논문 링크:
Generalizing to Unseen Domains: A Survey on Domain Generalization [Link]
What is Domain generalization(DG)?
DG의 목적은 하나 혹은 다수의 도메인을 포함하는 학습 데이터로 학습한 모델이 unseen testing domain에서도 정상적으로 작동하기를 원하는 것이다. 일반적인 machine learning(ML)에서는 iid(independent and identically distribution, 독립 항등분포)라는 가정을 안고있다. random variable이 독립적이고(independent), 같은 확률분포(identically distribution)를 갖는다는 가정인데, random variable인 training domain과 testing domain이 같은 분포를 갖기 때문에 train data로 학습한 모델이 test data에도 작동한다는 뜻이다. 그러나 실제 환경에서는 그렇지 않은 경우가 많으며 이러한 필요때문에 DG 분야 연구가 인기를 끌게 되었다. 단순히 이러한 목적 때문이 아니더라도, 해당연구가 발전한다면 데이터를 수집하기 어려운 도메인에서 효과적으로 모델 학습을 진행할 수 있을것이다.

Detail
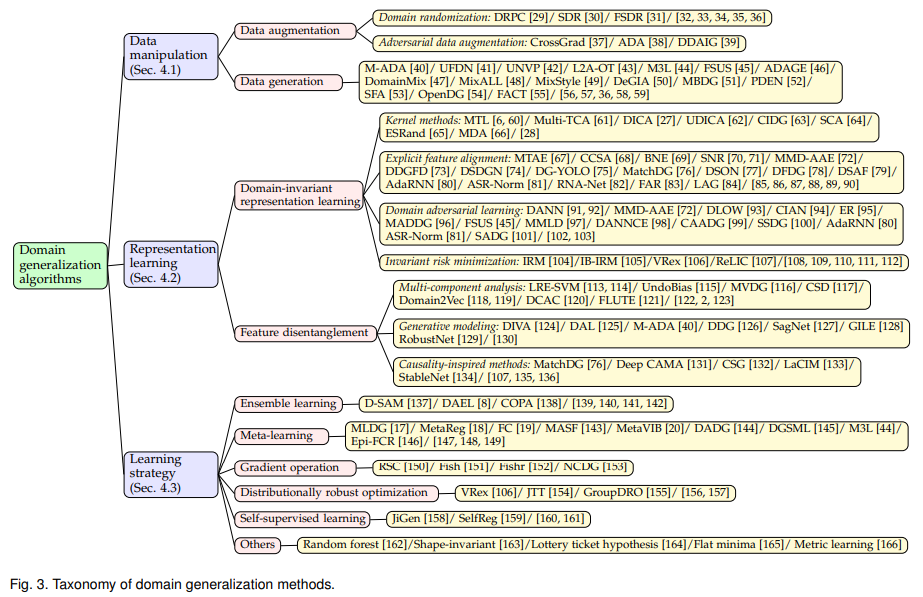
본 장에서는 DG를 상세하게 소개한다. 논문에서 DG연구를 세 분류(Data mainpulation, Representation learning, Learning stategy)로 나누었다.
- Data mainpulation는 학습 시 모델의 입력을 조작(manipulating)하는 방법론을 칭한다. 보통 data augmentation 이나 data generation을 통해 입력 데이터의 분포를 다양화하는 방식으로 접근한다.
- Representation learning은 DG분야에서 가장 대표적인 문제 해결법으로 하나의 커널처럼 작동하는 모델을 이용하여 불변 도메인의 표현법을 학습하는 domain-invariant representation learning이나, domain-shared feature와 domain-specific feature를 분리하여 접근하는 feature disentanglement 방법론이 있다.
- Learning strategy는 학습 전략을 발전시켜 일반화된 표현력을 배울 수 있도록 하는 연구방법론으로 Ensemble learning, Meta-learning, Gradient operation, Distributionally robust optimization, Self-supervised learning과 같은 다양한 연구가 이에 속한다.
관련 연구들-Data Manipulation(서베이)
Data manipulation을 통해 DG 문제를 해결하는 연구는 입력 데이터의 분포를 (데이터 증폭방식으로) 다양화하여 unseen domain data에 대응할수 있기를 희망한다. 학습 데이터 sample을 증폭하기 위해서는 1)특정 샘플을 기반으로 augmentation을 진행하는 방식 (data augmentation)과 2)데이터를 직접 생성하는 방식 (data generation)이 있다.
- [Data augmentation] domain randomization 은 전형적인 augmentation 방식으로 물체의 위치나 텍스쳐를 바꾸거나, noise를 추가하는 등의 변형을 한다. 또한 최근 peng[2021]의 연구는 label까지 augmentaion한다. 그러나 DG 관점에서 이러한 접근법은 random으로 생성된 도메인이기 때문에 실제로는 모델 성능 향상에 영향을 주지못하고 오히려 학습에서 제거해야하는 도메인까지 포함한다는 문제점을 항상 가지고있다.
- [Data augmentation] adversarial data augmentation 해당 방법론은 randomization과 다르게 데이터의 신뢰가능성을 보장하면서 데이터의 분포를 향상시키는 방법론이다. 예를 들어 shankar의 연구는 베이지안 네트워크를 통해 label, domain, input instance 의 관계를 모델링한 후 이를 이용해서 data augmentation을 진행하는 crossgrad 라는 기법을 고안했다.
- [Data generation] GAN을 이용한 방법론이 data generation을 위해 많이 사용되는데, 대표적으로 ComboGAN과 Mixup이 있다. 이러한 방법론을 통해 real과 generated images간의 분포 차이를 최소화하면서 새로운 데이터를 생성해낼 수 있다.
데이터셋과 평가메트릭
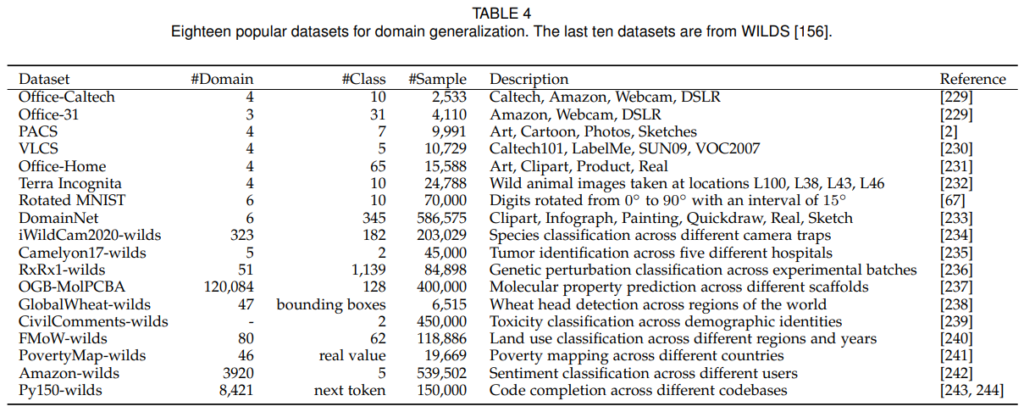
본 논문은 DG 분야를 위한 데이터셋과 벤치마크 등을 정리하였다. 논문이 말하길 PACS, VLCS, Office-Home 데이터가 DG분야에서 가장 유명한 데이터셋 들이며 large-scale evaluation을 위해 DomainNet, Wilds 등을 이용할 수 있다고 한다. 그 외에도 예를 들어 CityScape와 GTA5 데이터셋을 이용해 실험을 진행하는 등 다양한 실험을 해당 분야의 논문들이 진행하고 있다. 해당 분야에서 Evaluation을 위해서 다음의 세가지 전략을 이용한다고 한다: Test-domain validation set, Leave-one-domain-out cross-validation, Trainingdomain validation set
- Test-domain validation set
해당 방식은 test data를 학습의 validation 시 이용할 수 있도록 하는 방식으로, 모델 선정 시 도움을 받을 수 있다. 따라서 다른 평가방식에 비해 성능이 높은것이 특징이지만, real applications에는 적용하기 힘든 가정을 내포하고 있다. - Leave-one-domain-out cross-validation
이는 training data가 다수의 도메인을 포함하고 있을 때 사용가능한 평가방식으로, training data에 포함된 하나의 도메인을 평가용으로 제외한 후 이를 validation시 이용한다. 이는 제외한 데이터셋에 성능 의존성이 있어 stable 하지 않다. - Training domain validation set
해당 방법론은 가장 일반적인 평가방식인데, 데이터셋에 포함된 모든 도메인 데이터셋을 2 부분으로 나눈 후, training과 validation에 각각 포함시키는 것이다. 혼합된 모든 도메인에 대해 좋은 성능을 가져야 하므로 DG 분야에서 인기있는 평가방식이다.
Benchmark
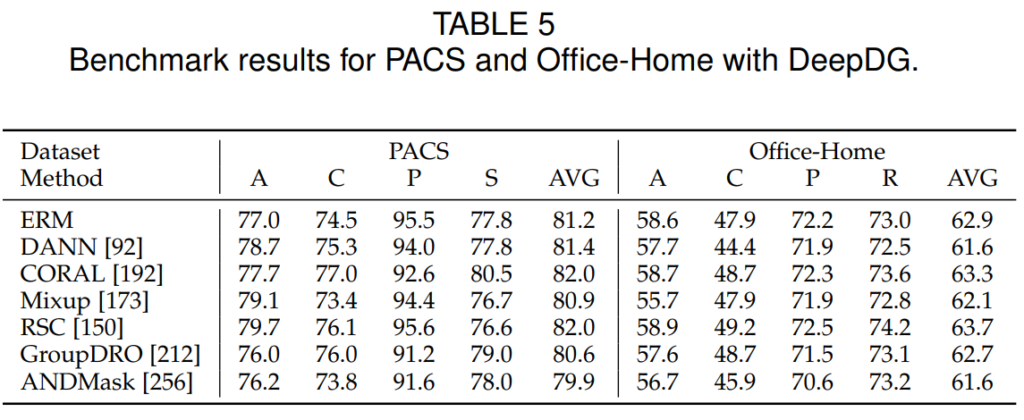
본 논문은 Benchmark 제공을 위해 DeepDG라는 codebase를 제공한다. 해당 codebase를 통해 image classification task를 위한 실험을 진행할 수 있으며 Office-31, PACS, VLCS, Office-Home datasets에 대한 실험을 진행할 수 있다. 위에서 분류한 세가지 분야의 다양한 방법론들에 대해 구현하였다:Data manipulation (Mixup), Representation learning (DDC, DANN, CORAL), and Learning strategy (MLDG, RSC, GroupDRO, ANDMask) 해당 codebase를 통해 실험한 실험 결과는 위의 테이블과 같다.
좋은 리뷰 감사합니다.
DG라는 것이 익숙한 것 같으면서도 굉장히 생소하네요. 굉장히 많은 연구가 되고 잇는 것으로 보이는데요, 우선 가장 기본적인 질문을 드리자면 DA 랑은 어떤 차이가 있을까요?
DG는 target domain에 대한 일반화를 목적으로 하지만 DA의 경우는 target domain이 특정 된 경우가 일반적입니다.