Abstract
coordinate-based neural representations 라고도 불리는 Implicit neural representations(INRs)은 signal representation 연구로, 기존 signal representation은 signal values를 좌표계인 voxel이나 pixels 기반으로 나타냈다면 INR은 연속된 정보인 neural networks로 나타내고자 합니다. neural network는 activation 함수의 존재때문에(복셀이나 픽셀과 다르게) 연속적인 표현을 갖는다는게 특징입니다. 그러나 현재의 INR로 signal을 표현하는 것은 연산량이나 메모리등의 문제로 아직 많은 수의 데이터셋이나 signal에 확장하는데 어려움이 있습니다. 이러한 어려움을 해결하기 위해 해당 논문은 meta-learning 방식을 활용하여 빠르게 unseen signals에 적응할 수 있도록 잘 초기화된 희소 매개변수화(well initialized sparse parameterization)를 제안합니다. 실험을 통해 meta-learned sparse neural representations 방식이 같은 수의 파라미터를 갖는 dense meta-learned models 보다 빠르게 new signal에 학습하였음을 검증하였습니다.
Intro
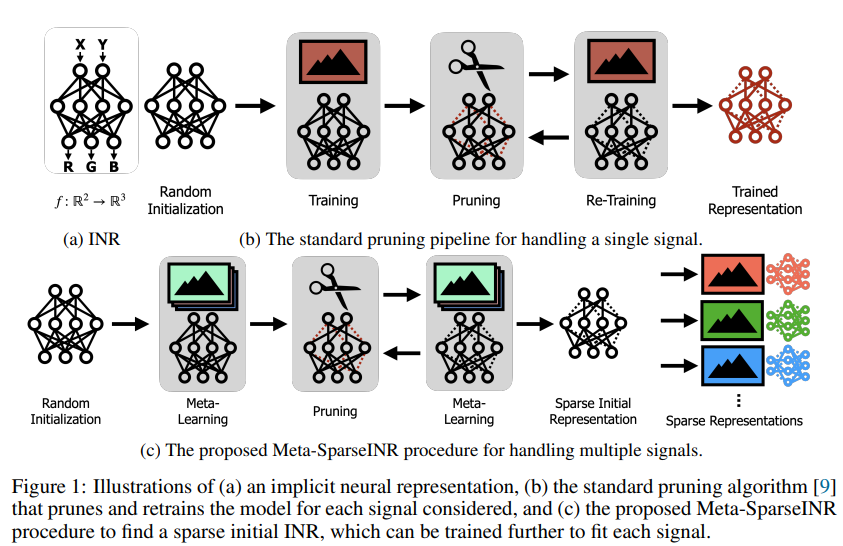
앞서 소개하였듯이 INR은 신호를 연속성으로 나타낼 수 있다는 장점을 갖습니다. 기존의 pixel 단위로 이미지를 저장하는 것과 다르게 연속적인 시그널을 통해 데이터를 저장한다면 spatial resolution 등과 같은 조건에 엄격히 제한받았던 기존 조건을 타파할 수 있습니다. 그러나 많은 이점이 기대되는 INR(논문에서는 network-as-a-representation이라고 표현하더군요. 이해가 쉬워보여 용어를 가져왔습니다)는 large set을 갖는 데이터에 대해 표현하는것에 제한이 있는데요, 그 이유는 각 신호에 대해 학습된 parameter-heavy한 네트워크를 갖으려면 많은 메모리와 연산량이 요구되기 때문입니다. 이러한 문제점에 대해 기존 연구는 크게 3가지로 대응하는데, 첫번째는 시그널들에 대해 공유하는 neural networks를 이용하는 것입니다. 각 시그널을 encoder로 임베딩한 latent code vector를 입력으로 하여 INR로 수정하는 방법입니다. 해당 방법론은 표현력에서 취약성을 갖는데, latent space에서 많이 벗어난 데이터에 대해 표현력이 떨어집니다. 두번째는 초기 INR을 생성하기 위해 meta-learning을 이용하는 방식인데, 이러한 방법론은 각 signal을 저장하기 위해 neural representations을 저장하여 발생하는 메모리가 크다는 취약성을 해결하지 못합니다. 세번째 방식은 각 INR의 가중치(파라미터 수)를 균일하게 정량화하는 것인데 INR 방법론의 취약성인 메모리 필요성을 줄인 방법론입니다. 그러나 해당 방법론은 각 시그널을 위한 학습과정에서 발생하는 시간 소요를 해결하지 못해 연산량 측면에서 낭비가 발생합니다. 즉 기존 방법론은 [그림1.top]과 같이 시그널의 각 도메인 마다 재학습을 필요로 하거나(compute-efficient 포기), 큰 메모리(memory 효율성 포기)를 필요로 합니다. 이에 제안하는 방식은 neural network pruning(neural network의 파라미터를 제거하여 단순화하는 방법론)과 meta-learning을 이용하여, 좋은 표현력을 지닐 수 있고 가벼운 초기 INR을 제안하여 기존 방법론의 문제점을 해결합니다.
방법론

본 논문은 Sparse implicit neural representation(Meta-SparseINR)라는 initial INR을 소개하기 위한 논문으로, 이는 meta-learning을 접목하여 각 시그널을 적은 optimization steps으로 학습할 수 있는 well initialized sparse parameterization입니다. 또한 pruning을 학습 과정에서 접목하여, 각 signal 학습 시 pruning을 접목했던 기존 방법론보다 연산에서 간단하며, 가볍습니다. 뿐만 아니라 inital INR 생성시 pruning을 접목하여 initial INR 자체가 더 큰 표현력을 지닐 수 있습니다. (이는 [그림3]에서 정량적으로 확인할 수 있습니다.) well initialized INR인 Meta-SparseINR의 학습 순서는 다음과 같습니다.
- (Step1) Meta-learning the INR over the signals by running MAML(Model-Agnostic Meta-Learning)[1]
MAML[1] 방식으로 INR 을 학습(meta-learn) 합니다. - (Step2) Pruning the INR using the magnitude-based pruning
학습된 INR에서 가중치가 적은 연결(파라미터)의 k%를 제거합니다. - (Step3) Retrain and repeat
pruned된 INR을 MAML 방식으로 수렴할때까지 재학습합니다. 원하는 global sparsity 수준까지 도달하지 않았다면, 원하는 수준에 도달할때 까지 Step1, Step2를 반복합니다.
실험
실험을 위해 사용된 base INR은 multi-layer perceprons(MLPs)로, 4개의 hidden layers를 가지며 각 레이어마다 256개의 뉴런을 갖습니다. 이는 기존의 해당 분야 실험에서 많이 사용되는 구조입니다. 실험은 2D image regression task에 대해 진행하였으며 CelebAm Imagenette, 2D SDF 데이터셋을 이용하였습니다. 또한 비교를 위해서는 5개의 베이스라인을 잡았습니다. initial INR을 생성하기 위한 베이스라인 모델의 정보는 아래와 같습니다.
- Random Pruning
제안하는 Meta-SparseINR과 같지만 prune시 random하게 진행합니다. - Dense-Narrow
original INR보다 width가 작은 sparse INR을 meta-learn합니다. - MAML+OneShot
각 signal에 대해 MAML 을 50 epoch씩 학습하고, 각 shot에 대해 magnitude기반의 pruning을 진행합니다. 이후 pruned 된 네트워크에 additional training을 50 epochs씩 진행합니다. - MAML+IMP
pruning 시 20%의 weights를 매번 제거하고, 매 cycle(step1, step2 세트) 반복 시 epoch를 줄여 학습을 진행합니다. - Scratch
Dense-Narrow와 같지만 기존의 radom 초기화 방식(SIRENs[2])을 이용합니다.
[그림2]의 실험은 제안하는 Meta-SparseINR 방법론이 모든 baseline 방법론 대비 대표적인 3가지 데이터셋에서 일관적으로 높은 성능을 보임을 증명하는 실험입니다. 게다가 [그림2(d)]에서 확인할 수 있듯이 파라미터 수 또한 다른 베이스라인에 비해 적은것을 알 수 있습니다.
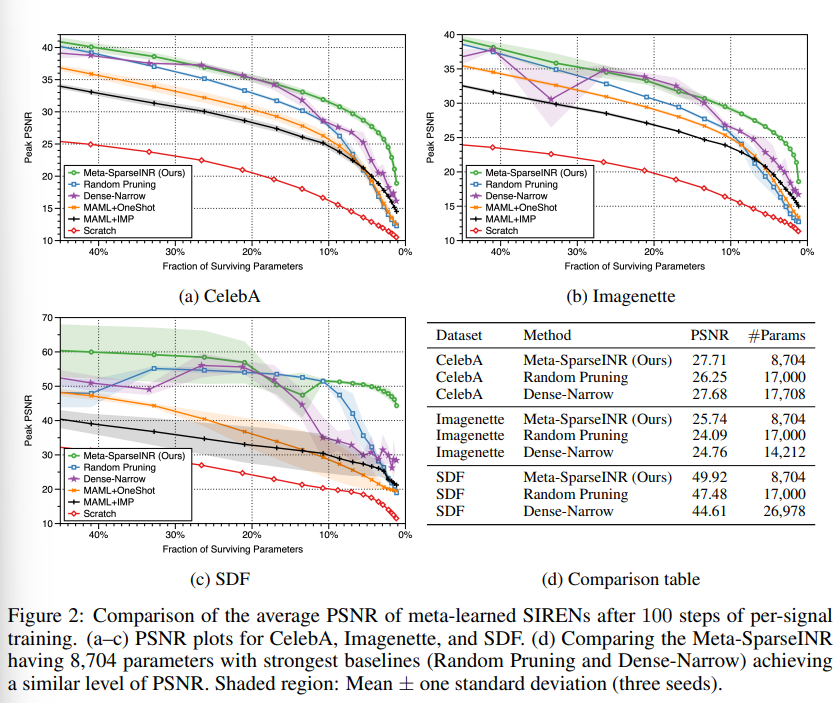
또한 [그림3]에서는 제안하는 Meta-SparseINR이 Dense-Narrow보다 같은 정도의 파라미터수를 가지고 더욱 많은 정보를 갖을 수 있음을 정성적으로 보였습니다.

Reference
[1] C. Finn, P. Abbeel, and S. Levine. Model-agnostic meta-learning for fast adaptation of deep
networks. In Proceedings of International Conference on Machine Learning, 2017.
[2] V. Sitzmann, J. N. P. Martel, A. W. Bergman, D. B. Lindell, and G. Wetzstein. Implicit neural
representations with periodic activation functions. In Advances in Neural Information Processing Systems, 2020.
..?
문맥이 잘못 적혀있는 부분이 있었네요 죄송합니다
수정하였으니 확인 부탁드립니다
리뷰 잘 봤습니다.
두가지 정도 질문이 있는데 일단 메타러닝에 대해서 간략하게 설명 좀 해주실 수 있으실까요? 키워드는 자주 들어봤지만 관련 논문을 읽어보지는 않아서 개념이 없다보니 리뷰 내용에 어려움이 있네요ㅠ
그리고 두번째는 리뷰 내용 중 “또한 pruning을 학습 과정에서 접목하여, 각 signal 학습 시 pruning을 접목했던 기존 방법론보다 연산에서 간단하며, 가볍습니다.”라는 내용이 있는데 이게 기존의 각 신호 학습 시 pruning을 접목했던 기존 방법론과 제안된 방법론이 학습 과정에서 pruning을 접목한다는 것에서 어떤 차이가 있는 것인가요? 결국 제안된 방법론도 학습과정에서 pruning을 사용하는 거고 기존의 방법도 학습시에 pruning을 쓴다는 점에서 같은 의미 아닌가요..?