최근 연구의 방향이 모델의 구조적 관점보다는 data augmentation에 더 초점을 맞추다보니 image augmentation 쪽 논문들을 찾아보게 됐습니다. 아무래도 self-supervised learning 쪽 분야가 표현력을 높이기 위해 다양한 augmentation을 적용하지 않을까 싶어서 관련 논문을 읽어보게 되었습니다.
Intro
Unsupervised visual representation learning은 모델이 어떠한 semantic annotation 정보 없이 영상 특징을 학습하도록 하는 분야입니다. 최근에 해당 분야에서는 instance discrimination task를 통해 self-supervised learning을 하는 방법도 있고 또는 Siamese 구조를 활용해 학습하는 방법들도 있다고 합니다.
이러한 visual embedding 방법론들은 동일 영상으로부터 다양하게 파생된 변화들 사이에 비유사성을 최소화하도록 학습이 진행되거나 다른 영상들(즉 네거티브 쌍)에 augmentation을 적용하여 이들 사이의 거리가 커지도록 하는 방식으로 학습됩니다.(대충 augmentation을 적용한 영상을 negative로 보고 유사성이 멀어지도록 한다는 의미 같습니다.)
결과적으로 말하자면, self-supervise 기반의 representation learning을 수행하기 위해서는 영상 변환, 즉 하나의 영상에 어떠한 변환을 적용하여 다양한 영상처럼 생성할 것인가가 성능 향상에 가장 중요하다고 합니다.
하지만 저자는 이러한 방법론들은 대부분 근본적인 문제점을 공유하고 있다고 합니다. 문제점이란 바로 모델 학습을 위해 오직 적은 양의 augmentation 기법들을 활용하고 있다는 점입니다. 예를 들어 random crop, color distortion, Gaussian blur 그리고 grayscale 정도의 조합은 좋은 성능을 도달하는데 있어 매우 중요한 기법들로 자리 잡히며 매우 유명한 instance-wise self-supervised learning methods들이 이 augmentation setting을 활용하고 있습니다. (그리고 저자는 위의 언급한 기법들을 standard augmentation이라고 명칭을 붙였습니다.)
최근에 다른 연구들은 이러한 standard augmentation 말고도 매우 마이너한 augmentation을 적용하는 연구들이 있다고 하는데, 한 연구에서는 RandAugment(말 그대로 어떤 augmentation을 할지를 랜덤하게 골라서 적용하는 것)와 JigSaw puzzle과 같은 것을 활용해 성능을 향상시켰다고 합니다.
하지만 위에서 설명드린 방법론은 negative pair 기반의 방법론이기 때문에, negative pair를 활용하지 않는 방법론들(논문에서는 Sim-Siam 이라는 방법론이 그런 방법론의 예시라고 합니다.)의 경우 위에서 언급한 jigsaw puzzle같은 augmentation은 성능에 부정적인 영향을 주거나 model collapsing 현상을 발생시킨다고 합니다.(저자는 이러한 어려운 augmentation을 heavy augmentation이라고 명칭하였습니다.)
아무튼 저자는 이러한 관점에서 어떻게하면 heavy augmentation을 negative pair를 활용하지 않는 방법론에도 적용할 수 있을지에 대해 초점을 맞추고 해당 논문을 작성한 것으로 판단됩니다.
아무튼 저자의 방법론에 대해서 간략하게 다뤄보면 먼저 저자는 이전에 instance-wise self-supervised learning을 동일 instance로부터 augmented view로 생성된 것들의 k-means clustering 문제로 정의하는 논문에 영감을 받아서, 시각 특징 임베딩 공간 속 주어진 영상 인스턴스 중 하나의 모든 시각들을 gold standard feature cluster라고 가정하였습니다.
그 후 관련 있는 gold standard feature cluster의 핵심 지점으로부터 augmented view의 특징의 편차를 d라고 정의하였습니다.
위에 내용이 무슨 말인지를 제가 적어도 잘 이해가 되질 않아서 조금 더 정리하여 설명을 하겠습니다.
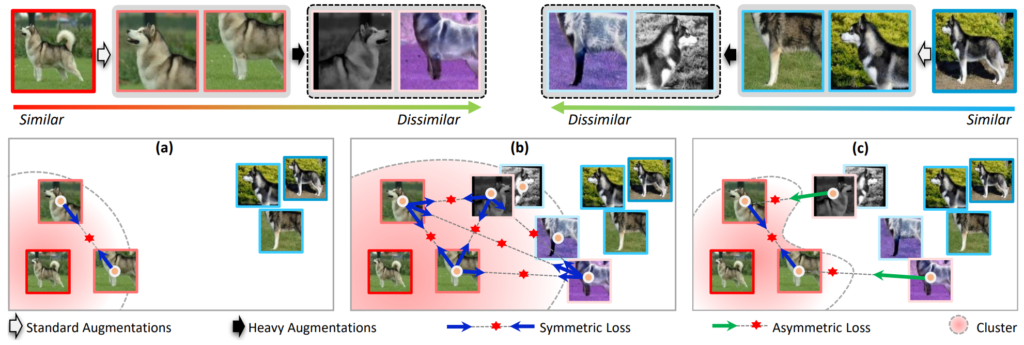
그림1에서 좌상단에 similar 부근에 있는 영상들이 아마 standard view라고 하는 것들로 판단됩니다. 즉 기존의 방법론들은 입력 영상에 대하여 standard augmentation(random crop, photometric distortion 등등)을 통해 입력 영상과 색감이나 strcture의 왜곡이 그리 심하지 않은 영상들이다 라고 이해하시면 될 것 같습니다.
그리고 이러한 standard view로부터 heavy augmentation을 수행하면 color 색감도 왜곡이 심해지고 strcture에도 왜곡이 더 생기는 등의 어려운 harder view를 생성할 수 있습니다.
아무튼 일반적인 학습 기법들(그림1-(a))의 경우에는 standard view에 대해서만 이제 instance-wise learning을 수행하는 것을 볼 수 있습니다. 그리고 (b)의 경우에는 standard view 뿐만 아니라 harder view까지 함께 활용하는 self-supervised learning기법으로, standard view 끼리 뿐만 아니라 harder view와도 유사도가 커지도록 하는 symmetric loss를 활용한 것입니다.
하지만 (b)의 경우에는 2가지 문제가 발생하게 되는데 첫째는 standard view의 표현력이 harder view로 가까워지도록 하는 것은 embedding space 속 feature cluster가 커질 수 밖에 없다고 합니다. 그리고 이렇게 밀집하지 못한 군집은 모든 인스턴스들이 잘 펼쳐진 임베딩 공간에서는 올바르게 동작하기 어려울 뿐더러 각 인스턴스들 끼리 구분하는 능력이 하락하기도 합니다.(이는 instance-wise self-supervised learning이기 때문에 negative pair를 활용하지 않아서 더더욱 이러한 현상이 잘 발생한다고 합니다.)
그리고 둘째로는 harder view들 사이에 visual agreement를 최대화하는 것은 InfoMin principle에 부합하지 않는다고 주장합니다. d(즉 view의 feature들 간의 편차)가 큰 view들 사이에서 mutual information은 대체로 작을 수 밖에 없으며, 반대로 이러한 view들은 missing information을 이끌어갈 수 있기 때문에 downstream task에서 좋지 못한 성능을 달성한다고 합니다.
반면에 (c)는 논문에서 제안하는 방식으로 harder view에서 발생할 수 있는 missing information 때문에 발생할 수 있는 (위에서 언급한)불리한 현상들을 방지하고자 hard view 사이의 visual agreement가 최대화되도록 하는 loss를 적용하지 않았다고 합니다. 대신에 feature cluster를 보다 더 밀집하게 만들기 위하여 각각의 harder view를 그것과 관련된 standard view로 모이도록 하는 asymmetric loss를 적용했다고 합니다.
A unified formulation
방법론에 대해 들어가기전에 먼저 이전에 제안된 instance-wise self-supervised learning의 4가지 요소들에 대해 간략하게 짚고 넘어가겠습니다.
- 먼저 single image에 대하여 data augmentation을 적용하는 augmentation module을 \Tau 라고 명칭합니다.
- deep neural entwork encoder를 f라고 명칭하며 해당 encoder는 입력 영상을 어떠한 latent space로 투영시키게 됩니다.
- encoder network를 타고 나온 출력값이 instance-wise self-supervised loss를 적용하기 위하여 mapping을 수행하는 projection head를 g라고 명칭합니다.
- Self-supervised loss 함수는 instance들 간에 discrimination을 수행하거나 또는 feature prediction를 수행하는 방향으로 함수가 정의됩니다.
자 그러면 이제 어떠한 입력 영상 I가 주어진다고 가정했을 떄 data augmentation module을 통해 생성한 augmented view의 쌍은 다음과 같습니다.
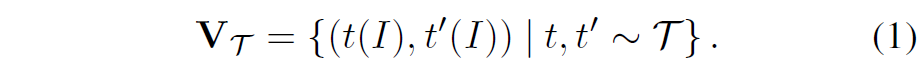
여기서 t와 t’은 \Tau 로부터 선정된 랜덤 augmentation 샘플이라고 보시면 될 것 같습니다.
학습 과정에서는 먼저 (v, v’)가 augmented view pair로 정의됩니다. 여기서 v는 encoder에 입력으로 들어가 어떠한 visual representation을 가지는 f(v)가 되며 이를 projection head에 입력으로 다시 태워 어떠한 vector z를 생성합니다.(즉 z = g(f(v)))
여기서 objective function은 augmented view pairs( S(z, y(v’))) 사이에 agreement를 최대화하는 방향으로 학습이 진행되며 이때 y는 모델 학습을 위해 label을 생성하기 위한 함수라고 이해하시면 될 것 같습니다.
그리고 여기서 각각 y를 어떻게 정의하느냐가 최근에 제안된 논문들의 방법론을 의미합니다. 가장 대표적인 방법론 3가지에 대하여 논문에서 설명하는 문단을 아래에 첨부합니다.

여기서 augmented view가 랜덤하게 생성되기 때문에 위에 언급한 3가지의 목적 함수들은 symmetrical한 형식으로 구현이 되어 있습니다.
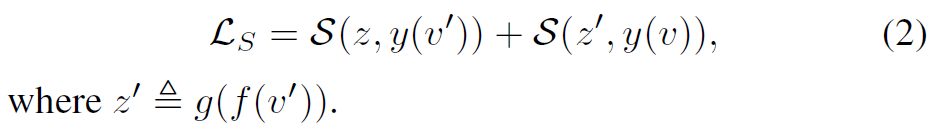
Partially-ordered views construction
일단 먼저 논문에서 새롭게 제안하는 heavy data augmentation( \hat{\Tau} 다루고자 합니다.(참고로 이전 방법론들이 사용하는 standard data augmentation 정책은 \Tau 라고 합니다.)
저자는 \hat{\Tau}, \Tau 를 적절히 조합하여 새로운 view들을 생성하였다고 합니다. 예를 들어서 새로운 augmented view가 \hat{v} = \hat{t}(v)라면, 이는 v = t(I)에서 새롭게 heavy augmentation을 적용한 것이라고 이해하시면 되겠습니다.
만약 잘 학습된 모델이 있다면 해당 모델은 동일한 영상에 아무리 augmentation을 적용해서 만든 여러 view가 있다 하더라도 모든 view들을 매우 인접한 embedding space로 군집시킬 것입니다.
즉 어떻게하면 이 view들의 embedding space 내에서의 편차를 개선시킬 수 있는가에 대하여 저자는 먼저 core-point(즉 original view I)로부터 추출한 augmented view의 특징( f(v))의 편차를 d(v)라고 정의하였습니다.
여기서 편차의 정도를 정량적으로 추정하는 것은 상당히 어려운 일에 속하게 됩니다. 하지만 일반적으로 v(augmented view)를 생성하기 위해 더 큰 왜곡량을 적용하였다면, 아마도 d(v) 역시 더 크게 발생할 수 밖에 없습니다.
즉 standard augmented view에 더 복잡한 heavy augmentation을 적용하게 된다면 당연히 원본 view로부터 꽤나 큰 편차를 지니게 될 것입니다.
여기서 \Tau, \hat{\Tau} 사이에는 중복되는 기법이 없으며 \hat{t} 의 연산은 non-identity 하기 때문에, 저자는 d(\hat{v}) > d(v) 라는 형식을 통하여 상대적인 magnitude를 비교계산할 수 있다고 합니다.
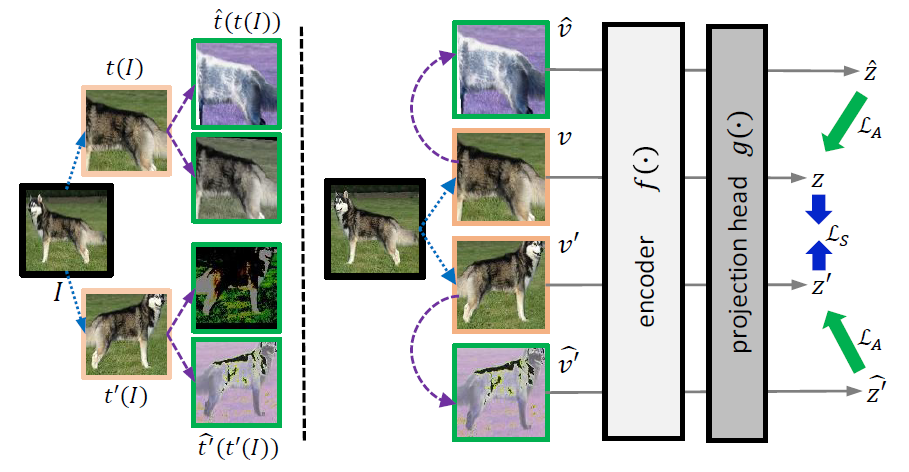
그림으로 보면 그림2 좌측과 같은 상황이라고 보시면 될 것 같습니다.
Directional self-supervised learning
다음으로는 self-supervised learning을 수행하기 위한 loss function에 대해서 알아보도록 하겠습니다.
먼저 두개의 augmented view pair ( v, \hat{v} ), ( v', \hat{v'} )를 샘플링하였다면, v hat이 v로 향하는 asymmetric loss를 아래와 같이 정의할 수 있습니다.
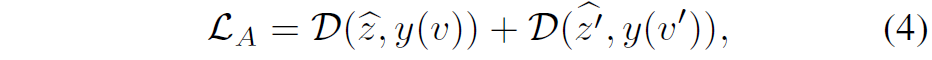
여기서 y 연산은 위에서 설명드린 수식2와 동일한 세팅을 가지고 있습니다만, 조금 다른 것이 y는 오직 standard view에 대해서만 계산을 수행합니다. 저자는 이것은 self-supervised learning이 directional하면서 동시에 asymmetrical 하도록 만들어준다고 합니다.
이 말이 무슨 의미냐면, 해당 loss가 최소화하고자 하는 목표는 harder view의 표현이 그것과 연관있는 source view의 표현과 가까워지도록 한다는 것을 의미합니다.
또한 수식(4)에서 D는 두 벡터 사이에 negative cosine similarity라고 합니다.
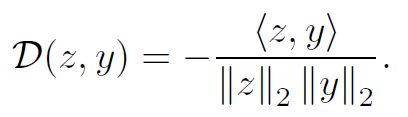
그림2를 다시 보시면 우측 부분에 loss 계산 방식이 두개의 standard view와 각각의 연관된 harder view들의 loss 계산을 아래와 같이 이뤄지는 것을 알 수 있습니다.
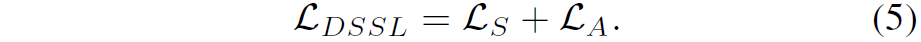
여기서 Ls는 수식(2)로 standard view들 간에 symmetrical loss입니다.
Experiments
그럼 실험 부분을 다루고 리뷰를 마무리 해보도록 하겠습니다.
먼저 성능 비교 대상으로 다룬 논문은 method에서도 설명한 3가지 방법론 SimCLR, SimSiam, BYOL입니다. SimCLR은 positive와 negative view가 학습 때 모두 필요로 하는 방법론이며, BYOL과 SimSiam은 negative sample이 필요 없는 방법론에 해당합니다.
그리고 y label을 계산하는데 있어서 SimSiam은 네트워크의 branch의 gradient를 잠시 freeze하게 되는데 이때 BYOL은 y를 업데이트하기 위해 momentum encoder를 활용합니다.
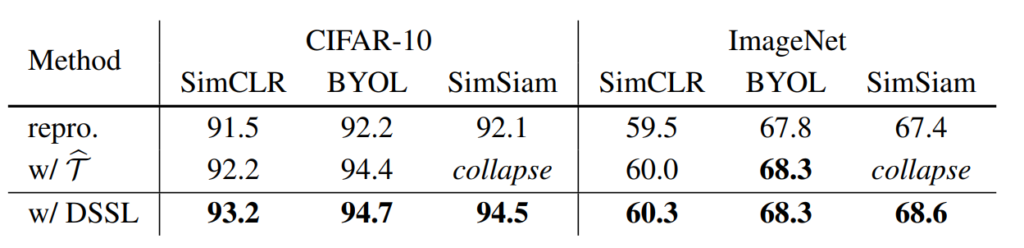
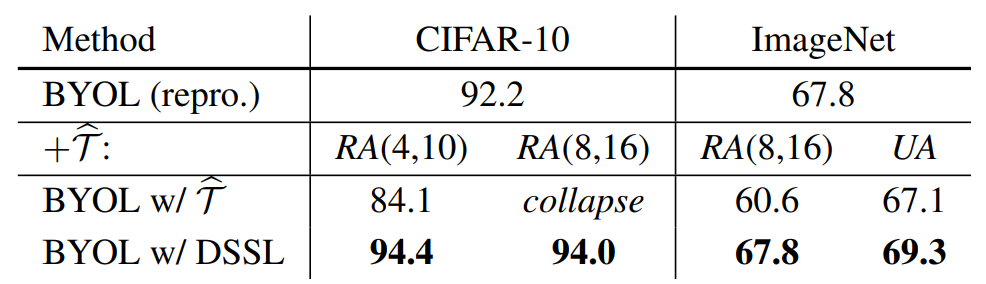
위에 표는 CIFAR-10과 ImageNet에서의 정량적 결과입니다. 제일 좌측에 repro는 그냥 각 방법론 별로 논문에서 제안된 내용 그대로 돌렸을 때 결과를 의미하며, \hat{\Tau} 는 heavy augmentation을 취했을 때, 그리고 DSSL은 논문에서 제안하는 학습 기법을 적용했을 때를 의미합니다.
보시다시피 SimCLR은 postive pair와 negative pair를 함께 활용하는 contrastive learning을 수행하기 때문에 heavy augmentation을 취하였을 때가 standard augmentation을 적용했을 때 보다 더 좋은 성능을 달성하는 것을 확인할 수 있습니다.
하지만 negative pair가 없는 SimSiam의 경우에는 heavy augmentation을 학습 때 적용하였을 때 모델이 collapse되는 현상이 발생하였다고 합니다. 그럼 똑같이 negative pair를 사용하지 않은 BYOL은 왜 학습이 될 뿐더러 성능 향상도 있었을까요?
저자가 주장하는 바로는 BYOL의 경우 momentum encoder를 사용하기 때문에 hard view에 더 강인하다고 주장합니다. 하지만 momentum encoder는 모델의 학습 안정성을 상당히 해치게 되는데, 이는 momentum이 불일치한 표현으로부터 정보의 잘못된 흐름을 생성할 수 있기 때문이라고 합니다.
아무튼 저자가 제안하는 DSSL 방식을 SimSiam에 적용하게 되는 경우에는 model collapse가 발생하지 않고 성능 향상이 있는 것을 확인할 수 있습니다. 이는 DSSL이 heavily augmented view들 사이에 유사도를 같도록 하는 것을 예방하기 때문이라고 합니다.
물론 BYOL에서는 DSSL을 적용한 것과 적용하지 않은 것과 ImageNet에서의 성능 차이가 발생하지 않습니다. 하지만 저자는 아래 표처럼 더욱 강한 heavy augmentation을 추가하게 될 경우에는 BYOL에서도 성능 향상을 일으킬 수 있다고 합니다.
결론
self-supervised learning 쪽 논문에 대하여 다른 연구원님들이 작성해준 리뷰나 세미나를 잠깐 들어본 정도의 수준으로 최신 work을 읽으려고 하니 논문을 이해하고 리뷰를 작성하는데 쉽지가 않네요:(
비록 리뷰는 조금 간략하거나 모호하게 작성된 부분이 있지만 최대한 어떤 컨셉인지에 대해서는 다루었으니 관심있으신 분들은 논문을 직접 읽으시면 좋을 것 같습니다.
좋은 리뷰 감사합니다.
2가지 질문이 있습니다. 우선 intro 부분에서
‘둘째로는 harder view들 사이에 visual agreement를 최대화하는 것은 InfoMin principle에 부합하지 않는다고 주장합니다.’
라고 하셨는데 view feature간의 편차가 클 경우 동일한 instance로 판단하기 위한 정보가 많아지고(두 view의 합집합의 정보를 사용하는 것..?) 잘못된 정보를 이용하게 될 수 도 있다는 의미가 맞나요??
또한, BYOL에 대한 결과만 리포팅되어있는 두번째 표에 해당하는 실험이 앞선 실험보다 더 강한 augmentation을 주었다고 하셨는 데, 더 강한 heavy augmentation 방식을 추가하여 적용한 것인지, 아니면 augmentation을 적용한 이미지에 다시 heavy augmentation을 적용한 것인지 궁금합니다.
음 먼저 첫번째 질문에 대해서 답변드리면 먼저 InfoMin principle에 대하여 정의하고 넘어가야할 것 같습니다. 저도 InfoMin principle에 대해 이 논문에서 처음 키워드만 접해본거라 정확하지는 않지만 대략적으로 feature의 정보량이 너무 적으면 정보량 부족으로 모델 학습이 어려워지고, 정보량이 너무 많으면(해당 분야에서는 data augmentation이 과해질 때를 의미하는 듯?) 그것대로 노이즈로 작용해서 학습에 부정적인 영향을 주기 때문에 이러한 요인들을 다 고려해서 가장 최적의 지점을 찾는? 뭐 그런게 있는 듯 합니다.
그러한 관점에서 InfoMin principle은 두 view가 최소한의 정보만을 공유하고 있을 수록 학습에 좋다는 주장인 것 같은데, 학습 시에 많은 정보가 변형 및 포함된 hard view와도 유사해지도록 학습이 되면 InfoMin principle이 깨져버린다는 것 같습니다.
두번째 질문에 대한 답변으로는 그냥 처음부터 harder view를 생성하기 위해 더 많은 종류 및 augmentation magnitude 값을 더 크게 하여 한번에 적용했다고 합니다.