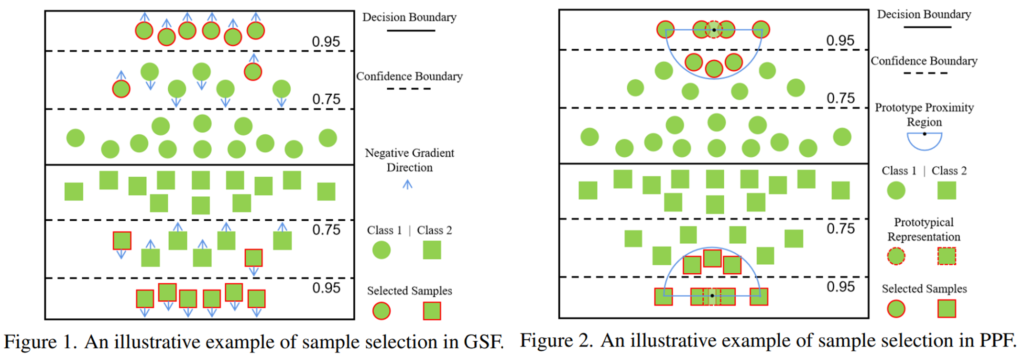
(기존 방법론은 매우확신(self-training), 매우 불확신 데이터(active learning)만 사용하였음)
소개
최근 SSL(Semi-supervised learning)은 self-training, consistency regularization 기술 발전에 따라 발전했다. 이 기술들은 보통 confidence를 통해 데이터셋 필터링 과정을 거쳐 unlabeled sample에서 데이터를 선별하였는데, 본 논문에서는 중간정도의 confident를 내제한다고 평가되는 데이터셋이 실제로(정녕) 쓸모 없는지 그리고 어떻게 유용한 데이터를 선정하는지에 대해 관심을 가지며. 최종적으로 높은 confident를 갖는 unlabeled data와 labeled data 샘플을 허용하는 Taylor expansion inspired filtration (TEIF) framework를 제안하였다. 이 모델(TELF)는 stable하며 더 나은 일반화 성능을 갖는다.
제안하는 방법론에서는 두 가지의 새로운 필터를 제안하였는데 하나는 gradient synchronization filter (GSF)로 fully-supervised learning에서 optimization정도가 dynamic이면 중간정도의 가치(confident)를 갖는 셈플도 중요하다고 판단한다. 다음으로는 prototype proximity filter (PPF)인데 majority gradient와 유사한 gradients를 갖는 데이터를 선정한다는 뜻이다. 즉, 어느 정도의 prototypicality즉, 분포 내 데이터의 속성을 띄어야 한다는 것이다.
제안하는 방법은 기존 SSL 방법론에 쉽게 통합될 수 있으며, FixMatch를 baseline으로 실험을 진행하였다.
contributions
1) SSL 분야에 새로운 질문(중간정도의 중요도로 평가되는 데이터의 중요성)을 던지고 이에 대한 PRELIMINARY answers를 얻었다.
2) Taylor expansion inspired filtration (TEIL) 이라는 프레임워크를 제시하여 새로운 데이터 중요도 판단(필터 2)을 제시하였다.
3) optimization dynamic과 prototype proximaity에 관한 새로운 관점을 새로운 필터 (PPF, GSF)를 통해 제시하였다.
Method
- Task: 논문에서 집중하는 Task는 다음과 같다.
K개의 classes를 구분하며 labeled data(X^l), unlabeled data(X^u)를 통해 학습한다. semi-supervised learning(SSL)을 통해 feature extractor (E(-))를 학습하는것을 목적으로 하며 classifier인 F(-)를 통해 최종 예측 확률을 계산한다. classification model(F(E(-)))는 X^l과 X^u로 학습하며 unseen test sample에 대해 일반화된 옳은 예측을 하도록 학습하는 것을 목적으로 한다. unlabeled data의 contrastive learning 적용을 위해 weakly augmentation(a(-))과 strong augmentation(A(-))를 사용한다. - Preliminaries
이 내용을 이해하기 위해서는 self-training(pseudo labeling), consistency regularization 기법을 알아야 한다. - Taylor Expansion Inspired Filtration
기존 SSL 모델은 높은 확신도를 갖는 데이터에 집중하여 모델이 이미 가지고 있는 정보에 집중했다. 하지만 제안하는 방법은 중간정도의 확신도를 갖는 데이터를 포함하여, 데이터의 정보량을 높여야 한다고 주장한다. 이를 위해 제안하는 TEIF는 신뢰도가 높은 샘플과 유사한 중간 신뢰도 데이터를 골라 학습한다.
– GSF(Gradient Synchronization Filter) 필터. ([그림1]의 좌측 참조)
deep learning model은 쉬운 filter먼저 학습하기 때문에 easy example에 대해 잘 작동한다. 따라서 optimization이 수렴하지 않은 dynamic 상태의 데이터는 모델에게 어려워 정보량이 많은 데이터일 가능성이 크다. 최근 많은 연구들은 optimization 정도를 loss 함수의 gradient를 기준으로 확인한다. 구체적으로 논문에서는 먼저 labeled sample과 highly confident unlabeled data에 대한 majority gradient(the sum over normalized feature gradients)를 계산한다. 이후 feature gradient와 majority gradient의 cosine 유사도를 계산하며 그 중 유사도가 τ이상인 데이터를 한다.
– PPF(Prototype Proximity Filter) 필터. ([그림1]의 우측 참조)
FixMatch는 특정 클래스에 대한 정보를 담아 대표성을 띄는 데이터를 기반으로 학습하여 대표성을 띄는 샘플 데이터의 추가를 통해 성능을 향상할 수 있음을 보였다. 이에서 영감을 받은 PPF 는 중간정도의 확신도가 있는 데이터 중 전형적인 (prototype에 가까운) 데이터를 선별한다. 앞선 연구에 기반하여 prototypical representation을 찾고 이를 기반으로 거리를 계산하여 미리 설정한 hyper parameter τ2 이상의 유사도를 갖는 중간정도 확신도 샘플을 샘플링한다.
Results
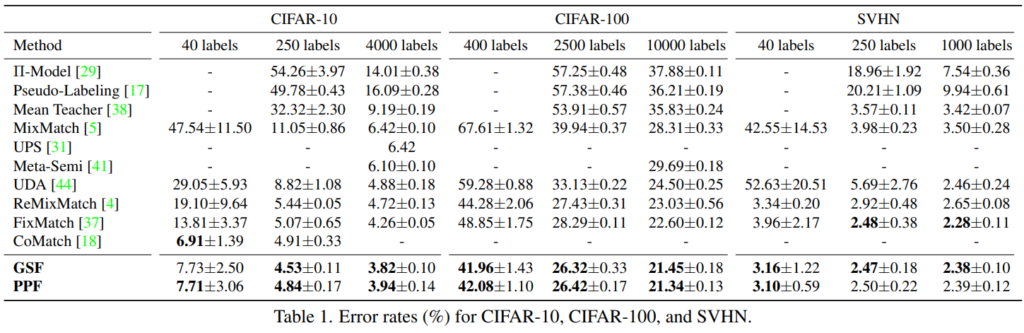
FixMatch를 베이스라인으로 하여 실험하였으며 다양한 데이터와 세팅에서 SOTA 성능을 보임을 확인할 수 있다.
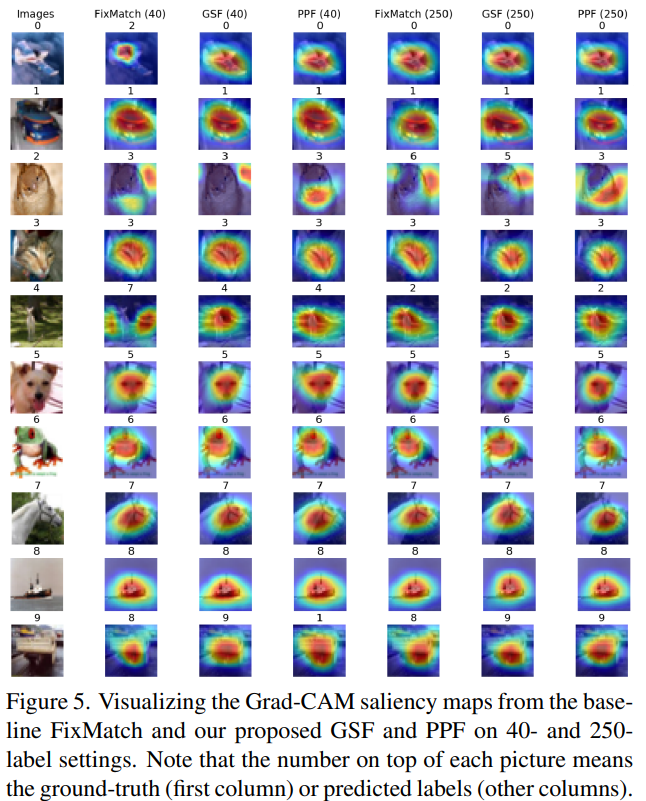
또한 CAM을 통해 Fixmatch와 비교하였을 때 제안하는 방법론이 더욱 물체에 집중하는 것을 알 수 있다.
좋은 리뷰 감사합니다.
본 논문은 Fixmatch 기반으로 제안된 방법론 같은데요, 이를 요약하면 결국 1) 중간정도의 confident를 가지는 데이터가 중요한데, 2) 그 데이터가 정말 효과적인지 아닌지와 최적화를 개선하기 위해 유용한지를 선택하는 방법 에 대해 제안한 것 같습니다. 따라서 2) 를 해결하기 위해 TEIF 프레임워크를 제안한 것 같습니다. 그런데 1) 중간 정도의 confident를 가지는 데이터가 왜 중요한지 이를 서술한 것이 잘 나와있을까요? Confidence가 낮으면 수도 라벨링에 사용하지 않는것에 익숙한 저로서 중간 단계의 confidence를 가지는 데이터가 왜 중요한지 이해가 가지 않아 질문드립니다!
말씀하신것처럼 기존 SSL 모델은 높은 확신도를 갖는 데이터에 집중하여 모델이 이미 가지고 있는 정보에 집중했으나. 이는 모델이 이미 알고있는 데이터를 학습하는 것과 마찬가지 입니다. 제안하는 방법은 중간정도의 확신도를 갖는 데이터를 포함하여, 데이터의 정보량을 높여야 한다고 주장합니다.