Intro
SOD는 영상 내 가장 중요한 물체를 인지하는 것을 목적으로 하는 태스크로 컴퓨터 비전 분야에서 중요한 문제입니다. 해당 태스크는 물체 인식, 영상 검색, 슬램 등등 수 많은 어플리케이션에서 성공적으로 활용되었습니다. 하지만 텍스쳐가 적거나 배경의 노이즈가 심하거나 유사한 물체가 많은 경우에는 좋지 못한 결과를 보여준다는 문제점이 있었습니다. 최근에는 RGB 카메라의 본질적인 문제를 해결하기 위해서 Depth 정보를 함께 사용하는 움직임을 보이고 있습니다. Depth 정보와 함께 사용함으로써 도전적인 케이스에서도 높은 성능을 보여주는 모습을 보여주고 있습니다.
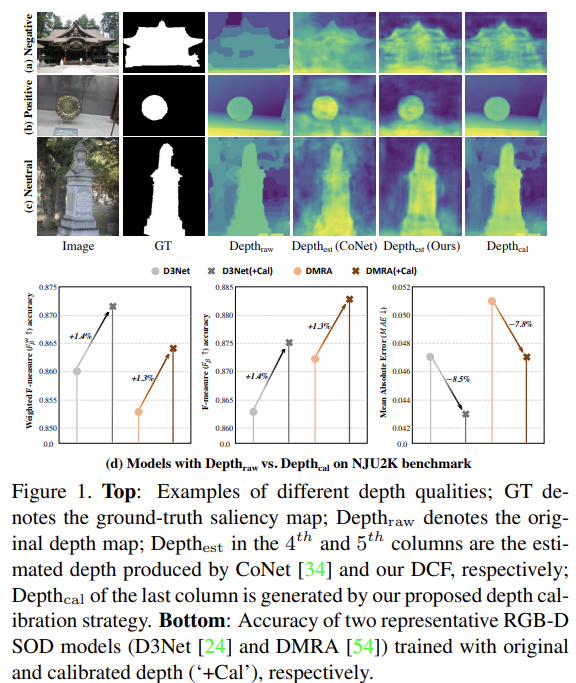
본질적으로 SOD에서 깊이 정보는 배경으로부터 물체 실루엣을 식별하기 위한 기하학적 정보를 가진 것에 잇습니다. 하지만 fig 1의 그림을 토대로 깊이 정보를 완전한 활용을 방해하는 두 가지 문제점을 캐치 할 수 있습니다. 1) 원본 깊이 정보는 물체의 경계면에서 노이즈가 발생한다. 이는 가려짐, 반사, 시점 등 깊이 센서의 한계로 발생합니다. 2) fig 1-(c)와 같이 주목해야할 물체와 배경간 구분이 차이가 적은 경우. 이러한 경우에는 RGB를 단독으로 사용한 것과 비교하여 잠재적 성능 향상에 큰 제약을 주게 됩니다.
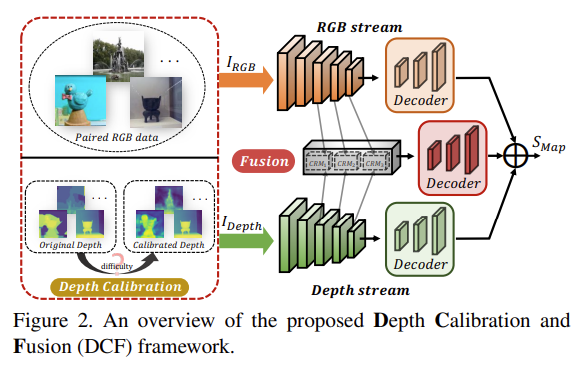
저자는 위의 두가지 문제를 해결하기 위해서 Depth Calibration and Fusion (DCF) framework를 제안합니다. fig 2에서 볼 수 있다시피 DCF는 RGB 기반의 salient object detection과 보정된 depth를 이용한 salient object detection의 융합으로 구성된 모듈로 구성됩니다.
Method
Overview
해당 방법론은 비교적 간단합니다. 노이즈가 심한 깊이 정보를 찾고, RGB 기반의 깊이 추정 모델로 보정하는 방법입니다. 여기서 노이즈가 심한 정도를 판단하기 위한 Difficulty-aware Selection Strategy과 이를 직접적으로 구분하고 보정하는 Depth Calibration Module로 구성됩니다. 최종적으로 RGBD와 RGB를 적절히 Feature Fusion한 Fusion Strategy로 구성됩니다.
Depth Calibration
앞서 다룬 바와 같이 SOD에서 깊이 정보를 사용할 경우, 물체의 공간적 정보를 알 수 있기에 어려운 케이스에서도 좋은 결과를 보여줍니다. 하지만 깊이 센서의 한계로 깊이 센서 자체의 노이즈가 발생하여 잠재적으로 향상될 수 있는 성능을 끌어올리지 못하는 문제가 있습니다. 저자는 이에 대한 해결책으로 깊이 정보를 보정하는 방법을 선택하였고, 효율적으로 보정하기 위한 2가지 문제점을 정의하였습니다. 1) 품질이 좋고/나쁜 깊이 정보를 어떻게 구분하는 방법을 어떻게 학습하는가? 2) 좋은 품질의 깊이 정보는 유지하되, 저품질의 깊이 정보에서 정확도가 떨어지는 정보를 보정하는 방법은 무엇인가? 저자는 이 두가지 문제점을 해결하기 위한 방법을 제안합니다.
Difficulty-aware Selection Strategy
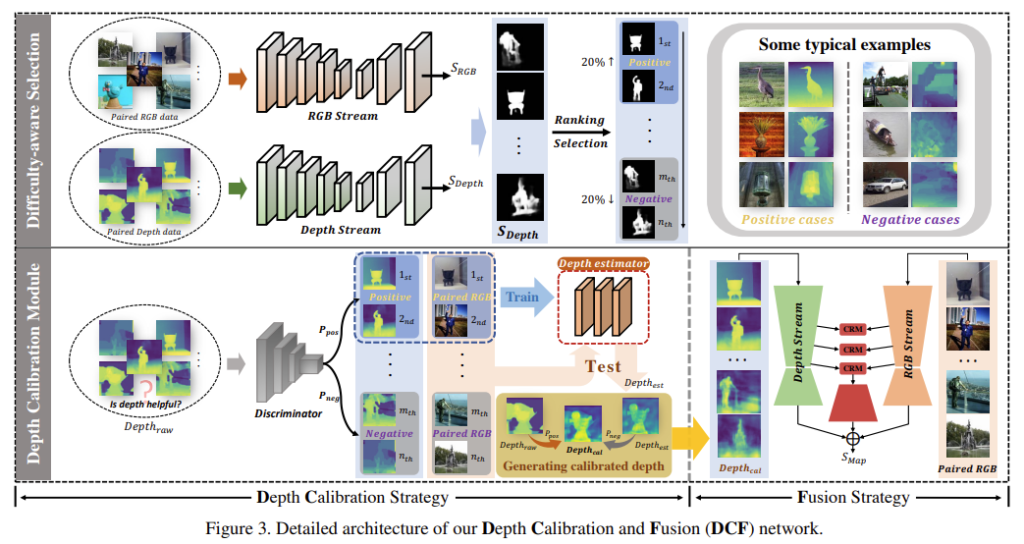
가장 먼저 Fig 3의 상단에서 보이는 바와 같이 데이터 셋으로부터 positivie sample과 negative sample을 구분 짓는 것을 목적으로 합니다. 구분된 샘플들은 깊이 맵의 신뢰도를 예측하는discriminator/classifier 학습하기 위해 사용됩니다.
구체적으로 설명하자면, 저자는 다른 두 도메인에서의 어려움을 평가하기 위해 동일한 구조를 가진 지도 학습 기반의 SOD 베이스 모델을 통해 학습을 진행합니다. 두 도메인의 SOD 정확도를 평가하기 위해 각 도메인 별 IoU를 GT와 측정하고, 깊이 정보를 기반으로 랭킹을 선정합니다. 여기서 상위 20%는 positive sample, 하위 20%는 negative sample로써 활용됩니다. 또한 깊이 정보의 IoU > 영상 기반의 IoU인 경우도 positive sample로 선정합니다. 이는 원본 깊이 정보가 RGB보다 풍부한 전경 정보를 가지고 있다는 뜻을 의미합니다.
Depth Calibration Module
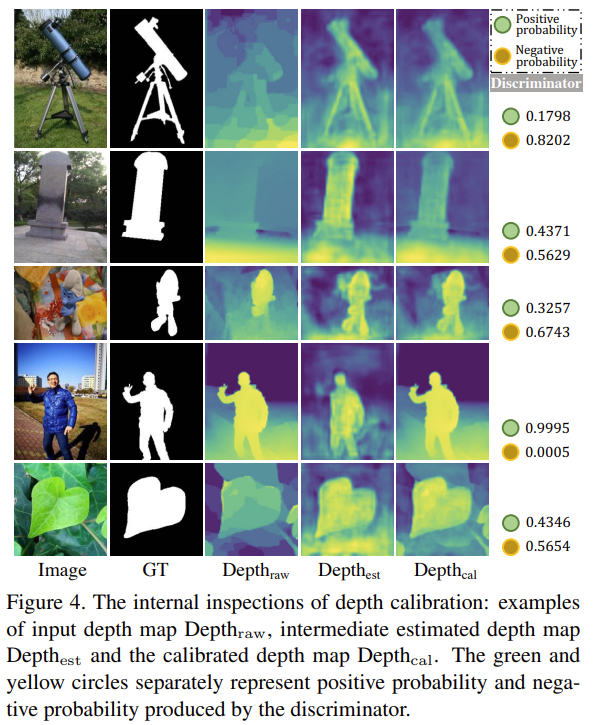
앞서 선별된 positivie/negative sample를 기반으로 ResNet18로 구성된 discriminator/classifier를 학습하여 깊이 정보의 신뢰성을 평가합니다. 그 다음, discriminator로부터 positive로 분류된 깊이 정보와 대응되는 RGB 영상으로부터 깊이 정보를 학습 및 추정합니다.
신뢰도가 떨어지는 깊이 정보인 경우, depth calibration module에서는 저품질인 깊이 정보를 그대로 사용하는 대신 RGB로부터 추정된 깊이 정보와 가중합을 통해 새로 생성합니다. 가중치는 classifier로부터 추론된 신뢰도를 이용합니다. 이에 대한 정성적 예시는 Fig 4에서도 확인 할 수 있습니다.
Feature Fusion
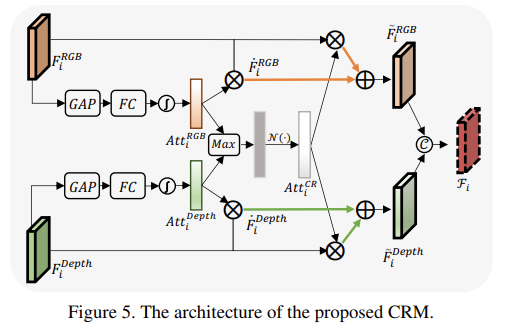
해당 섹션에서는 RGB와 보정된 깊이 정보에 대한 퓨전 모듈과 이를 이용한 SOD를 소개합니다. 퓨전 기법은 매우 심플합니다. 먼저, RGB와 보정된 깊이 정보를 개별적인 feature extractor를 통해 feature를 생성합니다. 생성된 피쳐는 어텐션을 이용한 퓨전을 적용하여 융합니다. 어텐션 기법은 Fig 5에서 보이는 바와 같이 보편적인 기법을 이용합니다. Global Average Pooling 수행 후, 간단한 FC를 태우고 softmax를 통해 수식 2와 같이 각 도메인 별 attention map을 생성합니다.
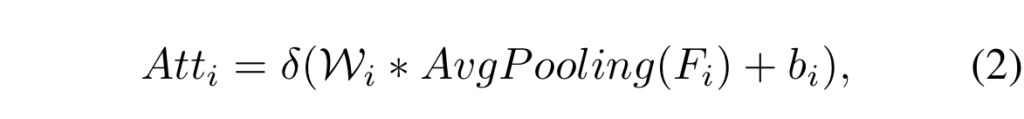
그리고 두 도메인의 어텐션을 융합하기 위한 전략으로 maximum function을 이용합니다. 두 도메인의 어텐션 중 높은 값을 선별한 후, 정규화를 진행합니다. 이를 cross-referenced channel attention vector라고 칭하며 수식 3과 같습니다.
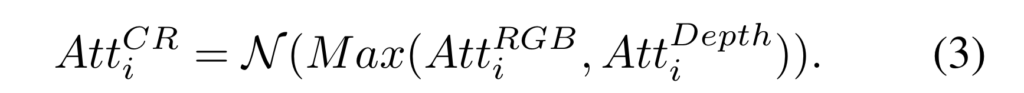
마지막으로 각 값은 fig 5와 같이 각 값들의 채널 측면에서의 어텐션 수행과 합으로 두 도메인의 정보가 융합된 특징을 생성합니다. 생성된 특징은 수식 5와 같이 1×1 conv를 통해 SOD에 대한 회귀를 수행합니다.
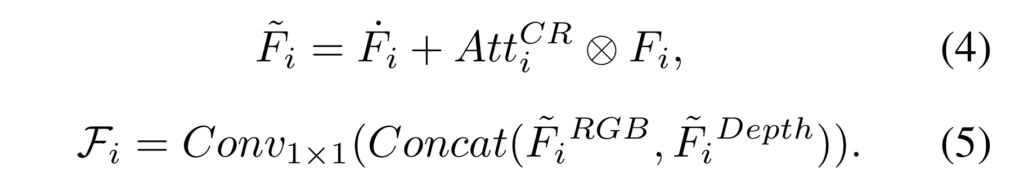
추출된 값들은 GT map S에 대한 전경과 배경에 대한 정보를 나누도록 수식 6-7을 수행합니다.
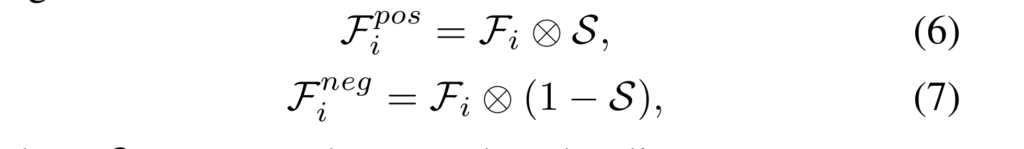
위의 수식을 통해 전경과 배경에 대해 집중하도록 만든 값을 triplet loss를 통해 학습을 진행합니다.
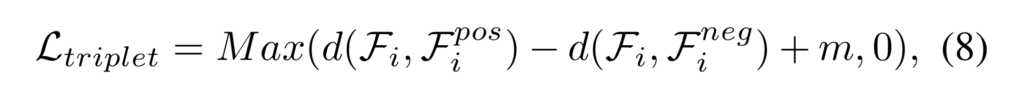
최종적으로 각 도메인 별 예측된 정보에 대한 binary cross-entrophy loss를 통해 각 도메인과 융합 특징에 대한 세부적인 정보를 학습 할 수 있도록 학습을 진행합니다.
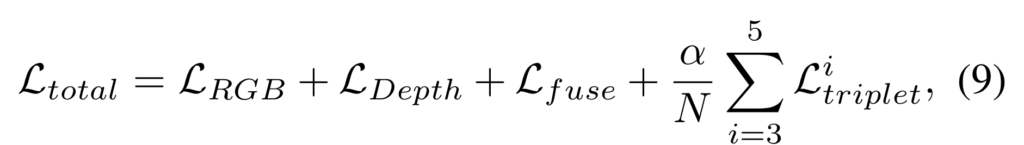
Experiment
실험은 5개의 RGBD 데이터 셋에서 수행되어집니다. (TODO 메트릭 설명 추가할 것)
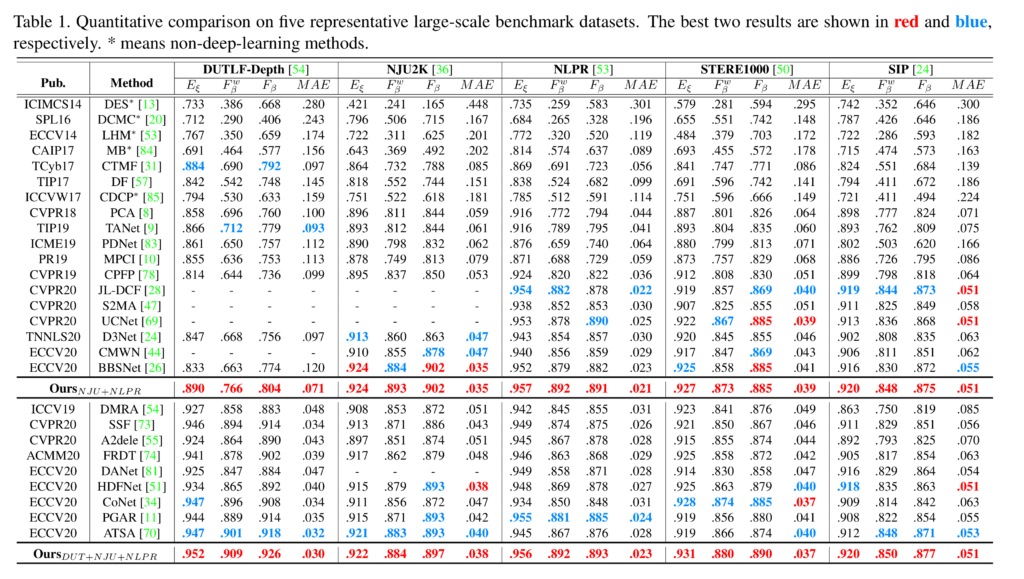
먼저 정량적인 결과 5개의 데이터 셋에서 가장 높은 성능을 보여주고 있습니다. 이를 통해 깊이 정보를 보정 효과를 증명합니다.

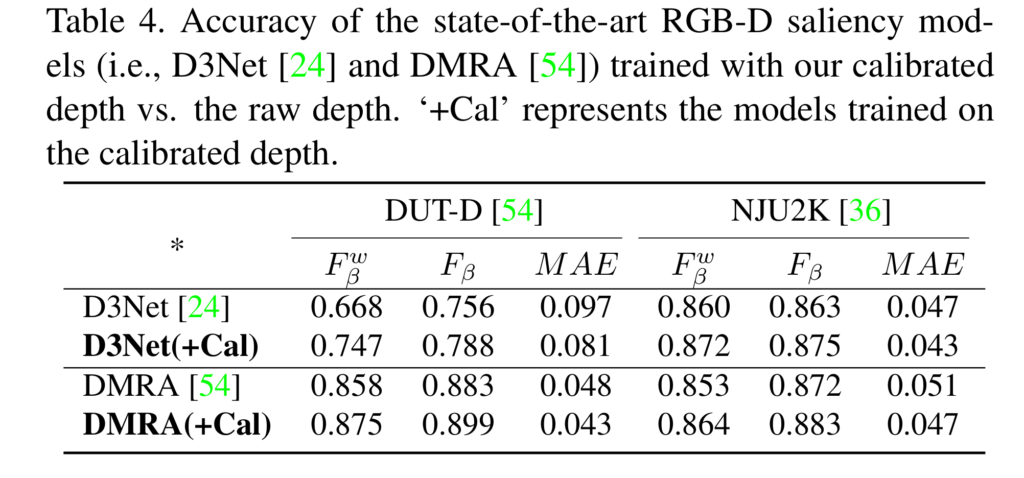
다양한 실험 중 가장 흥미를 이끌었던 실험은 Table 4의 실험입니다. Cal은 보정된 깊이 정보를 사용했을 때의 결과이며, 다른 SOTA 모델에서 보정된 깊이 정보를 사용했을 때, 성능 향상를 보여줍니다. 해당 기법은 SOD 뿐만이 아니라 다른 태스크에서도 충분한 효과를 보여줄 것 이라고 기대합니다.
좋은 리뷰 감사합니다.
‘ 1) 원본 깊이 정보는 물체의 경계면에서 노이즈가 발생한다. 이는 가려짐, 반사, 시점 등 깊이 센서의 한계로 발생합니다. 2) fig 1-(c)와 같이 주목해야할 물체와 배경간 구분이 차이가 적은 경우.’로 문제가 정의되었는데 각 문제의 해결이 결론적으로는 depth 뿐만이 아니라 RGB 정보도 활용하여(보정) 해결한다고 보면 되나요?
또한, Difficulty-aware Selection Strategy의 경우 positive와 negative를 비율로 설정하였는 데, threshold를 이용하여 positive와 negative로 나누는 것이 좋을 수도 있을 것 같은데 어떻게 생각하시나요?
Q. depth 뿐만이 아니라 RGB 정보도 활용하여(보정) 해결한다고 보면 되나요?
A. 넵, 맞습니다. RGB 영상은 depth 대비 콘텐츠 정보가 명확하게 등장하면 이를 이용한 깊이 정보인 경우 보다 콘텐츠를 기반으로 생성되기 때문에 depth sensor 대비 부드러운 표현과 명확한 표현이 가능하긴 합니다. 이는 depth sensor의 거친 표현은 depth sensor의 갯수에 의한 영향이 큽니다. 그렇기에 저자는 이를 보완하기 위해 RGB로부터 추론된 depth를 같이 사용하여 보정을 합니다.
Q. Difficulty-aware Selection Strategy의 경우 positive와 negative를 비율로 설정하였는 데, threshold를 이용하여 positive와 negative로 나누는 것이 좋을 수도 있을 것 같은데 어떻게 생각하시나요?
A. threshold는 사람의 판단에 의해 구분 짓는 것이기에 사용자가 판단 가능할 정도로 제한한 상황이라면 기존 방법보다 더 좋은 효과를 발휘하지만 범용적인 측면에서는 효과적이라고 보기 힘듭니다. 또한 해당 방법도 상하위 20%만 사용하는 것이기에 threshold를 사용하는 것과 다를바가 없으며, 적정 데이터를 추려야하는 상황에서는 기존 방법이 합리적이라고 생각합니다. 또한, 높은 score가 반드시 좋은 결과를 보여준다고 보기 힘들기 떄문에 모호하다고 생각합니다.
반대로 왜 threshold가 왜 더 좋다고 생각하나요?