오늘은 다소 흥미로워 보이는 주제에 대한 논문을 리뷰해보려고 합니다.
Self-supervised learning(이하 SSL) 이라면 이제 많은 분들이 충분히 이해하고 계실 방법론이라고 생각됩니다. 게다가 최근 이 방법론을 이용한 연구들이 아주 활발하게 진행되고 있기도 합니다. 그렇다면 왜 이런 SSL이 주목을 받을까요?
Self-supervised learning: The dark matter of intelligence Meta AI 블로그에 올라온 얘기를 인용해보도록하겠습니다. 인간의 Common Sense 는 인간으로 하여금 새로운 일에 대해 많은 양의 학습을 요구하지 않고도 약간의 예시로도 충분히 이를 습득할 수 있게 도와줍니다.
이게 무슨소리일까요? 예를 들어 보겠습니다. 지도학습 기반의 AI는 학습 시 사용한 데이터가 아닌 전혀 다른 도메인에서의 데이터를 보여줬을 때 동일한 물체일지라도 부정확한 예측을 할 수 있습니다. 예를 들어 돼지의 얼굴 위주의 데이터로 학습한 모델은 누워있는 돼지에 대해 예측하지 못할 수 있습니다. 그렇기 때문에 누워있는 돼지를 맞출 수 있도록 또 동일한 양의 데이터를 제공하고 학습해서 이를 극복해내야 합니다.
반면, 인간의 경우 전혀 다른 도메인에서의 물체라도 잘 알아차리게됩니다. 돼지의 얼굴을 충분히 이해했다면, 누워있는 돼지에 대해서도 돼지임을 알 수 있을 가능성이 높죠.
따라서 인용한 글에서는 그 차이가 바로 “인간은 세상이 어떻게 작동하는지에 대해 이전에 습득한 배경 지식에 의존하기 때문”이라고 이야기하였습니다. 따라서 SSL이 바로 이 인간의 Common Sense처럼 데이터 자체에서의 패턴을 찾아 학습을 하게 되면 데이터 고유의 패턴을 이해할 것이고, 이를 다른 태스크에 적용함으로써 약간의 데이터로도 충분한 성능을 기대하게 된 것입니다.
We believe that self-supervised learning (SSL) is one of the most promising ways to build such background knowledge and approximate a form of common sense in AI systems.
정리하자면, 해당 글에서는 SSL을 통해 AI 시스템은 훨씬 더 많은 데이터를 학습할 수 있으며, 이는 더 미묘하고 덜 일반적인 representation의 패턴을 인식하고 이해할 수 있도록 할 것이라고 주장합니다.
이렇듯 SSL에서는 인간의 Common Sense를 모사하기 위해 데이터가 굉장히 중요해보입니다. 제가 오늘 리뷰하려고 하는 논문이 흥미로운 이유는 바로 이 데이터에 집중하였기 때문인데요. 해당 논문에서는 데이터 자체에 존재하는 사회적 편향/편견 을 지적하였습니다. 데이터라는 것은 자고로 인간이 직접 수집한 것으로, 인간이 가지는 사회적 편견이 포함되곤 합니다. 그런데 이런 데이터에 대해 SSL이 적용되면, 데이터에 존재하는 사회적 편견까지 학습하게되어 버려 과학 윤리에 위배된다는 것이 저자의 주장입니다. 따라서 저자는 이런 문제에 집중하여 사회적 편견에 대해 측정하기 위한 도구와 여러 SSL 방법론으로 훈련된 모델의 사회적 편견에 대해 연구하였습니다. 그리고 이 편견을 줄이고자 하는 방법도 제안하였습니다.
언젠가 SSL이 왜 촉망받고 있는지를 설명드리고 싶어서 이렇게 서론이 길어졌네요. 그렇다면 본격적으로 리뷰 시작해보도록 하겠습니다.
A study on the distribution of social biases in self-supervised learning visual models

Introduction
Self-Supervised Learning 은 지금까지 Supervised learning 과의 성능 격차를 많이 좁혀오며, 앞으로의 딥러닝 연구를 이끌 방법론으로 주목받고 있습니다.
인간의 사회적 편견은 이미 충분히 연구되고 분야라고 합니다. 특히 나이, 성별, 인종 측면에 기초한 사회 집단에 대한 편견은 정량화가 가능하다고 합니다. 그런데 이런 사회적 편견이 학습 데이터에 포함될 경우, 사회적 편견 역시 학습될 수 있습니다. 실제로 이런 사례가 적용되어 보고된 경우가 있다고도 합니다. 예를 들어 contextual cues (ex. location – kitchen, office) 를 기반으로 성별을 예측하거나, 남성보다 여성 지원자에 대해서 자동으로 고임금의 직무를 추천하지 않거나, 데이터/정치적 의사결정에서 편향된 제안을 하는 경우들이 있다고 합니다. 따라서 이런 상황을 예상하여 유럽 위원회에서는 신뢰할 수 있는 AI를 위한 윤리지침을 발행하였고, 미국에서는 잠재적인 인간의 편견을 가진 기계학습 방법 사용을 규제하기 위한 제도가 개발되고 있다고 합니다. (이 부분을 보니 우리나라에서도 발생했던 ‘이루다’ 사건이 생각이 나네요)
지도학습 모델은 이러한 인간 편향이 데이터와 라벨에 캡슐화되기 때문에 이런 편향을 학습하기 쉽다는 것이 입증되기도 하였습니다. 심지어 ImageNet의 이전 버전은 피부색, 나이 및 성별과 관련된 불균형적인 분포를 가져서 특정 그룹에 대해 underfitting 되었다고 합니다.
따라서 인간이 지정한 라벨을 사용하지 않는 SSL은 이런 레이블의 내제된 편향에 대한 영향을 덜 받을 것으로 예상됩니다. 이런 SSL이라고 할지라도, 데이터 자체의 포함된 편향은 피해가기 어렵습니다. 게다가 비지도 학습 모델에도 사회적 편견이 포함되어 있다는 연구 결과가 있다고 합니다. 따라서 저자는 이 사회적 편향에 대한 SSL 기법들에 대해 연구하였습니다.
아래 섹션에서는 편향이라는 것을 어떻게 정량화하는 지에 대해 나오니, 분석 결과가 궁금하시는 분들은 Experiment로 내려가시는 것을 추천드립니다!
Related Work
Measuring biases of computer vision models
해당 논문의 Related work에는 편향성을 측정하는 방법과 SSL 로 유명한 방법론들에 대해 간단하게 서술합니다. 저는 사실 편향이라는 것이 주관적이라고 생각하여 어떻게 정량화를 할 수 있는지가 궁금하였는데요.
기존에 많은 연구에서 이 편향성이라는 것을 정량화 하기 위해 Implicit Association Test (IAT) 를 사용하였다고 합니다. IAT란 편향된 관계를 측정하기 위해 concept과 attribute (이하 개념과 속성) 사이의 차등 관계를 측정하는 방법으로, 편향된 연관성이 존재하는 쉬운 concept과 attribute을 상관시킬 때 발생하는 응답자의 반응 시간 차이를 측정하는 방식입니다. 예를 들자면, 꽃이라는 개념을 pleasant 라는 attribute에 연관시키는 시간은 곤충이라는 개념을 plesant 라는 attribute에 연관시키는 것보다 더 적은 시간이 걸릴 것입니다. 이렇게 응답자의 반응 시간을 측정하는 방식을 IAT라고 합니다.
이런 연관성 편향 테스트는 NLP에서 많이 사용되었지만, 최근 Word Embedding Association Test (WEAT)을 이미지 영역으로 확장되면서 컴퓨터 비전 모델에서의 연관성 편향을 정량화하는 것이 가능하게 되었다고 합니다. 이름하여 Image Embedding Association Test (iEAT) 는 개념과 속성을 나타내는 이미지를 학습이 완료된 딥러닝 모델에 제공하여 얻은 이미지 임베딩을 기반으로 target 개념 x, y 및 속성 a, b의 차등 관계를 측정하게 됩니다. 예를 들어 target 개념이 곤충(x)과 꽃(y)이고 속성이 불쾌함(a) 과 기쁨(b)라고 가정해봅시다. 다음, 연관성 테스트는 x, y, a, b의 임베딩 사이의 코사인 거리를 기준으로 곤충과 불쾌, 꽃과 기쁨 사이의 상관관계를 측정하는 방법이라고 합니다.
본 논문에서는 이 방식을 채택하여 이미지 도메인에서의 편향을 측정하고자 하였으며, 아래 Method 섹션에서 자세히 계산하는 방법에 대해 다뤄보도록 하겠습니다.
Method
바로 직전에 언급한 것처럼 해당 논문에서는 iEAT 이라는 방법론을 사용하여 연관 편향의 존재를 살펴보았습니다. iEAT은 target 개념을 나타내는 이미지 (X, Y) 의 임베딩 {x, y} 세트와 측정된 속성 (A, B)를 나타내는 입력 임베딩 {a, b} 세트가 있어야합니다. 예를 들어, 과체중 사람과 마른사람의 개념은 아래 왼쪽 그림처럼 이미지로 표현되는 반면, 유쾌하다 및 불쾌하다와 같은 속성은 원자가 개념을 나타내는 아래 오른쪽 이미지처럼 시각화할 수 있습니다.


iEAT에서 테스트한 null-hypothesis는 X=과체중인 사람의 임베딩이 Y=마른 사람의 임베딩만큼 (A, B)=(pleasant, unplesant) 임베딩에 대해 유사하다는 것을 의미합니다. 그리고 null-hypothesis의 반대는 하나의 개념이 다른 개념보다 하나의 속성과 더 연관된다는 것을 의미하므로 연관 평향을 탐지합니다. iEAT은 permutation test와 아래 수식과 같이 정의된 미분 연관성(X, Y,A, B)를 정량화하는 메트릭으로 null-hypothesis 를 테스트합니다.
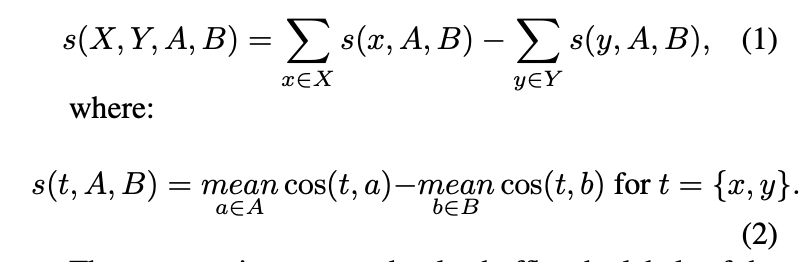
permutation test는 target 개념 (X, Y)를 나타내느 임베딩 집합의 레이블을 랜덤하게 섞어서 10000개의 랜덤 순열 집합을 생성합니다. 그런 다음, 이 순열 집합 각각에 대한 Equation 1에 의해 미분 연관성을 측정합니다. p-value는 원래 집합보다 더 크거나 동일한 미분 연관성을 생성하는 순열 집합의 백분율로 구해집니다, p-값이 특정 임계값보다 작으면 높은 확률로 null-hypothesis이 rejected 될 수 있으며 따라서 편향성이 있다고 판단합니다. 그리고 편향성의 강도는 effect size (d-value)로 측정됩니다. 자세한 수식은 아래 첨부하겠습니다.
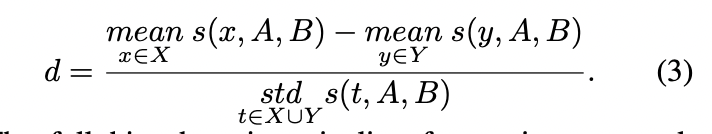
따라서 주어진 네트워크 모델에 대한 편향 감지는 2개의 개념과 속성을 나타내는 4개의 이미지 세트로 구성됩니다.
이렇게 해당 논문의 저자는 iEAT 저자가 제공한 데이터로 다양한 SSL 방법론에 대하여 분석하였습니다. 데이터는 인종, 성별, 나이와 같은 일련의 개념에 대한 시각적 자극이 포함되었다고 합니다.
Experiments
저자는 이 실험에서 가장 깊은 ResNet-50 임베딩과 중간 및 얕은 레이어에서의 임베딩에 대한 편향 탐지 결과에 대해 알아보았습니다.
Bias-analysis for the GAP embeddings
서로 다른 SSL 모델에 대한 사회적 편견의 존재 분석은 ResNet-=50의 GAP 계층 뒤에 잇는 임베딩을 사용하여 수행하였습니다. Method에서 서술한 방식으로 편향을 탐지하였습니다. 아래 그림이 바로 편향을 정량적으로 그래프화한 것인데요. 아래 오른쪽 그림을 통해 Contrastive / Non-Conrastive 모델 그룹 간의 편향의 수의 차이를 확인할 수 있었습니다. Contrastive 모델은 더 많은 편향을 생ㄱ성하는 데요 예를 들어 ,10^(-2) 에서는 rotation에 대해 편향이 탐지되지 않은 반면 Contrastive 모델에서는 8~12 정도로 나타났습니다. (참고로 아래 테이블에서 x 값은 p-value를 나타냅니다)
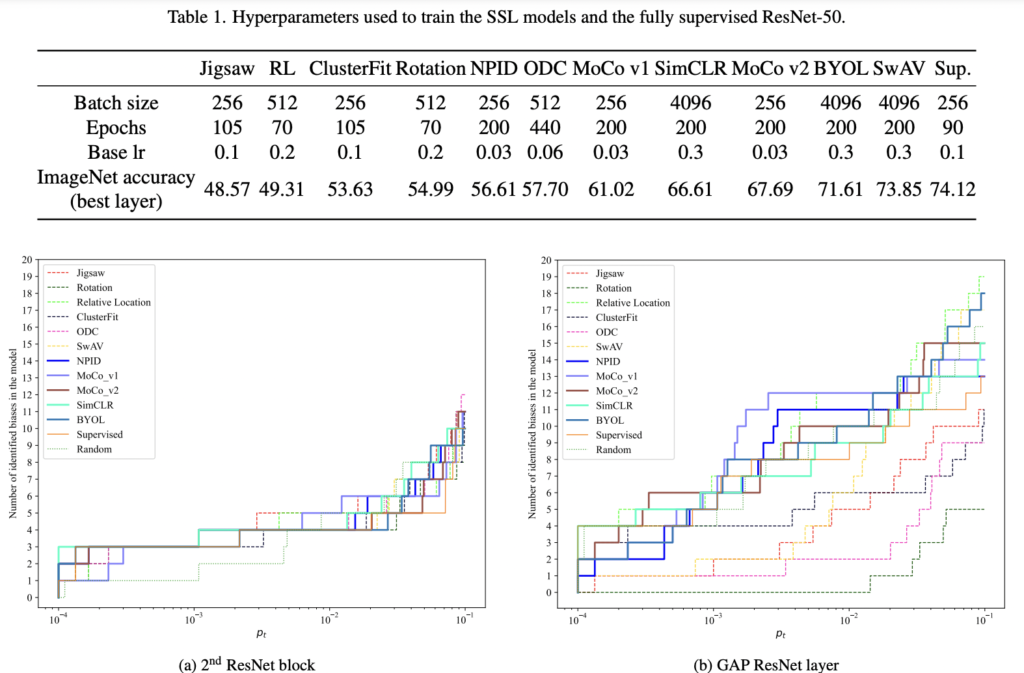
저자는 SSL 방법론에대해 1) Contrastive 2) non-Contrastive로 분류하여 두 가지 동일한 크기의 모델에 존재하는 편향의 통ㄱ적 분석을 통해 편향을 정량적으로 평가하였습니다. 위에 보이는 그림의 편향데이터와 표를 비교해보면, 모델의 분류 정ㄹ확도와 모델에 포함된 평향의 수 사이에는 직접적인 연관성이 없었따는 것을 알아볼 수 있었습니다.
Per-layer analysis
저자는 네트워크 아키텍처의 여러 레이어에 대해 강도와 편향의 개수가 달라질 것이라 예상하여 각 레이어에서 추출된 임베딩에 대해 조사하였습니다. 그 결과는 위에 있는 왼쪽 두번째 ResNet 블록에 나와있습니다. 의미론적으로 낮은 수준의 feature와 유사한 얕은 레이어의 피처 임베딩에서도 편향이 감지되었습니다. 그러나 얕은 레이어의 편향은 모든 모델에 대해 대부분 반복되는데, 예를 들어 인종과 관련된 편향이었다고 합니다. 반면, 오른쪽 그림에 나온 것처럼 깊은 레이어에서 추출된 피처 임베딩은 동일한 임계값에 대해 더 많은 평향이 발견되었습니다. 따라서 통계적 유사성의 정도가 동일한 편향의 수는 얕은 계층 임베딩에서 더 균일함을 확인하였습니다.
Discussion / Conclusion
저자는 다양한 SSL 모델에서 공통된 사회적 편견이 존재하는 지를 살펴보았습니다. 실험을 정리하면 탐지된 편향의 수는 SSL 모델의 분류 정확도가 아니라 유형에 따라 달라지고, Contrastive 기반의 방법론이 가장 많은 편향 수를 발생하였습니다. 또한 편향의 존재가 모델의 다른 레이어에서 일정하지도 않았고, 이러한 편향의 계층 분포가 모델마다 달라진다는 것을 확인하였습니다. 따라서 저자는 사전학습된 모델에서 Transfer를 수행할 때, 정확도 말고도 편향의 수와 강도를 함께 고려해야함을 제안하였습니다.
CVPR에 이런 분석과 관련된 논문이 있어서 새롭게 느껴져 한번 리뷰를 시도해보았습니다. 그동안 이런 논문보다는 방법론을 제안한 논문에만 치중하여 읽어본 것 같은데요. 완벽하게 이해할 수는 없었으나 약간의 시야를 넓혀준 논문 같습니다.