제가 다양한 논문을 리뷰하면서 혹은 제가 실험한 결과를 보여드리는 것을 통해 Stereo 를 입력으로하는 Network의 성능이 단일 영상을 입력으로하는 것보다 Depth estimation 을 하는데 훨씬 유용한 성능을 보인다는 것을 알려드렸습니다. 이러한 사실은 저희 분야의 많은 연구자들이 아는 사실이며 이러한 사실을 토대로 제안된 신박한 논문이 있어서 소개드리고자 합니다.
Contribution
- stereo matching model의 입력이 될 stereo image를 생성하는 새로운 pipeline을 제시함
- 다양한 실험
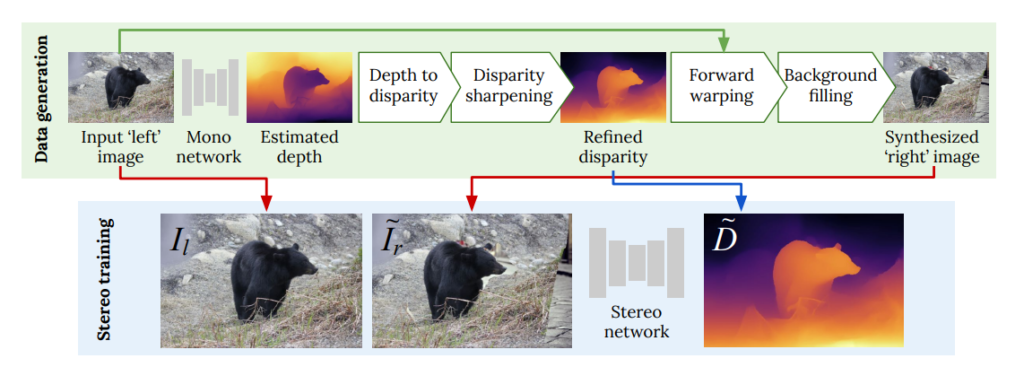
그림 1을 보시면 이 논문이 제안하는 방법론이 무엇인지 볼 수 있습니다. Mono Network를 통해서 Depth를 추정한고 scale이 맞는 disparity를 추정한 후 sharpening을 통해 depth를 더욱 정확하게 만들어줍니다. 그리고 warping 방식을 통해서 오른쪽 영상을 생성합니다.
그후 생성된 왼쪽 영상과 오른쪽 영상을 가지고 stereo Network를 학습시키면 됩니다. 이때 GT는 sharpening 까지 완료한 Depth를 사용합니다.
Background filling
영상에서 Depth를 추정할경우 occlusion 이나 collision 등의 이유로 인해서 값이 이상한 depth 가 추정됩니다. 이때 forward warping 을 통해서 오른쪽 영상을 생성하면 해당 부분을 검정색으로 나오게 되는데 이러한 부분으로인해서 인공적인 disparity가 예측되는 문제가 발생합니다. 이러한 문제를 해결하기위해서 이 논문에서는 cutmix 와 같이 데이터 중에서 다른 임의의 영상을 붙혀넣어서 성능을 올렸다고 합니다.
Depth Sharpening

단순히 mono network에서 나온 output을 사용할 경우 위그림과 같이 노이즈하거나 엣지가 살지 않은 depth map으로 인해서 warping 되 right image 또한 noisy 하게 됩니다. 따라서 이논문에서는 이러한 문제를 sobel filter를 통해서 해결했습니다. sobel filter를 통해 거르고 해당 pixel을 날려버려서 더욱 정확하고 sharp 한 right image를 생성하고 최종적으로도 좋은 disparity를 예측할 수 있었다고 합니다.
Experiments
실험 파트가 기존에 제가 읽었던 depth estimation 방법들하고 달라서 살짝 이해가 안가는 부분들이 없잖아 있던게 살짝 아쉬웠습니다. 분명 인트로나 초록에서는 depth gt를 구하기 힘들드했는데 대부분의 실험에서 mono network로 depth gt 있이 학습된 MiDAS 를 쓴다는 점이나 학습데이터가 MfS라고 해서 매우 다양한 데이터 셋 ( COCO, Mapillary, ADE Depth in the wild, DIODE) 등을 다 썼다는 것이 살짝 방향성이 다르구나를 느꼈습니다. 물론 이 논문에서 계속 이야기하는게 간단한 방법으로도 data synthesis 방법론들의 성능을 이길 수 있다는 것이지만 … 음 … 이러면 비교가 너무 어렵지 않나.. 생각이 듭니다.
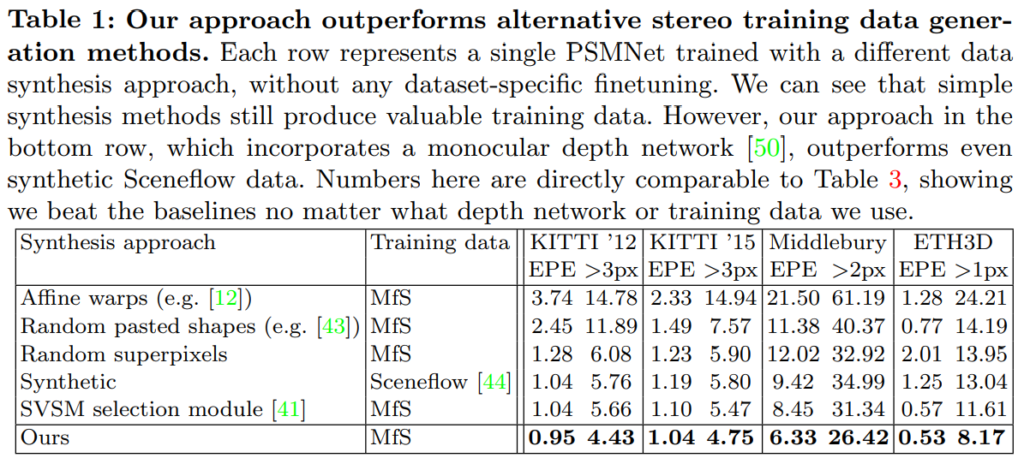
첫번쨰 실험 입니다. 다양한 데이터 생성 방법롣들과 비교했을때 성능을 비교했습니다. 보면 확실한 성능 향상을 볼 수 있습니다.

정성적으로도 확실하게 성능이 ㅎ야상되는 것을 볼 수 있습니다.
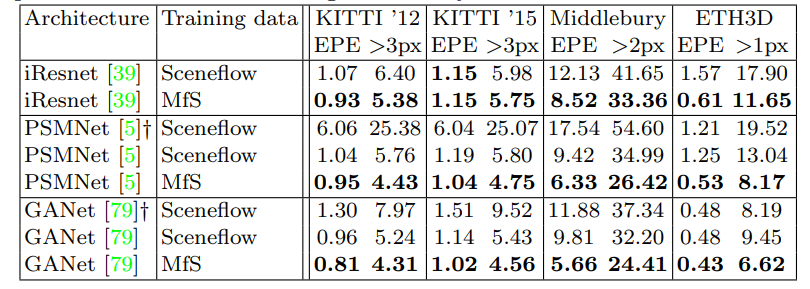
그리고 다양한 stereo model에 적용했을때도 동일한 양상을 보여줍니다.
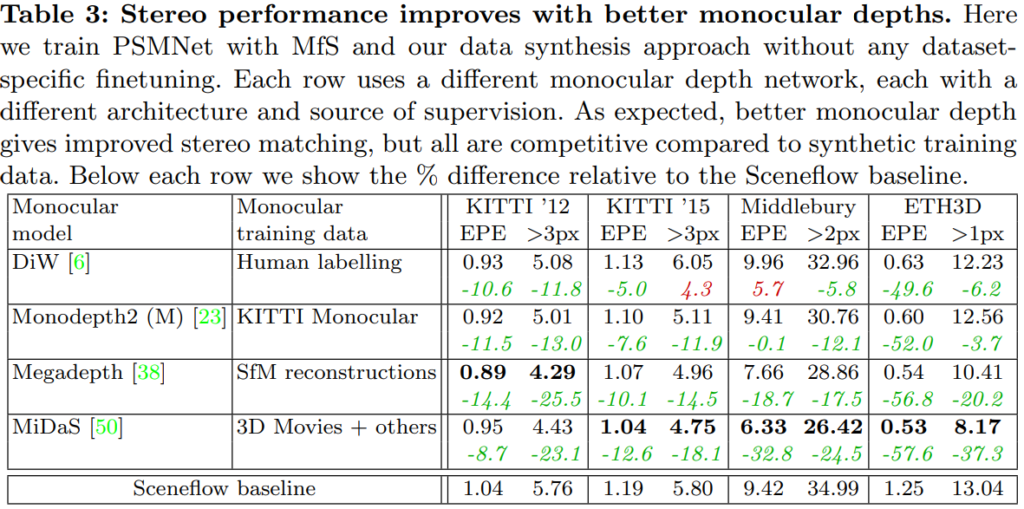
또한 mono network가 바뀌었을때 성능 드랍이 있지만 그래도 기존 방법론 대비 성능 향상을 볼 수 있습니다.
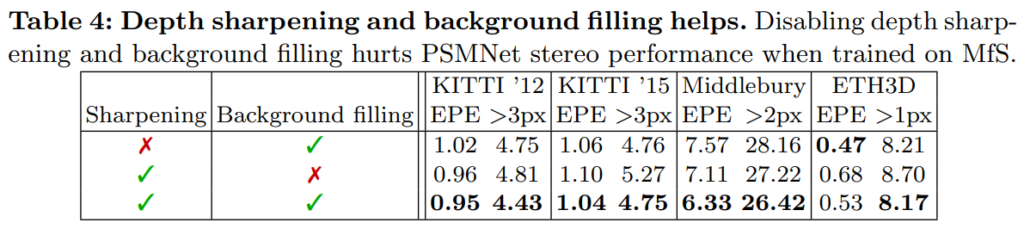
제안한 방법론이 추가됐을때 성능향상표입니다. 아무것도 없을때의 성능도 궁금하긴 한데 그래도 각각이 추가됐을때 성능 향상이 되는 되는 것을 볼 수 있습니다.
리뷰 잘 봤습니다.
제안된 network는 2장의 이미지를 사용해서 depth를 예측하는 stereo depth estimation 으로 보여지는데,
stereo에서 input으로 들어가는 right image는 left에 의해 warping된 image이므로 실질적으로 사용된 real image는 left image 1장이라고 생각됩니다.
헷갈리는(?) 점은,,, 이러한 경우 stereo 인가요 mono 인가요..?
Disparity가 잘못 나온 부분에 대해서 “이 논문에서는 cutmix 와 같이 데이터 중에서 다른 임의의 영상을 붙혀넣어서 성능을 올렸다고 합니다.” 라고 리뷰에 적어주셨는데 그 밑에 그림에는 disparity sharpening?을 통해서 해결했다는 얘기가 나오네요.
Cutmix와 sharpening의 역할이 동일하다고 봐야하는 것인가요? 그리고 Cutmix를 정확히 어떻게 사용했다는 말씀이신가요? 무언가 잘못 예측되는 disparity 부분에 cutmix를 적용해야할 것 같은데, 해당 논문에서는 그런 것과 상관없이 무작위로 적용한 것인가요?