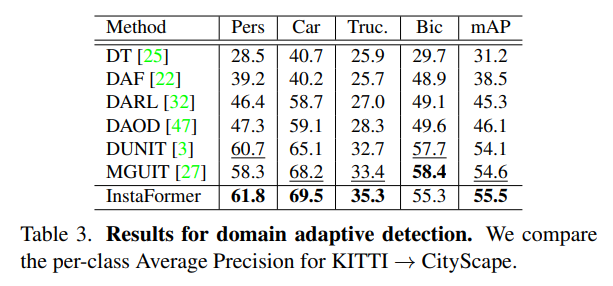
위에 표는 KITTI 데이터셋을 City Scape로 DA를 적용한 다음에 Faster-RCNN에 대한 MAP 성능을 나타낸 것이라고 합니다. Bic를 제외하고는 모두 가장 좋은 성능 향상 폭을 보여주고 있습니다.
결론
열화상 영상을 RGB 영상으로 만들려는 실험을 오랫동안 해온 저로서 저도 항상 기존의 I2IT 방법론들이 Instance level에서 너무나 노이즈하고 왜곡이 심한 영상들을 많이 만들어서 불만이 이만저만이 아니었던 기억이 납니다.
하지만 해당 논문은 End-to-End 방식에 test 타임에는 bounding box가 필요없다는 점에서 상당히 메리트가 있는 방법이라고 생각이 듭니다. 하지만 한가지 아쉬운 점은 test time에는 bounding box가 필요없도록 따로 설계한 것이 아닌데… 그냥 있고 없고의 성능 차이가 그리 크지 않았길래 뺐다라는 저자의 솔직한 답변을 KCCV에서 듣고 왔더니 운적인 측면에서도 좋았다고 볼 수 있겠습니다.
좋은 리뷰 감사합니다.
정성적 결과는 혹시 어떤 도메인으로의 변환한 결과인 지 알 수 있을까요??
변환이 되었을 때 인스턴스 레벨에서 선명하고 실제 이미지 같아 보이는 지를 정성적으로 확인하는 것일까요??
그리고 객체에 ROI Pooling을 적용하여 translation을 적용하는 것이면 객체의 크기에 따라 정확도가 영향이 있을 것 같은데 이에 대해 어떻게 생각하시나요??
첫번째 행부터 차례대로 sunny2night, night2sunny, cloudy2night입니다.
Image2Image Translation에서 눈여겨 볼 점은 domain 정보가 잘 변환되면서 instance와 global에 대한 모든 content 정보들이 입력 영상과 동일하게 잘 나타나있으면 됩니다.
그리고 제가 리뷰에는 깜빡하고 넣지 못했는데, ROI pooling을 적용해서 구한 instance content map이 kxk 해상도를 가지는데, 이때 patch embedding layer에서 kxk만큼의 downsampling을 수행하는 바람에 1×1 크기의 일종의 벡터로 계산이 된다고 합니다.
즉 ROI에 global average pooling을 한 것처럼 진행이 되기 때문에 객체의 크기에 대하여 조금 더 능동적이지 않을까라는 생각이 들고 그럼에도 작은 물체에 한해서는 성능이 좋게 나오지 못할 수도 있을 듯 합니다.