해당 논문은 CVPR2022에 통과된 논문이며 이번 KCCV2022에서 포스터로 보게 되어 읽게 된 논문입니다. 아마 당분간 x-riview는 kccv에서 봤던 논문들 위주로 작성될 것 같습니다.
Intro
해당 논문은 이벤트 카메라 두대로 깊이 추정을 하자는 논문입니다. 여기서 이벤트 카메라는 일반적인 RGB 카메라와는 조금 다른 카메라로 이벤트 카메라에 대한 간단한 소개부터 다루고 가겠습니다.
이벤트 카메라는 사람의 눈을 잘 모델링한 카메라라고 합니다. 이렇게 들으시면 일반적인 RGB 카메라가 사람의 시각 시스템을 그대로 모델링한 것 아닌가? 싶기도 하실텐데, 여기서 말하는 사람의 눈의 기능이란 시각적 변화를 기반으로 주변 환경을 인식한다는 개념입니다.
이벤트 카메라는 현재 프레임과 이전 프레임 사이의 조도 변화를 파악하여 주변을 촬영합니다. 즉 카메라가 매번 어떠한 트리거에 따라서 촬영되는 것이 아닌, 조도의 변화를 인지할 때(즉 이벤트가 발생했을 때) 비로서 촬영을 한다는 것이죠.
이러한 이벤트 카메라는 상당히 높은 FPS를 보유하고 있으며 또한 빛을 취득할 수 있는 range가 상당히 넓기 때문에 상당히 세밀한 조도 변화도 민감하게 촬영이 가능하다고 합니다. 그리고 이러한 특성 덕분에 모션 blur나 급격한 조도 변화(터널 입구에서 막 들어가거나 반대로 터널에서 출구로 빠져나올 때 눈부심 등)에 상당히 강인하다는 것이 이벤트 카메라의 장점입니다.
그런데 이제 이러한 이벤트 카메라도 단점은 명확하게 존재하게 됩니다. 먼저 이벤트카메라는 아까 말씀드렸다시피 일반적인 카메라처럼 프레임 하나에 모든 장면이 포착되는 게 아니라, 프레임들간의 조도 차이를 통해 장면을 포착한다고 말씀드렸습니다.
즉 이벤트 카메라는 하나의 프레임이 아닌 여러개의 프레임을 쌓아야만 이미지를 만들 수 있다는 것입니다. 그리고 이러한 이벤트 스트림을 얼만큼 stack해서 사용하느냐에 따라서 이벤트 카메라가 담을 수 있는 정보량과 특성이 달라지게 됩니다.
예를 들어서, 이벤트 카메라의 스트림을 길게 잡게 된다면 (large stack) 이벤트 카메라에 담겨있는 정보는 많겠지만, 때로는 조도의 변화가 클 때(이를 달리 생각하면 물체의 움직임이 빠르고 큰 경우) 너무 많은 양의 이벤트가 발생하고 이것들이 누적되어 상당히 노이즈한 결과가 생성됩니다.
반대로 stream stack이 너무 작으면 움직임 또는 조도의 변화량이 작을 경우 취득되는 정보량이 줄어든다는 단점이 존재합니다.

그래서 저자는 concentration network라는 것을 새로 제안하여 너무 과잉되는 정보나 누락되는 정보들을 잘 보완해줄 수 있는 새로운 네트워크를 제안합니다.
또한 기존의 event camera는 현재 프레임 기준 과거의 프레임 정보들을 스택하여 최종 영상을 만들게 되는데 이러한 과거 프레임 정보 외에도 미래 정보를 활용할 수 있으면 더 풍부하고 퀄리티 좋은 정보들을 종합하여 활용할 수 있게 됩니다.
하지만 현실적으로 inference 관점에서 미래 정보는 활용할 수가 없기 때문에, 모델 학습 때 과거-미래 정보를 과거 정보의 feature에 distilation하는 방식으로 학습하는 loss를 제안하였다고 합니다.
이정도로 해당 논문의 contribution을 나눌 수 있을 것 같으며 본격적인 내용은 밑에서 다루겠습니다.
Overall Framework
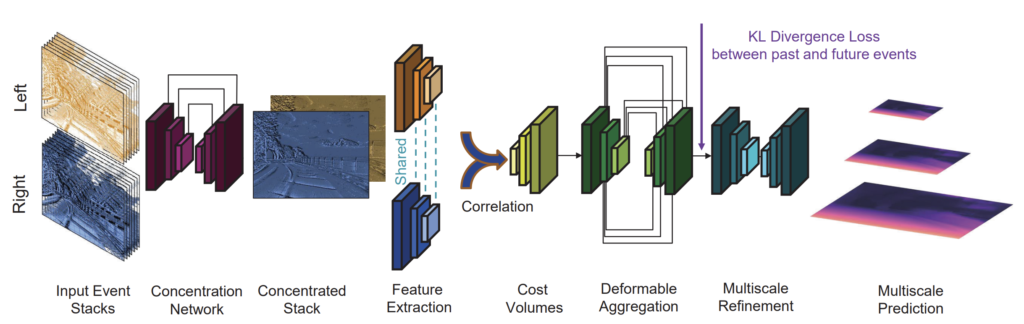
일단 좌우 event camera의 stream들이 stack되어서 논문에서 제안하는 Concentration network를 통과하게 됩니다. 그렇게 되면 멀티 프레임 정보가 통합된 1ch output map이 생성이 되며 해당 map을 이제 기본적인 stereo matching network를 통하여 disparity map을 생성하기 위한 feature를 추출합니다.
대충 그 과정이 deformable aggregation이라고 보시면 되고 그 후에 Multiscale refinement 과정을 들어가기 전에 past & future event 정보와 past 정보간에 KL divergence loss를 계산하여 학습을 따로 합니다. 그와 동시에 multi-scale refinement 과정을 거쳐서 생성된 multi-scale prediction 역시 실제 GT depth와 supervised 방식으로 학습합니다.
Concentration Network
Concentration Network는 상당히 단순합니다. U-net 구조의 Encoder-Decoder로 구성이 되어 있으며 네트워크의 출력으로는 입력 데이터와 동일한 해상도 및 채널을 가지는 attention score를 계산하게 됩니다. 이 계산된 weight를 pixel-wise softmax operation 연산을 통해 수학적으로 확률적인 의미를 부여한 뒤 이를 Concentration network의 입력으로 넣었던 density event input에 weighted sum을 해주게 됩니다.
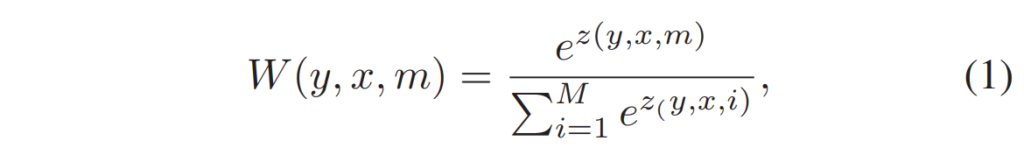
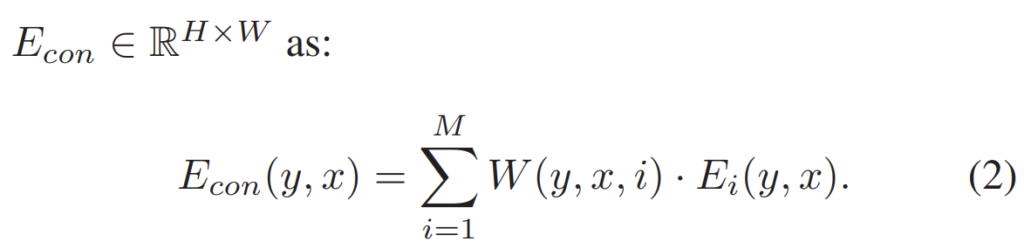
수식으로 표현하면 위와 같이 표현할 수 있습니다. 여기서 E는 density event input을 의미하며 W는 Concentration Network의 출력에서 구한 z score를 채널 축으로 softmax하여 계산한 것입니다.
Depth Estimation Network
이렇게 Concentration까지 마친 event image는 이제 기본적인 stereo depth network의 framework을 따르게 됩니다. 이 부분에 대해서는 저자가 기존의 RGB domain에서 많이 활용하는 방법을 그대로 활용하였기에 따로 디테일한 설명이 없습니다.
그냥 대충 feature extraction module, cost volume module, deformable aggregation module 그리고 multi-scale refinement module 형식으로 구성이 되어있다고 합니다.
Knowledge Transfer from Future Events
해당 내용은 제가 앞에서도 말씀드린 concentrated event stack이 아무리 정보를 잘 담았다고 하더라도 결국 과거 정보들 만으로는 깊이를 정밀하게 예측하기에는 정보량이 부족하다고 저자는 판단하였습니다.
그래서 과거 정보 뿐만 아니라 미래 정보들도 함께 활용하면 더 좋지 않을까 라고 판단하였으며 실제로도 미래 정보를 함께 concentration하게 되면 더 좋은 깊이 추정 결과를 얻을 수 있었다고 합니다.
하지만 학습 때는 미래 정보를 활용할 수 있더라도 추론 시에는 미래 정보라는 개념을 활용할 수는 없기 때문에, 학습 때만 미래 정보를 활용할 수 있도록 미래 정보를 과거 정보에게 distillation하는 방식을 활용했다고 합니다.
딱히 뭐 대단할 것은 없이 그냥 past&feature 정보를 합쳐서 depth module에 태우고 나온 feature map과 past 정보만을 depth module에 태우고 나온 feature map 사이에 KL loss를 계산한 것입니다. 참고로 past&feature feature map의 경우 사전에 미리 학습해두고 past 정보에게 distillation하는 2 stage 방식으로 학습을 진행하였다고 합니다.(논문에는 이런 내용이 없던디…)
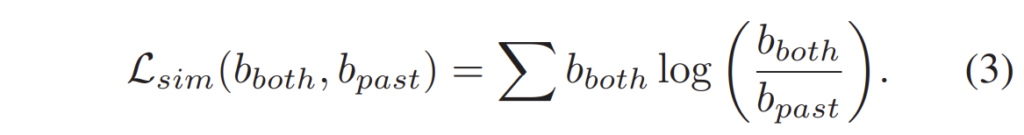
여기서 b_{past}, b_{both} 는 각각 past 정보만을 통해 취득한 feature map과 past & future 정보를 통해 취득한 feature map을 각각 의미합니다.
그리고 이 둘에 대한 KL loss를 계산한 것이 수식 (3) 이구요. 정말 간단합니다.
Objective Function
모델 학습은 supervised learning으로 진행되기 때문에 실제 GT disparity와 추론한 disparity 간에 smooth-L1 loss를 계산하게 됩니다.
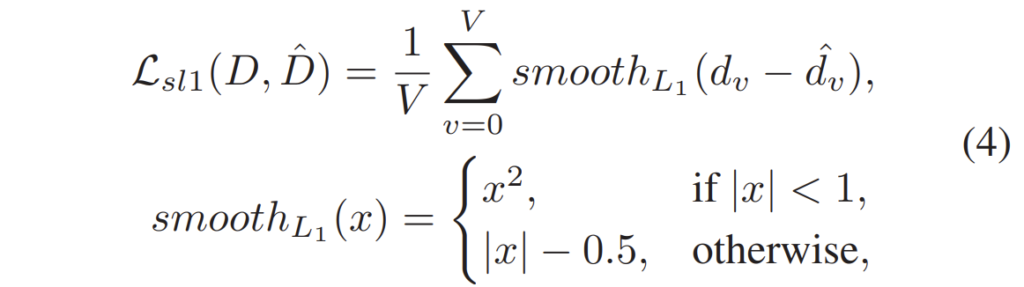
Experiments
그럼 실험결과 빠르게 정리하고 마무리 짓겠습니다. 실험에 사용한 데이터 셋은 DSEC dataset으로 이벤트 카메라와 RGB 카메라를 함께 촬영된 데이터 셋입니다.
평가 메트릭으로는 MAE, 1PE, 2PE, RMSE가 있는데 MAE와 RMSE는 추론된 결과와 GT 간에 에러라고 이해하시면 되고, N-PE의 경우 실제 GT 픽셀과의 disparity error가 N 보다 더 큰 값의 퍼센테이지를 나타낸 것으로 N보다 더 큰 애들이 많을수록 해당 지표 값도 같이 커지게 되는 것입니다.
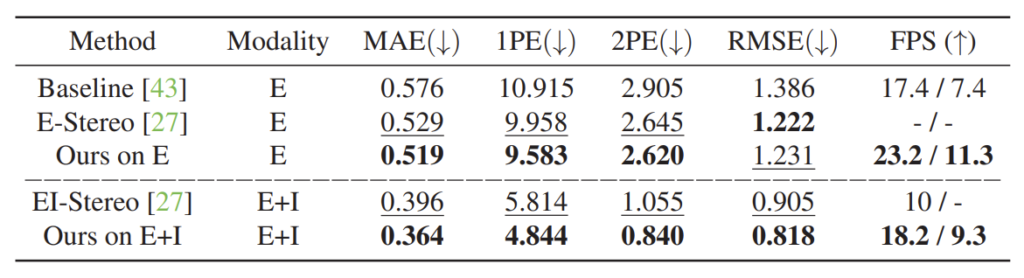
위에 표는 정량적 결과 입니다. 위에는 이벤트 카메라만을 활용한 것이며 아래 두 컬럼은 event + intensity 카메라를 모두 활용했을 때 결과입니다. 비교 방법론이 상당히 작은데, 이는 이쪽 연구가 많이 부족하다는 것을 보여주는 것이 아닐까 생각이 듭니다.
그리고 event camera만을 활용하였을 때 보다 Event + Intensity camera를 모두 활용하였을 때 성능 향상이 많이 큰 것을 볼 수 있는데, 여기서 논문에는 Intensity camera만 활용했을 때 성능은 보여주지 않더군요.
저는 Event + I가 I보다 훨씬 좋아야만 event camera를 쓰는 것이 유용하다고 판단이 되어 이 부분에 대해 KCCV에서 저자에게 여쭤봤는데 아쉽게도 I만 활용했을 때 결과가 E+I보다 살짝 더 낮다고 하네요. 즉 E+I와 I의 성능 차이가 별 반 차이가 없다는 뜻입니다.
이에 대해서 저자분은 아무래도 event camera가 강인하게 동작하려면 차량의 moving effect가 크거나 조도의 변화가 큰 장면들이 많아야하는데, 아쉽게도 해당 데이터 셋에서는 그러한 데이터들이 많지 않아서 event camera 덕분에 성능 향상이 일어날만한 곳이 별로 없다고 합니다.
그래서 제가 추가로 night scene도 있냐고 여쭤봤는데 해당 데이터 셋에서 밤 낮이 모두 함께 존재한다고 합니다. 그렇다는 것은 event camera가 night에서 강인하게 동작할 줄 알았는데 사실은 RGB와 별 차이가 없는 것이 아닌지 아니면 night data의 개수가 터무니 없이 적거나 혹은 생각보다 주변 환경이 밝거나 한 것 같은데… 개인적으로 Thermal의 대안책이 될 수 있는 카메라라고 생각했지만 해당 논문의 결과만을 놓고 봤을 때는 조금 아쉬웠습니다.(물론 분석을 더 해봐야하긴 하겠지만요)
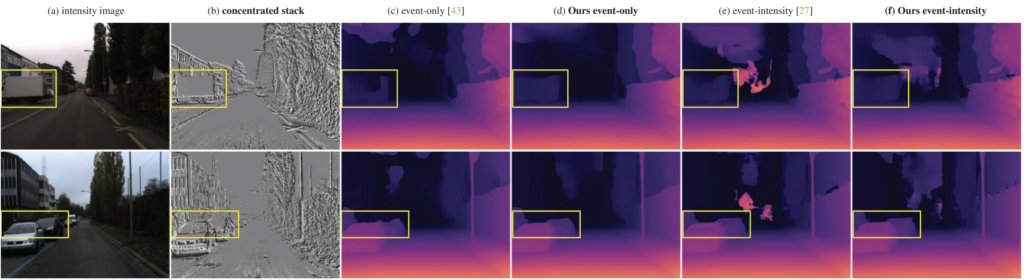

위에는 정성적인 결과입니다. 한번 훑어보시면 좋겠네요.
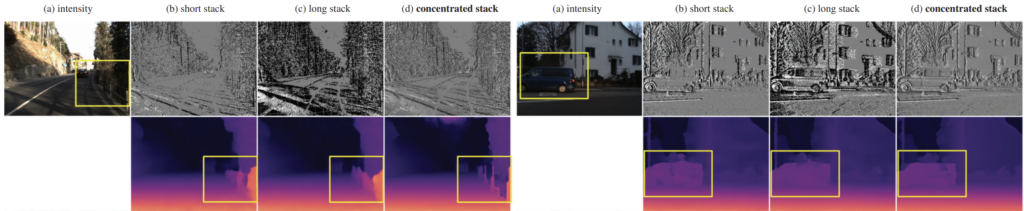
해당 결과는 논문에서 제안하는 concentrated stack이 기존의 short & long stack과의 차별점 그리고 이 때의 깊이 추정 결과가 어떻게 생성되는지를 정성적으로 보여주고 있습니다. cherry picking이긴 하겠지만 깊이 맵의 성능이 상당히 향상된 것을 볼 수 있습니다.
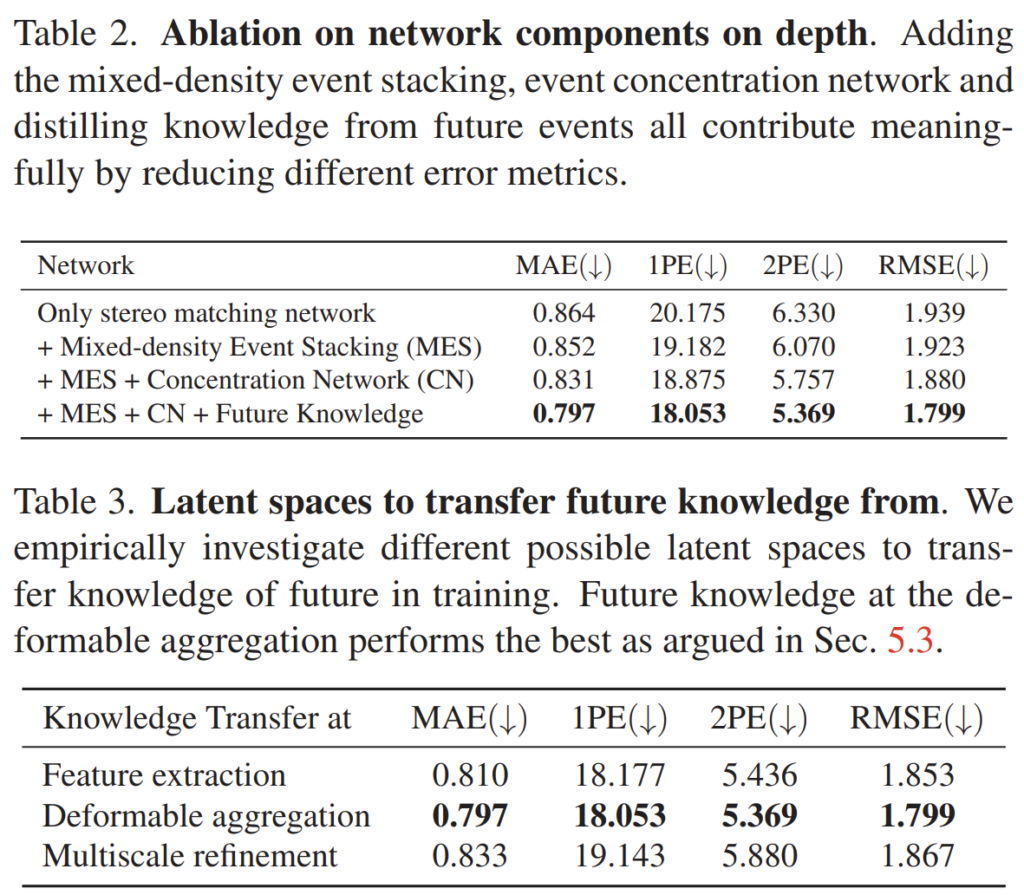
위에 표들은 ablation 결과입니다. 제안하는 방법론들이 점진적으로 성능 향상을 일으키는 것을 보실 수 있습니다. 또한 표3의 경우에는 KD loss를 어떤 단계에서 수행하면 가장 좋은가?에 대한 실험인데 실험적으로는 Deformable aggregation 이후에 하는 것이 가장 좋았다고 합니다. 그 이유에 대해서는 multi-scale refinement 단계에서는 feature map의 semantic한 정보들이 손상되기 때문에 그런 것이 아닐까라고 주장하는데 아마 저자도 제대로 된 분석을 하기에는 어려워서 그냥 얼버무린 듯 합니다.
결론
Event camera에 대한 논문들이 KCCV에서 조금씩 보이길래 다들 Thermal보다는 event를 더 많이쓰네.. 생각해서 한번 읽어보고 포스터에서 질문도 했었던 논문입니다. 기대를 많이 했는데 실험 결과물이 그리 좋지 못한 것을 보고 조금 아쉽다는 생각도 듭니다.
미래랑 과거를 같이 쓴거의 결과를 distilation 한다고 봤는데 그럼 미래랑 과거를 같이 쓴거의 결과의 성능도 리포팅 되었나요?