시각적 변화에 강인하도록 하기 위해 feature간의 매칭을 한다면, RGB와 Thermal 이미지를 feature로 만들어 매칭시킬 경우에도 어느정도 강인하게 작용할 수 있지 않을까 하여 읽게 되었습니다.
Abstract
카메라의 포즈 추정은 입력 이미지에서 정확한 기하학 값을 추정하는 작업으로 새로운 view-point에 대해 일반화되지 못하고, 모델의 파라미터들이 특정 장면에 연결되어 있다는 문제가 있다고 합니다. 저자들은 deep network가 시각적 특징에 강인하도록 학습이 되어야 하고, 기하학적 추정은 원칙적인 알고리즘을 이용해야 한다고 주장합니다. 따라서 이미지와 3D 모델에서 장면과 상관 없이 정확한 6-DoF를 추정하는 PixLoc를 제안하였습다.
Introduction
각 픽셀에 해당하는 3D 장면 좌표를 regressoin으로 구하도록 CNN을 훈련하는 방식은 end-to-end로 학습할 수 있지만 절대적인 pose와 좌표를 구하는 방식은 장면에 특화되어 있어 새로운 장면에 대해서는 학습(혹은 adaptation)이 필요합니다. 따라서 낮의 이미지로 학습되었을 때 밤 시간대의 이미지로 localization을 수행하거나, 더 크고 복잡한 이미지를 이용하는 것 과 같은 경우에 어려움이 있습니다. 게다가 pose를 regression하는 것은 정확도가 제한되기 때문에 새로운 view-point로 일반화하는 것에 종종 실패하게 된다고 합니다. 이렇듯 일반화가 어려운 것은 카메라 pose나 3D 지오메트리를 이미지 정보만을 이용하여 예측하기 때문이라 합니다.
이미지의 alignment를 맞추는 것과 특이치를 제거하기 위해 학습된 image representation을 이용하는 것에 영감을 받아 저자들은 visual localization 알고리즘은 representation learning을 해야 한다고 주장합니다. 기본 기하학적 관계를 학습하거나 3D 맵을 인코딩하기보다는 이해도가 높은 기하학적 원리에 의존하고, 외관과 구조적 변화에 대한 강인성을 학습해야 한다고 합니다.
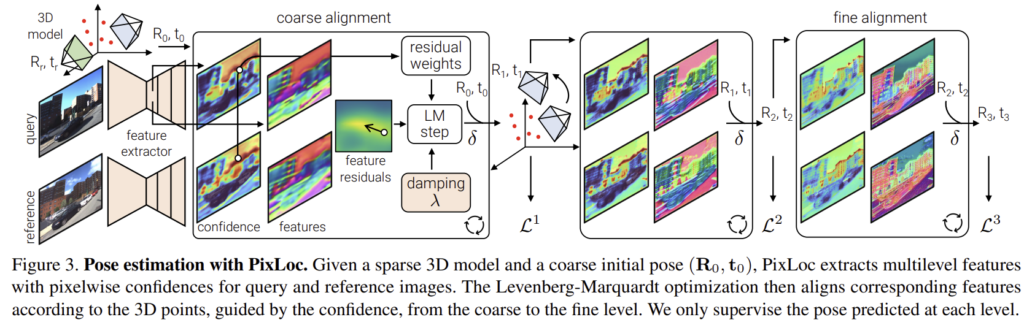
따라서 이 논문에서는 CNN에서 추출한 feature를 기반으로 하는 장면의 3D 모델과 이미지를 정렬하여 위치를 찾는 PixLoc을 제안합니다. 고전적인 최적화 방식에 의존하여 pose regression을 학습하지 않고, 적절한 feature를 추출하면 되기 때문에 알고리즘이 정확하고, 장면에 구애받지 않을 수 있다고 합니다. PixLoc은 pose만을 감독하여 픽셀로부터 pose를 end-to-end로 학습합니다. 이미지 retrieval을 통해 초기의 pose를 추정하면 공식을 통해 localization을 수행하고, 간단한 후처리를 통해 추정된 pose를 추정할 수 있다고 합니다.
PixLoc: from pixels to pose
Motivation
단일 이미지로부터 절대 pose와 장면의 좌표 regression에서 DNN은 1)장면의 대략적 위치를 인식하고, 2) 장면에 맞는 강인한 시각적 특성을 인식하며, 3) pose나 좌표와 같이 정확한 지오메트리 값을 regression하는 것을 학습하게 됩니다. 이때 1)과 2)는 CNN이 외관과 지오메트리를 일반화하도록 학습 될 수 있으므로 특정 장면에 국한되지 않을 수 있습니다. 그러나 3)은 feature matching이나 이미지 정렬과 3D representation을 이용하는 고전적인 기하학에 의해 방해를 받습니다. 따라서 저자들은 포즈 추정에 장면에 구애받지 않고 기하학에 제약을 받도록 만드는 강인하고 일반적인 feature를 학습해야 한다고 합니다. 이때 localization에 좋은 feature를 저자들은 지오메트리를 구별할 수 있게 추정하고 최종 pose 추정만을 감독할 수 있도록 하는 것으로 보았습니다.
problem formulation
3D point cloud를 \left\{ \mathbf{P}_i \right\}라 하고, 포즈 정보가 포함된 참조 image를 \left\{ \mathbf{I}_i \right\}라 하면 쿼리 이미지 \mathbf{I}_q 에 대한 6-DoF(rotation: \mathbf{R} 와 translation:\mathbf{t})를 추정하는 것이 해당 task의 문제 정의입니다.
1. Localization as image alignment
Image Representation
쿼리 이미지와 참조 이미지로부터 CNN을 이용하여 여러 층에서 feature를 추출합니다. 이때 여러층에서 추출한 feature는 해상도가 점점 낮아지고, 점차 풍부한 semantic한 정보를 가지고 더 큰 공간 context가 인코딩되어 있습니다.
이후 feature들은 L_2-mormalization이 적용되어 강인성과 일반화를 높입니다.
이러한 learned representation은 큰 조도 변화와 viewpoint 변화에 강인하고, 잘못된 초기 pose값에도 유의미한 그래디언트를 제공할 수 있도록 연구된 과거의 camera tracking 연구들을 기반으로 영감을 받았다고 합니다. 또한, 고전적인 direct alignment는 원본 이미지를 활용하였기 때문에 강인하지 않았다고 합니다.
Direct alignment
지오메트리 최적화의 목표는 쿼리 이미지와 참조 이미지의 차이를 최소화 하는 pose(\mathbf{R,t})를 찾는 것입니다. \mathcal{l} level에서 3D point cloud i가 reference image k에 존재할 경우 residual은 다음과 같이 정의됩니다.
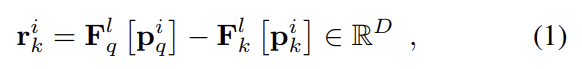
\mathbf{p}^i_q는 i가 쿼리 이미지로 투영된 것을 의미합니다. total error는 다음과 같이 구합니다.
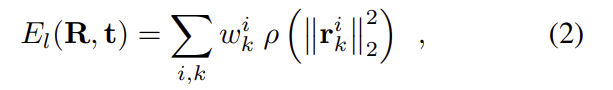
이때 \mathcal{ρ}는 미분이 가능한 비용함수( Frank R Hampel, Elvezio M Ronchetti, Peter J Rousseeuw, and Werner A Stahel. Robust statistics: the approach based on influence functions.의 robust cost function이라 하는데 정확히 어떤 형태의 함수인지 알고 싶어 찾아보았으나 확인하지 못하였습니다…)이고, w^i_k는 residual마다의 가중치이다. 이는 Levenberg-Marquardt알고리즘(해로부터 멀리 떨어진 경우에는 gradient descent 방식으로 작동하고, 해 주변에서는 가우스-뉴턴 방식을 이용하는 방식이라 합니다.)을 이용하여 초기 추정 pose(\mathbf{R}_0,\mathbf{t}_0를 업데이트합니다.
수렴을 최대한으로 하기 위해 가장 coarse한 level \mathcal{l}=1부터 각 feature map을 연속적으로 최적화 하고, 이전 level의 결과를 이용하여 초기화합니다. 이러한 과정을 통해 저해상도의 feature는 강인성을 갖도록, 고해상도의 finer feature는 정확성을 높이도록 학습됩니다.
Infusing visual priors
CNN이 복잡한 시각적 정보를 학습 할 수 있으므로, 저자들은 CNN을 이용하여 포즈를 올바르게 최적화하고자 하였고, 이를 위해 CNN으로 feature map과 불확실성 맵 \mathbf{U}^l_k를 예측하도록 하였습니다. 그리고 쿼리와 참조 이미지의 point별 불확실성은 residual별 가중치로 결합되도록 하였습니다.
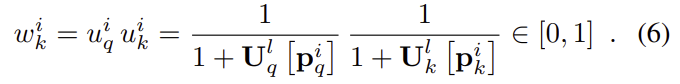
3D point가 쿼리와 참조 이미지 모두에서 불확실성이 낮은 위치로 투영될 경우 가중치는 1이 됩니다. 이때, w^i_k는 supervised로 학습되지 않고 pose의 정확도를 최대화 하기 위해 학습됩니다.
네트워크는 불변 특징을 예측할 수 없을 경우 불확실성이 높도록 학습될 수 있습니다. 또한 pose가 local minima를 도입하여 정확한 포즈로부터 멀어지도록 학습되는 경우에도 불확실성이 높을 수 있습니다. 이는 그림 4와 6에서 확인할 수 있듯이 움직이는 객체나 반복되는 패턴과 대칭되는 것에서(불확실성이 높은 것에서) 가중치가 0이 됩니다.

Fitting the optimizer to the data
Levenberg-Marquardt는 몇가지의 파라미터를 실험적으로 선택해야 하는 최적화 방식이다. 과거의 연구들이 최적의 cost function과 damping 파라미터, pose 업데이트를 예측하기 위해 deep learning을 사용하였으나 저자들은 optimizer를 훈련 데이터의 시각적-의미론적 내용과 연결시키는 방식은 새로운 데이터 분포로 일반화 하는 능력을 손상시킨다고 주장합니다. 대신, 최적화 도구를 pose나 residual에 최적화 시키되 의미론적 내용에 맞추지 않도록 damping 파라미터는 고정하고 CNN에 gradient descent를 이용해 학습할 것을 제안하였습니다.
2. Learning from poses
Loss function
해당 논문에서는 각 레벨에서 추정된 포즈를 GT 포즈 (\mathbf{\bar{R},\bar{t}})와 비교하여 학습됩니다.
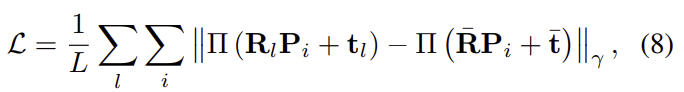
\gamma는 Huber cost로 아래의 식입니다. 저자들은 어려운 씬에서 특징을 부드럽게 만드는 것을 막기 위해, 이 loss는 이전 레벨 추정 치가 GT와 가까울 경우에만 loss를 적용합니다. 즉, pose와 차이가 클 경우에는 후속 조건이 무시된다고 합니다. (otherwise를 무시한다는 의미로 이해하시면 될 것 같습니다.)

Localization pipeline
Initialization
단순한 파이프라인을 위해 이미지 retrieval에서 반환 되는 첫번째 참조 이미지의 pose를 초기 pose로 선택할 경우 대부분의 시나리오에서 수렴이 잘 된다고 합니다. 그러나 retrieval 결과가 나쁘고 잘못된 pose를 추정할 경우 reranking이나 pose verification을 이용하여 초기 pose의 정확도를 높일 수 있다고 합니다. (학습에 대한 경우이기 때문에 GT와 비교하여 초기값을 조정할지 판단한다고 이해하시면 될 것 같습니다.)
3D structure
단순성을 위해 sparse SfM 모델들을 이용하였다고 합니다. retrieval 결과 상위의 n개 이미지에 해당하는 3D 포인트를 수집합니다.
Experiment
Training
환경에 특화된 사전학습의 영향을 확인하기 위해 2가지 버전으로 PixLoc을 학습하였다고 합니다.
- 전 세계의 랜드마크를 묘사하는 Mega Depth 데이터 셋으로 학습
- 도시와 시골 환경에서 촬영된 시퀀스 데이터로 구성된 Extended CMU Seasons데이터 셋으로 학습
Extended CMU Seasons 데이터는 큰 계절적 변화가 있어 feature matching에 어려움을 준다고 합니다.
1. Comparison to learned approaches
Cambridge Landmarks와 7Scenes 데이터에서 평가를 하였으며, 각 데이터 셋은 5개의 실외 장면과 7개의 실내 장면이 포함되어 있으며 다양한 궤적과 조건을 따라 촬영된 pose 정보가 포함된 참조 이미지와 쿼리 이미지로 구성되었습니다.
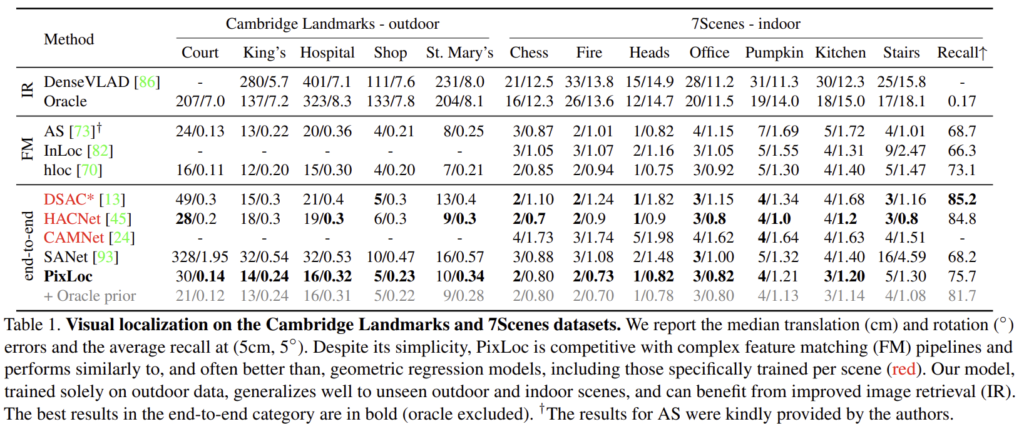
outdoor 데이터에서 PixLoc은 end-to-end이고 장면에 구애받지 않는 방법론인 SANet보다 전체적으로 좋은 성능을 보입니다. 또한, 실외 데이터로만 학습하였음에도(Landmark 데이터) 실내 장면에서 경쟁력 있는 성능을 달성합니다.
2. Large-scale localization
Cambridge Landmarks와 7Scenes보다 더 높은 다양성을 보이는 대규모 데이터셋 long-term loalization benchmark로 평가를 진행하였습니다. 밴치마크는 3가지 데이터셋으로, 손으로 들고 촬영된 Aachen Day-Night데이터 셋, 차에 탑제된 카메라로 촬영된 RobotCar, Extended CMU 데이터셋으로 구성됩니다. 모든 데이터 셋은 pose정보가 있는 참조 이미지와 SfM 모델 및 쿼리 이미지가 있습니다.
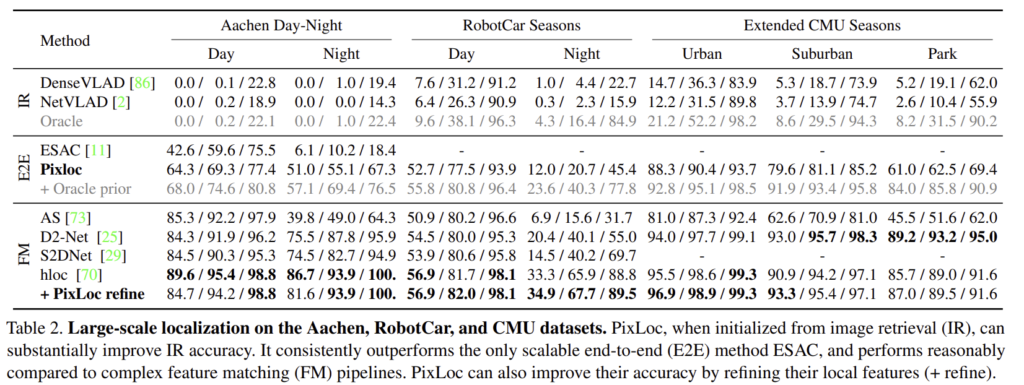
retrieval에 의해 pose가 초기화되면 PixLoc은 ESAC 방식보다 더욱 정확하며, 특히 어려운 조건인 밤에서 좋은 결과를 보입니다. PixLoc은 잘못된 pose를 반환할 경우 알고리즘이 수렴되지 않아서(loss 조건상) feature matching에서는 성능이 조금 덜어집니다.
3. Additional insights
Interpretability
가중치 map u_q을 시각화 하여 어떤 환경에서 localization이 잘 되는지, 방해가 되는 지 이해하는 데 도움이 된다고 합니다. 아래 그림 6이 map을 시각화한 경우로 빨간색 부분이 학습에 도움이 되는 부분이고, 파란색 부분이 학습에 도움이 되지 않는 부분입니다.

Limitations
PixLoc은 제한된 context만 인코딩할 수 있는 CNN의 gradient에 의존합니다. 따라서 local한 방식이며, viewpoint가 크게 변하는 경우에 발생하는 초기 pose의 오류에 대해서는 실패할 수 있다고 합니다. 또한 눈에 띄는 방해물에 의해 실패할 수 있으며, 카메라의 miscalibration에 더 민감하다는 한계가 있습니다.
해당 논문에서 제안한 방법론이 굉장히 reasonable해서 좋은 것 같습니다.
해당 방법론에서 어떤 r, t가 입력되는 건지 잘모르겠네요.
그니깐 같은 위치 혹은 비슷한 위치의 영상쌍이 요구되는 건가요?