저번 리뷰에서 소개 드린 논문이였던 EDCDepth 논문의 key contribution 인 Data Grafting이 제안된 동기가 특정 논문에서 분석한 결과를 따왔다고 설명했었습니다. EDCDepth 논문을 읽을 당시 잠깐 봤었던 이 논문은 Deep learning을 통해 Depth estimation을 할 때 CNN이 이미지의 무엇을 중요하게 보는지에 관한 분석이 많이 있다는 것을 보고 저에겐 굉장히 중요한 논문이고 많은 영감을 줄 수 있을 것이라 생각하고 읽게 되었습니다.
이 논문은 위에서 말했다 싶이 CNN을 이용해 Monocular depth estimation 할때 과연 모델은 무엇에 집중하는 것인지에 대한 분석으로 구성되어 있습니다. 이러한 분석 논문이 나오게 된 이유에 대해 간단히 소개해드리자면, 원래 영상을 이용한 깊이 추정은 Stereo Image 를 이용한거나 Multi Image를 이용해야지만 가능했으며 카메라 하나만을 이용하는 방식은 epipolar geometry를 사용할 수 없기 때문에 불가능에 가까웠습니다. 다양한 주요 논문에서 물체의 실제 크기를 이용해서 깊이를 추정하는 방식을 제안했지만 그건 자율 주행 상황에서는 사용할 수 없기 때문에 단일 카메라를 이용한 깊이 추정을 연구가 되지 않았었습니다.
하지만 CNN의 출현이후 다양한 연구를 통해 supervised depth estimation 심지어는 Self-supervised depth estimation 논문까지 제안되어 많은 발전이 이뤄지고 있는 상황입니다. 그렇지만 이러한 발전은 CNN의 단순한 활용을 통해 이뤄낸 성공이기 때문에 이게 왜 잘되는지에 대해 분석된 논문은 없었습니다. 따라서 소개 드리는 이 논문에서 그걸 했다고 보시면 됩니다. 그럼 그 분석이 왜 중요할까요 그 이유는 다음과 같습니다. 첫째, 네트워크가 무엇을 하는지 알지 못하면 올바른 동작을 보장하기 어렵습니다. 테스트 세트에 대한 평가는 어떠한 경우에 올바르게 작동하는 것으로 나타났지만 다른 시나리오에서는 올바른 동작을 보장하지 않습니다. 둘째, 네트워크가 학습한 내용을 아는 것은 훈련에 대한 통찰력을 제공합니다. 학습 세트 및 데이터 증대에 대한 분석은 학습된 행동에서 파생될 수 있습니다.
이 논문에서 주장하는 Depth estimation의 큰 요소는 물체의 수직상의 위치 입니다. 물체의 실제 크기는 성능에 영향을 주지 않지만 수직상의 위치는 큰 영향을 끼친다는 것을 다양한 분석을 통해서 증명했습니다.
이 논문에서는 먼저 Monocular Depth Estimation에서 큰 영향을 끼치는 것은 물체의 수직 위치와 겉보기 크기라고 가정했습니다.
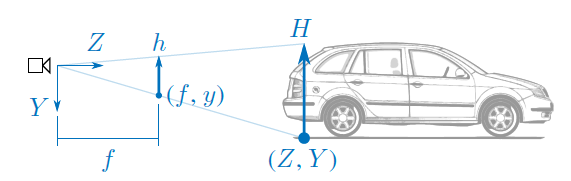
그 이유는 위 그림과 같은 상황을 촬영했을때, 자동차까지의 거리는 아래 수식과 같이 정의될 수 있으며 이는 물체의 높이인 H만 알면 구할 수 있습니다.
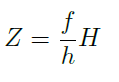
이러한 상황에서 KITTI 와같은 주행 데이터 셋에서 보이는 물체는 트럭이나 자동차, 보행자 같이 한정되어 있어서 그 크기를 학습할 수 있을거라는 가정하에 물체의 크기가 중요하다고 첫번쨰 가정을 세울 수 있습니다.
다음으로 실제 바닥의 위치 yh와 물체 바닥이 촬영된 위치인 y 와 카메라의 높이인 Y의 관계를 고려하는 아래 식을 통하면 Depth를 구할 수 도 있습니다.
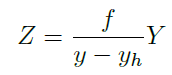
음.. 식이 논문에서 위와 같이 적혀있는데 좀 이상한거 같습니다. 제 생각에는 Z=(Z-f)*Y/(y-yh) 같은데 암튼 이 수식에서 중요한 Y와 yh 같은 경우 KITTI에서는 일정하니 depth 가 쉽게 구해졌을꺼라는 가정을 세울 수 있습니다.
두가지 가정을 세운다음 두가지에 대해 증명하기 위한 여러 실험을 진행합니다 먼저 아래와 같은 실험을 진행했습니다. ㅇ

위 그림을 통해서 알 수 있는 것은 물체의 크기는 깊이 추정에 큰 영향을 끼키지 않지만 물체의 수직적인 위치는 예측에 영향을 끼친다는 것입니다. 그리고 depth 값을 보면 물체의 depth는 물체 기준 앞 뒤의 깊이 정보 평균화해서 예측된다는 것을 알 수 있습니다.
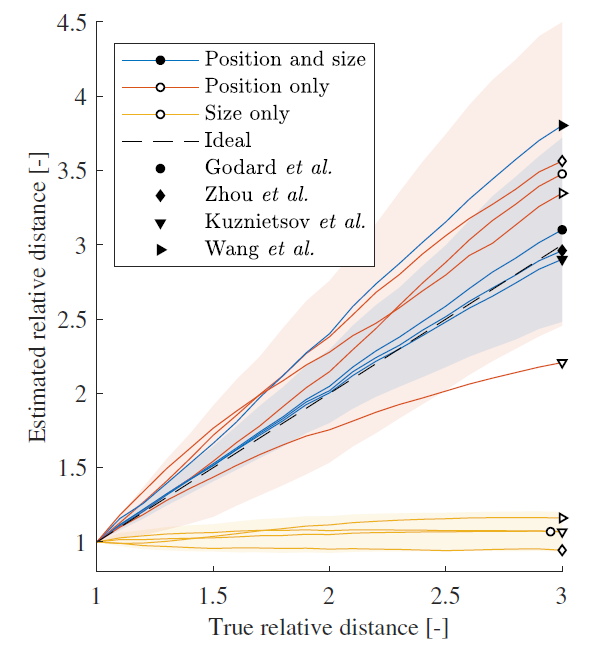
실제 값을 보면, 정상적인 영상이라 할 수 있는 Position 과 size를 전부 변경한 방법론에서 wang을 제외하면은 추정된 깊이가 물체의 실제 깊이에 가깝게 유지되어 네트워크가 이러한 인공 이미지에서 여전히 올바르게 작동함을 보여줍니다.
그리고 수직적 위치를 변경할 경우 대략적인 Depth estimation은 가능 하나 과하게 예측하거나 매우 작게 예측하는 경향을 보여줍니다. 또한 크기만 변경할 경우 예측되는 깊이 값이 변경되지 않는 것을 볼 수 있습니다.
이러한 결과는 크기 정보가 제거될 때 동작의 일부 변화가 관찰되지만 신경망이 겉보기 크기보다는 주로 물체의 수직 위치에 의존함을 시사합니다.

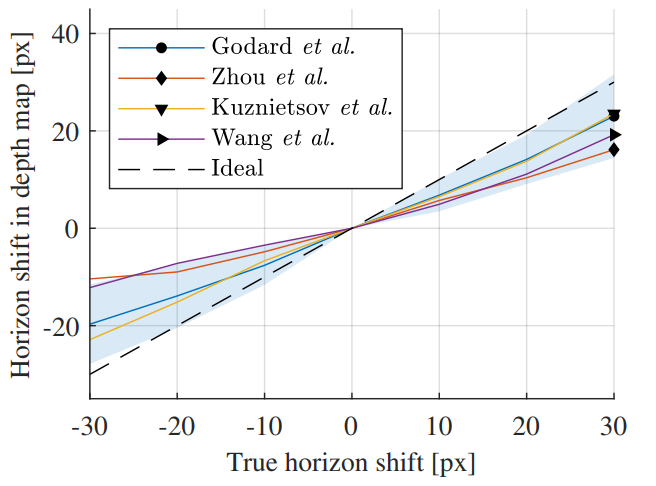
Depth estimation 이 수직정보에 많은 영향을 받는건지 증명하기 위한 두번째 실험을 진행했는데요, figure 5와 같이 crop을 height에 따라서 했을때 Depth estimation 결과 입니다. 결과를 보면 일관되게 적절하게 예측하지만 조금씩 작게 예측 되는 것을 확인할 수 있습니다.

다음으론 학습에 없는 물체를 넣었을 때 결과인데 확실히 이상한 물체를 넣을 경우 예측을 하지 못합니다.

그리고 texture 와 색그리고 semantic 정보에 대한 성능 변화를 보였습니다.
보면 texture 를 유지 할 경우 색이 변경 될 경우 성능 차이가 없지만 , texture 변화가 생기면 굉장한 성능 드랍이 있는 것을 볼 수 있습니다.
이 외에도 다양한 평가가 있어서 한번 봐보면 좋을 것 같습니다.
mono depth 모델과 관련된 논문들은 여러편 읽어 봤지만,
모델은 무엇에 집중하는 것인지에 초점을 두고 분석한 논문은 처음인 거 같습니다.
새로운 느낌의 논문인 거 같아서 흥미가 가네요.
결론적으로 depth를 예측하는 데에 있어서 image 내 물체의 수직적인 위치에 따라서 정확도가 달라지는것은 CNN모델의 근본적(?) 인 문제라고 저자는 말을 하고 있는 것인가요??
최근 등장하고 있는 transformer 기반의 논문들에서는 이러한 문제점이 있는지 궁금하네요 ㅎㅎ.
좋은 리뷰 감사합니다.
좋은 논문 소개해주셔서 감사합니다.
해당 논문에서는 물체의 수직 위치가 깊이 추정에 주는 영향에 대해 소개하고 있습니다. 그럼 물체 검출과 깊이 추정은 서로 연관성을 가질 수 있을 것 같다는 생각이 드네요. 이는 깊이 추정과 물체 검출 알고리즘의 멀티 태스킹 네트워크의 가능성을 시사한다고 보는데 어떻게 이에 대해 어떻게 생각하시나요?