이번 논문은 가동원전 과제 중 RGBD를 활용한 3D object detection과 관련된 논문입니다. 해당 태스크의 이전 방법론들은 포인트 클라우드만을 이용하여 문제를 해결하려는 경향을 보였으나, 근래에 들어서 컬러 영상의 컨텐츠 정보와 포인트 클라우드의 명시적인 기하학적 정보를 잘 융합하여 좋은 성능을 보이는 방법론들이 대세를 이루고 있습니다. 이번 논문에서는 두 모달리티의 도메인 차이를 극복하기 위해 다리 역할을 수행하는 object token을 추가한 트랜스포머를 제안합니다.
Intro
이번 논문은 RGBD 데이터 셋(e.g. 실내)에서의 3D Object Detection을 수행합니다. 이전 연구에서는 포인트 클라우드(~= Depth map)을 다루기 쉬운 포맷(e.g. voxel, girid, polygon meshs…)로 변환하여 사용하는 추세를 가지다가 별도의 가공 없이 포인트 클라우드 자체의 특징적인 정보를 그룹핑하는 전략을 이용했습니다. 근래에는 명시적인 기하학적 정보를 가진 포인트 클라우드 뿐만이 아니라 풍부한 컬러 정보를 가진 컬러 영상을 이용한 multimodal 기법들이 놀라운 성과를 보여주고 있습니다.
특히, imVoteNet은 포인트 클라우드로부터 3차원 물체 위치 정보를 캐치할 뿐만이 아니라 사전학습된 2D 물체 검출기로부터 컬러 영상 속 2D 물체에 대한 feature를 추출하여 함께 활용합니다. 2차원과 3차원 간의 기하학적 연관성을 암시적으로 이용하는 방법을 통해 놀라운 성과를 보여주었습니다. 하지만 해당 방법은 단순하게 2차원과 3차원의 특징들을 명확한 연관성 없이 사용하기 때문에 모호성으로 인한 에러 값이 쌓여갈 수 밖에 없다는 문제점이 있었습니다.
++ 에러값이 쌓이는 이유에 대해 이해하기위해서는 사전 지식이 필요합니다. 우선 컬러 영상과 포인트 클라우드의 표현되는 해상도가 매우 상이하다는 점과 두 모달리티의 feature를 표현하면서 기하학적인 정보는 더 손실되기 때문에 안그래도 애매모호한 두 모달리티 간의 기하적인 연관성이 더 낮아진다는 문제가 있습니다.
해당 논문은 두 모달리티의 기하학적인 모호성과 적응적으로 융합하기 위해 생각보다 쉬운 방법을 제시합니다. 트랜스포머가 permutation invariant하다는 특성을 이용하여 모델 내부적인 영역에서 두 모달리티 간의 bridge 역할을 하는 coditional object queris를 제안합니다. 또한, 추가적으로 point-to-patch prohection을 두 모달리티의 공간 관계성을 명시적 활용하기 위한 방법으로 사용합니다.
++ permutation invariant를 이용한다는 의미에 대해 설명을 드리자면 트랜스포머는 구조상 영상의 형태, 입력되는 영상의 패치 정보의 순서에 상관 없이 연산이 수행됩니다. 허나, CNN인 경우에는 영상의 패치의 순서가 달라진다는 이야기는 다른 영상이 입력된다고 인식합니다. 그렇기에 다른 예측값이 나오기 때문에 permutation에 불변성이 없다고 이야기 합니다. 저자는 트랜스포머가 permutation invariant 하기 때문에 위치 정보에 큰 연관 없이 각 특징 정보간의 유사성을 학습하여 보다 잘 정렬된 결과를 보일 거라는 것으로 보입니다. ps. 논문에 이에 대해 명시된 내용이 없네요….
Method
Overall architecture
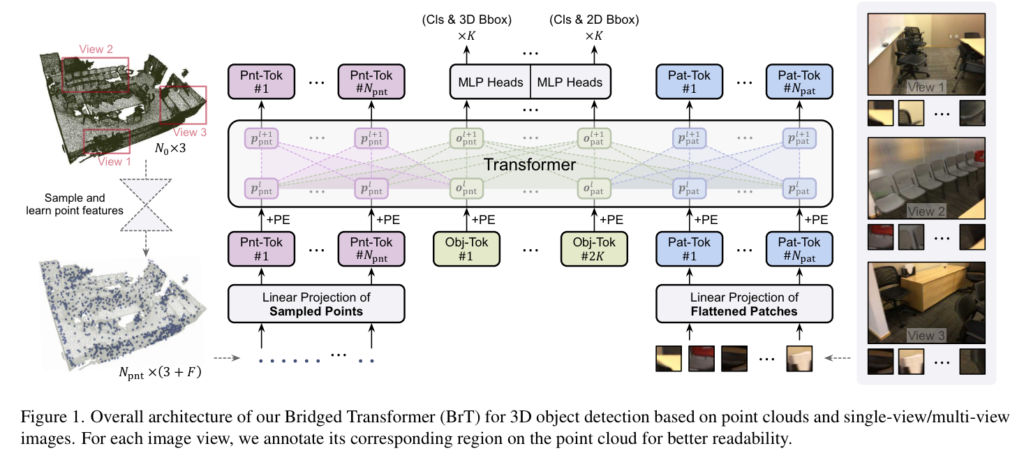
해당 모델은 기본적으로 DeiT의 방식을 따릅니다. MHA(Multi-Head Attention)과 MLP를 이용하는 방법과 영상 정보인 경우에는 patch embedding을 수행합니다.
포인트 클라우드인 경우에는 날 것 그대로인 정보를 사용하는 것이 아닌 local한 영역에서의 포인트 클라우드 정보를 점진적으로 receptive feild를 늘려 보는 PointNet을 이용하여 feature를 추출하여 사용합니다. 이때 선별된 포인트 N_{pnt} 를 입력 정보로 사용합니다. 영상 정보인 경우, DeiT와 동일하게 패치 사이즈와 동일한 CNN을 이용하여 패치로 나눠 사용합니다. 해당 논문에서는 16×16 패치를 이용하여 N_{pat} 로 나눠 입력으로 사용합니다. 두 입력 정보들은 object query를 이용하여 상호보완적인 정보를 출력합니다. Object query는 선별된 포인트 특징 정보와 영상 패치의 수에 따라 N_{pnt} + N_{pat} = 2k 로 구성됩니다. 각 정보들은 token으로써 입력이 되며 L 개의 transformer blcok과 MLP 지나 object query를 중심으로 K 개는 3차원 bbox와 그에따른 cls, 남은 K개는 2차원 bbox와 그에 따른 cls를 예측하게 됩니다. 최종적인 loss는 수식 2와 같이 각 예측값에 따른 loss를 구하여 계산되어집니다.
+ 각 loss는 imVoteNet과 GroupFree 방법론에서 사용된 loss를 사용합니다. 논문에서는 loss에 대한 자세한 설명 없이 레퍼런스로 마무리 지은 걸로 보아 저자가 강조하고 싶은 부분이 아니였던 것 같습니다. 그렇기에 따로 추가하지는 않겠습니다.
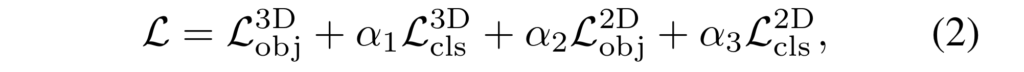
Transformer building block of BrT
앞서 언급한 바와 같이 DeiT를 기본 베이스로 사용하며 block 또한 MHA를 기본으로 합니다. 단, 각 모달리티들은 직접적으로 상호작용하는 것이 아닌 중간 다리 역할을 하는 object query간 간접적인 상호작용을 수행하기 위해 사용됩니다. 그림 1에서도 보이는 바와 같이 두 모달리티들은 직접적으로 attention을 주지 못하도록 구성되며, 아래의 수식과 같이 포인트와 패치에 대한 object query o_{pnt}^{l}, o_{pat}^l 와 각 모달리티에 해당하는 토큰 별로 concat되어 MHA를 수행합니다.

+ Att( query, {key})에 해당하며, l 는 진행 중인 층, i와 j는 토큰 인덱스를 의미합니다.
두 object query들은 아래의 수식과 같은 가정을 통해 두 모달리티 간의 간접적인 attention을 진행합니다.
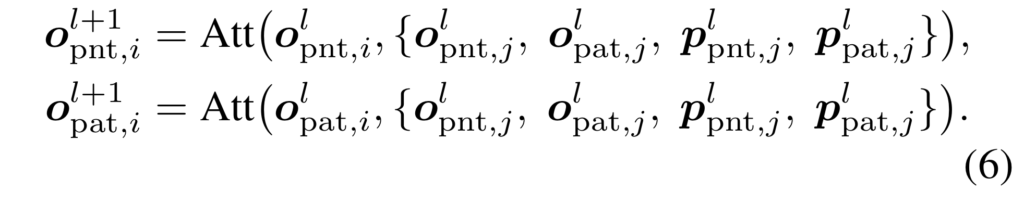
수식 5를 통해 각 모달리티만의 고유한 특징을 유지하되 수식 6과 같이 object query를 이용하여 간접적으로 각 모달리티의 상호적 관계에 대한 feature fusion을 진행함으로써 모호한 위치 정보 마저 학습이 진행되며 암시적으로 각 모달리티 간 유의미한 정보가 정렬되는 현상을 야기됩니다.
Bridge by conditional object queries
앞서 언급한 바와 같이 3차원 공간의 포인트 클라우드와 픽셀 좌표계인 2차원 영상은 서로 다른 공간에 속합니다. 그렇기에 수치적으로 정규화를 수행한 후, 모델이 학습하더라도 두 공간의 관계를 학습하기 어려울 수 있습니다. 저자는 이러한 문제를 하결하기 위해 2D와 3D를 모두 인식하여 작동하는 conditional object query를 제안합니다.
conditional object query는 트랜스포머 기반의 2차원 검출기인 DETR에서 영감을 얻었습니다. DETR에서는 랜던한 값으로 초기화된 object token을 decoder의 object query로써 입력을 받아 2차원 물체 검출을 수행합니다. 저자는 랜덤한 초기화에 생성된 값에서도 물체의 위치를 잘 찾는 능력에 영감을 얻어 포인트와 이미지의 object query를 정렬하고 성능 향상을 얻기 위해 랜덤한 값이 아닌 포인트 기반의 정보로 구성된 conditional object query를 대신해서 사용합니다.
conditional object query은 두 모달리티의 정보와 토큰 수를 일치 시키기 위한 몇가지 트릭을 제안합니다. 가장 먼저 유의미한 포인트를 추출하기 위해서 PointNet으로부터 추출된 정보 N_{pnt} 로부터 kNN을 통해 k_{pnt} 와 이에 대응되는 f_{pnt} 을 추출합니다. 그런 다음 아래와 수식을 이용하여 차원과 특징 값을 적응적으로 학습하여 추출합니다.
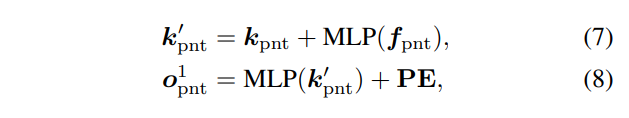
여기서 PE는 랜덤하게 초기화된 positional embeddings이라고 합니다. 그런 다음 영상 정보에 대응되는 object query o_{pat}^1 는 아래의 수식으로 추출됩니다.
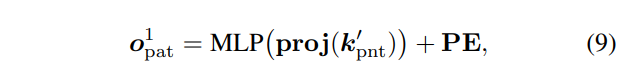
K 개의 포인트는 카메라 파라미터로 구성된 proj()을 통해 영상 좌표계로 사영됩니다. 정의하자면 proj(k_{pnt}^{'} \in \matbb{R}^{K \times 2} 로 사영되며, MLP를 통해 o_{pnt} 와 동일한 차원을 가지며, 적응적으로 특징값을 조절할 수 있도록 합니다.
추가로 PE는 두 object query에서 동일한 정보를 사용함으로써 모델에게 직접적으로 두 정보가 일치하다는 것을 알려줍니다.
Bridge by point-to-patch projection
해당 섹션에서는 두 모달리티의 연관성을 더욱 강화하기 위해서 point-to-patch projection을 수행합니다. 해당 모듈은 특정하게 샘플링된 포인트 클라우드와 해당 정보가 있는 영상 패치 정보를 활용하는 방법에 대해 제안합니다. 자, 입력 영상 H x W에 포인트 클라우드를 사영한다고 하였을 때, 우리는 이제 특정 포인트 클라우드가 픽셀 위치 u, v에 어디에 있는지 알 수 있습니다. 이를 수식으로 정리하면 아래와 같습니다.
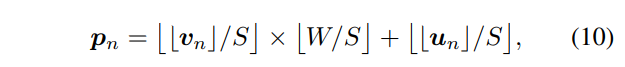
여기서 ⌊·⌋ 는 반올림을 의미합니다. S는 영상 패치를 의미합니다. 이를 통해 특정 포인트 클라우드를 포함한 영상 패치를 알아낼 수 있게됩니다. 저자는 입력 정보를 보다 풍부하게 주기 위해서 아래의 수식을 추가합니다.
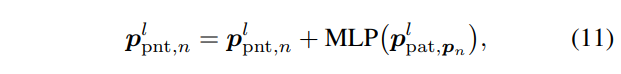
이를 통해 두 모달리티는 공간의 차이로써 발생하는 도메인 갭을 더욱 줄일 수 있게 됩니다.
Experiment
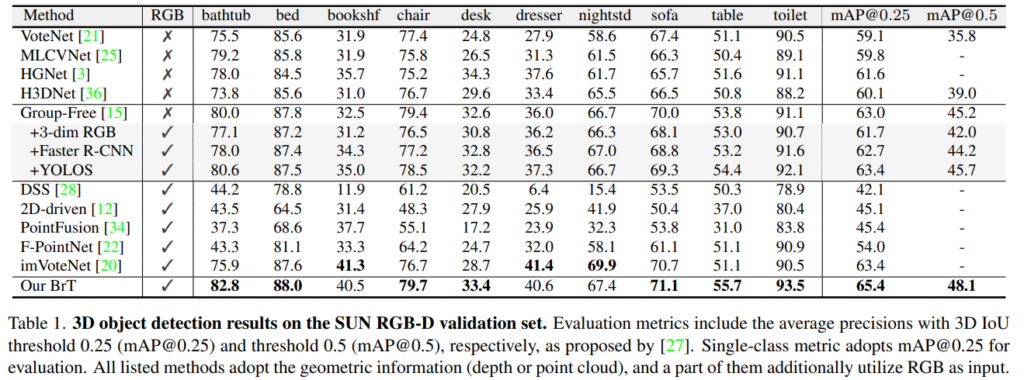
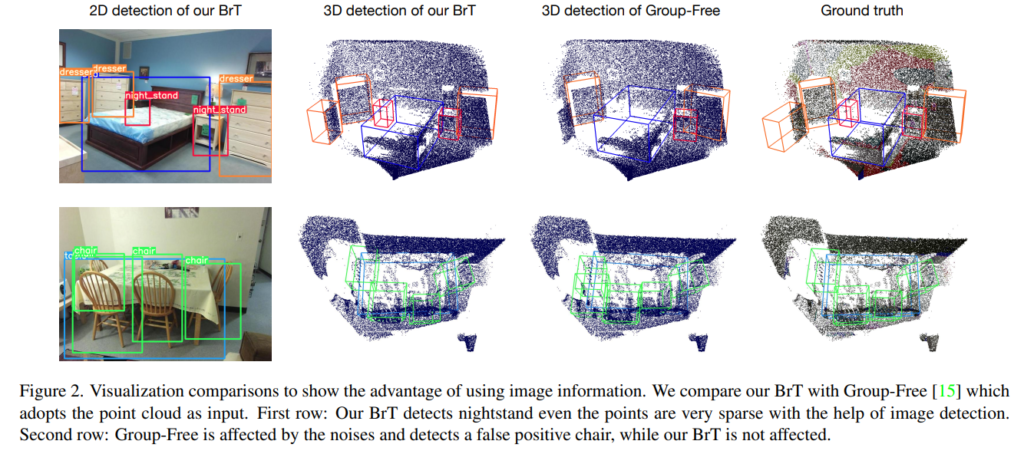
RGBD 데이터 셋 SUN-RGBD에서 정량/정성적으로 좋은 결과를 보여줍니다.
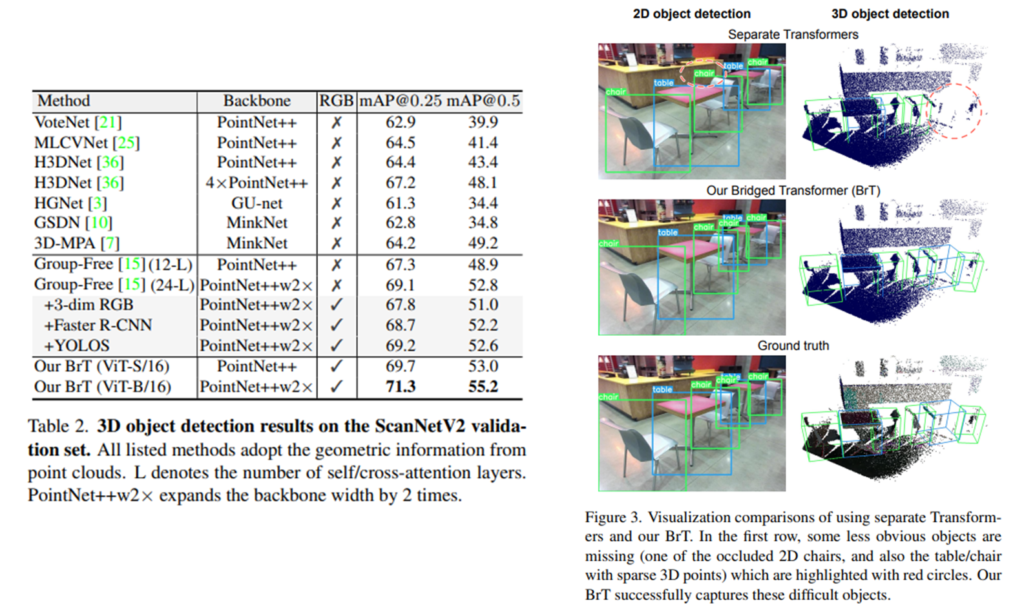
또 다른 RGBD 데이터 셋인 ScanNetV2에서도 좋은 결과를 보여줍니다.
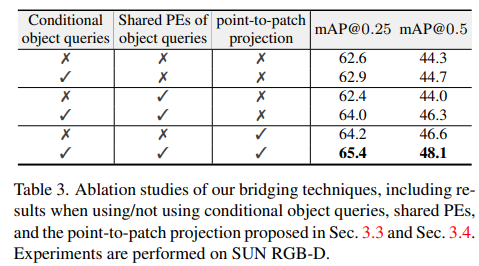
제안한 기법들에 대한 ablation study 결과 입니다. 여기서 흥미로운 점은 point-to-patch projection만 수행했을 때, 2번째로 높다는 점이 가장 흥미로운 것 같습니다. 입력 데이터를 사전 처리를 수행한 파트인데 높은 성능 향상을 보여줍니다.
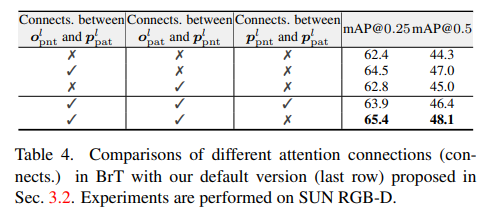
여기서는 토큰 별로 연결에 따른 ablation study 입니다. 흥미로운 부분은 포인트와 영상 토큰을 직접으로 연결 했을때, 오히려 성능이 떨어진다는 점입니다. 해당 실험에서 포인트와 영상 토큰을 직접 연결한 실험도 같이 있었으면 좋았을텐데 아쉽네요.
사실 알고리즘 자체는 가져다가 사용한 방법이지만, 속에 있는 모듈들이 직관적으로 문제를 해결하는 점에서 높은 평가를 받은 것 같습니다. 저자가 제안한 관점은 멀티스펙트럴에도 적용 가능하다고 판단하며, 나중에 3차원 물체 검출 수행에 있어 베이스 모델 중 하나로 가져갈만하다고 생각이 드네요.