다시 돌아온 Self-learning 논문 리뷰입니다. CVPR 2022에 발표된 FAIR의 따끈따끈한 Self-supervised learning 논문입니다. 해당 논문이 발표된지 2-3달이 안되었지만 벌써 citation이 오늘(7/31) 날짜로 353회가 넘어가네요. 아, 저자는 Kaiming He입니다. 각설하고 리뷰 시작하겠습니다.
Self-Learning 에 대해서는 제가 워낙 많이 다룬 것 같아, 이 태스크가 무엇인지는 생략하겠습니다. 해당 태스크가 궁금하신 분들은 제가 작성해둔 리뷰 중 Background 부분을 읽어보시면서 워밍업하시는 것을 추천드립니다! 참고할 리뷰는 아래 링크로 첨부해두겠습니다.
[CVPR 2022] Masked Autoencoders Are Scalable Vision Learners

Introduction
self-supervised learning의 등장은 바로 NLP였습니다. 특히, masked autoencoder 와 같이 데이터의 일부를 제거하고 제거된 내용을 예측하는 방법이 사용되면서 엄청나게 성능을 끌어올릴 수 있었습니다.
그래서 이 masked autoencoder의 아이디어를 컴퓨터 비전에 끌고오는 것은 아주 자연스러운 현상이었습니다. 그러나 이 아이디어를 비전에 적용한 방법론들이 있었지만, 여전히 이 오토인코더 기반의 성능은 NLP보다 뒤쳐지고 있는 실정이었습니다.
그래서 저자는 이런 의문을 가졌습니다: 왜? 무엇 때문에 그 성능 차이를 가져오는것인가?
What makes masked autoencoding different between vision and language?
이에 대해 저자는 다음과 같은 3가지의 차이가 있다고 답변 및 분석을 제시합니다.
- Architecture가 다르다.
- 비전에서는 Convolution 네트워크가 근 몇 십년동안 우세하였습니다. 이 ConvNet은 regular grid에서 작동하는데다가, 여기에는 마스크 토큰이나 위치 임베딩과 같은 indicator가 없었고 이걸 통합하는 것도 쉬운게 아니었죠.
- 그러나, ViT의 등장으로 비전과 language 사이의 아키텍처 상의 차이가 해소될 수 있었습니다.
- 정보의 밀도가 다르다
- 언어는 사람이 만들어내는 신호로, 정보집약적입니다. 따라서 문장 내 몇 개의 단어를 없애고 그 누락된 단어를 예측하도록 모델을 학습할 경우, 정교한 언어 이해를 유도할 수 있습니다.
- 이에 반해 이미지는 자연 신호로, 공간적 중복성이 큽니다. 공간적 중복성이 크다라는 말을 달리 해석하면, 모델이 그 이미지(i.e. scene, object)를 거의 이해하지 않고도 주변에 인접한 패치만 보고도 누락된 부분을 복구해낼 수 있다는 뜻입니다.
- 따라서 언어는 정보가 많으니, 한번에 많은 단어를 가리는 것이 어렵겠지만 그에 반해 이미지는 한번에 많은 부분을 가리는 것이 가능하다고 해석할 수 있습니다. 저자는 이 이야기를 증명하고, 이용하기 위해 이미지의 많은 부분을 랜덤하게 가리는 방법을 제안하습니다!
- 디코더의 역할이 다르다.
- 비전에서는 디코더가 픽셀을 reconstruction 하므로, 일반적인 recognition보다 의미적인 레벨이 낮습니다.
- 그에 반해 Language에서의 디코더는 누락된 단어를 예측해내는 역할을 합니다. 이 때, 단어는 2번에서 이야기 했던 것처럼 많은 의미 정보가 포함되습니다.
- 따라서 디코더의 역할이 이렇게 다르니, 이미지에 특화된 디코더 설계가 중요한 역할을 한다는 것이죠!
따라서 저자는 이미지에 특화된 간단하고 효과적이며 확장가능한 masked autoencder(MAE) 방법론을 제안합니다. 특히, 앞서 분석한 3가지 언어-이미지의 차이를 기저로 모델을 제안하였다는 것이 인상적입니다.
(1번의 경우, ViT를 사용하겠다는 얘기겠죠. 그 얘기는 즉슨 이미지를 패치로 나눠서 학습을 하겠다는 이야기가 함축되있다고 보시면 될 것 같습니다)
특히 2번을 집중해봅시다. 저자가 주장한 “2번, 이미지-언어 사이의 정보의 밀도가 다름”에도 불구하고, 기존에 사용되던 masked-autoencoder 기반의 방식들은 언어처럼 이미지의 약간의 영역만 가려서 모델을 학습하였습니다. 따라서 저자는 이미지의 75%를 가리고, 이를 오토인코더가 복원하는 것을 self-learning 에서의 pretext task를 설계하였습니다. 그렇게 함으로써 이미지의 공간적 중복성을 최소화하면서 이미지의 특성을 고려하여 모델을 학습할 수 있다는 뜻이죠! 이게 75%라는 수치가 어느정도인지가 체감이 되지 않으실까봐 아래 이미지를 첨부해드립니다. 아래 이미지가 바로 MAE의 pretext task인 이미지 복원으로, 이미지에 대해 패치로 나눈 후, 랜덤하게 75%를 가려서 이것을 복원하도록 모델을 학습한 결과가 되겠습니다.

저자는 언어-이미지의 차이 3번으로 디코더의 역할 차이에 대해서도 언급하였는데요. 그 전에, 오토인코더는 인코더-디코더가 symmetric하게 구성된 게 일반적이지만 저자는 asymmetric한 모델을 제안합니다. 그렇기 때문에 인코더와 디코더를 독립적으로 분리하여서 여러 실험도 진행하고, 디코더를 기존 모델에 비해 더욱 경량화할 수 있었죠.
서론이 굉장히 길었습니다. 사실 MAE를 요약하자면, 결국 Self-learning에서의 pretext task로서 이미지의 75% 랜덤한 패치를 가려(masked) 복원하는것으로 설정하였다고 이해하시면 됩니다. 그리고 이 모델의 차별점 및 성능을 다음 Method 및 Experiment에서 확인해보도록 합시다.
Method
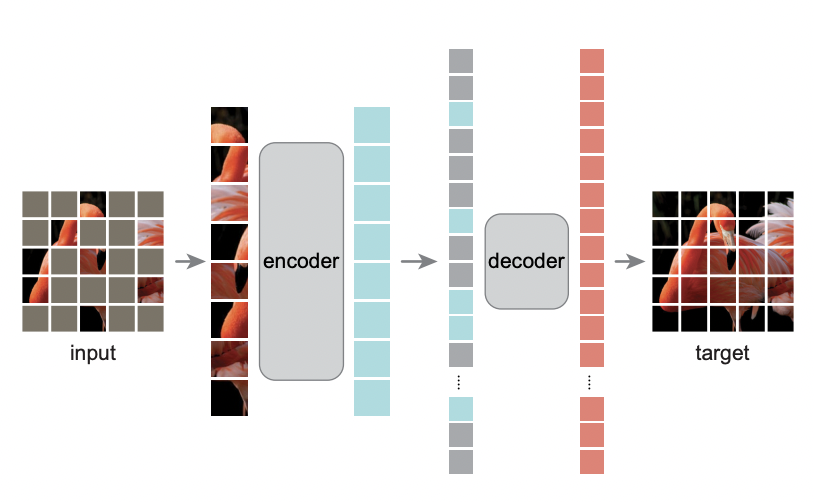
위의 그림이 바로 MAE 모델의 개요입니다. MAE는 이미지를 패치 단위로 나눈 후, 패치의 75%를 랜덤하게 masked 합니다. 그 다음 Auto-encoder 에 순차적으로 넣어서 모델을 Reconstruction하므로 Masked AutoEncoder 라고 명명합니다. 그런데 MAE는 기존 오도인코더와 달리 Encoder와 Decoder가 서로 Asymmetric합니다. 어떻게 다르냐? 우선 인코더에는 앞서 랜덤하게 가린 75%의 패치를 제외한 Visible한 25%의 패치만 입력으로 들어갑니다. 자세한 내용은 각 파트별로 설명드리죠.
Masking
ViT를 사용하는 만큼 이미지를 패치 단위로 나눕니다. 그리고 패치를 랜덤하게 마스킹합니다.
(최적의 마스킹 비율이 75%였는데요) 많은 비율이 무작위로 가려지기 때문에 이미지가 가지는 중복성이 크게 제거되며, 이를 통해 인접한 패치만으로는 이미지를 복원해내기에는 어려운 태스크가 됩니다. 그렇기 때문에 모델은 이미지 전체를 이해해야 각 패치를 잘 복원할 수 있는 것이죠.
MAE Encoder
그리고 해당 네트워크의 특징이 바로 Vislble한 패치만 인코더에 입력으로 들어가는 것입니다. 즉, 75%가 마스킹된다면 그 패치는 모드 빼고 25%만 인코더에 입력으로 들어갑니다. 그 덕분에 컴퓨팅 및 메모리가 줄어들어 오히려 더 큰 인코더를 학습시킬 수도 있게 됩니다.
MAE Decoder
MAE 디코더는 인코더와 달리 마스킹된 패치가 입력으로 들어갑니다.. (마스킹된 패치를 복원하는 것이 디코더의 역할이니까 당연하겠죠?) 따라서 디코더의 입력은 1) 인코딩된 visible 2) 마스크 토큰 까지 전체 이미지 토큰이 됩니다. 위치 임베딩 역시 전체 토큰에 추가되는데, 그래야 마스크의 위치 정보를 알 수 있기 때문이죠.
게다가 디코더는 이 pretext task인 영상 recontruction에서만 사용되었습니다. 그렇기 때문에 인코더-디코더를 독립적으로 설계하고 여러 실험을 할 수 있었습니다.
Reconstruction target
해당 태스크가 복원인만큼 Loss로는 MAE를 사용하였습니다. 특히, normalization 여부에 따라 reconstruction 품질에 차이가 있는 것을 실험을 통해 확인할 수 있었습니다.
Simple Implementation
사실 MAE의 동작은 한 줄로 요약할 수 있을 정도로 굉장히 간단하게 구현될 수 있습니다. 우선, 이미지를 패치로 나누고 패치에 대한 토큰을 생성합니다. 그 다음 토큰 목록을 랜덤으로 섞은 뒤, 마스킹 비율에 따라 목록 마지막에 위치한 패치를 마스킹 합니다. 그 다음 인코딩을 한 다음, 마크스 토큰 목록을 인코딩된 패치 목록에 추가하고, 이 전체 목록을 다시 셔플을 해제해서 정렬합니다. 그 다음 디코더에 이 전체 목록을 넣습니다. 여기서 셔플링 및 언셔플링이라는 오버헤드가 있긴 하지만, list를 셔플링하는거라 무시할 수 있을 만큼 굉장히 빨리 진행됩니다.
즉, 아주아주 빠르고 간단한 방법론이죠! 여기까지가 모델에 대한 설명 전부입니다. 굉장히 간단하죠?
저자는 그런데 이제 실험 결과를 아주 디테일하게 가져왔습니다. 참고로 실험은 모두 이미지넷을 기반으로 수행되었습니다.
Experiment
우선 ViT를 Backbone으로 사용하는 만큼 간단한 ablation study 입니다. ViT-Large를 기준으로 수행하였는데요. ViT-L의 경우, 지도 학습 기반으로 scratch로 학습된 것입니다. ViT-L를 처음부터 학습시킨 결과 76.5%, MAE는 82.5% 였는데요. 여기서 finetuning까지 한 결과 84.9%의 결과를 가져왔습니다.
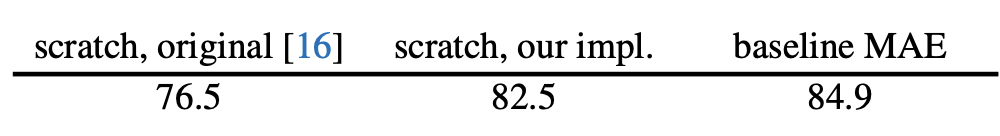
Main Properties
저자는 이제 각각의 실험을 통해 MAE를 뜯어서 분석하였습니다. 아래 Table 1이 그 뜯어본(?) 결과입니다. 순차적으로 함께 설명을 드리겠습니다.
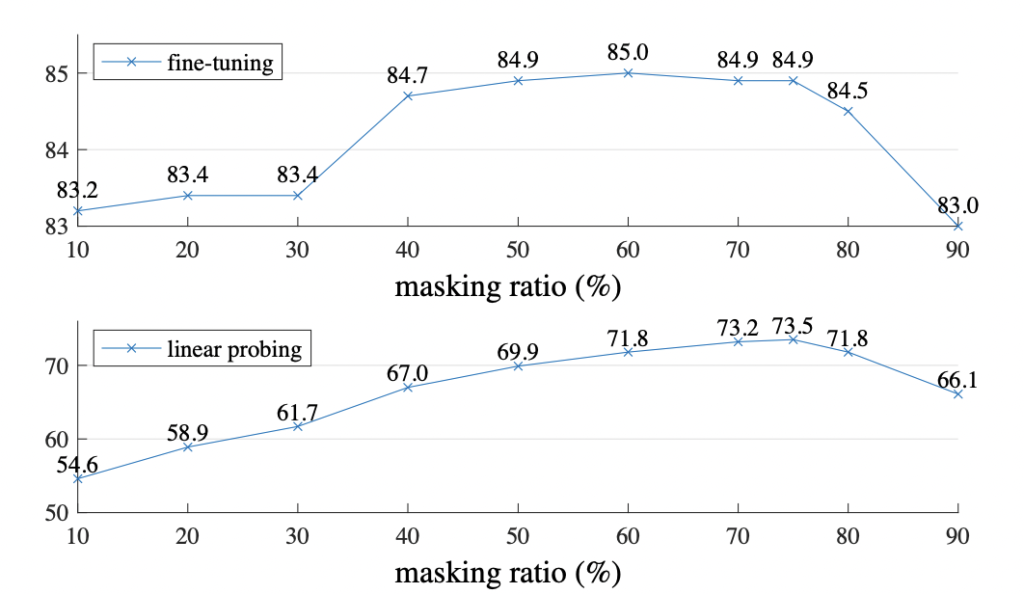
우선 마스킹 비율에 따른 결과는 아래 그림에 나와있습니다. 최적의 비율은 75%로 굉장히 큰 비율이었습니다. 굉장히 인상적이지 않나요..? 게다가 BERT에서는 15%정도만 가리고, 이런 마스킹을 사용하는 기존 방법론들도 20~50% 정도만 마스킹 시켰었다고 합니다. 이 모델은 단순하게 선이나 텍스처를 늘려서 완성할 수 없는 사물이나 장면의 제스처를 이해하였다고 해석할 수 있습니다.

fine-tuning(이하 ft)과 line-probing(이하 lin)에서는 마스킹 비율에 따라 경향성이 다르게 나왔는데요. ft의 경우, 마스킹 비율에 대해 다소 둔감한 반면 lin의 경우 10% <-> 75% 사이 20%라는 정확도 차이가 발생하곤 합니다. 그러나 ft는 마스킹 비율에 상관없이 scratch로 학습한 결과인 82.5%보다 좋았습니다.
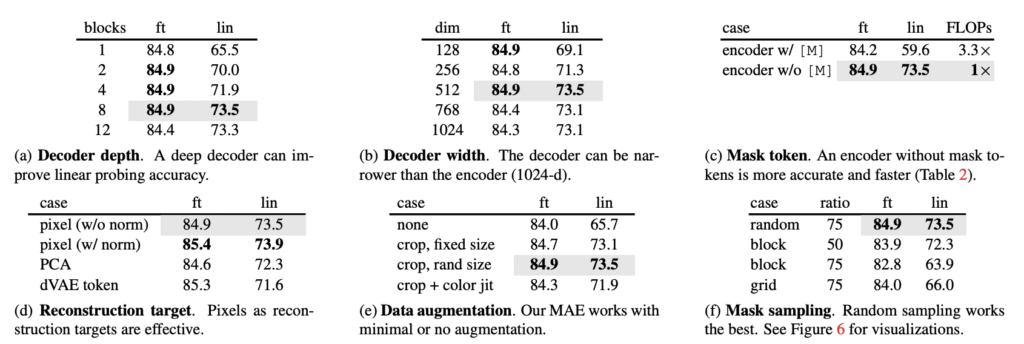
이제 테이블 1에 대해 다시 찾아봅시다. 저자는 줄곧 우리의 디코더는 굉장히 경량화되어 있다고 하는데, 왜 그런 주장을 하였을까요?
우선 뎁스와 width를 살펴봅시다. (a), (b). decoder의 뎁스는 곧 트랜스포머 블록의 개수라고 생각하시면 되는데요. 아래 ft 결과에 집중해봅시다. 1개의 블록을 사용해도 2, 4, 8개를 사용한 것과 버금가는 성능을 가져옵니다. 물론 기본 옵션은 회색으로 칠해진 8개의 블록인데요. ㅣlin 에서 가장 좋은 성능을 가져오는 것이 8개이기 때문입니다. 오른쪽은 width 즉 ,채널의 개수입니다. 기본적으로 512-D를 사용했을 때 모든 ft와 lin에서 우수하였습니다.

다시 말해 MAE는 8개의 블록과 512-d를 사용하는데, ViT-L은 24개의 블록 그리고 1024-d를 가지기 때문에 토큰 당 FLOPs는 9%에 불과한 경량화된 디코더라고 주장할 수 있는 것이죠.
Mask Token. (c)저자가 visible한 패치만 인코더에 넣은 이유는 단순하게 masked 를 같이 넣으니 오히려 성능이 떨어졌기 때문이라고 하는데요. 게다가 FLOPs는 3.3배 줄였습니다. 메모리도 속도도 확연하게 줄여서 더 큰 모델을 학습시키고 배치도 키울 수 있다는 장점이 있죠,.
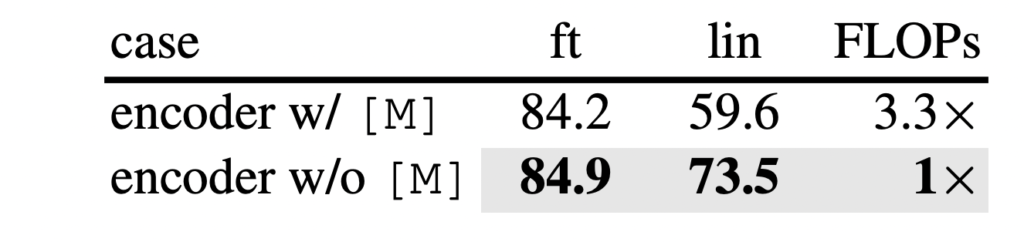
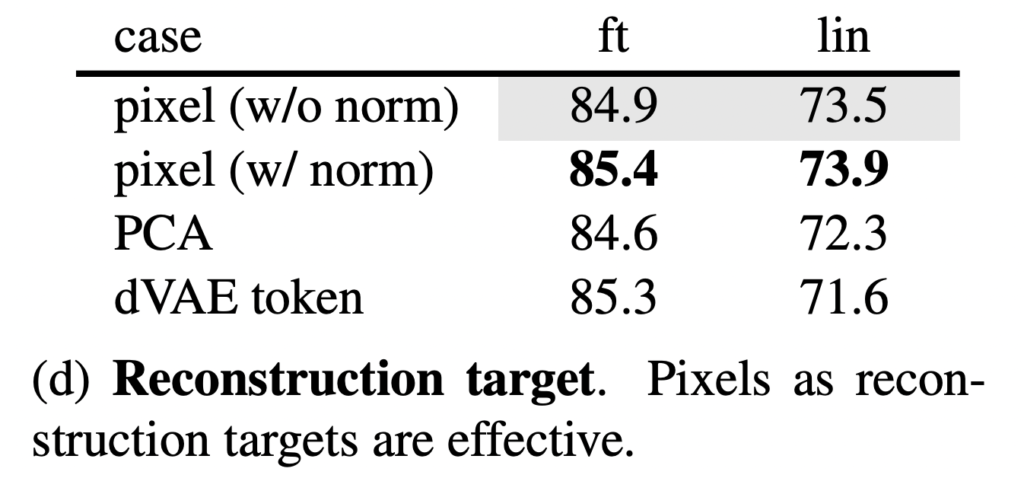
Reconstruction target. (d)앞서 보인 결과는 패치 별 normalization을 적용하지 않은 것입니다. 그런데 이 normalization을 사용하면 정확도가 향상될 수 있습니다. 간단하게 패치 별로 normalization 함으로써 대비를 향상시키고 성능 역시 올라가게 되는 것이죠. 특히 고주파 영역에서 유용하였다고 합니다. 이 외의 PCA나 dVAE라는 BEiT에서 사용된 토큰을 사용하엿는데요. 이건 사전학습이 필요한데다 그닥 높은 성능을 가져오지 않았다는 점을 시사하였습니다.
Data Augmentation (e). 데이터 augmentation에 따른 성능 차이인데요. 결과적으로 말하자면 기존 contrastive 기반의 방법론들은 이 데이터 증강에 아주 큰 영향을 받아서 참 다양한 증강 법을 적용했던 것을 기억합니다. 그런데 MAE는 다 필요없이 중앙 크롭만 심지어 플립도 없이 사용하는 것만으로성능이 좋았습니다. 오히려 컬러 지터를 추가하면 성능이 저하되어서 다른 실험을 적용하지도 않았다고 합니다. 그 이유에 대해서 저자는 매번 랜덤하게 마스크를 설정하는 것 자체가 새로운 데이터를 만드는 것이기에, 랜덤 마스킹이 먼저 적용되기 때문에 augmentation은 오히려 recon.을 어렵게 만들게 하는 요인이된다고 이야기 합니다. 즉, 많이 가려서 안그래도 재구성 작업이 어려운데 거기에 augmentation까지 적용하니 어려워졌다는 것이죠.

마지막으로 다양한 마스킹 전략입니다(f). 아래 이미지를 함께 보시면 좋을 것 같은데요. block은 가운데를 뻥 뚫어버린 것입니다. 이 방법을 사용하면 50% 가려도 잘 동작하긴 하지만 오히려 75% 마스킹을 할 경우 성능이 떨어지는 결과를 보였습니다. 게다가 loss가 커서 학습이 어렵고 random 보다 blurr한 결과를 보였습니다.
또한 grid라는 가장 오른쪽 마스킹 방법을 사용하면 분명 학습도 쉽고 로스도 낮았지만.. 퀄리티가 더 낮았습니다. 따라서 랜덤이 가장 간단하고 좋은결과를 보였다는 결론을 내렸습니다.


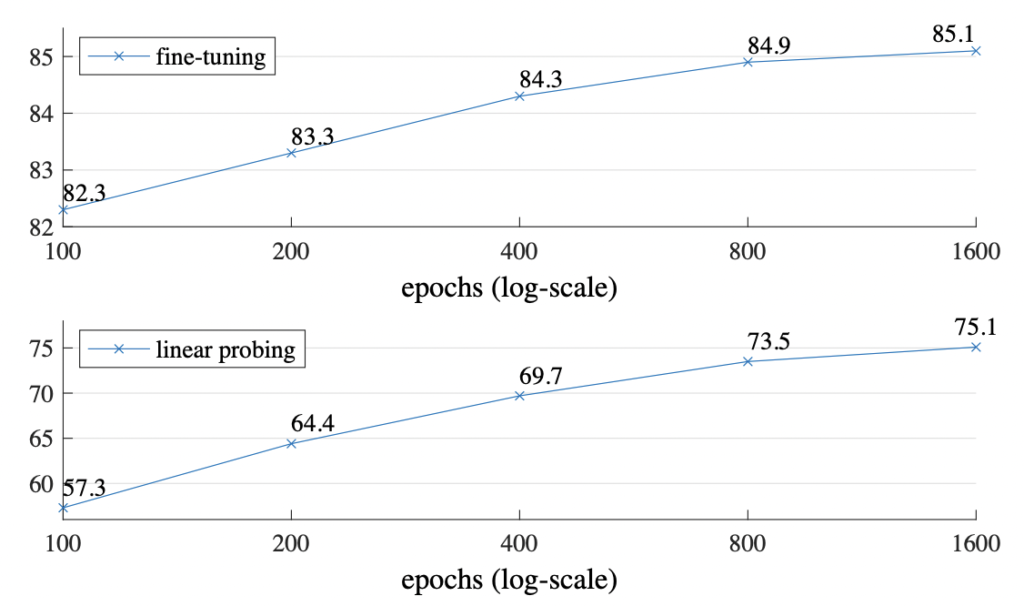
Training schedule. 지금까지 모든 실험은 800epoch의 사전학습에 기초한 결과였습니다. 그런데 아래 그림ㅇ은 학습 epoch의 영향을 보여주는 것인데요. 정확도는 꾸준히 향상되는 것을 볼 수 있습니다. 게다가 1600epoch에도 saturation이 발견되진 않았다는 특징이 있습니다.
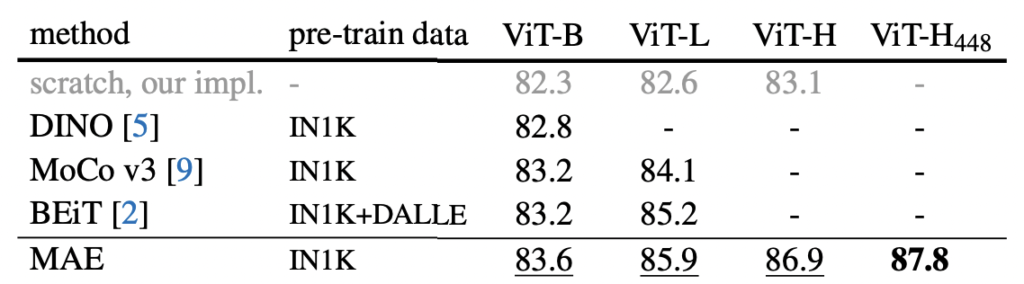
Comparisons with Previous Results
ViT를 기반으로 하는 fine-tunning 결과를 비교한 테이블을 아래 첨부하였습니다. 뭐 결론적으로 말하자면 MAE가 기존 연구보다 더 좋은 ㅅ성능을 보였다는 것을 보이고 싶은 건데요. 여기서 집중해야하는 건 BEiT에 비해서 훨씬 간단하고 빠르다는 것입니다. 에포크 당 3.5배 정도로 상당히 빠르다는 것을 알 수 있었습니다.
게다가 동일한 하드웨어에서 MAEsms 1600epoch를 31시간동안, MoCo v3는 300 epoch를 36시간동안 학습되었다고 합니다.
지금까지 굉장히 좋은 성능을 보인 MAE를 리뷰해봤습니다. 역시 simple is best라는 것을 또 새삼스레 깨닫게 된 논문인 것 같습니다.
리뷰 잘 봤습니다. 내용이 심플하면서도 효과는 좋은 것이 상당히 재밌네요.
다만 리뷰 내용에 이해하기 어려운 부분들이 있어 몇가지 질문 좀 드리겠습니다.
먼저 Ablation 실험을 어떻게 해석해야하는지 잘 모르겠습니다. 맨 처음 76.5 성능이 지도학습 기반으로 그냥 학습했다고 하셨는데 두번째 실험인 reconstruction loss를 적용하였을 때 82.5가 나왔다는 것은 supervised learning과 self-supervised learning을 동시에 수행한 일종의 multi-task learning이라고 이해하면 되는 것인가요?
그렇다면 84.9짜리의 fine-tuning은 도대체 무엇을 fine-tuning했다는 것인가요? 2번째처럼 한번에 multi-task learning을 하는 것이 아닌 supervised learning을 먼저 수행했다가 뒤에 self-supervised learning으로 fine-tuning을 한 것을 의미하는 건가요?
둘째로 line-probing이 무엇을 의미하나요? 그리고 fine-tuning의 경우에는 지도학습을 한 다음에 masked reconstruction loss를 활용한 것인가요?(아마 ablation쪽 fine-tuning과 같은 의미인 것 같은데..)
실험 결과에서 fine-tuning과 line-probing이 자주 나오는데 이것이 정확히 무엇을 의미하는지를 몰라서 결과의 의미가 어떤 의미를 가지는 지 잘 모르겠네요.
마지막으로 저 75% 이상의 masking이 기존의 masked auto-encoder보다 더 좋다면 Transformer backbone이 아닌 기존의 CNN 구조로 적용하였을 때도 이전보다는 더 좋은 결과를 보이는 실험은 없나요? 물론 인트로에서 CNN은 주변의 공간정보를 많이 활용하기 때문에 영상의 전반적인 문맥정보를 잘 보지 않으므로 Transformer를 활용하는 것이 더 좋았다고 했던 것 같은데, 75%정도로 masking한 것이면 CNN도 충분히 일부 영역만으로 reconstruction을 수행해야하니 주변 정보만으로는 reconstruction을 수행한다는 것이 어렵다는 생각이 드는데 어떻게 생각하시나요?
안녕하세요 리뷰 감사합니다
NLP 모델과 비전 모델의 차이에서 디코더의 역활이 비전에서는 reconstruction 하므로, 일반적인 recognition보다 의미적인 레벨이 낮다고 말씀해주셨는데, 픽셀간의 관계를 고려하여 픽셀을 되살리는 비전 영역의 테스크가 어느 부분에서 의미적인 레벨이 낮다고 평가되는지 궁금합니다.
일반적으로 비전 분야의 reconstruction은 주변 영역의 컬러만으로 되살릴 수 있기 떄문인가요?
둘째로 그렇다면 해당 reconstruction을 sematic segmentation mask로 변경한다면 해결할 수 있다고 생각하시는지 궁금합니다.
감사합니다
안녕하세요 주영님 좋은 리뷰 감사합니다.
마스킹을 통해 인접한 픽셀이 아닌 결국 전체적인 이해를 학습한다고 이해했습니다.
그렇다면 일반적인 ViT 계열보단 MAE를 이용한 방법론은 어떤 task에 더 유리한지 궁금합니다.
이 댓글을 쓰는 기준에서 대부분의 foundation들을 ViT계열이고,
MAE는 잘 보이지 않는다고 생각합니다.
그래서 MAE는 현재연구에서는 어떤 목적으로 쓰이는지 질문드립니다.
감사합니다.