
오늘 리뷰할 논문은 ICCV 2021년에 게재된 ‘Revealing the Reciprocal Relations between Self-Supervised Stereo and Monocular Depth Estimation’ 이라는 논문입니다.
여태까지와 마찬가지로 Self-supervised monocular depth estimation에 관한 논문인데, 여기에 추가적으로 pseudo label을 사용한 knowledge distillation 방법론이 살짝 추가된 논문이라고 보시면 됩니다.
현재 한대찬 연구원과 같이 본 논문을 baseline으로 잡고 실험을 하려고 진행중인데, 코드가 제공되어 있지 않고 method 설명도 그렇게 까지 자세하지 않은지라 원복을 하는데에 있어서 많은 난관을 겪고 있습니다.
우선 각설하고, 리뷰 시작하겠습니다.
Abstract
현재 존재하는 여러 방법론들은 보통 depth estimation을 진행할 때에 stereo 또는 mono 둘 중 하나에 초점을 두고 연구를 진행하곤 합니다. 본 논문에서는 stereo와 mono에 대한 depth estimation 성능을 모두 개선시켰다는 것에 contribution을 두고 있습니다.
구체적인 방법론에 앞서 전체 구조에 대해 간략하게 설명 드리겠습니다.
자세한 내용은 아래 Method에서 모델 그림과 함께 더 자세하게 설명 드릴 예정이니
이해가 잘 안되시는 분들은 넘어가셔도 무방합니다.
- self-supervised 방식으로 stereo image pair에 대해 학습을 진행하는 StereoNet이 존재합니다.
또한 mono image 에 대해서 학습을 진행하는 SingleNet 이 존재합니다. - occlusion-aware distillation (OA Distillation) 이라는 모듈을 제안합니다.
StereoNet이 생성한 depth map을 pseudo label 삼아서 SingleNet이 학습을 하게 되는데,
생성된 pseudo label 중에서 occluded 되지 않은 영역만을 사용하게 됩니다.
occlusion 영역을 판단하는 것은 occ map 이라는 마스크가 하게 되는데, 이에 대해서는 뒤에서 자세하게 설명 드리겠습니다. - Occlusion-aware fusion module(OA Fusion) 이라는 모듈을 설계합니다.
앞서 생성된 occ map이 주어지면, StereoNet과 SingleNet에서 추정된 depth를 fusion해서 더 안정적인 depth를 생성하고, fusion된 depth를 새로운 pseudo label삼아 StereoNet을 다시 한번 학습 시킵니다.
이번 단계에서는 supervised 방식으로 StereoNet을 학습 시키는 것입니다.
Introduction
앞서 말씀드린 것처럼 최근 self-supervised depth estimation 분야에서는 stereo와 mono 각각에 대해서 초점을 두기 때문에, 이들간의 상호관계에 대해서는 무시가 된다고 저자는 말합니다.
이에 더불어 Stereo와 mono 각각의 장,단점이 존재하기 때문에 이를 잘 활용하고자 했습니다.
각각의 장단점은 아래와 같습니다.
우선 Stereo Matching 방식의 경우, left와 right image에서 각각 좌우 patch 단위로의 local similarity 를 비교함으로써 network를 학습 시킵니다.
이처럼 좌, 우 이미지를 직접적으로 비교하기 때문에 단일 view만 볼 수 있는 left boundary 또는 occlusion 영역의 경우에 부정확한 depth가 예측될 확률이 높습니다.
이에 반해 Monocular Depth Estimation의 경우 input image에서 뽑은 feature 내부의 appearance나 semantic knowledge에 의존합니다. 이러한 이유 때문에 occlusion 되는 영역의 경우에 한정해서는 Monocular 방식의 depth 정확도가 더 높습니다.
위에서 ‘occlusion 되는 영역의 경우에 한정해서는‘ 이라는 표현을 썼는데,
occlusion 영역에서 성능이 mono가 더 높음에도 불구하고, 이미지 1장에 대한 전체적인 depth 예측 정확도는
stereo 방식이 더 좋다는 뜻입니다.
이처럼 Stereo와 mono 는 각각의 장, 단점이 존재하고
저자는 이를 knowledge distillation 방식을 사용하여 모델을 제안하였습니다.
그림하나 없이 너무 글만 주저리주저리 쓴 거 같네요,,,ㅎ
아래 Method에서 그림과 함께 방법론에 대해 자세하게 말씀 드리겠습니다.
Method
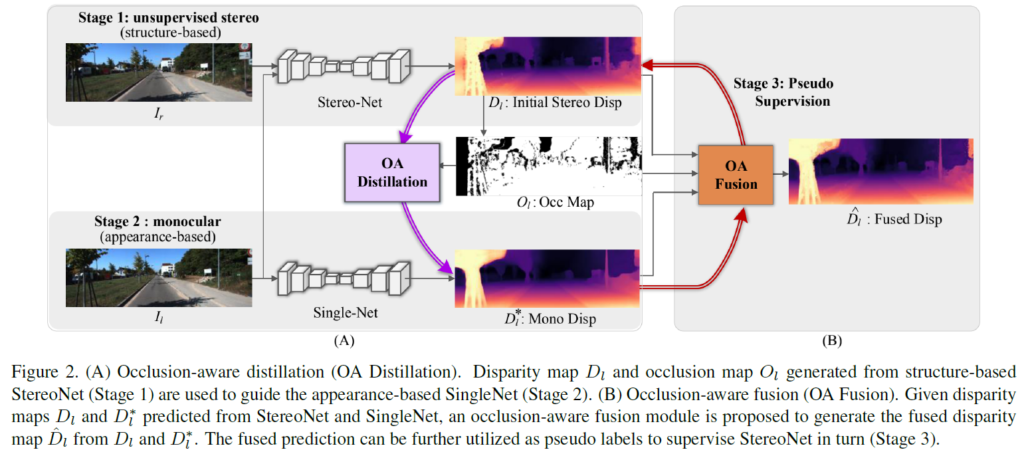
전체적인 파이프라인은 크게 3개의 stage로 구성이 됩니다.
Stage 1 – StereoNet
StereoNet은 말 그대로 stereo image pairs로 학습이 되는 network를 말합니다.
gt가 없기 때문에 network는 left와 right image에서 각각 patch 끼리의 correspondence를 학습하게 되고,
patch들 사이의 유사성 비교를 수행하기 때문에, 저자는 이를 structure-based learning이라고 표현했습니다.
위에서 말씀드린 것 처럼 StereoNet에서는 patch 사이의 유사성을 학습하기 때문에,
occluded pixel이나 left boundary 처럼 single view에서만 보이는 영역의 경우에는 예측이 잘 되지 않습니다.
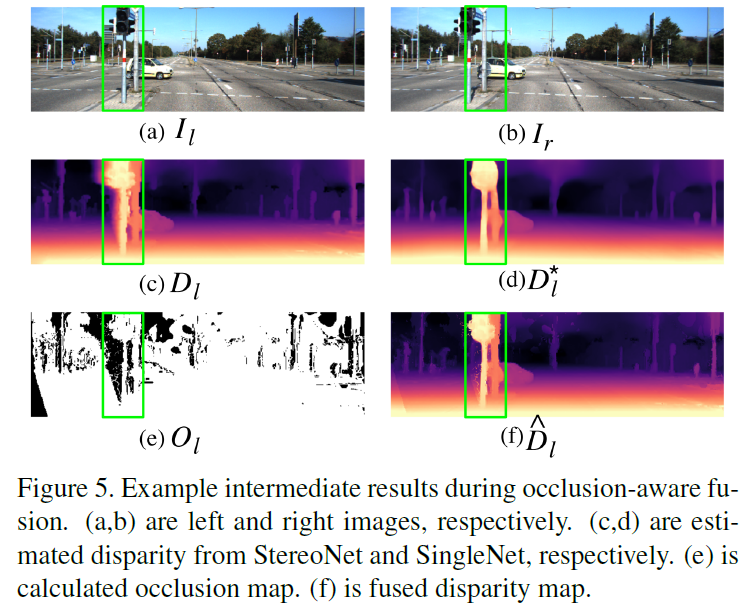
어찌저찌 StereoNet에서 stereo disparity map이 예측이 되면, 이를 기반으로 occlusion map을 구할 수 있습니다.
위 그림에서 O_l 로 표시된 0과 1로 이루어진 binary mask가 occlusion map에 해당합니다.
이 occlusion map은 StereoNet이 예측한 disparity map 중에서 occlusion 영역에 해당하는 부분을 필터링 해서 걸러주는 역할을 수행하게 됩니다.
한마디로 말해, occlusion 영역이 아닌 일반적인 영역에서의 정확한 depth만을 SingleNet에게 pseudo label로 주고자 하는 역할이라고 생각하시면 됩니다.
Stage 2 – SingleNet
StereoNet이 예측한 disparity map은 occluded pixel이나 left boundary 영역에서의 예측이 정확하지 않습니다.
그래서 occ map을 통해 필터링을 진행한 disparity map을 SingleNet의 pseudo depth label로 사용하게 됩니다.
저자는 이러한 방식을 occlusion-aware fusion이라고 하였습니다.
위 모델 사진에서 OA Distillation 이라는 보라색 사각형이 이에 해당합니다.
Stage 3 – Pseudo Supervision
앞서 말씀드렸지만 다시한번 말씀드리자면 Stereo와 mono 둘 모두 각각의 장단점이 존재합니다.
저자는 이 둘의 장점을 융합하고자 했습니다.
occlusion map인 O_l 를 사용해서 stereo와 mono가 각각 예측한 disparity를 융합시킵니다.
occlusion된 영역같은 경우 mono의 disparity를 , occlusion이 아닌 영역의 경우 stereo의 disparity 를 사용하는 것입니다.
이렇게 fuse 된 disparity map 을 \hat{D_l} 이라고 표기하였고, \hat{D_l} 을 StereoNet의 pseudo label로 사용해서 StereoNet을 supervision 하는 방식으로의 성능도 추가적으로 리포팅 하였습니다.
아래에서 각 stage에 대한 추가적인 설명과 loss에 대해서 설명 드리겠습니다.
Stage 1 – Self-supervised Stereo Branch
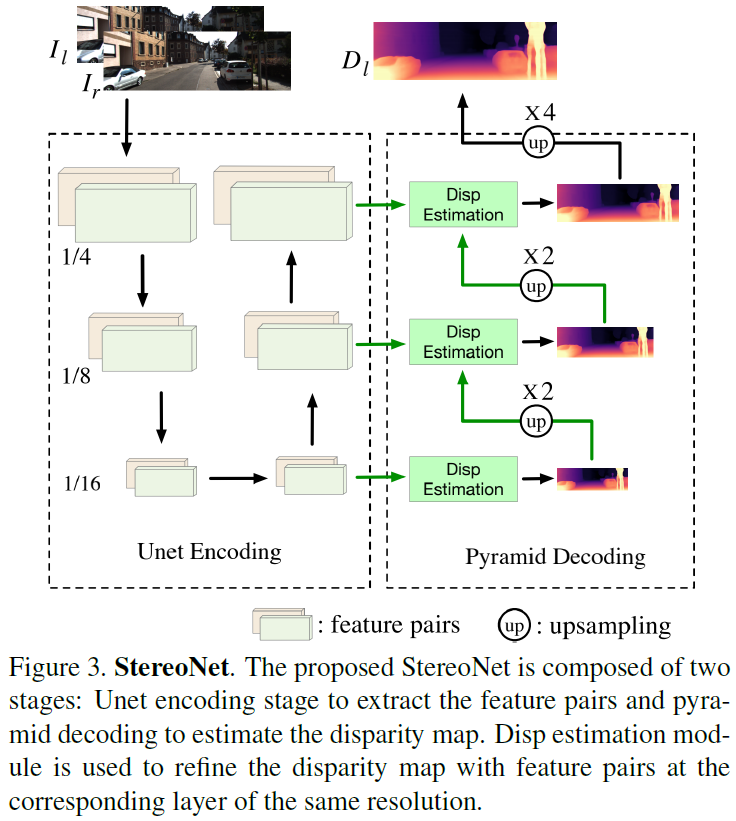
본 논문에서는 StereoNet으로 Unet 구조를 사용하였습니다.
기존 Unet의 encoder 부분을 pyramid 구조에서 Unet으로 변경하였습니다. 그리고 이러한 구조 변경을 통해서 미세한 성능 향상을 보였다고 합니다. 뒤쪽의 실험 부분에서 해당 부분에 대한 성능 향상을 리포팅합니다.
어쨋든 StereoNet은 Input으로 2장의 left-right image pair를 받고,
output으로 disparity map D_l 을 뱉게 됩니다.
이와 같은 StereoNet을 training 할 때에는 아래와 같은 photometric loss를 사용하게 됩니다.
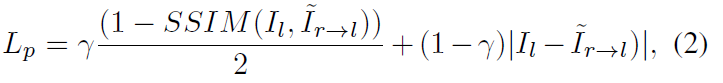
이에 추가적으로 보통 depth 논문에서 많이 사용하게 되는 smoothness라는 loss가 있는데,
이는 disparity map의 object 경계 부분에서의 급격한 변화를 방지해 줍니다.
식은 아래와 같습니다.
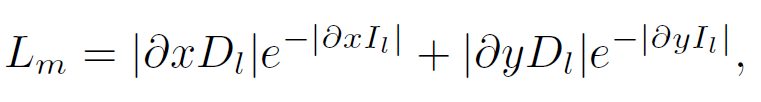
저자는 occlusion영역과 같은 곳에서는 StereoNet이 부정확한 depth 를 예측한다고 하며,
이에 대한 해결책으로 occlusion map O_l 을 설계합니다.
해당 식은 아래와 같습니다.
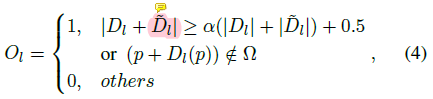
이 식은 optical flow 논문에서 비롯된 식입니다.
위 식에서 D_l은 left disparity map을, \hat{D_l}는 warped된 left disparity map을 의미합니다.
옴 문자는 image boundary를 의미합니다.
결과적으로 O_l=1 인 경우에 occlusion 영역에 해당하는 부분인 것이고,
O_l=0 인 경우가 occlusion되지 않은 영역을 의미합니다.
해당 occlusion map을 사용해서 설계한 loss 식은 아래와 같습니다.
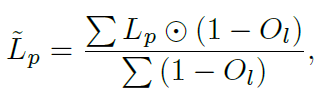
위 식에서 L_p 는 위에서 설명드린 photometric loss를 의미하고,
동그라미 문양?? 은 pixel-wise multiplication을 의미합니다.
StereoNet에서 계산된 photometric loss 중에서 occlusion 영역에 해당하는 pixel은 loss 계산에 반영하지 않고,
occlusion이 아닌 영역에 해당하는 pixel만 loss 계산에 반영하겠다는 의미입니다.
stage 1의 최종 loss는 위에서 설명드린 smoothness loss와 이를 결합한 \hat{L_p}+L_m 입니다.
Stage 2 – Distilling Monocular Branch
mono 모델인 SingleNet은 single image I_l 로 부터 diparity map {D_l}^* 을 예측합니다.
StereoNet은 2장의 이미지를. SingleNet은 1장의 이미지를 받는것으로 미뤄보았을때
당연히 예측된 disparity map의 성능은 StereoNet이 더 좋을 것이라고 생각할 수 있습니다.
물론 성능적인 지표로도 이 추측이 증명되구요.
이 때문에 저자는 StereoNet이 예측한 disparity map을 mono 에게 distillation 하는 방식을 사용합니다.
하지만 StereoNet같은 경우엔 occlusion 영역에서의 성능이 좋지 않으므로 이를 occlusion map을 통해 필터링 한 뒤 distillation 하는 과정이 필요하겠죠?
이를 반영한 SingleNet의 distillation loss는 아래와 같습니다.
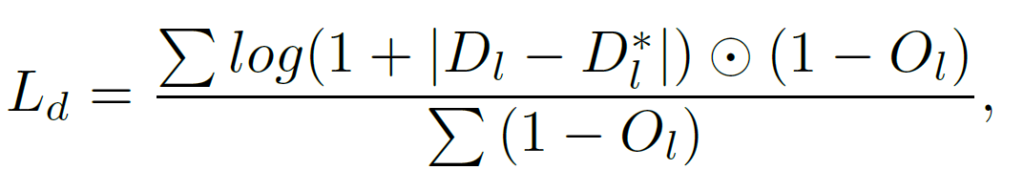
D_l 은 stage 1 에서 pretrained된 StereoNet이 예측한 disparity map을 의미하고,
{D_l}^*은 SingleNet이 예측한 disparity map을 의미합니다.
O_l=0, 즉 occlusion이 아닌 영역에서 D_l과 {D_l}^*의 L1 loss에 log를 씌운 loss가 계산되는 것을 알 수 있습니다.
stage 2의 최종 loss는 위에서 설명드린 smoothness loss와 이를 결합한 L_d+L_m 입니다.
Stage 3 – Distilling Stereo Branch
앞서 말씀드린 것 처럼 Stereo와 mono는 각각의 장단점이 존재합니다.

위 그림에서도 이를 살펴볼 수 있습니다.
D_l 이 StereoNet이 예측한 disparity map이고,
{D_l}^* 이 SingleNet이 예측한 disparity map 입니다.
파랑색 네모 박스 영역의 경우엔 D_l이 {D_l}^* 보다 더 디테일이 살아 있는 모습을 볼 수 있습니다.
하지만, 빨간색과 초록색 박스 영역처럼 occlusion이 되는 영역의 경우 SingleNet의 예측이 더 좋다는 것을 정성적으로 볼 수 있습니다.
그리하여 저자는 stage 3 에서 앞서 예측한 stereo의 D_l과, mono 에서 예측한 {D_l}^*을 fusion 하는 방식을 고안해냅니다.
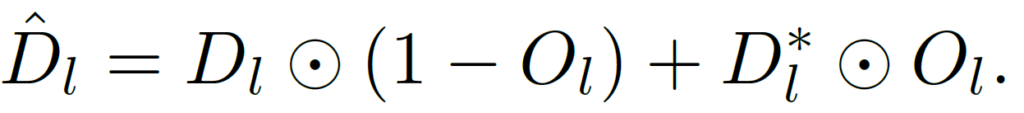
fusion 하는 식은 위 처럼 매우 단순합니다.
저자는 fusion된 disparity map을 \hat{D_l} 이라고 표현 하였고, 아래와 같이 정성적인 경과도 리포팅 하였니다.
여기에 더해, \hat{D_l} 을 사용해서 StereoNet을 추가적으로 학습시키는 방식을 설계합니다.
이를 통해서 StereoNet의 성능을 더 극한으로 끌어 올릴 수 있다고 하였고, 이를 StereoNet-D라고 하였습니다.
사용된 loss는 아래와 같습니다.
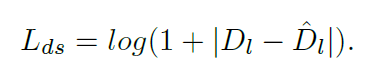
D_l과 \hat{D_l}를 가지고 단순하게 logistic L1 loss를 계산 하였습니다.
단순히 disparity map을 fusion한 \hat{D_l} 보다 더 좋은 성능을 낸다고 하였습니다.
실험 단계에서 성능 리포팅도 존재합니다.
Experiment
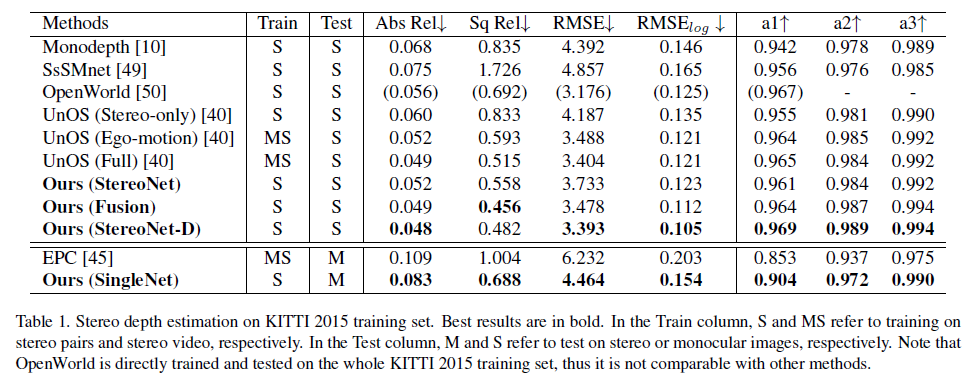
Stereo depth estimation에서의 정량적인 결과는 위와 같습니다.
위의 (Fusion) 방식은 Stereo와 mono의 disparity 를 fusion한 것이고,
(StereoNet-D) 방식은 fusion한 disparity map을 pseudo label삼아 또 다시 training을 진행 한 결과 입니다.
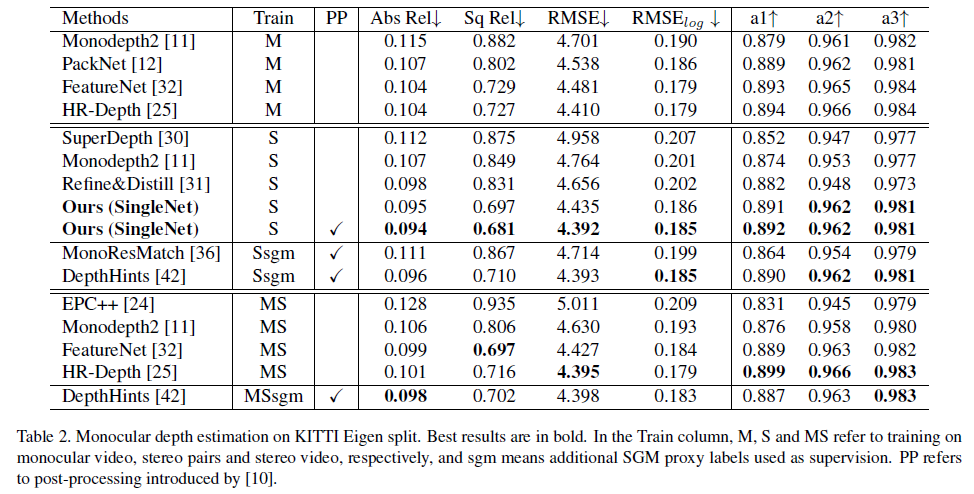
monocular depth estimation 방식은 위와 같습니다.
mono 방식에서도 성능적으로는 SOTA의 성능을 달성한 것을 볼 수가 있습니다.
하지만 성능은 높지만, 본 논문과 다른 방법론 사이에는 입력 해상도가 다르다는 차이점이 존재합니다.
본 논문에서의 input 해상도는 1024 X 320 이지만, Stereo의 UnOS 같은 경우는 832 × 256 를 input 해상도로 합니다.
따라서 이 성능비교가 과연 공정한 비교인지는 잘 모르겠습니다.
그리하여 저는 이 논문을 읽을때에 occlusion map과 distillation 이라는 방법론적인 관점에 조금 더 초점을 두고 읽었던 거 같습니다.
Conclusion
본 논문의 접근방식과 occlusion map이라는 추가적인 방법론이 마음에 들었습니다.
Stereo와 mono 각각의 장단점을 분석하고 이들의 장점을 결합하는 방식으로 모델을 설계하는 흐름이 좋았고,
이를 위해 occlusion map이라는 mask를 설계한 방법론도 참신하다는 생각이 들었습니다.
본 논문을 baseline으로 잡고있는 현재… 빠르게 원복이 되면 좋겠습니다.
그럼 리뷰 이만 마치겠습니다.