저는 이번에 KCCV 포스터에서 알게된 논문을 리뷰해보려고 합니다. 포스터에서 저자의 말을 들으면서 읭? 하는 부분이 다소 있었는데요. 그 궁금증을 해소하고자 이렇게 논문을 읽게되었습니다.
[ICCV 2021] Self-supervised Product Quantization for Deep Unsupervised Image Retrieval

Introduction
Approximate Nearest Neighbor (ANN) 연구에는 크게 두 가지 방법이 있습니다: (1) Hashing (2) Vector Quantization(VQ). 두 방법론은 모두 의미론적 유사성은 유지하되 이미지 데이터를 compact binary code로 변환하느 것을 목표로 하며, 이진 코드 사이의 거리를 측정하는 방식에 따라 달라진다고 합니다.
이 ANN 연구는 retrieval에서 자주 사용되는 것 같습니다. 주어진 vector space에서 구하고자 하는 query vector와 가장 유사한 vector를 찾는 경우에 사용되는 것 같습니다.
본 논문은 retrieval과 관련된 논문인데요, self-supervised의 대표 방법론이라 할 수 있는 SimCLR에 Product Quantization을 붙여서 제안하는 방법론이라고 할 수 있습니다.
그렇다면 Product Quantization(PQ)은 무엇일까요? 우선 quantization이란 직역하자면 양자화입니다. continuous한 값을 일정 단계로 나누어 discrete 하게 바꿈으로써 데이터를 압축하거나 하는 데 사용된다고 합니다. 그리고 PQ는 이 quantization의 방법 중 하나 입니다. 그리고 처음 서론에서 얘기한 두번째 방법론인 Vector Quantization 역시 quantization의 일부이며, PQ의 친구(?)로 이해하시면 좋을 것 같습니다. 다만, PQ는 VQ에 비해 필요한 메모리가 매우 적고 새로운 쿼리벡터가 들어왔을 대 아웃풋도 빠르게 나와서 quantization 분야에서 흔히 사용된다고 합니다.
따라서 본 논문에서는 이미지 검색 시스템에 있어 라벨링 없이도 의미론적으로 구별할 수 있는 binary code를 발견하기 위한 Quantization 기반 방법론을 제안하였습니다. (기존에는 Unsupervised 기반의 해싱 연구는 있었으나 저자가 아는 한 Quantization 연구가 없었다고 하네요)
Self-supervised Product Quantization (SPQ)
아래 그림중 (a)는 SimCLR를 나타내는 것입니다. SimCLR는 Self-Supervised 의 대표 방법론으로 동일한 이미지에 대해 서로 다른 augmentation을 진행한 뒤, 그 쌍을 positive pair로 두며 배치 내에 있는 나머지 이미지의 augmentation 쌍을 negative pair로 설정한 뒤 contrastive learning을 수행하는 것입니다. 저자가 제안하는 SPQ는 아래 (b)를 의미하며, 기존 SimCLR에서 MLP로 구성된 Projection 파트를 quantization으로 변경하여 빠르고 효율적인 이미지 검색 방법론을 수행하였습니다. 이 때, 유사도를 기존과는 다르게 Projection output끼리가 아닌, 정보량이 더 많은 input과 비교하며 유사도를 측정하였다는 차별점이 있습니다.
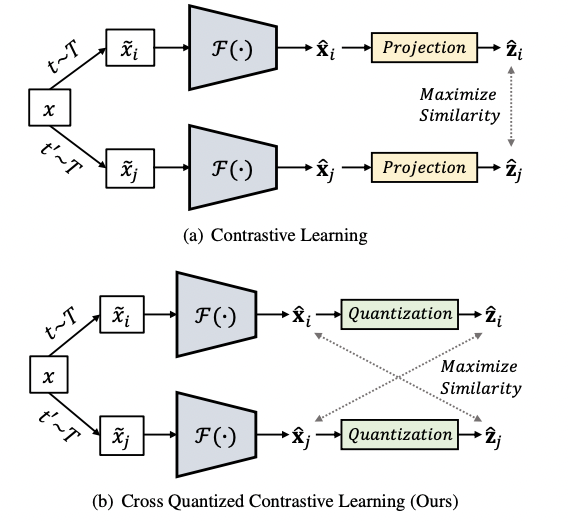
본격적인 설명에 앞서 간단하게 모델의 학습 목표부터 알아봅시다. 우선 이미지 검색 모델의 목표는 input image x에 대해서 binary code인 b를 학습하는 것입니다. 아래 글미과 같이 저자가 제안하는 Self-supervised Product Quantization(SPQ) 의 R에는 compact deep descriptor(feature vector)를 출력하는 feature extractor F(x;\theta_F)가 포함됩니다. SimCLR와 마찬가지로 동일한 이미지에 대해 두 개로 Augmentation을 진행한 뒤, Feature Extractor에 넣어 모델의 feature를 추출하는 단계가 됩니다.
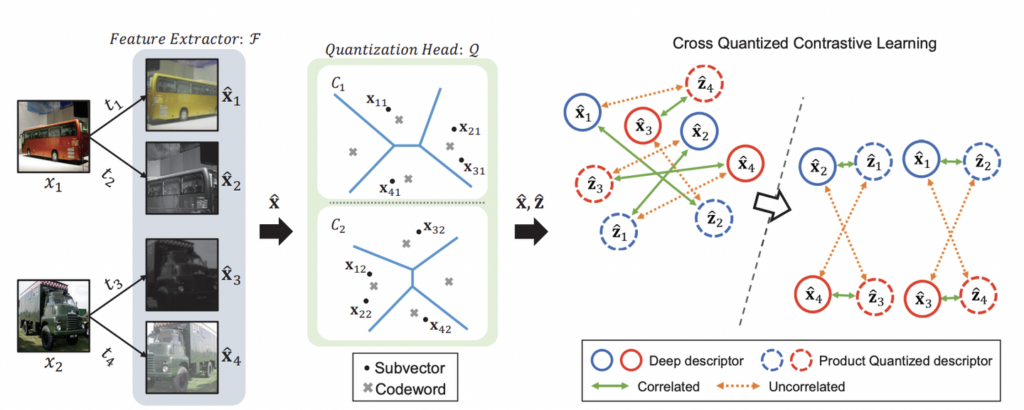
그 다음, 빠른 이미지 검색을 위한 양자화 단계인데요. 이를 위해 Quantization Head Q로 M개의 codebook을 사용하였습니다. 이때 각 Codebook은 K개의 Codework로 구성됩니다. 코드북은 이미지 데이터셋을 나타내는 고유한 특성을 나타낸다고 이해하시면 좋을 것 같습니다. 따라서 코드북에 속하는 각 코드워드는 자주 발생하는 로컬 패턴을 유지하는 것을 목표로 분할된 deep descriptor의 클러스터를 중심으로 계산되게 됩니다.
아래 알고리즘이 SPQ를 요약하여 나타냅니다.

우선 SimCLR 처럼 하나의 이미지에 대해 서로 다른 transformation을 수행합니다.
다음, Feature extractor에 태워서 \hat{x}_{2n-1}, \hat{x}_{2n}를 구성합니다. 다음으로 Quantization Head에 각각을 태워 descriptor \hat{z}_{2n-1}, \hat{z}_{2n}를 구성합니다. Quantization Head에 대한 수식은 아래와 같이 구성됩니다. (\lambda_q는 소프트맥스 입력을 스케일링하는 파라미터입니다) 아래 수식처럼 sub-quantization descriptor는 C_m에 속하는 codeword의 exponential weighted sum으로 간주되는 것이죠. 또한 코드북의 전체 코드 워드는 양자화된 출력의 근사치로서 사용되며, 가장 가까운 코드 워드가 가장 큰 영향을 주게됩니다.
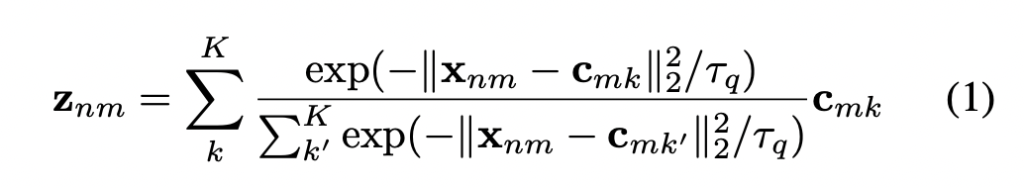
이제 discriptor와 codewords를 함께 학습하기 위해 cross quantized contrastive learning을 제안합니다. 즉, Quantization head의 input과 output을 비교하는 과정이라고 보면 되는데요. 이렇게함으로써 일반화된 성능을 향상시키고자 하였습니다.
Retrieval을 위해서는 이미지에대해 Feature extractor에 태운 뒤, 가장 가까운 코드워드를 구하기 위해 거리를 계산하여 검색합니다. 모든 이미지에 대해 각 코드워드 사이의 거리를 계산하고 하위 코드들끼리 연결되며 이진 인코딩된 검색 데이터베이스가 구축됩니다. 거리로는 유클리드 거리가 사용되며, 사전 계산된 룩업 데이블을 구성하기 위해 모든 코드북의 하위 벡터와 모든 코드워드 사이의 유사성 역시 유클리드 거리가 사용됩니다.
Experiments
저자는 성능 확인을 위해 CIFAR-10, FLICKR25K, NUS-WIDE 데이터셋을 사용하여 실험을 진행하였습니다.
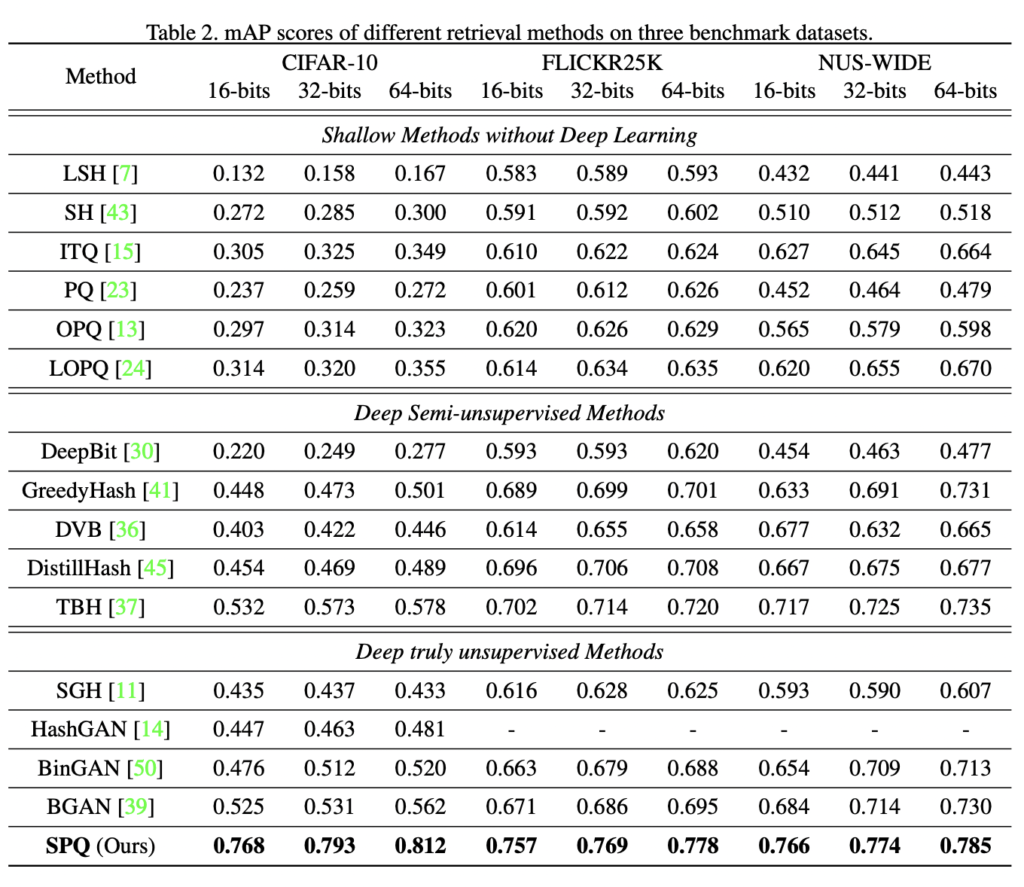
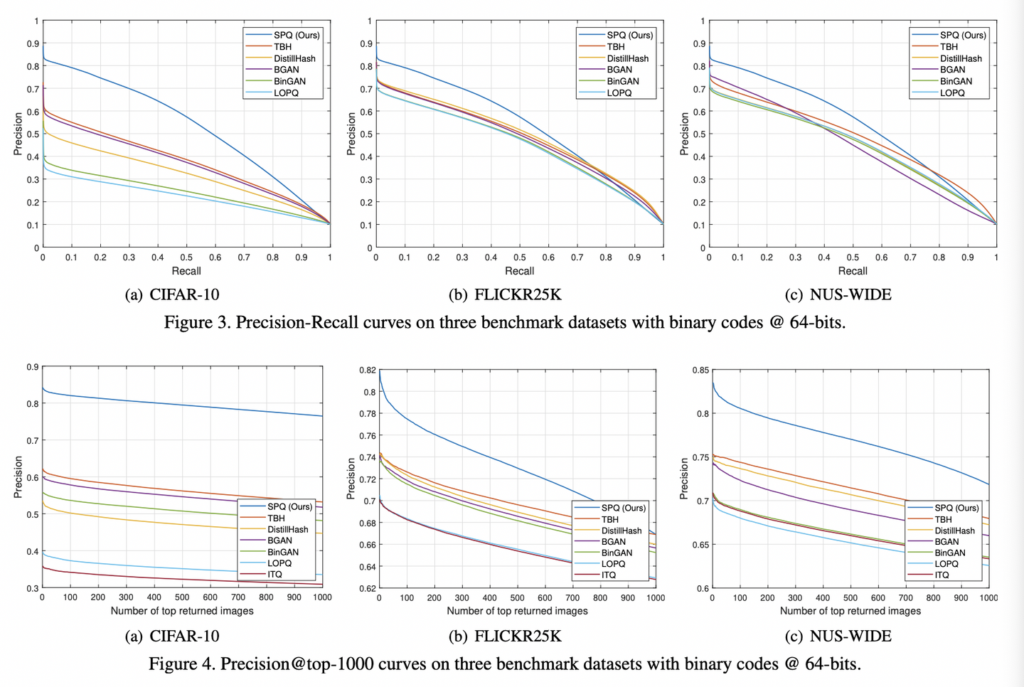
세개의 서로 다른 이미지 검색 데이터셋에 대한 mAP 결과는 아래 테이블에 나열되어 있고, SPQ가 모든 비트에서 기존 방법론을 크게 이길 수 있었다는 것을 보여주었습니다. 또한 아래 Figure 3, 4역시 SPQ가 가장 합리적인 방법론임을 알 수 있다고 합니다.
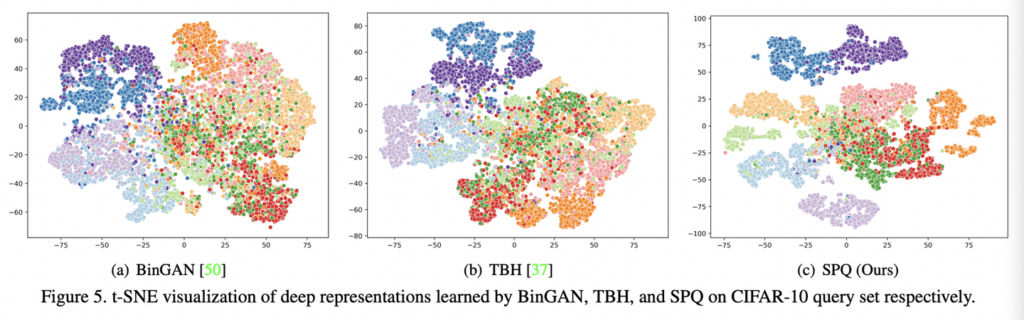
또한 아래 그림처럼 t-SNE를 사용하여 확인한 벡터 분포를 살펴본 결과입니다. BinGAN과 SPQ가 완전한 unsupervised 환경에서 학습이 되었습니다. 그럼에도 불구하고, SPQ는 색상이 다른 클래스 레이블을 나타내는 곳에 데이터 샘플을 가장 몇확하게 구분해냈습니다. 또한 그에 따른 정성적 결과 역시 그 아래 첨부하였습니다. SPQ는 개 검색 결과에 고양이가 나타나는 것과 같이 시각적으로 유사한 내용을 가진 이미지들도 검색 결과로 발생되었다고 합니다.

Conclusion
본 논문은 새로운 self-supervised image retrieval인 SPQ를 제안하되, 새로운 PQ를 채택하여 이미지 검색을 위한 최초의 end-to-end unsupervised framework를 구축하였습니다.
Image retrieval에서는 generality도 중요시 하게 여겨 cross-domain에서 학습 및 평가 (ex. cifar 학습->nus wide 평가)를 포함하는 경우가 많은 것으로 알고 있는데 혹시 이것에 대한 실험 결과는 따로 없나요?!
몇가지 질문이 있어 댓글 남깁니다.
1. 본 논문은 Quantization을 위해 Self-supervised 방식을 제안한건가요? Self-Superivsed Learning 기법을 고도화 하기 위해 Quantization을 도입한건가요?
2. 코드북을 만들때 사용하는 Clustering 방식은 K-means 인가요?