Before Review
정말 오랜만에 Video Retrieval 논문 입니다. 거의 Temporal Action Localization 논문만 읽다가 간만에 비디오 검색을 위한 논문을 들고 왔습니다. 갑작스럽지만 Video Retrieval 논문을 빠르게 써보자는 의견이 나와 가장 최근의 방법론을 벤치마킹 하기 위해 읽게 됐습니다.
리뷰 시작하도록 하겠습니다.
Introduction
Video Retrieval은 요새 Text를 이용해서 찾기도 하고 Text와 Video를 같이 던지는 Multi-modal 연구도 많이 진행되는 것으로 알고 있습니다.
이번에 제가 가져온 논문은 Text나 Multi-modal은 아니고 단순히 Video를 던져서 유사한 Video를 찾는 Video-to-Video Retrieval 방법론을 가져왔습니다. Video-to-Video Retrieval 같은 경우는 연구 초기에는 Near-Duplicated Video Retrieval 이라고 해서 거의 복사된 비디오를 찾는 Task를 의미했습니다.

위의 그림 처럼 시각적으로 거의 동일한 장면들이 복사된 비디오를 찾는 것이기 때문에 검색 난이도가 그리 높다고 볼 수 없겠네요.
그러다가 Content-Based Video Retrieval 이라고 해서 이제는 단순히 시각적으로 동일하게 복사된 비디오가 아니라 Content가 유사한 비디오를 찾기 시작합니다.

위의 그림은 테러가 일어나서 시민들이 대피하고 있는 비디오를 모아둔 사진들입니다. 모두 시각적으로는 다르지만 모두 담고 있는 콘텐츠는 동일하기 때문에 검색 난이도가 더 어렵다고 볼 수 있습니다.
그리고 이러한 Content-Based Video Retrieval을 수행하기 위해서는 비디오의 long-range를 잘 커버하는 higher-level의 representation을 요구하게 됩니다.
무튼 이러한 상황에서 크게 Video-to-Video Retrival은 두가지의 방법론으로 나뉜다고 볼 수 있습니다.
먼저, Frame-level feature를 이용한 방식입니다. 비디오에서 고정된 개수의 일정 프레임을 샘플링 한 다음에 샘플링된 모든 프레임으로 부터 frame-level feature를 추출합니다.
예를 들어 한 비디오에서 64개의 프레임을 추출했다면 64개의 frame-level feature를 가지고 비디오간의 유사도를 결정합니다. 프레임끼리 one-to-one 방식으로 유사도를 계산하면 64 by 64의 유사도 맵을 계산할 수 있고 이를 잘 aggregate하여 비디오 단위의 유사도를 측정하게 됩니다.
Frame-level feature를 이용한 방법론들은 비교적 검색 정확도가 높습니다. 프레임 단위의 유사도를 모두 계산하기 때문이죠. 따라서 정확도는 높지만 searching time이 오래 걸리는 편 입니다.
다음으로는 Video-level feature를 이용한 방식입니다. 비디오 전체를 설명할 수 있는 하나의 벡터를 추출하여 이 벡터 끼리의 유사도 만을 가지고 검색을 수행하는 방식 입니다. Frame-level feature 방식에 비해서는 검색 정확도가 낮지만 하나의 벡터만을 이용해서 유사도를 검색한다는 측면에서 searching time은 비교적 짧은 편입니다.
본 논문의 방법론은 Video-level feature에도 적용할 수 있으며, Frame-level feature에도 적용할 수 있습니다.
그런데 사실 제안된 framework가 그냥 transformer를 사용하면서 memory bank를 이용한 contrastive learning이 전부라 방법론에 대해서는 그렇게 어렵지 않았고 얻어가는 내용이 많지는 않았습니다.
다만 한가지 insight를 얻을 수 있었던 부분은 기존에 ViSiL 이라고 해서 아직까지도 SOTA의 성능을 보여주는 Frame-level feature 방법론이 있습니다. 그 방법론에서는 triplet loss를 사용하여 학습을 진행했는데 본 논문에서는 NCE Loss를 활용했다고 합니다.
그 이유는 triplet loss 같은 경우는 hard negative를 직접 찾아주는 것이 아니면 학습이 잘 되지 않기 때문에 한계가 있지만 NCE loss 같은 경우는 그냥 negative sample만 충분히 많이 넣어주면 좋은 representation을 얻을 수 있기 때문에 retrieval에는 NCE loss를 활용한 contrastive learning이 더 적합하다는 주장이 있습니다.
무튼 서론은 여기까지 하고 이제 제안된 방법론에 대해서 말씀드리도록 하겠습니다.
Method
결국 retrieval의 핵심은 embedding function을 최적화 시키는 것이라 볼 수 있습니다. 무슨 소리냐면 두 유사한 비디오의 feature끼리 유사도를 측정했을 때 높은 유사도가 나올 수 있도록 embedding function을 학습 시키는 것입니다.
Embedding function이라는 것은 결국 back-bone feature로 부터 우리가 원하는 embedding space로 projection 시켜줄 수 있는 신경 레이어를 의미하는 것이죠. back-bone feature를 추출하는 것은 우리가 많이 하던 방식으로 frame 단위로 추출할 수 있습니다. ImageNet으로 학습된 weight를 가지고 VGG나 ResNet같은 Back-bone을 이용하면 이미지 단위의 괜찮은 feature를 추출할 수 있습니다.
본 논문에서는 i-MAC이라는 feature를 사용하는 데 이는 back-bone feature를 추출하는 과정에서 max 연산을 통해 maximun activation convolution이라 불리는 feature를 사용합니다. 사실 이 frame-level의 feature는 본 논문의 contribution이 아닌 이미지를 설명할 수 있는 여러가지 feature 기술 방법중 그냥 i-MAC이라는 방법을 사용했다고 보시면 됩니다.
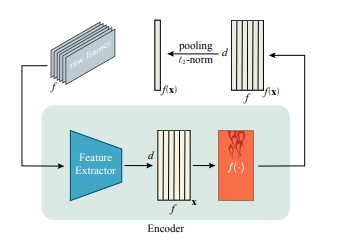
그래서 feature를 extraction 하는 부분 학습 과정에서 backward 되지 않습니다. 고정된 feature extraction 방식을 이용하여 feature를 얻어낸 것이죠.
진정으로 학습이 되는 부분은 이 frame-level feature를 projection 시키는 과정에서 일어납니다.
비디오를 이해하기 위해서 가장 중요한 것은 frame 간의 상호작용을 이해하는 것 입니다. 프레임 단일 장면만을 보고 feature를 기술하면 전체적인 맥락을 파악할 수 없기 때문입니다. 이러한 사실에 기인해 저자는 frame-feature 끼리의 dependency를 encoding 하기 위해 self-attention 방식을 사용합니다. 바로 transformer의 encoder 구조를 이용했다고 볼 수 있습니다.
원래 자연어처리에서 문장에서 단어를 토큰화 시켜 입력으로 넣어줬다면 비디오에서는 프레임을 벡터화 시켜 입력으로 넣어 long-range dependency를 encoding 했다고 보시면 됩니다. 하지만 이 역시 저자가 새로운 무언가를 제안했다고 보기는 어렵습니다. 단순히 transformer 구조를 사용했기 때문이죠. 어떠한 분석이나 insight가 있는 것이 아니라 self-attention을 사용하면 비디오의 전체적인 맥락을 파악할 수 있다는 주장으로 말이죠. 그래서 이 부분은 개인적으로 조금 아쉬운 것 같습니다.
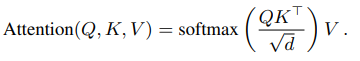
코드를 찾아보니 torch.nn 모듈에서 transformer layer를 지원하는 것을 확인할 수 있었습니다. 간단하게 입력 feature의 차원가 head의 갯수 등을 하이퍼파라미터로 설정해주면 transformer 기반의 encoder를 설계할 수 있었습니다. 저자도 이렇게 간단하게 frame 간의 dependency를 transformer 구조를 통해 모델링하고 있었습니다.
그렇다면 이 transformer를 통한 feature embedding은 어떻게 이루어지냐면
우선, frame-level feature는 그냥 encoder의 출력으로 나온 벡터를 그대로 사용합니다. transformer encoder의 입력과 출력 벡터의 차원은 동일하기 때문이죠. self-attention 과정을 통해 이상적이라면 비디오 검색을 수행하는 데 있어 보다 더 의미있는 프레임에 더 높은 weight가 부여되기를 희망하며 이러한 embedding을 수행했다고 볼 수 있습니다.
video-level feature는 그냥 transformer encoder를 통해서 나온 출력 벡터들을 평균내주고 normalize 해준 벡터로 사용해줍니다. 가장 간단한 방법이겠네요.
Loss를 설명드리기 전에 비디오간 유사도를 측정하는 부분에 대해서 알고 가야 합니다.
우선 frame-level feature를 이용해서 유사도를 계산하는 방식은 19년도에 나온 ViSiL이라는 논문의 방식을 그대로 사용하였습니다.
Chamfer Similarity(CS)
비디오에서 N개의 frame feature를 추출한다면 서로 다른 두 비디오 끼리 N by N similarity matrix를 생성할 수 있습니다. 프레임 하나씩 일대일 방식으로 유사도를 측정했다고 볼 수 있겠네요. 그리고 이 similarity matrix를 잘 aggregate 해서 score를 산출해야하는 데 방식은 아래와 같습니다.
- CS(col,row)=\frac{1}{N} \sum^{N}_{i=1} \max_{j\in [1,M]} S(i,j)
수식으로 보면 위와 같은데 , 설명을 해보자면 similarity matrix S\in R^{N\times M}이 있을 때 각 Row 별로 최댓값만 추출해오면 길이 N의 1D vector가 생성될 것이고 , 그 vector들의 원소를 가지고 평균 내준 것을 video-level similairty라고 보겠다는 것입니다.

Max-Mean 연산을 통해서 N by N의 similarity map으로 부터 하나의 스칼라 값인 similiarity score를 계산하는 것 입니다.
다음으로 video-level feature를 이용해서 유사도를 계산하는 방식은 간단합니다. 그냥 두 벡터끼리의 cosine similarity를 사용하는 것입니다.
무튼 frame-level feature를 이용하든 video-level feature를 이용하든 비디오간 유사도는 계산할 수 있습니다. 이러한 유사도를 최적화 시키는 Loss 함수는 바로 NCE Loss를 사용했다고 하네요.
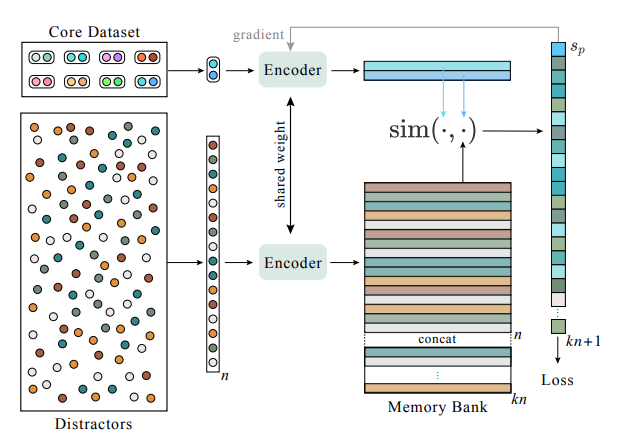
Video Retrieval Dataset 같은 경우는 Negative sample을 구하기 쉽습니다. 바로 연관 관계가 아닌 비디오들은 모두 Negative라고 고려할 수 있기 때문입니다. NCE Loss를 통해 representation learning을 수행할 때 중요한 것은 바로 Negative sample의 갯수이죠. 저자는 Memory Bank를 통해 Negative sample에 대한 feature를 모두 저장해두고 바로 바로 꺼내서 사용할 수 있는 구조를 만들었습니다.
NCE Loss는 저의 이전 리뷰들에도 많이 다룬적이 있으니 이번 리뷰에서 자세히 다루지는 않겠습니다.
학습은 이렇게 진행이 되는데 정리를 한번 해보자면
- Frame-level feature extraction은 i-MAC이라고 하는 고정된 feature representation을 이용하였습니다.
- feature embedding은 transformer 구조를 변형 없이 그대로 사용하여 retrieval에 적합한 feature로 embedding을 시켰습니다.
- Contrastive learning을 통해 유사한 비디오끼리는 유사도가 높아지는 학습을 진행하였습니다.
바로 이어서 보겠지만, 성능이 아주 높은 것도 아니고 framework 측면에서도 novelty가 많아 보이지는 않은 그러한 논문인 것 같네요.
Experiments
실험 section은 간단히 살펴보도록 하겠습니다.
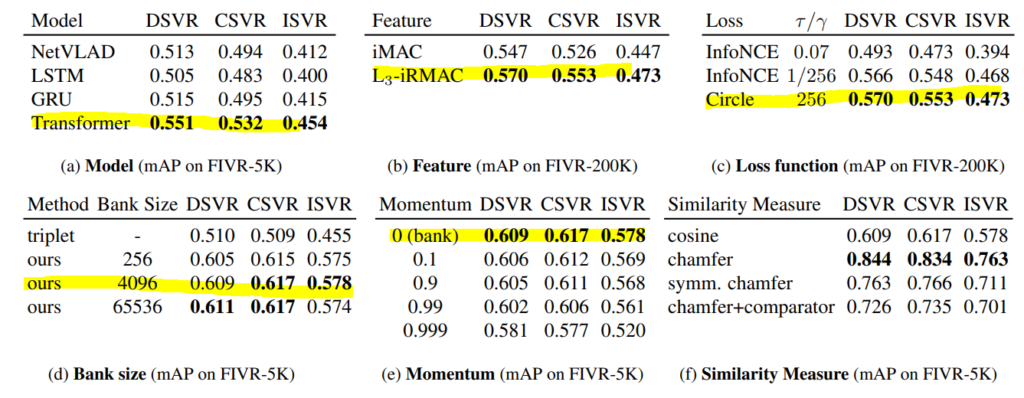
이 테이블이 제안된 방법론을 뒷받침하는 모든 실험을 담고 있다고 볼 수 있는데 먼저 table (a)를 보면 feature를 embedding 하는 모델에 대한 ablation을 볼 수 있습니다.
NetVLAD, LSTM, GRU, Transformer 중 Transformer의 성능이 가장 우수하다고 보여주지만 이는 단순히 여러개의 모델을 돌려본 것에 불과합니다. Transformer가 long-range dependency를 잘 modeling 한다는 장점이 있어서 단순히 사용했다고 하기에는 contribution 조금 약하지 않나 그렇게 생각이 듭니다.
다음으로는 feature extraction입니다. I-MAC과 L3-IRMAC feature를 비교한 실험입니다. L3-IRMAC이 좀 더 spatial한 information을 강조할 수 있고 이로인한 성능차이라고 주장합니다.
다음으로는 Loss 함수 입니다. 어떠한 insight가 있는 것은 아니고 단순히 특정한 하이퍼 파라미터 상황에서는 circle loss가 더 좋은 성능을 보이더라 이런식으로 서술이 되어 있습니다.
다음으로는 Memory Bank의 사이즈 즉, Negative Batch의 크기라고 보시면 됩니다. 흔히 알려진 사실 처럼 Negative Batch의 크기가 커질 수록 더 좋은 성능을 보여주고 있습니다. 그리고 하나 인상깊은 점은 실제로 triplet loss가 성능이 훨씬 떨어진다는 것을 확인할 수 있다는 것 입니다.
Hard Negative를 직접 찾아줘야 triplet loss가 잘 학습한다는 한계점을 앞에서 서술 했는데 이러한 주장에 힘을 실어주는 실험 결과인 것 같네요.
Memory bank를 원래는 모멘텀 방식으로 업데이트를 할 수도 있는데 저자는 하지 않는 것이 더 좋다고 실험을 통해 보여주고 있습니다.
Ablation은 이것이 전부 입니다. 조금 아쉬운 부분이 드는 것은 단순히 성능 뿐만 아니라 정성적 결과도 같이 나열하여 설명을 뒷받침 했다면 어땠을 까라는 생각이 드네요.
Conclusion
사실 본 논문의 Contribution이 정확히 무엇인지는 저도 잘 모르겠습니다. 잘 된다는 모듈들을 붙여서 논문을 쓴 것 같은 느낌이 강하게 들어서 그런것 같습니다. 아직 Video-to-Video Retrieval 분야가 활발하지 않은 탓에 그런 것도 같네요. 더 좋고 참신한 후속 연구들이 계속 나왔으면 좋겠습니다.
이상으로 리뷰 마무리 하도록 하겠습니다.