제가 이번에 리뷰할 논문은 image enhancement 태스크에 관한 논문입니다. 어두운 환경에도 강인한 retrieval이 가능하도록 하기 위한 방법론으로 적용해보아도 좋은 것 같아 읽게 되었습니다.
Abstract
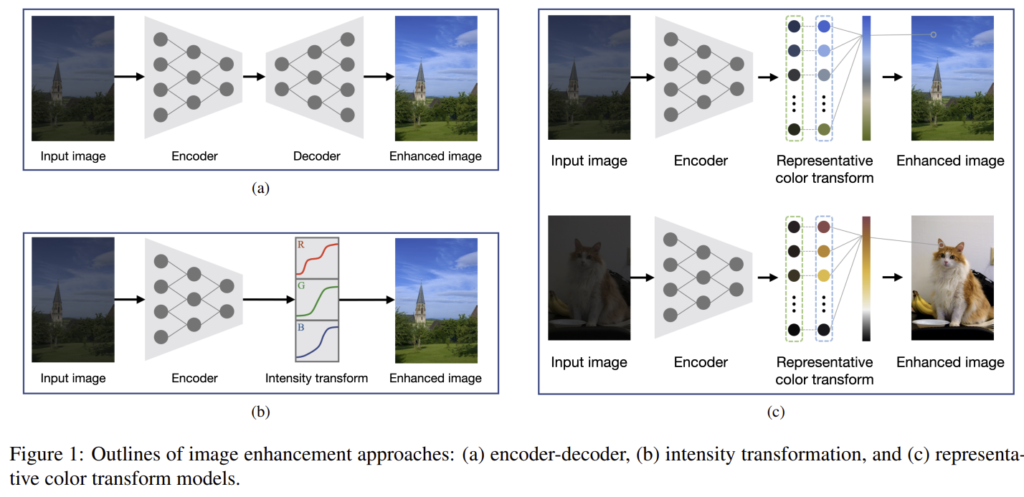
image enhancement에서 encoder-decoder 기반의 방식과 intensity transformation 방식이 연구되어 상당한 발전이 있었다 합니다. 그러나 encoder-decoder 방식의 경우 down-samplig과 up-sampling 과정에 디테일한 정보가 소실되고, intensity transformation 방식은 색상 변환 능력이 제한이 있다는 문제가 있고, 이를 해결하기 위해 representative color transform(RCT)라는 새로운 방식을 제안하였습니다. RCT 방식은 입력 이미지에 맞도록 represnetative color를 결정하고, representative color를 구하기 위해 transform된 색상을 추정합니다. 이후 입력과 representative color사이의 유사도를 기반으로 enhanced color를 결정하게 됩니다. (즉, 이미지 색상 보정을 하는 것입니다.)
Introduction
빛이 부족한 환경에서 촬영된 이미지는 명암 범위가 작고, 실재와 다른 왜곡된 색을 갖는다는 문제가 있다고 합니다. 이를 해결하기 위해 encoder-decoder 방식은 encoder를 통해 이미지의 semantic한 정보를 추출하고decoder를 통해 high-level(sementic) 정보를 low-level 픽셀로 전달합니다. 그러나 이 방식은 up-sampling과정에서 디테일한 정보를 읽게 되고(skip connection 방식을 적용한다 하더라도 해결하기 어렵다 합니다), 고정된 크기의 입력 이미지를 학습하여 임의의 크기를 가진 inference 이미지에 적용하기 어려운 문제가 있다 합니다.
이러한 이슈를 해결하고자 transformation function을 추정하는 방식(intensity transformation)이 제안 되었고, 이 방식은 up/down-sampling을 적용하지 않아 디테일한 정보 유지가 가능하다고 합니다. 그러나 이 방식도 특정한 색 공간에 의존하고, 채널 별로 색을 변환하기 때문에 동시에 모든 채널을 고려하지 못하며, 사전에 정의된 모델을 이용하므로 성능을 보장할 수 없다(학습 데이터에 맞춰진 모델이라 유동적이지 못하다는 의미인 것 같습니다)는 문제가 있다고 합니다.
이 논문은 representation color transform(RCT)이라는 방식을 제안하였고 다음과 같이 작동된다 합니다.
- 이미지의 high-level context 정보를 추출하여 encoding
- high-level context 정보로 representative color 결정
- 입력 이미지와 representative color의 유사도 계산
- 3에서 구한 유사도와 representative color transformation을 융합하여 representative color transform 만들기
(representative color transform을 이용하여 enhanced image 구함)
해당 논문의 contribution을 정리하면 다음과 같습니다.
- color transformatioin의 능력을 확대하기 위한 representative color transformation 제안
- encoder, feature fusion, global RCT, local RCT로 구성된 RCTNet 제안
- RCTNet의 확장성 증명
Method
1. Representative Color Transform
저자들이 제시한 새로운 RCT 방식에 대해 정리하여 보겠습니다.
입력 이미지 \mathbf{X}(저해상도 이미지)를, CNN을 통해 얻은 high-level 정보를 임베딩 하기 위해 feature representation \mathbf{Z}로 인코딩합니다. 그리고 N개의 representative color에 대해 feature \mathbf{R}과 transformed color \mathbf{T}를 추출합니다.
이때 \mathbf{T}는 N개의 대표 색상만을 포함하므로, 모든 픽셀의 색상을 매칭하기 위해 입력 색상과 임베딩 공간의 representative feature \mathbf{F}간의 유사성을 계산하고, 이를 기반으로 색상 transform을 수행합니다. attentation matrix \mathbf{A}는 아래의 식(3)을 이용해 구하고, 이때 유사도를 구합니다.
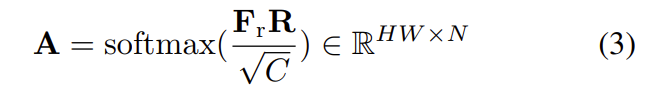
enhanced image는 아래의 식으로 구해진다고 할 수 있습니다.

이러한 RCT 방식은 색상의 transformation의 커버 영역을 확대하고, 각 픽셀에 독립적으로 작용하여 학습시의 입력 이미지의 크기와 상관 이 없다는 장점이 있습니다. 이제 이러한 RCT 방식을 네트워크로 구성한 내용을 정리해보겠습니다.
2. Representative Color Transform Network
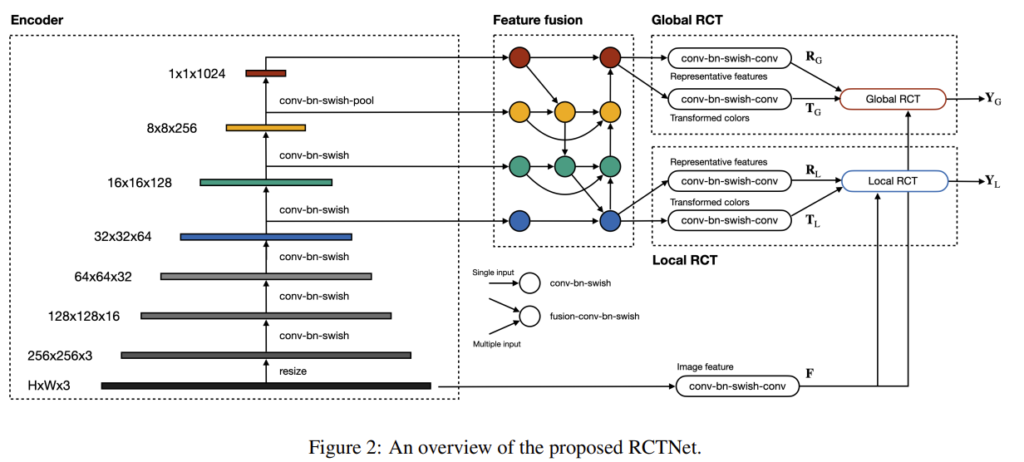
RCTNet은 encoder, feature fusion, global RCT, local RCT 4가지 모듈로 구성이 되고, 흐름은 위의 그림과 같습니다. high-quality 이미지 \mathbf{\tilde{Y}}를 구하기 위해서는 global RCT 모듈의 output인 \mathbf{Y}_G과 local RCT 모듈의 output인 \mathbf{Y}_L를 이용한다고 합니다.
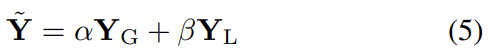
이제 각 모듈을 간단하게 정리해보겠습니다.
1. Encoder
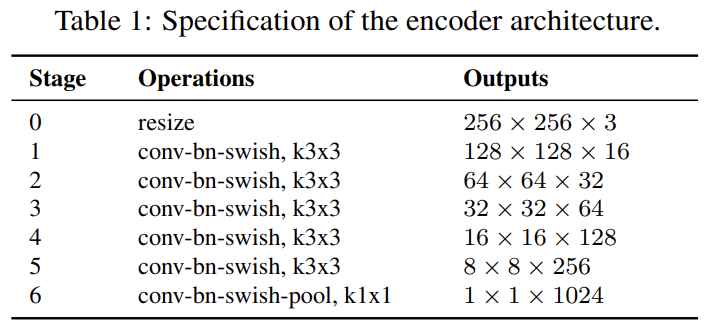
인코더는 CNN을 이용하여 high-level contexxt 정보를 추출합니다. 아래의 표1이 인코더 구조라 합니다. 이때 conv-bn-swish란 convolution-batch normalization- swish activation레이어를 의미합니다. 그리고 마지막 4개의 블록에서 multi-scale feature maps을 추출하여 feature fusion 모듈에서 결합합니다.
2. Feature Fusion
일반적으로 coarse한 feature map은 넓은 receptive field로 인해 글로벌한 맥락 정보를 가지고, fine한 feature map은 디테일한 local 정보를 가지고 있다고 합니다. global한 정보와 local한 정보는 이미지를 보정하는 데 중요하므로, multi-scale feature map들을 fusion 모듈을 이용하여 합쳐줍니다.
작동 방식은 그림 2를 참고하시면 됩니다. 이때 Feature fusion 모듈에서 단일 입력이 들어오는 노드들은 ‘conv-bn-swish’ 블록을 의미한다고 합니다. 또한 여러 입력이 들어오는 경우는 ‘conv-bn-swish’블록 앞에 feature fusion 레이어를 이용하였고, feature fusion 레이어는 다음과 같이 정의가 된다고 합니다.
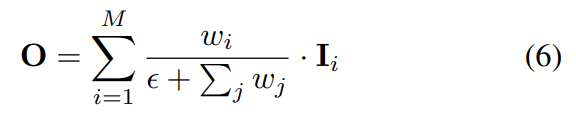
이때 w_i는 0과 음수가 아닌, 학습 가능한 가중치이고, \epsilon= 0.0001라 합니다.
가장 coarse한 노드(그림2에서는 빨간색)를 제외하고는 3×3인 128개의 conv 커널이 있고, 가장 coarse한 노드는 feature map이 1×1의 사이즈이므로 1×1의conv 커널을 가진다고 합니다.
3. Global RCT
\mathbf{Z}_G∈\mathbb{R}^{C'}(이때 C’는 128로 설정하였다 함)가 가장 coarse한 feature fusion의 output feature라 할 때, global RCT 모듈은 global한 정보를 포함하는 feature vector \mathbf{Z}_G를 2개의 ‘conv-bn-swish-conv’ 블록을 통해 각각 representative feature \mathbf{R}_G과 transforemd color \mathbf{T}_G를 결정합니다. 이렇게 구한 \mathbf{R}_G과 \mathbf{T}_G는 벡터 형태이고, 이들을 2D 구조로 수정해준다고 합니다. 입력 이미지는 transform을 거쳐 image feature \mathbf{F}가 되고, \mathbf{F}는 \mathbf{F}_r로 reshape됩니다.
\mathbf{R}_G, \mathbf{T}_G \mathbf{F}_r를 위의 식(3)과 식(4)를 적용하여 global enhanced image Y_G를 구합니다.
4. Local RCT
local RCT 모듈은 이미지 enhancement를 위한 local 특징을 고려하기 위한 모듈로, representative color를 결정하며 가장 fine-scale을 갖는 fusion feature \mathbf{Z}_L∈\mathbb{R}^{32x32xC'}를 이용합니다. Global RCT와 마찬가지로, 2개의 ‘conv-bn-swish-conv’블록으로 들어가 representative feature set \mathbf{R}_L과 transformed color \mathbf{T}_L를 생성합니다.
따라서 (u,v) 위치에서 representative features\mathbf{R}_L(u,v)과 transformed color \mathbf{T}_L(u,v)를 얻게 됩니다.
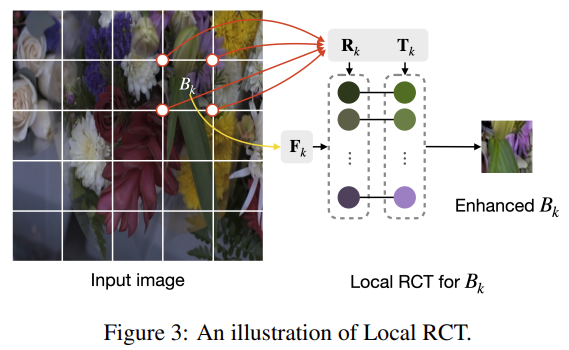
k번째 그리드 B_k는 4개의 코너를 가지며, 이는 B_k가 4개 세트의 representative feature와 transformed color가 4개의 점과 관련이 있는 것이라 합니다. 코너의 4개 포인트에서 representative feature를 연결하고, 각 코너 4개의 점들에 대한 feature 세트를 concat함으로써 \mathbf{R}_k를 결정한다고 합니다. 또한 \mathbf{T}_k도 앞선 방식과 유사하게 구합니다.
그리드 feature \mathbf{F}_k는 그리드 영역을 crop하여 추출한다고 합니다.
마지막으로 \mathbf{R}_k, \mathbf{T}_k \mathbf{F}_k를 식 (3)과 (4)에 적용하여 주니다.
local RCT 모듈은 위의 과정을 각 그리드에 모두 적용함으로써 enhanced image \mathbf{Y}_L를 생성합니다.
local RCT와 global RCT는 모두 이미지 피쳐를 down sampling을 거치지 않고 추출하기 때문에 이미지 크기 조정 없이 입력 이미지를 보정할 수 있습니다.
3. Loss Function
low-quality image \mathbf{X}와 hight-quality image \mathbf{Y}를 한 쌍으로 사용하며 loss 는 아래의 식으로 계산된다고 합니다.
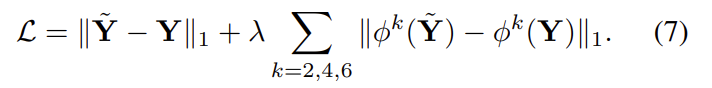
앞의 텀은 이미지와 enhanced 이미지 사이의 평균 절대값 오차이며, 두번째 텀은 임베딩 공간에서의 차이를 구합니다.
Experiments
마지막으로 성능과 정성적 결과를 확인하고 마무리하겠습니다. 실험 파트에 궁금한 것이 있으신 분들은 논문을 보시면 좋을 것 같습니다.
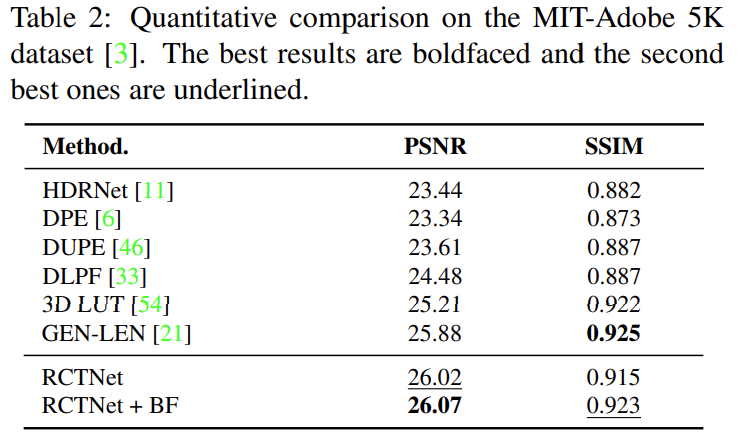
- MIT-Adobe 5K 데이터는 5000장의 이미지로 구성되어있습니다. SOTA방법론들과 비교한 결과 아래의 표와 같은 결과를 얻었고 PSNR에서는 가장 좋은 성능을 보이고, SSIM에서도 우수한 성능을 보입니다.
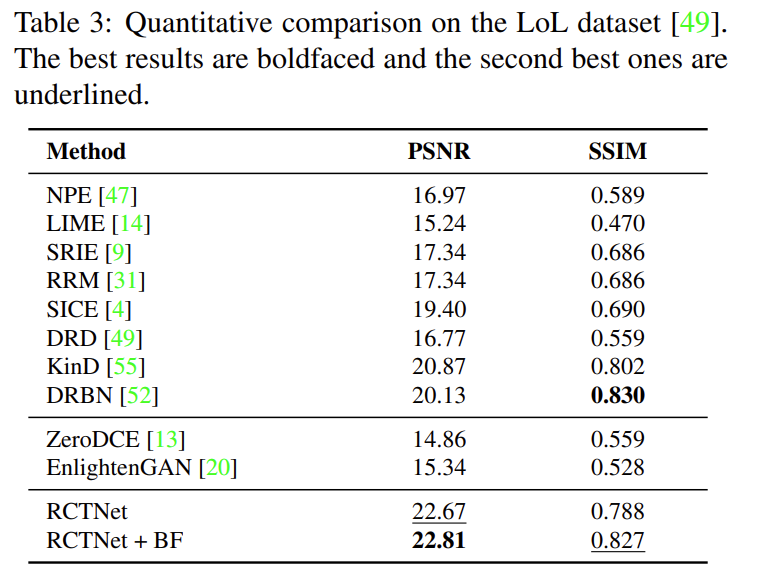
- Low Light (LoL) 데이터는 저조도 이미지 개선을 위한 데이터셋으로 500쌍의 저조도 이미지와 정상 이미지가 있습니다. 이 데이터셋에 대한 성능이 저자들의 주장을 증명할 수 있는 가장 중요한 실험 결과라 생각합니다. 정량적 성능도 우수하게 나왔고, 정성적인 결과를 확인해보아도 이미지의 품질이 좋아진 것을 확인할 수 있습니다.

새로운 enhancement 방식을 제안했다는 점이 가장 큰 컨트리뷰션이라 생각합니다. 또한 논문이 주제가 명확하게 잡혀있어 논문을 읽는 데 상대적으로 수월했습니다.