
오늘 제가 소개해 드릴 논문은 [ECCV 2020] 에서 소개된 ‘Feature-metric Loss for Self-supervised Learning of Depth and Egomotion’ 이라는 논문입니다. 저번주 세미나때 소개드린 논문이긴 하지만, 이 논문의 특징이 새로워서 글로 남기고 싶어서 이렇게 리뷰를 하게 되었습니다. 그럼 시작하겠습니다.
본 논문은 self-supervised monocular depth estimation 방법론입니다. 보통 해당 방법론에서는 한장의 이미지가 input으로 들어가기 때문에 해당 image의 앞 뒤 프레임 사이의 pose변화도 추가적으로 예측을 해 주어야 합니다.
예측한 pose 변화를 통해 image를 target frame으로 warping 시키고, 기존 이미지와 변환된 이미지 사이의 photometric loss를 구하는 방식을 사용합니다.
하지만 흔히 사용되는 photometric loss에는 치명적인 단점이 존재한다고 저자는 언급하고, feature-metric loss라는 새로운 loss에 대해 제안합니다. 이를 통해 성능 향상을 이뤘는데 자세한 내용은 아래에서 설명 드리겠습니다.
Introduction
기존에 self-supervised에서 흔히 사용하던 photometric loss에는 문제점이 존재합니다.
바로 source view에서 warping을 통해 구한I_{s->t} 와 I_t 사이의 photometric loss 가 정확하지 않다는 문제점입니다.
심지어 특정 pixel 에서 이러한 photometric loss가 작다고 해서 그 pixlel에서 정확한 depth를 보장하는 것도 아닙니다.
이는 texture less한 영역 때문입니다. 이런 texture less 영역에서는 특정 pixel과 그 주변 pixel들이 비슷한 픽셀값을 가지게 됩니다. 따라서 source->target warping이 조금 잘못 이루어 졌음에도 photometric 가 낮게 나올 수 있습니다.
monodepth의 smoothness loss와 같은 방법론들이 이러한 문제를 조금 완화해 주긴 하지만,
이러한 smoothness loss 같은 방법론은 object 경계 주변에서 disparity가 지나치게 부드럽게 나오는 결과를 초래합니다.
저자는 이러한 textureless 영역에서 representation에 한계가 있다고 판단하였습니다. pixel 값으로는 주변 pixel과의 차별성이 낮다고 판단하여, textureless한 영역에서도 feature representation을 잘 배울 수 있도록 하는 새로운 loss를 제안하였습니다. 그것이 바로 feature-metric loss 입니다.
추가적으로 저자는 아래의 식을 통해 기존의 Photometric loss의 문제점을 지적하였습니다.
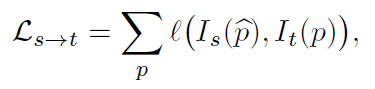
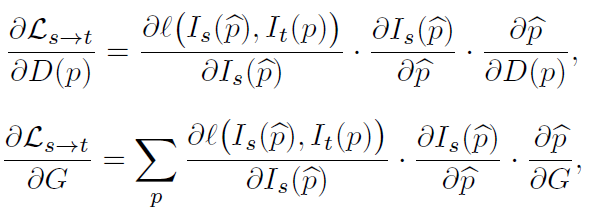
위의 Photometric loss를 Depth와 camera egomotion으로 각각 미분하였을때의 결과 식입니다.
두 식 모두 중간항에 공통적으로 warping했을때 image에서의 pixel gradient에 해당하는 항이 존재합니다.
texture less한 영역에서는 pixel gradient가 0에 수렴하므로, photometric loss의 gradient도 0에 수렴하게 됩니다.
이에따라 해당 영역에서는 학습이 잘 일어날 수 없게 되고, 경우에 따라서는 local minima에 빠지게 될 가능성도 존재하게 됩니다.
이 식을 통해서 photometric loss의 한계에 대해 설명하고 새로운 loss인 feature-metric loss 를 소개하게 됩니다.
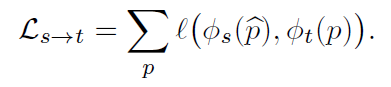
feature-metric loss 를 계산하기 위해서는 주어진 image에서 정확한 feature representation이 이루어 져야 합니다.
이를 위해 저자는 encoder-decoder 구조인 FeatureNet을 추가로 설계하였습니다.
결과적으로 전체 network는 FeatureNet, DepthNet 그리고 PoseNet으로 이루어 져 있습니다.
전체 구조는 아래 Method에서 그림과 함께 설명드리겠습니다.
Method & Loss
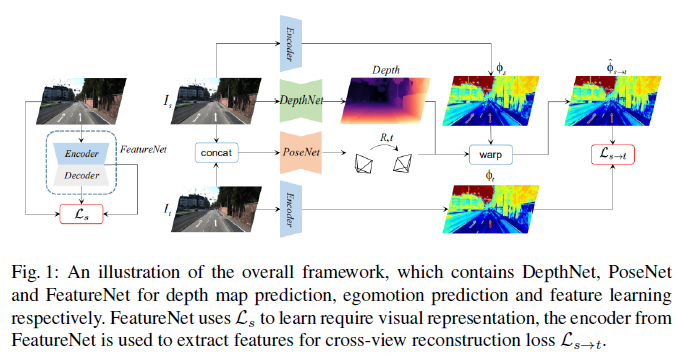
전체 pipeline은 위와 같습니다.
FeatureNet에서의 encoder-decoder중에서 encoder 부분이 위에서 소개드린 feature-metric loss를 계산하기 위한 feature represenatation 함수로 사용되게 됩니다. 위의 그림을 보시면 직관적으로 이해하실 수 있습니다.
왼쪽에 있는 FeatureNet에서는 모델이 image의 Feature를 잘 표현할 수 있도록 학습이 진행됩니다.
그리고 오른쪽에서는 PoseNet으로 예측한 Pose를 통해 source image에서의 feature를 target image 쪽으로 warping 시키고, 이 둘 사이에서 feature-metric loss를 구하게 됩니다.
본 모델을 전체가 1-stage의 end-to-end 방식으로 training이 진행되게 됩니다.
그렇다면 각각의 loss에 대해서 설명 드리겠습니다.
FeatureNet – Single-view reconstruction
FeatureNet은 encoder-decoder 의 구조로 구성되어 있습니다.
- 이중에서 encoder는 주어진 image에서 deep feature extractions의 역할을 하게 됩니다.
한마디로 image의 feature를 만들어 내는 부분이라고 생각하시면 됩니다. - 반대로 decoder는 생성된 deep feature를 가지고 다시 image를 reconstruction 하는 역할을 합니다.
feature->image reconstruction을 진행하는 것입니다.
앞서 말씀드린 것 처럼, 이 encoder는 나중에 feature map간의 loss를 계산할 때 feature map을 생성하는 역할을 하게 됩니다.
이러한 feature representation 역할을 하는 FeatureNet을 학습하기 위해서는 3가지 loss가 필요합니다.
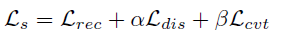
1) Image reconstruction loss
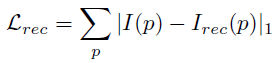
기존 image와, encoder-decoder 를 통해 reconstruction된 image를 비교하는 loss 입니다
2) Discriminative loss
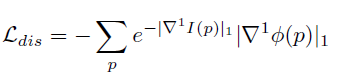
학습이 되어야 하는 FeatureNet이 명시적으로 더 큰 gradient를 가지도록 하기 위한 loss 입니다.
추가적으로 앞의 exp term을 통해 low-texture 영역에서 더 큰 가중치를 줍니다.
3) Convergent loss
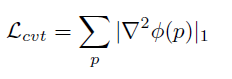
feature gradient 의 smoothness를 위한 loss입니다.
이계도함수를 활용하였고, feature gradient에서의 일관된 기울기를 보장함으로써
효과적이고 안정성 있는 학습을 위한 loss 입니다.
Total Loss
최종 loss에 대한 설명입니다.
최종 loss는 FeatureNet 학습을 위한 loss인 L_s 와 feature-metric loss인 의 L_{s->t}합입니다.
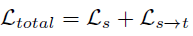
여기서 더 높은 성능을 위해 feature-metric loss를 기존의 photometric loss와 결합해서 사용할 수 있습니다.
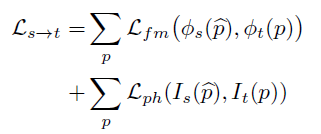
각각의 loss는 아래와 같습니다.
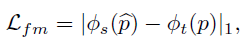
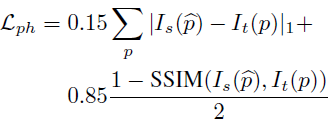
추가적으로 occlusion 문제를 해결하고자,
monodepth2의 min loss를 사용할 수 있습니다. 이때는 2개의 source view가 사용됩니다.
min loss에 대한 자세한 설명은 제 monodepth2 논문리뷰를 참고하시면 좋을 거 같습니다.
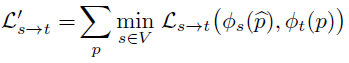
이와 같은 방식을 통해,
FeatureNet은 image의 feature를 잘 표현하도록 학습이 되는것이고,
FeatureNet의 encoder를 활용해서 기존의 photometric loss가 아닌, Feature map끼리의 비교인 feature-metric loss를 통해서 textureless한 영역에서 더 정확한 depth를 예측할 수 있게 되었습니다.
Experiment

우선 monodepth2 와의 정성적인 비교입니다.
벽, 표지판 등의 texture less한 영역에서 더 정확한 depth를 예측한 것을 볼 수 있습니다.
또한 사람, 기둥 등의 영역에서 경계부분이 더 선명하게 예측이 된 것을 볼 수가 있는데,
이는 monodepth2에서 smoothness loss를 사용해서 생긴 경계부분이 지나치게 부드러워 진 현상이 본 논문에서는 나타나지 않은 것이라고 볼 수 있습니다.
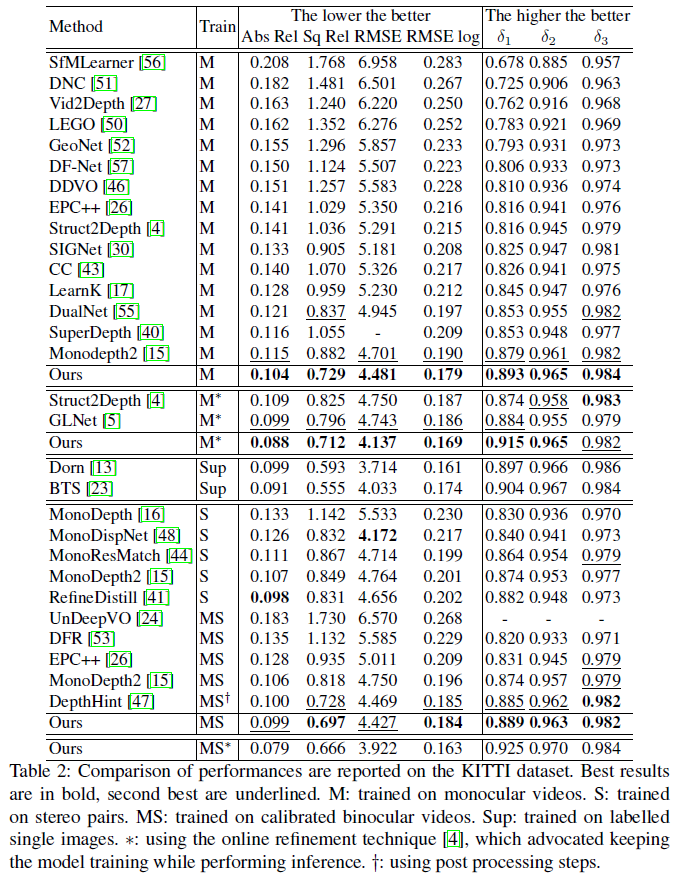
이는 다른 방법론들과의 성능 비교입니다.
모든 부분에서 성능 향상이 이루어졌지만 특히 Sq Rel 성능지표에서의 성능 향상이 많이 이루어진 것을 볼 수 있습니다.
Sq Rel = mean(|p_i-g_i|^2/g_i)
해당 성능지표는 위 식과 같습니다.
본 식에서 예측된 depth와 gt depth 사이의 오차에 제곱을 해 주는것을 볼 수 있습니다.
예측을 잘못했다면 이와 같은 오차가 더 극대화 된다고 생각하시면 됩니다.
image에서 벽, 도로, 표지판 등과 같은 texture less 영역은 image에서 넓은 영역을 차지한다고 생각할 수 있습니다.
본 논문에서는 이러한 textureless 한 영역에서의 depth 예측을 성공적으로 수행 하였으므로 Sq Rel에서의 성능이 크게 올랐다고 생각합니다.

위 Ablation Study는 FeatureNet의 loss를 계산하는 3가지 loss를 각각 하나씩 추가하면서 해당 영역에서의 feature map을 정성적으로 살펴 본 것입니다.
(a),(b),(c) 는 각각 벽, 바닥과 같은 textureless한 영역입니다. FeatureNet의 loss를 하나씩 더할수록 해당 영역에서의 Feature가 명확하게 표현이 되는 것을 볼 수가 있습니다.
3번째 row의 결과에서 4번째 row의 결과로 넘어갈 때 더해진 loss는 L_{cvt} 인데, 이는 feature map gradient를 한층 완화시켜 주는 역할을 합니다. 이 결과를 눈으로도 살펴볼 수 있습니다.
이때까지 제가 읽었던 self-supervised monocular depth 논문에서는 모두 photometric loss를 사용하였는데,
이 한계점을 제시하고 새롭게 feature map끼리의 loss를 비교했다는 점에서 매우 참신한 논문이였습니다.
저자의 발상(?) 이 참 훌륭한 거 같습니다.
그럼 이만 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요 리뷰 잘 읽었습니다.
지난번 세미 때도 질문했었지만, Sq-Rel과 RMSE는 서로 오차의 제곱을 계산한다는 점에서 매우 유사합니다.
그렇다면 textureless한 영역에 정확한 깊이를 추정하는 것이 어째서 RMSE나 다른 메트릭과 달리 sq_rel의 성능에 크게 기여했을까요? 리뷰에서 textureless한 영역에서 깊이를 정확히 추정했기 때문에 Sq_rel이 크게 향상되었다고 하셨는데 왜 다른 metric은 왜 sq_rel만큼의 성능 향상을 보이지 못했던 것일까요?
이 부분에 대해서 사소할 수 있지만 왜 그런지 알아두시면 metric에 대한 이해가 더 쉽게 될 수 있을 듯 합니다.
그리고 정량적 결과를 나타내는 table2에서 monodepth2가 M으로 학습하였을 때 abs_rel 기준 0.115고 Feat depth는 0.104라고 명시되어있습니다. 이렇게만 보면 monodepth2와 완전히 동일한 조건에서 FeatDepth가 무려 0.011의 차이를 보였다고 생각이 들 수 있으나 논문을 자세히 보시면 monodepth2의 입력 해상도는 640×192인 반면에 featdepth는 정확하게 기억은 나지 않지만 더 큰 해상도(아마 1024×320?)를 입력으로 사용했을 겁니다. 일반적으로 더 큰 입력 해상도로 모델을 학습시키면 깊이 추정 결과도 크게 향상이 됩니다.
앞으로 쭉 depth 논문을 읽으실 것 같은데, 정량적 숫자만 보고 해당 방법론이 무조건 좋다가 아닌 정당한 비교를 했는가?에 대해서도 고려하여 실험 섹션을 읽으시면 좋을 듯 합니다.
Sq-Rel과는 다르게 RMSE나 RMSE-log 메트릭에서는 오차에 root 연산이 들어가게 되서 scale이 줄어들게 됩니다. 따라서 이러한 metric 에 비해 오차의 scale이 고스란히 강조되는 Sq-Rel 에서 성능향상이 크게 이루어졌다고 생각을 합니다.
입력 해상도 부분에 대해 논문을 다시 확인해 보니 FeatureNet 과 DepthNet 에서는 320 X 1024 의 input 을, 그리고 PoseNet 에서는 192 X 640 의 input이 들어오는 것으로 확인하였습니다. 동일한 환경이 아닌데 이렇게 성능 향상을 이루었다고 하나의 표에서 설명하는 저자의 논리(?) 가 맞는지 좀 의심이 가긴 하네요.
정민님의 좋은 충고와 의견 감사합니다. 도움이 많이 되었습니다.
좋은 리뷰 감사합니다.
저자가 제기한 photometric loss의 문제를 해결하기 위해 단순히 영상 픽셀끼리가 아닌 encoder를 태워 얻은 feature끼리 비교하겠다는 것으로 이해하였는데, 이 encoder 학습에 사용되는 discriminative loss의 역할이 잘 이해가 되지 않습니다.
리뷰에 작성해주신 ‘학습이 되어야 하는 FeatureNet이 명시적으로 더 큰 gradient를 가지도록’이라는 부분에서 gradient가 정확히 어떤 gradient를 말하는 것인지 궁금합니다.
또한 소개해주신 feature-metric loss를 적용하는 파이프라인이 장점을 인정받아 depth 분야의 이후 연구에서 계속 사용되었는지도 궁금합니다.
저자는 textureless 영역의 depth 예측 부정확성을 해결하고자 기존의 photometric loss 대신 feature-metric loss를 제안하였고, 이 중에 하나가 discriminative loss 입니다.
여기서 말하는 gradient란 FeatureNet을 통과한 Feature map 에서 주변 픽셀과의 값 차이를 나타낸 feature 값(?) 의 차이라고 생각하시면 될 거 같습니다. 단순 밝기 픽셀차가 아니라 feature map에서의 값 차이이고, 거기서의 변화량(gradient) 라고 생각하시면 됩니다.
feature-metric loss 가 그 후에 활발하게 사용될 만 하다고 생각했는데, 해당 loss를 사용한 논문은 제가 읽은 논문 내에서는 아직 못본 거 같습니다. 요즘의 트렌드는 transformer를 사용한 depth 모델인거 같습니다.