이번에는 오랜만에 GAN 논문으로 가져왔습니다. 해당 논문을 읽게 된 계기는 facebook에서 우연히 홍보?글을 읽게 됐는데 생각보다 내용이 심플하면서도 참신한 것 같아 궁금해서 읽어보았습니다.
Intro
GAN을 활용한 분야는 너무나도 많이 존재를 합니다. 가장 대표적으로 Image Translation, Image Manipulation, Image generation 등등이 존재를 하죠. 이중에서 Conditional GAN을 활용하는 Image Translation의 경우에는 A도메인의 영상을 Generator에 입력으로 넣어 B 도메인의 가짜 영상을 생성한 후, 이 생성된 가짜 영상과 원래의 입력 영상(즉 real A 이미지)를 concat하여서 Discriminator의 입력으로 넣어줍니다.(아래 그림 참고)
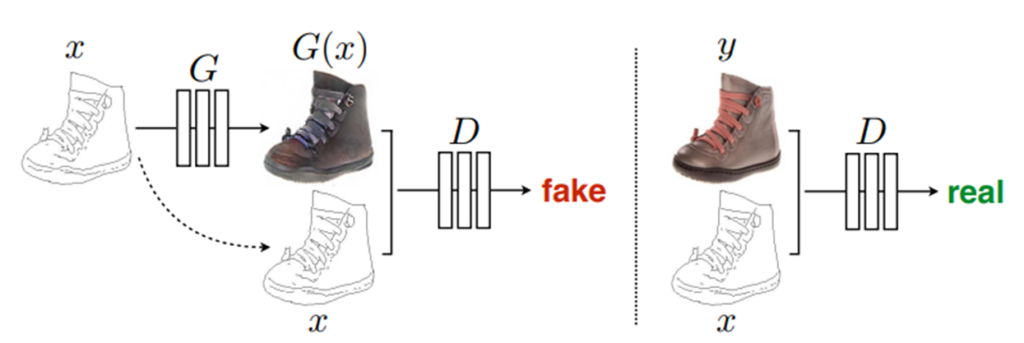
그 후 Discriminator는 이 영상이 진짜 영상인지 가짜 영상인지를 잘 구분하는 방향으로 학습하고 Generator는 이를 속이는 형식으로 학습하면서 매우 그럴 듯한 영상을 생성할 수 있게 되는 것입니다. 위의 방법론을 활용하는 가장 대표적인 방법론으로는 매우 유명했던 Pix2Pix가 있습니다.
CC-FPSE 라는 방법론은 Fake B와 Real A의 concat을 하는 것이 아닌, Real A를 새롭게 제안한 Embedding Layer를 태워서 projection 시키는 방향으로 Discriminator에게 학습을 시켰다고 합니다.
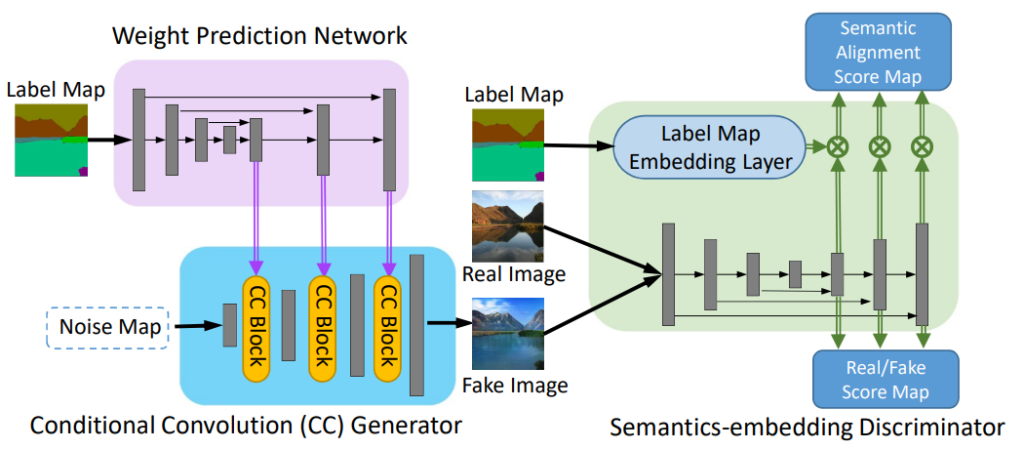
마지막으로 OASIS라는 방법론에서는 Discriminator를 Semantic-Segmentation을 수행할 수 있도록 하는 Encoder-Decoder 구조의 모델로 제안함으로써, Fake image에 대하여 어떠한 label map을 생성하도록 학습을 수행하였다고 합니다. 그리고 이렇게 추정된 label map은 Generator 입력에 사용된 GT label map과 segmentation loss를 적용하여 학습을 수행하게 되죠.
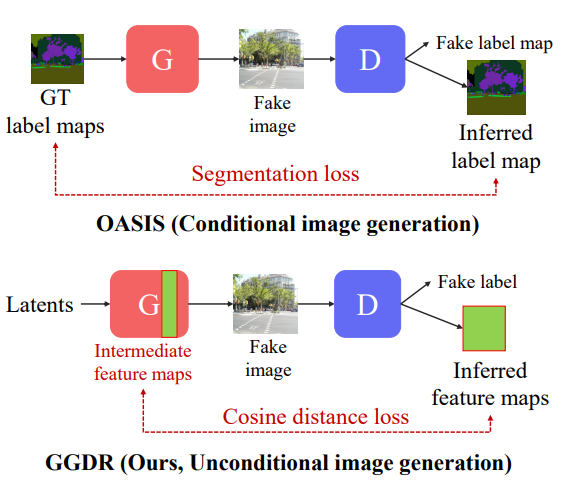
이러한 OASIS 방법론은 일종의 multi-task learning을 하게 됨으로써 Discriminator의 표현력을 높이고, 덕분에 경쟁 관계인 Generator의 성능도 함께 좋아지게 됩니다. 하지만 이러한 방법들의 단점은 바로 Conditional GAN이라는 점입니다.
즉 Generator에 사용하는 input image(해당 논문에서는 Semantic Label로 RGB 영상을 생성하는 테스크를 수행하니 Semantic Label이라고 생각하시면 좋겠습니다.)가 있는 경우에만 위에 제가 언급했던 방법들을 활용할 수 있는 것이죠.
이러한 매우 큰 제약은 Unconditional GAN 방법론들에는 적용하기 어렵다는 단점으로 찾아오게 됩니다. 여기서 말하는 Unconditional GAN이란 Generator의 입력으로 어떠한 Image가 들어오는 것이 아닌, Latent vector가 입력으로 들어오는 상황을 의미합니다.
이러한 상황에서는 입력 영상이 아닌 어떠한 latent vector가 들어오게 되니 discriminator에게 도움을 줄만한 수단이라고는 딱히 없는 상황이 되버리는데, 제가 리뷰하고자 하는 논문에서는 이러한 문제를 해결하기 위한 새로운 방법을 제안합니다.
바로 Generator의 feature map을 일종의 semantic label로 활용하자는 전략입니다. 그림1 하단을 살펴보시면 Generator의 입력으로 latent vector가 들어가기 때문에 Discriminator에 Decoder를 붙여 어떠한 semantic segmentation을 예측하더라도 비교할 대상이 마땅히 없는 상황입니다. 하지만 여기서 Generator의 feature mpa을 Pseudo Label로 활용하여 비교하는 loss term을 추가함으로써 Discriminator의 성능을 향상시켰다 라고 이해하시면 되겠습니다.
사실 이게 논문의 끝이라 방법론에 대해서는 자세히 설명할 부분이 없습니다 허허. 이대로 리뷰 마치고 싶지만, 과연 Generator가 Pseudo Lable로서 역할을 잘 수행할 수 있는가?에 대하여 궁금하실 것 같아 이에 대한 내용들을 다뤄보겠습니다.
Dense semantic supervision in unconditional GAN
일단 먼저 Unconditional GAN에서도 Discriminator에게 Semantic Label로 추가적인 학습을 수행하면 성능이 좋아지는가?에 대한 테스트를 논문에서는 수행합니다. 이는 기존의 Conditional GAN에서는 OASIS와 같이 semantic label로 discriminator를 추가적으로 학습하는 것이 더 좋은 성능을 야기한다는 것을 입증했지만, Unconditional GAN에 대해서는 그 누구도 시도를 해보지 않았기 때문입니다.
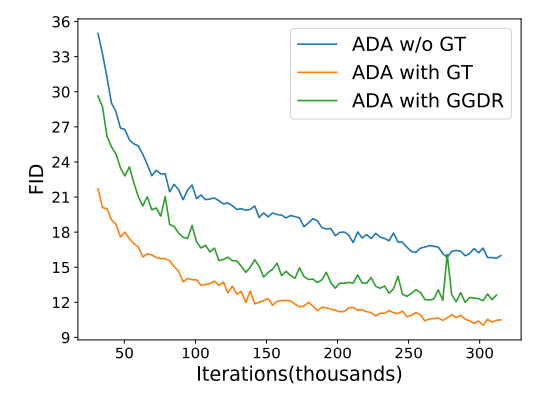
저자는 가장 대표적인 Unconditional GAN인 StyleGANv2를 가지고 학습시킬 때 각각 Discriminator에게 semantic label를 제공하지 않았을 때, 하였을 때, Generator의 feature map을 pseudo label로 제공하였을 때에 대하여 FID 성능을 나타냅니다.
보시면 semantic label를 제공하지 않았을 때(파란색)가 제공하였을 때(초록색) 보다 성능이 더 낮은 것을 볼 수 있습니다.(FID는 값이 낮을수록 좋습니다.) 이러한 관점에서 Unconditional GAN도 역시나 Discriminator에게 semantic label로 추가적인 학습을 하는 것이 Generator의 생성 관점에서 장점이 될 수 있다는 것을 증명하였습니다.
게다가 더더욱 놀라운 점은, 저자가 제안하는 방식인, Generator의 feature map을 pseudo label로 제공하여 학습시키는 경우가 실제 Ground Truth를 제공하는 것보다 더 우수한 FID 점수를 달성했다는 점입니다. 즉 Generator는 Discriminator를 향상시키는데 있어 매우 중요한 semantic 정보를 제공하고 있다는 것을 정량적으로 확인할 수 있게 됩니다.
Analysis of generator feature maps
위에서 저희는 Generator의 feature map이 Discriminator에게 상당히 우수한 semantic 정보를 제공한다는 것을 정량적으로 알게 되었습니다. 그렇다면 정성적으로 Generator의 feature map은 어떻게 생성된 것일까요?
이에 대한 궁금증을 파악하고자 저자는 Generator의 feature map을 아래와 같이 시각화를 하여 확인합니다.

보시면 Generator가 16×16부터 128×128 feature map을 생성해나갈 때의 feature map을 시각화 한 것입니다. 시각화 한 방식으로는 K-means clustering을 통해 군집화를 시켜서 마치 semantic segmentation처럼 표현했다고 합니다.
보시면 low-resolution feature map에서는 Coarse한 정보들을 위주로 품고 있으며 점차 고해상도로 가면 갈수록 디테일한 정보들을 생성해 나가는 것을 쉽게 확인하실 수 있습니다.
저자는 이러한 결과를 토대로 generator의 feature map을 semantic label로 활용해도 되겠다는 판단을 하였고 그 결과 좋은 성능에 달성할 수 있었다고 합니다. 심지어 GAN의 기술이 많이 발전해서 인지는 몰라도 학습의 완전 초기에서 역시 Generator의 feature map이 대략적인 semantic 정보를 벌써 생성하고 있다는 점입니다.

이러한 점 덕분에 two-stage로 나누어서 학습할 필요 없이 end-to-end로 한번에 진행해도 학습에 크게 문제가 되지 않은 듯 합니다.
Generator guided discriminator regularization
그럼 이제 간략하게 실제 Generator와 Discriminator가 어떤식으로 구조를 가지고 있고 학습하는지에 대하여 방법론에 대해 설명하고자 합니다.
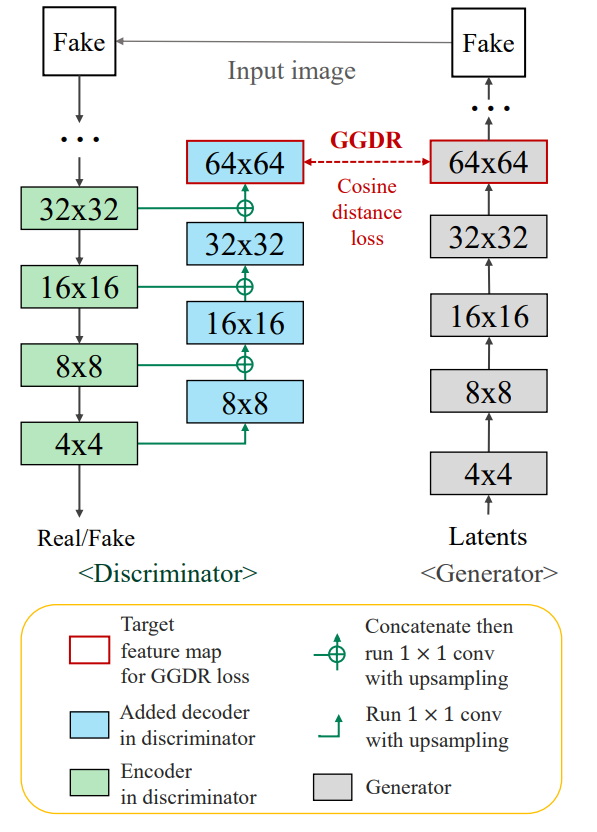
일단 모델 구조는 그림4와 같습니다. 좌측은 Discriminator를, 우측은 Generator를 의미하는데, Discriminator는 위에서 아래로 forward가 진행되고 있으며, Generator는 아래에서 위로 forward가 됩니다. 이는 Discriminator는 Generator가 생성한 이미지를 입력으로 받는 반면에 Generator는 어떠한 latent로부터 4×4부터 영상을 생성하기 때문에 저렇게 그림을 표현한 것 같습니다.
아무튼 일반적인 Discriminator라면 4×4에서 이제 real/fake 구분 여부에 대한 binary classification을 수행하게 될 텐데, 제안하는 방법론은 4×4에서 다시 upsampling 과정을 거쳐 64×64 사이즈의 feature map까지 생성하게 됩니다.
이때 Discriminator의 decoder는 매우 단순하게 1×1 convolution이 포함된 upsampling layer로 구성되었다고 합니다. 이는 해당 task의 목표가 generator가 더 사실적인 영상을 생성하는 것이 목표이지, discriminator가 정확한 semantic label을 생성하는 것이 목표가 아니기 때문에 굳이 deep하고 복잡하게 decoder를 설계한 것은 아니라고 합니다.
loss function으로는 흔히들 알고 계시는 Adversarial loss와 논문에서 제안하는 generator의 feature를 discriminator의 label과 비교하는 loss로 구성되어 있습니다. 수식으로는 아래와 같습니다.
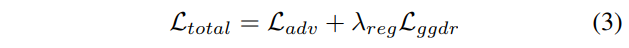
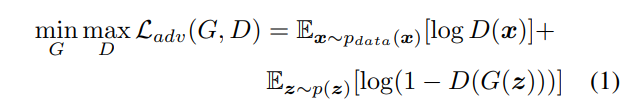
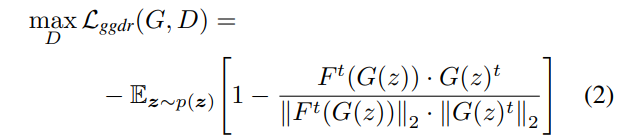
여기서 ggdr loss는 cosine similarity를 비교하는 식으로 진행됩니다.
Experiments
실험섹션을 정리하면서 마무리 짓도록 하겠습니다.
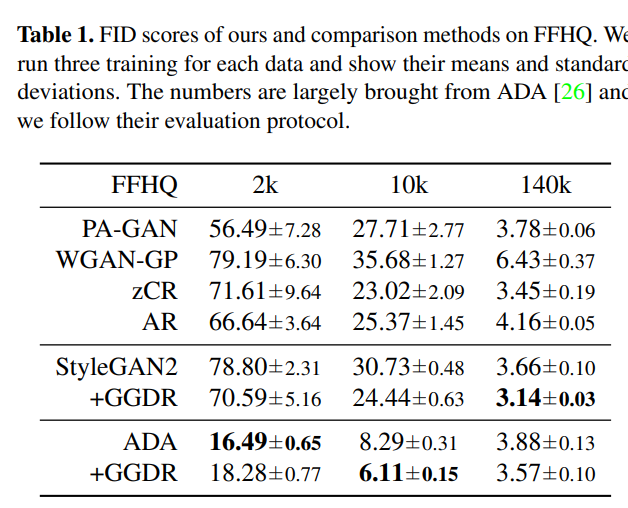
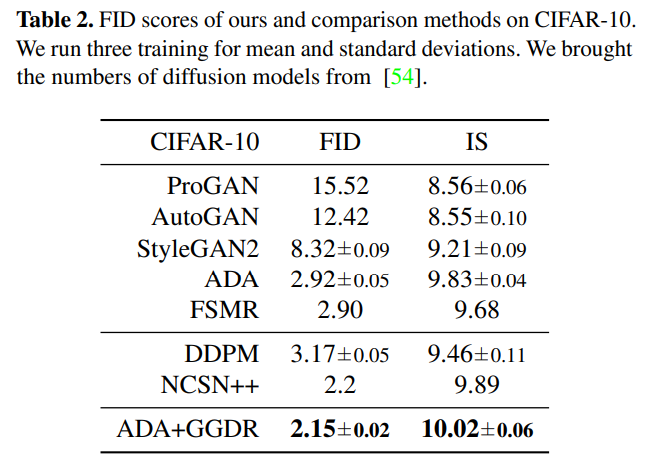
표1, 2는 각각 FFHQ와 CIFAR-10에 대하여 Image Generation을 한 결과입니다. 여기서 표1에 2k, 10k, 140k는 학습에 사용한 이미지 수라고 합니다. GGDR 기법을 적용하게 될 경우 ADA 2k를 제외하고는 모두 뚜렷한 성능 향상이 있는 것을 확인하실 수 있습니다.

다음은 정성적인 결과입니다. LSUN에서 Horse가 중심이다 보니 승마하는 사람에 대해서는 부자연스러운 것을 볼 수 있지만 그 외에는 모두 다 실제 사진처럼 잘 만들었네요.
Limitation?
GAN 논문은 항상 논문만으로 볼 땐 그럴 듯 하지만, 실제로 가져다가 사용할 때는 많은 실망을 하게 됩니다. 그래서 limitation 란이 있을 때면 항상 주의깊게 보게 되는데 내용은 간략합니다.
Generator를 pseudo semantic label로 활용하는 것이니, 만약 generator가 너무 적은 량의 데이터로 학습하거나 또는 학습 초기에 training collapse에 빠져버리게 되면 좋지 못한 성능을 달성한다는 것이죠. 하지만 최근에 나온 GAN 방법론들은 다양한 테크닉과 구조 등으로 많은 단점들을 해결하였기에 자신들이 제안하는 방법론들이 잘 동작할 것이다 라는 희망찬 얘기로 끝을 냅니다.
결론
Simple is best. 방법론 자체가 정말 심플해서 가벼운 마음으로 읽기 좋았으며 이렇게 단순한 컨셉으로 우수한 성능을 달성했다는 것에서 모처럼 만족스러운 논문을 읽은 것 같습니다.
나중에 Image Translation할 때 한번 적용해봐도 좋을 것 같네요.
latent vector 가 generator 의 입력으로 들어가는거면 세그멘테이션 라벨은 어떻게 입력으로써 쓰이는건가요?
latent vector가 generator의 입력으로 들어간다는 의미는 unconditional gan이란 의미이고 그렇기에 segmentation label을 입력으로 사용하지 않습니다.
다만 discriminator에 추가적인 디코더를 붙여서 어떠한 infered semantic label을 실제 GT semantic label과 비교는 수행할 수 있게 됩니다.
해당 논문에서 이러한 관점에서 generator의 feature map과 infered semantic label을 비교하는 loss텀을 활용한 것이구요.
안녕하세요 좋은리뷰 감사합니다
CC-FPSE 라는 방법론의 작동 과정이 약간 이해가 되지 않아 질문 드립니다.
Discriminator는 보통 real 혹은 fake를 판별하기 위한 레이어로 알고있었는데, 기존 방법론이 fake B와 real A를 concat 했다는 부분이 이해가 어렵습니다. 혹시 제가 잘못 이해한 부분이 있는지 궁금하네요
감사합니다
제가 작성한 리뷰의 제일 첫 번째 그림 보시면 pix2pix가 generator로 생성한 fake b와 함께 generator의 입력으로 사용했던 real a를 함께 합쳐서 discriminator에게 제공하는 것을 볼 수 있습니다.
이것이 가장 흔한 conditional gan의 방식으로 CC-FPSE에서 이해하기 어려우신 부분이 fake B와 real A를 concat했다는 부분이시라면 그건 pix2pix도 동일하니 pix2pix가 학습하는 방법을 떠오르시면 좋을 것 같습니다.