제가 이번에 리뷰할 논문은 VO(Visual Odometry)과정에서 센서들의 동기화가 맞지 않는 경우에 대응하기 위한 연구입니다. VIO에 대한 동기화 문제를 해결하는 것이 기본연구의 과제 중 하나인데, odometry의 센서 비동기화 해결이라는 점에서 활용할 수 있는 아이디어가 있을 것이라 기대하여 읽게 된 논문입니다. 이 방법론을 그대로 적용하지는 못하더라도 활용할 만한 포인트들이 있다고 생각이 됩니다.
Abstract
motion 추정시 센서가 동기화 되지 않는 경우에 대응하기 위해 해당 논문에서는 여러 센서(여기서는 센서는 카메라)로부터 VO를 추정하는 새로운 transformer 기반의 센서 퓨젼 방식인 AFT-VO를 제안하였다. 비동기 multi-view카메라의 예측을 결합하고 다른 센서로부터 오는 측정 시간의 불일치를 처리한다.
해당 논문의 방식은 Mixture Density Network(MDN)를 이용하여 시스템의 모든 카메라의 6-DoF 포즈의 확률 분포를 추정한 뒤, AFT-VO를 이용하여 동기화가 맞지 않는 신호를 융합한다.
nuScenes와 KITTI 데이터셋에 대해 해당 논문의 성능을 측정하였으며 VO를 위한 multi-view 융합이 강인하고 정확한 궤적을 추정하여 날씨와 조명 조건에서 모두 SOTA를 달성하였음을 보인다.
Introduction
VO는 연속적인 이미지를 이용하여 카메라의 상대적 자세와 움직임을 예측하는 것이다. 기존 VO 연구는 단일 카메라를 이용하였으나 이는 occlusion이나 조도 변화와 같이 이미지의 퀄리티가 떨어질 경우 잘 작동하지 않는 문제가 있다. 이로 인해 IMU 센서를 활용하는 연구도 진행되었으나 멀티 카메라를 이용하는 것이 각 카메라의 문제 상황에서 강인성을 줄 수 있는 가장 확실한 방법이다. 따라서 다른 뷰를 가진 두 카메라를 이용하여 VO를 수행하는 연구가 진행되었다.
멀티 카메라를 이용하는 시스템은 최적화 기반의 방식을 이용하는데 이는 두 신호가 동기화가 되어있다는 가정이 있고, 이러한 가정은 하드웨어적으로나 신호를 이용하는 genlock(한 소스의 비디오 출력을 사용하여 다른 사진 소스를 동기화하는 기술)을 요구하고 이미지를 처리하는 충분한 간격이 필요하므로 실제로 어려운 문제이다. 따라서 해당 논문은 멀티 카메라를 이용하여 강인한 VO를 추정하는 것을 목표로 한다. 이를 위해 새로운 프레임워크를 제안하였다.
해당 논문의 contribution은 다음과 같이 정리할 수 있다.
- AFT-VO라는 트랜스포머 기반의 deep fusion 프레임워크를 제안하여 비동기 신호를 융합할 수 있으며, 멀티 view VO 추정 문제에 적용할 수 있다.
- 두가지 새로운 방식을 도입하였다. 비동기 시스템의 시간 관계를 타나내기 위한 Discretiser, 모델의 정보 출처를 알리기 위한 Source Encoding.
- 공개 데이터 셋인 KITTI와 nuScens 데이터 셋에 적용하여 접근법을 평가하였고, SOTA를 달성하였다.
Multi-View Visual Odometry
해당 논문은 다른 센서에서 다른 시간에 촬영된 multi-view VO를 융합하는 문제에 대한 연구로, 차량의 궤적Y_{1:U}를 추정하고자 한다. 이때 비동기 비디오 시퀀스 \mathcal{V} = \left\{ \mathcal{V}^0, ..., \mathcal{V}^K \right\} 는 동일한 차량에 고정되어 있다. k번째 카메라인 C^k의 비디오 스트림은 다음과 같이 표현할 수 있다.
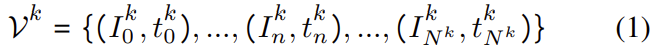
이때 비동기된 상태를 의미하므로, I_n^i와I_n^j는 n이라는 동일한 인덱스를 가지지만 다른 타임스탬프를 갖는다.(t_n^i≠t_n^j)
A. Mixture Density Network (MDN)
해당 연구에서는 학습 기반 방법론을 이용하여 6-DoF pose의 확률 분포를 추정하는 MDN를 이용한다. pose를 분포의 혼합으로 추정하면 융합 모듈의 불확실성의 지표를 이용할 수 있다.
먼저, CNN을 이용하여 각 카메라의 연속적인 이미지 쌍에서 latent 표현(w_t^k)을 추출한다. 이때 CNN은 기하학적으로 의미있는 feature를 학습하도록 입증된 FlowNet^{[1]}을 백본으로 이용하며 다음과 같이 수식으로 나타낼 수 있다.
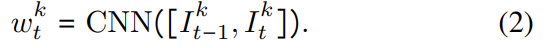
[1] Alexey Dosovitskiy, et al. Flownet: Learning optical flow with convolutional networks. In ICCV, 2015.
모션 추정은 시간 정보에 크게 의존하므로 RNN을 이용하여 시간적으로 풍부한 표현 r_t^k를 얻는다. 이는 아래의 식으로 표현할 수 있고, 이때 h_{t-1}^k는 RNN의 이전 hidden state를 나타낸다.
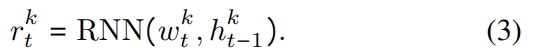
이를 통해 얻은, 시간적으로 풍부한 표현을 가진 r_t^k는 MDN 모듈로 전달된다. 혼합 모델을 다변량 가우스 분포(multivariant Gaussian distribution)로 구축하고, 혼합 모델 P_t^k는 다음과 같이 공식화한다.
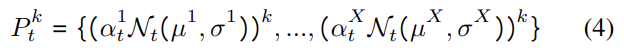
X는 융합된 요소의 수를 의미하고, µ, σ, α는 각각 평균, 표준편차, mixture 계수를 나타낸다.
혼합물들의 선형 조합은 타겟 pose y^k_{(t-1,t)}의 확률 밀도를 생성하며 다음과 같이 수식화할 수 있으며, 이때 ϕ_i는 i번째 요소에 대한 조건부 밀도 함수이다.
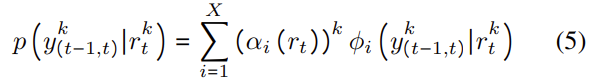
mixture 계수 (α_i(r_t))^k는 타겟 pose의 확률을 나타내며 i번째 요소에 의해 만들어진다. MDN 모듈은 GT pose와의 negative log likelihood를 최소화하도록 학습한다.
B. Asynchronous Fusion Transformer (AFT)
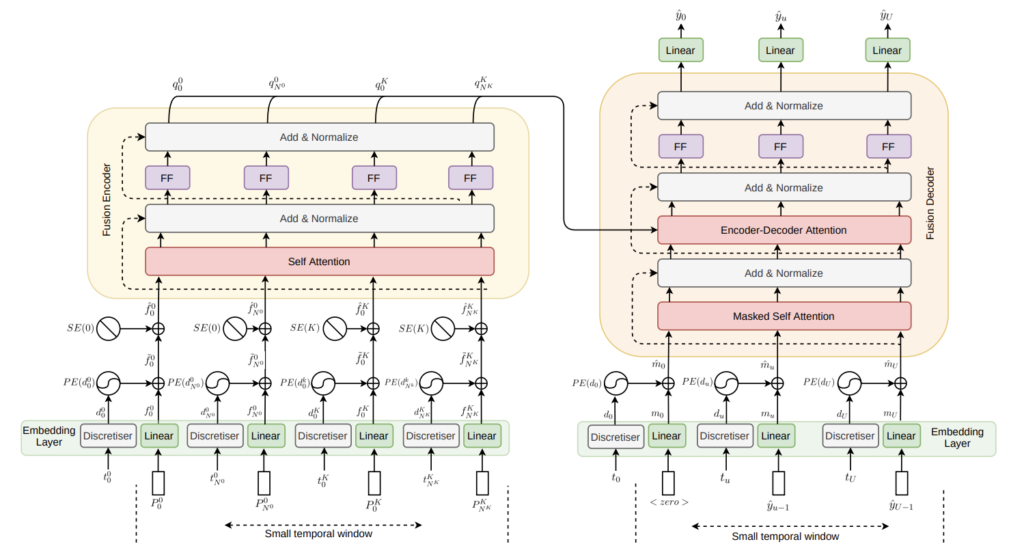
multi-view VO 추정 문제를 sequence-to-sequence 학습 문제로 보고 transformer 기반의, 비동기 카메라로부터 얻은 정보를 융합하는 방식을 제안하였다.
입력은 MDN모듈로부터 추정한 각 타임스탬프마다의 포즈와 불확실성이다. 이때 동기화가 맞지 않는 다른 두 카메라로부터 얻었기 때문에 집합의 크기가 동일하지 않을 수 있고(N^i≠N^j), 타임스탬프에 대한 인덱스가 동일한 n이라 해도 반드시 동일하지는 않다(t^i_n≠t^j_n).
각 카메라로부터 얻은 P_n^k를 선형 레이어를 통과시켜 latenet 표현으로 투영시킨다. : f_n^k = Linear(P^k_n)
트렌스포머는 시간정보를 모델링하지 않고 attention 방식을 이용하며, 이로인해 positional encoding로 고유 벡터를 생성하여 입력의 순서를 주게 된다. 그러나 이러한 방식은 입력들이 모두 동일한 간격을 가졌다는 가정이 있어야 하고, 해당 논문에서 해결하고자 하는 비동기 상황에는 적절하지 않아 Discretiser와 Source Encoding이라는 두 방법을 새롭게 제안한다.
Discretiser
이 모듈의 목적은 연속적인 시간 정보를 동일한 간격을 가진 이산 시간 간격의 bins 세트로 표현하는 것이다.
캡쳐된 정보는 정수 형식으로 시간 정보의 크기가 텍스트에 작동하도록 설계되었던 transformer의 문장의 단어 수 보다 크다. 또한 텍스트 도메인보다 느리며, 센서의 주파수는 캡쳐 중에 변할 수 있어 non-equidistant하게 된다.
- 이러한 문제를 해결하기 위해 연속적인 시간 도메인을 이산화 할 것을 제안한다. 주어진 일련의 타임 스탬프에서 가장 빠른 시간 정보를 찾아 이후의 값들을 빼주어 정규화한 다음, 시간 축을 더 작은 덩어리(실험에서는 Z=20ms로 설정함)로 나누어 연속적인 값을 가까운 시간 bin으로 그룹화한다.
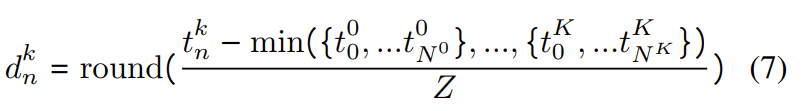
- 이후 이산화된 표현을 이용하여 연속된 입력에 대한 상대적 position embedding을 얻는다. 이를 위해 문장에서 위치 인덱싱하기 위한 positional encoding을 활용한다. 이를 통해 모델은 동기화가 맞지 않는 다중 source 신호간의 시간적 관계를 학습할 수 있게 된다.
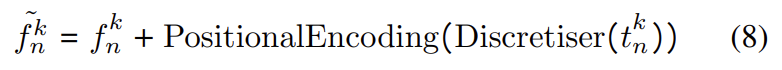
Source Encoding
transformer는 신호의 source를 알 수 있는 방법이 없지만 이 논문은 소스를 알 수 있어야 하므로 source encoding을 제안하였다. 시스템의 각 소스에 대한 고유한 one-hot-vector를 생성하여 학습 과정에 학습되는 선형 레이어에 one-hot-vector를 통과시킨 후 앞서 설명한 \tilde{f}^k_n에 결합한다.
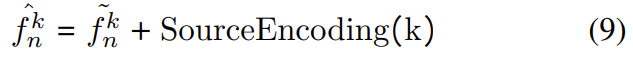
Fusion Encoder
transformer의 인코더 모델을 이용하여 상대 시간 위치와 소스 정보를 융합한다. 입력값들은 서로 다른 타임스탬프 간의 상관 관계를 학습하는 self-attention layer를 통해 모델링 된 후 position-wise feed forward 레이어를 통과한다. 이후 residual connection과 레이어 normalisation을 추가하여 인코딩을 진행한다.
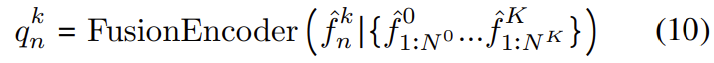
Fusion Decoder
encoder는 융합된 표현의 세트 Q=\left\{ q_n^k ∀ n, k \right\} 는 자동회귀(autoregressive)방식(변수의 과거 값의 선형 조합을 이용하여 관심 있는 변수를 예측하는 방식)으로 이용하여 차량의 odometry를 decode한다.
학습 시:
타겟 pose의 맨 처음에는 제로 벡터<0>를 붙여 decoder의 입력으로 이용한다. (두번째부터는 이전 프레임의 pose를 이용하므로 맨 처음을 채워주어야 함.) : \left\{ (<0>,t_0),...,(\tilde{y}_{u-1},t_u),...,(\tilde{y}_{U-1},t_U \right\}
pose에 시간 정보를 인코딩하기 위해 Discretiser를 이용하여 positional encoding을 수행하여, 시간정보가 포함된 \hat{m}_u를 얻는다. \hat{m}_u는 pose를 추정할 때 미래의 정보가 영향을 주지 않도록 막아주는 masked self-attention레이어로 들어간다. 이는 미래 정보를 이용하지 못하는 추론 과정에서도 작동할 수 있도록 하기 위해서이다.
그 다음 fusion 인코더와 디코더의 출력을 결합하여 encoder-decoder self-attention 레이어에 입력하고, 이 과정을 통해 소스와 타겟 pose간의 관계를 학습한다.
이때 fusion encoder와 마찬가지로 각 레이어들에는 residual connection과 레이어 normalisation를 수행한다.
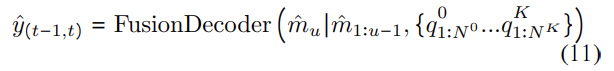
추론시 :
우리가 pose를 추정하고 싶은 시간 정보를 디코더와 함께 쿼리로 활용한다. 차량의 주행 기록을 알 수 할 수 있는 GT 시간 스탬프를 사용하였다. MSE를 이용하여 비동기 모델을 학습하였다.
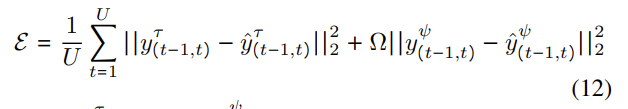
y_{(t-1,5)}^{\mathcal{T}}와 y_{(t-1,5)}^{\mathcal{ψ}}는 GT pose의 translation과 rotation를 나타내고, Ω는 rotation error의 중요도를 높이기 위한 파라미터(이 논문에서는 100으로 설정), U는 임의의 시간 간격에서 타임스탬프의 수를 의미한다.
Experiments
멀티 센서 VO의 SOTA와 AFT-VO의 성능을 비교하였다.
A. Dataset & Implementation Details
KITTI와 nuScene을 이용하였다.
- KITTI
- KITTI는 비동기화를 위한 성능 평가가 아닌, 동기화가 잘 맞는 경우에도 잘 작동하는 지 확인하기 위한 데이터셋으로 활용하였다.
- nuScene
- 360도의 이미지를 제공하는 6개의 비동기 카메라가 있어 동기화가 맞지 않는 경우에 강인하게 잘 작동하는 지 확인하기 위한 데이터셋으로 활용하였다.
B. Ablation studies
nuScene데이터를 이용하여 수행하였으며, (1) 서로 다른 카메라의 융합 효과, (2) 제안된 모듈의 효용을 확인하기 위한 ablation study를 진행하였다.
(1) Camera ablation
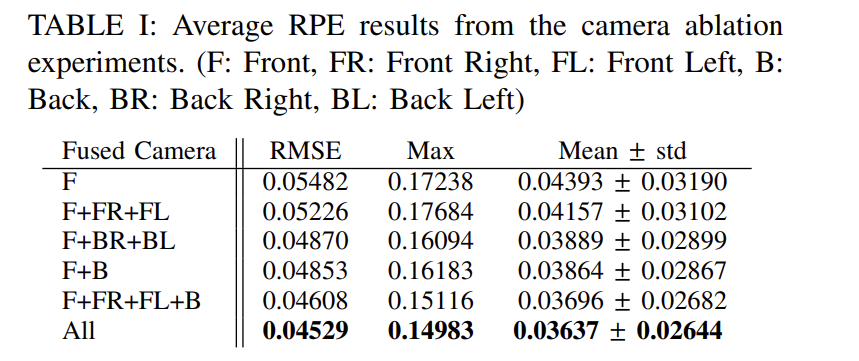
다양한 카메라 셋의 융합 효과를 확인하였다. 단일 뷰를 사용하는 F에서 가장 오차(std)가 큰 것을 확인할 수 있다. 또한, 3개의 카메라를 활용하는 경우(F+FL+FR) 보다 2개의 카메라를 활용할 경우(F+B)의 성능이 더욱 좋았고 그 이유가 F+B를 이용할 경우 중복된 영역이 적고, 더 넓은 각을 커버하기 때문이라고 보았다. 이러한 분석을 통해 여러 카메라의 정보를 융합하는 것이 좋은 성능을 가져올 것으로 판단하였고, 이 논문에서 제안하는 방법이 여러 카메라의 정보를 융합하는 방법이라는 점에서 활용성이 있을 것으로 보았다.
(2) Module ablation
해당 논문에서 제안한 모듈의 효과를 평가하였다.
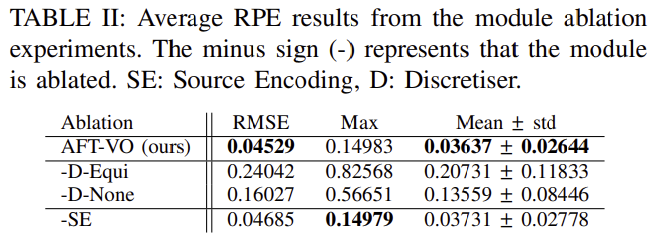
- -D-Equi: 모델이 연속적으로 동일한 간격이 프레임을 사용한다 가정하고 Discretiser를 기존의 positional encoding으로 대체하였다.
- -D-None: Discretiser와 positional encoding을 모두 제거하였다.
- -SE: source encoding모듈을 제거하였다.
시간정보를 제거할 경우(-D-Equi와 -D-None) 성능이 크게 떨어지는 것을 확인할 수 있다. 그런데 이때 시간정보를 완전히 제거하는 것이 기존의 positional encoding을 사용하는 것 보다 더 좋은 성능을 낸다는 점에서 비동기 데이터의 경우 정확한 시간정보를 제공하는 것이 중요하다는 것을 알 수 있다.
(3) Comparison Against the State-of-the-Art
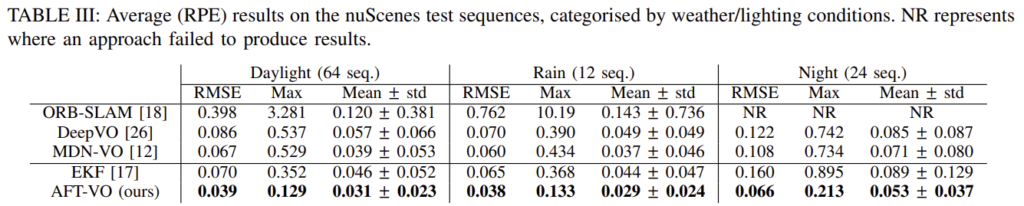
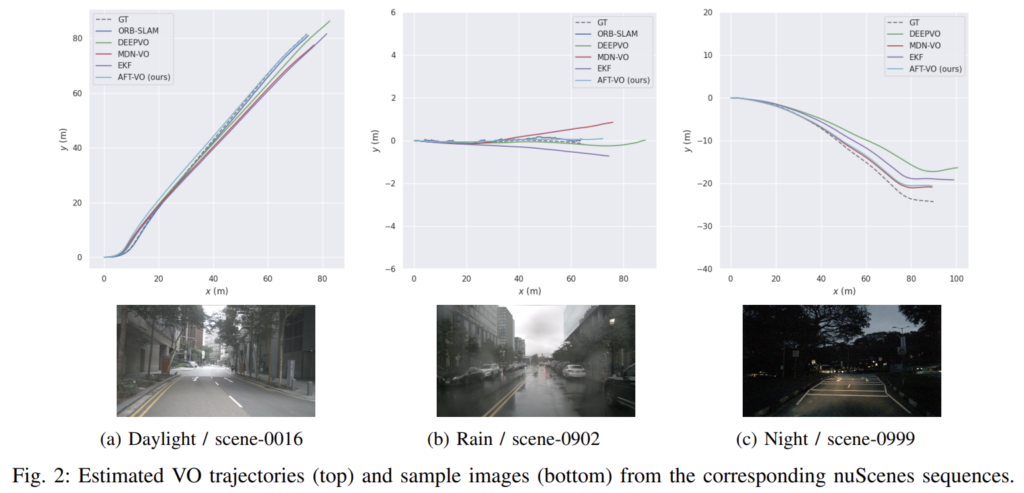
SOTA monocular VO 방식인 ORB-SLAM, DeepVO, MDN-VO와 Extended Kalman Filter(EKF)를 이용한 퓨젼 방식과 비교하였다. nuScene 데이터를 낮/비/밤 상황으로 나누었다. 이때 ORB-SLAM은 조도와 texture 정보가 부족하기 때문에 초기화 할 수 없다는 무제가 있어 밤 상황에 대한 결과는 리포팅하지 않았다.
ORB-SLAM 방식은 낮에는 좋은 성능을 보였으나 비가 오면 성능이 떨어지는 경향이 있다. 학습 기반 방식인 DeepVO와 MDN-VO는 야간에도 결과를 얻을 수 있으나 AFT-VO 방식보다 정확도가 떨어진다.
좋은 논문 소개해주셔서 감사합니다.
몇가지 질문 드리겠습니다.
1. 인트로에서
‘멀티 카메라를 이용하는 것이 각 카메라의 문제 상황에서 강인성을 줄 수 있는 가장 확실한 방법이다. ‘
라고 하셨는데 가장 이라는 단어는 저자가 사용한 것인지 아니면 승현님의 생각인지 궁금합니다. 그리고 왜 그렇게 생각하는지 궁금하네요.
2. 전 멀티 카메라의 장점이 3차원 위치 정보를 추정할 수 있다는 점이라고 생각합니다. 해당 방법론에서는 각 영상 간의 관계성을 포기하고 비동기화에 초점을 두고 개별적인 모노로 본다는 점에서 아쉬움이 크네요. 이에 대해 승현님은 어떻게 생각하시는지 궁금합니다.
3. 그리고 SOTA 모델들이 너무 예전 방법론 같아서 최근 방법론에서의 성능 지표는 없나요?