모든 실험을 말아먹고 있는 요즘… 저에게 마음 속 친구와 같은 Vitor의 논문을 리뷰하고자합니다. 보다보면 Monocular depth 쪽에서는 Toyota가 매우 연구를 잘하고 있는 것 같습니다. 꾸준히 괜찮은 논문을 들고오는 거 보면 참 대단한 것 같습니다.
이번에 소개드릴 논문은 Multi frame depth estimation 관련 연구입니다. Manydepth 이후 단일 프레임만을 사용하는 것이 아닌 여러 프레임을 사용해서 Depth estimation 하는 것이 주류로 넘어가는 느낌이 있습니다. 그리고 나온 논문이 이 논문이며 확실한 성능향상을 보여주었습니다.
기존 단일 프레임을 사용하는 방법론과 달리 Multi frame 을 사용하는 방법론은 두 영상간의 feature corresponding을 고려하며 학습이 됩니다. 따라서 기존에 단순히 단일 프레임의 값만을 이용해서 학습을 했던 것에 비해서 기하학적 관계까지 학습하기 때문에 더욱 높은 성능을 보여주고 있습니다. 그렇지만 이러한 feature-correspoding 역시 texture less, luminosity change 와 같은 문제가 있는 영상들을 이용해서 하기 때문에 노이즈가 끼어있고 부정확한 결과를 보여주곤합니다.
이러한 문제를 해결하기 위해서 이 논문에서는 다음과 같은 방법론들을 제안합니다.
- target image 와 context image feature 간의 epipolar 를 고려하는 cost volume 을 제안합니다.
- 영상 feature 간에 매칭하기 위한 새로운 방법론을 제안합니다.
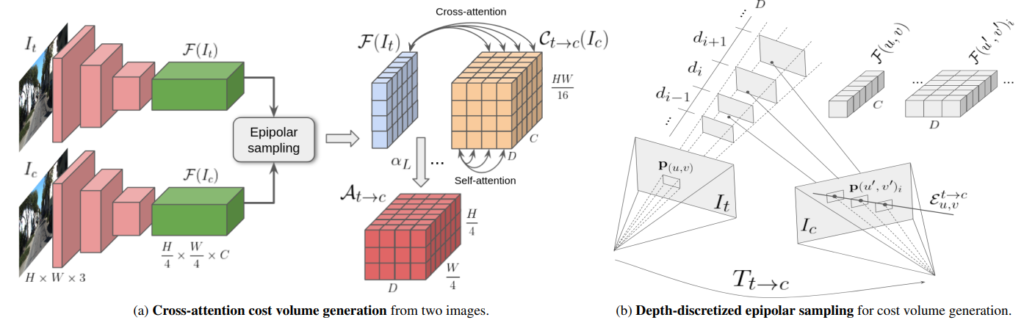
이 논문을 보고 처음 이 그림을 봤을 때는 뭔 멍멍이 소린인가 싶었는데, ManyDepth의 그림을 보시고 보시면 이해가 쫌 더 쉽습니다.
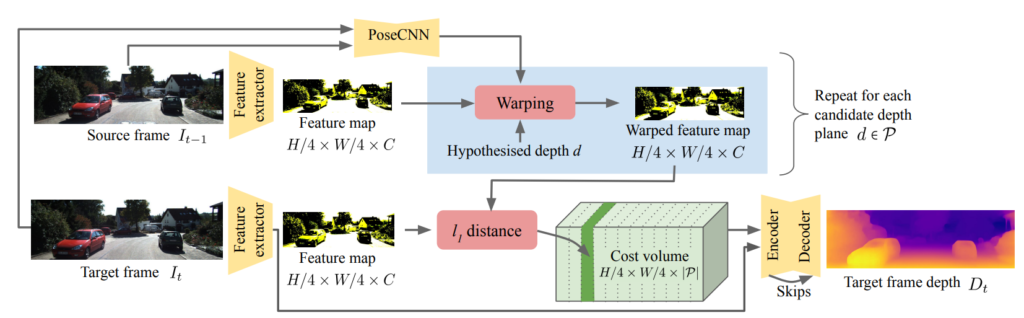
many depth 에서는 다음과 같이 feature map을 만든 후 depth를 예측하고 그걸 통해서 warping 을 해서 target 과 source 의 feature 를 일치 시켜서 cost volume을 계산합니다.
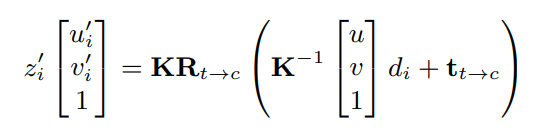
식을 보시면 위와 같습니다. target 영상의 pixel(feature)을 warping 시킬 경우 u’,v’과 일치 시킬 수 있습니다.
이때 소개드리는 논문에서는 depth를 1채널로 estimation 하지 않고 이산화 해서 좀 더 정확한 결과를 얻을 수 있었다고 보시면 됩니다.
또한 이 논문에서는 warp 된 target feature 와 source feature 간의 비교를 통해 cost volume 을 생성할 때 비교 방식을 Cross -attention과 self-attention 을 사용했다고 합니다.
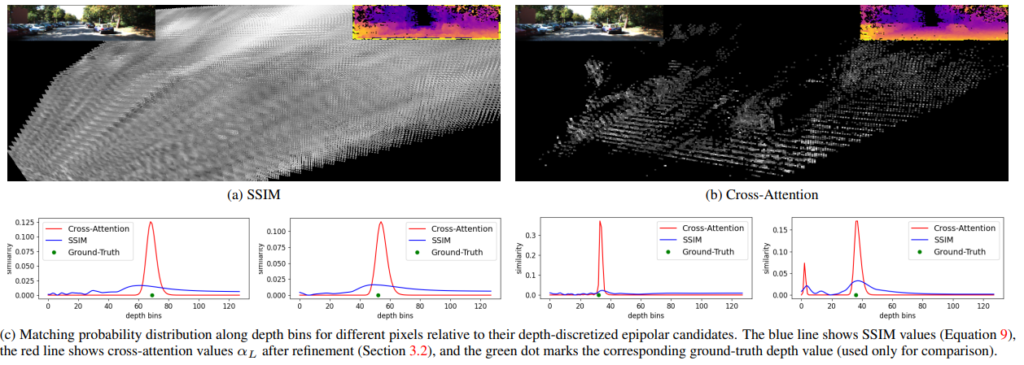
Cross-attention을 통해서 두 feature를 비교 하고 self-attention을 통해서 각 feature 를 강화했습니다. 이를 적용했을 때의 결과를 위를 통해서 볼 수 있습니다. 정성적으로 봤을 때도 depth tail이 사라진 것을 볼 수 있으며 아래 표를 통해서 볼 수 있는데 더욱 정확한 정확하고 확실한 depth를 예측하는 것을 확인 할 수 있습니다.
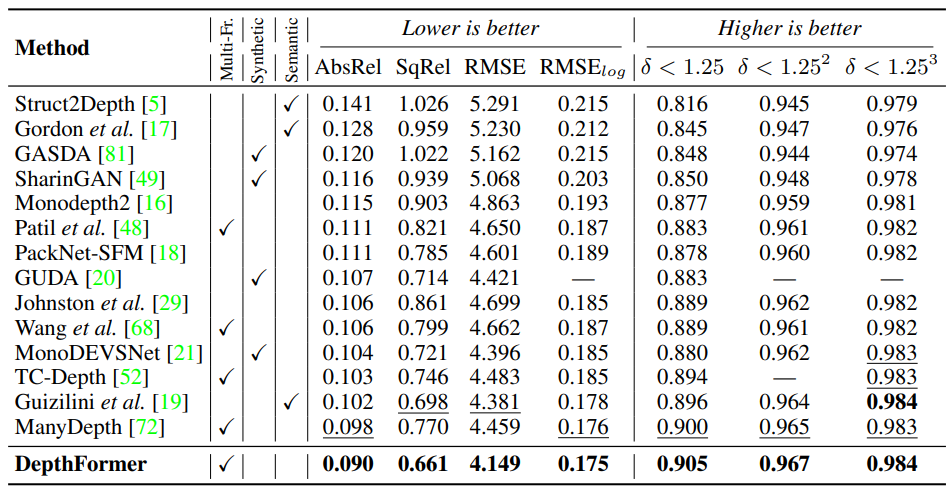
이러한 방법론 을 통해서 위와 같이 Many depth 보다 매우 높은 성능을 보여줍니다.
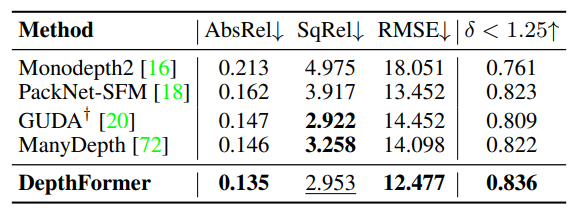
DDAD 에서 또한 성능 향상을 보여주며
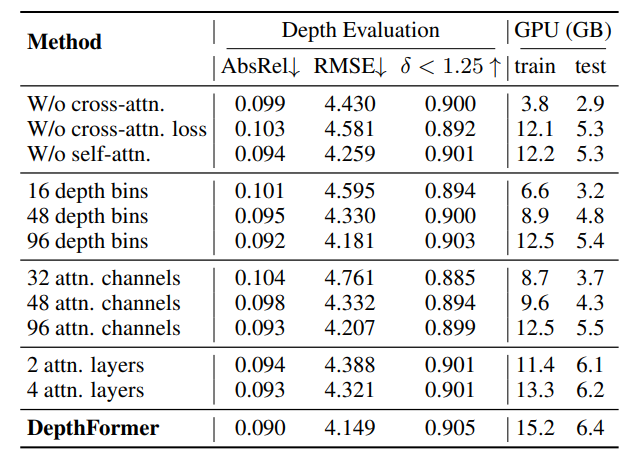
Ablation study를 통해서 각 방법론의 성능 향상 기여도를 볼 수 잇습니ㅏㄷ.
아키텍쳐가 매우 직관적이네요. t-1프레임에서 depth를 구하고, 이를 이용해 warping을 한 이후 t 프레임 영상과 비교를 하는 방식이라고 이해했습니다. 다만 해당 논문의 저자인 victor라는 분이 꽤나 괜찮은 논문들을 꾸준히 발표한다고 하셨는데, 본 논문이 다른 방법론들 대비 가지는 장점은 무엇인가요? 제가 개인적으로 느끼기에는 본 논문의 리뷰를 읽을 때 별다른 신박한점을 발견할 수 없었는데, 혹시 Cross -attention과 self-attention이 그러한 부분인가요?
리뷰 잘 봤습니다.
many depth 설명부분에서 target과 source의 feature 일치시켜서 cost volume을 예측한다고 하셨는데, cost volume의 개념에 대해 간단하게 설명해 주실 수 있나요?