안녕하세요. 이번에 제가 리뷰하게될 논문은 개인적으로는 흥미로운 논문이었습니다.
주제가 무겁지않고, 연구원분들 대부분이 익숙한 개념도 많이 등장하여 아마 어렵지 않게 리뷰를 이해할 수 있을거라고 생각합니다. 다만, 분석적인 내용이 많이 등장하므로 너무 편한마음으로 읽으면 조금 머리가 아플수도 있습니다.
바로 본론으로 들어가서, 오늘의 주제에 대해서 이야기 해보겠습니다.
오늘 제가 리뷰할 논문은 2020 Sensors 논문으로 SSD와 YOLO기반으로 Ad Panel Detection을 수행하고 비교하는 논문입니다.
여기서 Ad Panel이 무엇일까요? 그림으로 살펴보겠습니다.


위의 그림에서 광고판이 바로 Panel입니다. 한국에도 주로 버스정류소나 길거리에 저러한 AD Panel들이 많이 존재합니다. 해당 논문에서는 Smart City로 인트로를 열고, Panel Detection이 필요한 이유에 대해서 설명합니다. 여러페이지에 걸쳐서 설명하는데 사실 뻔한 이야기 이므로, 내용은 생략하겠습니다. Panel Detection이 필요한 이유에 대해 저자가 이야기 하는것이 궁금하신 분들은 한번 읽어보세요.
본론으로 돌아가서 본 연구에서는 Panel Detection을 YOLO와 SSD로 수행하고 비교분석합니다.
제가 서론에서 흥미로운 논문이라고 말씀을 드렸었는데, 그 이유는 본 논문에서는 SSD와 YOLO의 차이점에 대해서 실험적으로 분석하여 다루었으며, 그러한 경향성이 제가 직접 설계했던 SSD와 YOLO기반의 모델들과 비슷하게 나타났기 때문입니다.
다만, 논문을 읽고 아쉬운점이 꽤 있었는데 어떠한 점들이 아쉬웠는지 리뷰의 마지막에서 설명드리겠습니다.
먼저 본 논문에서는 Contributions을 아래와 같이 이야기합니다.
The paper describes a detailed experimental comparative study on the application of SSD and
YOLOv3 for the considered problem in practical conditions. The main contributions of this work are
the following ones:
• Experimental comparative study of deep one-stage detector networks applied to the outdoor
OPPI panel detection problem. SSD and YOLO detectors are compared under multiple variability
conditions (panel sizes, occlusions, rotations, and illumination conditions) to show the pros and
cons of each model.
• Comparison with semantic segmentation networks for a similar problem and under the same
evaluation metrics.
• Creation of an annotated dataset for this problem available to other researchers.
요약하자면,
- SSD와 YOLO를 다양한 제한조건에서 비교하였다.
- Ad Panel Detection을 하는 논문들에서 사용하는 방법인 Semantic Segmentation과 같은 평가지표로 비교하였다. (개인적으로 해당 실험은 굳이 해야했나 싶네요. 그냥 깔끔하게 YOLO vs SSD만으로 마무리했으면 어땠을까 싶네요.)
- Ad Panel 데이터셋을 직접취득하고 공개한다. (기존에 공개 데이터셋이 없었으므로)
사실 가장 큰 Contribution은 1번 YOLO와 SSD를 비교한거라고 생각을 합니다. 그래서 제 리뷰도 해당 부분을 중점적으로 설명드릴것 입니다. 제가 젤 관심가던 부분이기도 하고요. 본 논문이 23페이지라 내용이 좀 많은데 YOLO vs SSD 내용만 리뷰해도 양이 꽤 될 거 같네요.
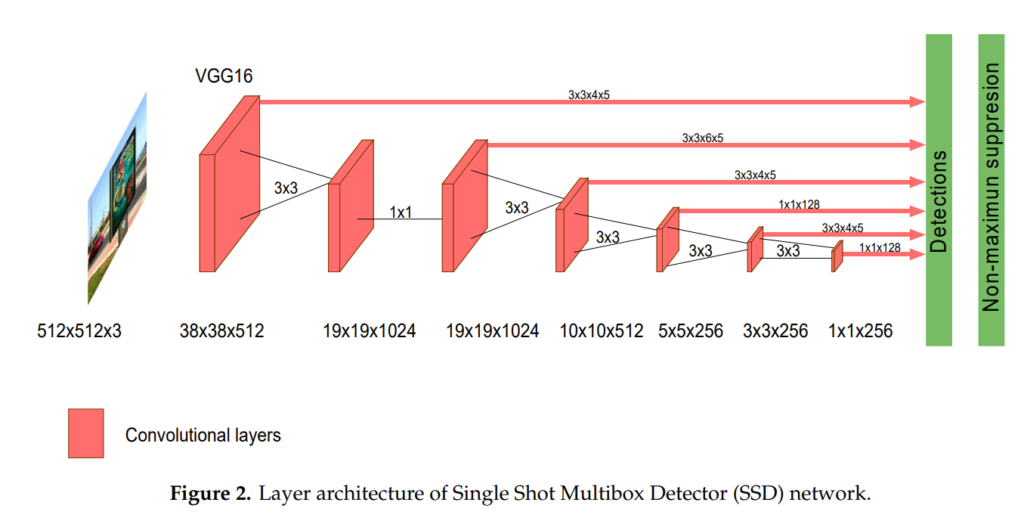
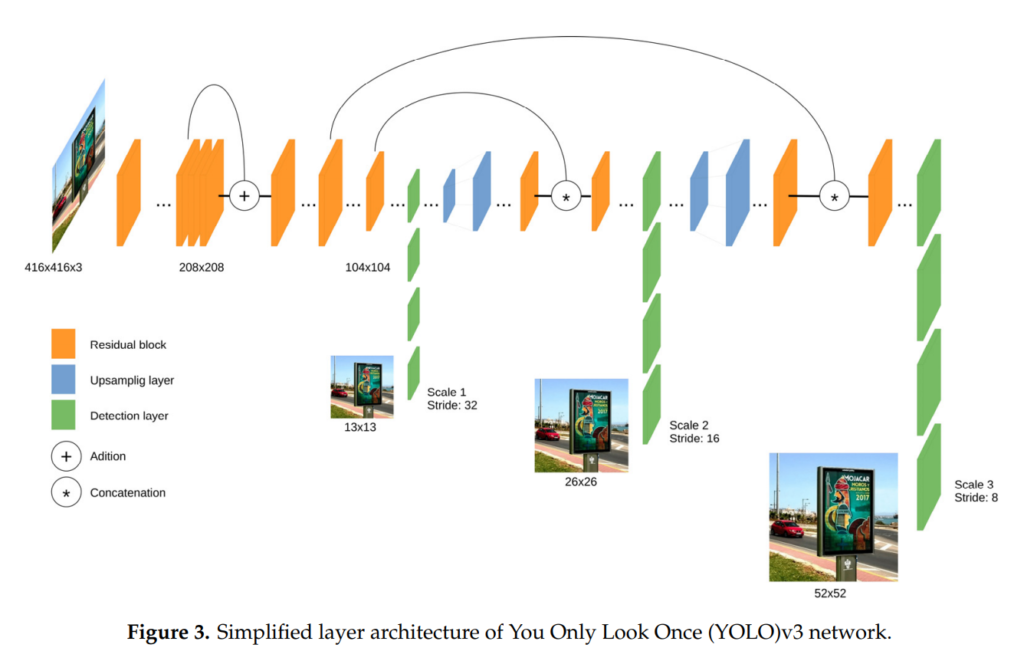
먼저, 본 논문에서는 SSD와 YOLOv3를 비교합니다. YOLOv3를 가지고 온 것은 적절해보입니다. v1과 v2는 멀티스케일 피쳐를 사용하지 않고, 시기적으로도 v3와 ssd가 비슷한 시점에 나왔으니깐요. 그리고 최신 욜로 버전들도 V3를 기반으로 설계하고있습니다. 위의 그림들은 SSD와 YOLOv3 아키텍쳐입니다.
SSD는 연구원분들은 다 익숙하신 아키텍쳐라고 생각이 되어서 YOLO에 대해서만 짧게 이야기 해보겠습니다.
더 궁금하신점이 있으시다면, 이전 리뷰를 참고해주세요.
YOLO는 위의 Figure 3에서 보이는 것처럼 3개의 피쳐맵을 뽑아내서 사용합니다. 그리고 그러한 피쳐맵을 Grid map이라고 칭합니다. 각각의 그리드맵은 SxS의 정사각형 모양입니다. Resolution을 맞추는데는 SPP라고 불리는 방법을 사용하여 fixed resolution의 SxS grid map을 항상 아웃풋으로 갖습니다.
Grid map에서의 픽셀 하나하나를 grid cell이라고 표현합니다. 각각의 grid cell은 4개의 [x, y, w, h, o, c]*3의 채널을 가집니다. 이 때, x, y, w, h는 bbox의 offset을 의미하고, o는 해당 grid cell 내에 object가 있을 확률, c는 class에 대한 확률값으로 c항은 class의 개수에 따라서 달라집니다. *3이 붙는 이유는 anchor box의 개수를 일반적으로 3개를 사용하기 때문입니다.
이렇게 총 3개의 scale이 다른 grid map으로 grid cell마다 3개의 anchor box에 대한 x, y, w, h, o, c값을 뽑아내서 bbox를 예측하는데 사용합니다.
SSD와 큰 차이점이라고 한다면, 우선, object score항인 o 가 존재한다는 것 입니다. SSD에서는 o 항이 없는 대신에 c값에 c+1(background)로 사용됩니다. 즉, SSD에서는 object가 아닐때는 background class로 예측을하고 YOLO에서는 object score가 낮게 예측이 됩니다.
또 다른 차이점은 YOLO에서는 Confidence score에 IoU를 곱해서 사용한다는 것 입니다. 때문에 전체적으로 confidence score가 낮은 경향이 있는 대신 좀 더 IoU 높게 detection을 합니다. 즉, 좀 더 GT와 오버랩이 잘되게 찾습니다.
위와같은 배경지식을 가지고 저자가 분석한 SSD와 YOLO의 관계에 대해서 알아보겠습니다.
그전에 우선 저자가 전체적으로 설계한 실험 파이프라인을 보겠습니다.
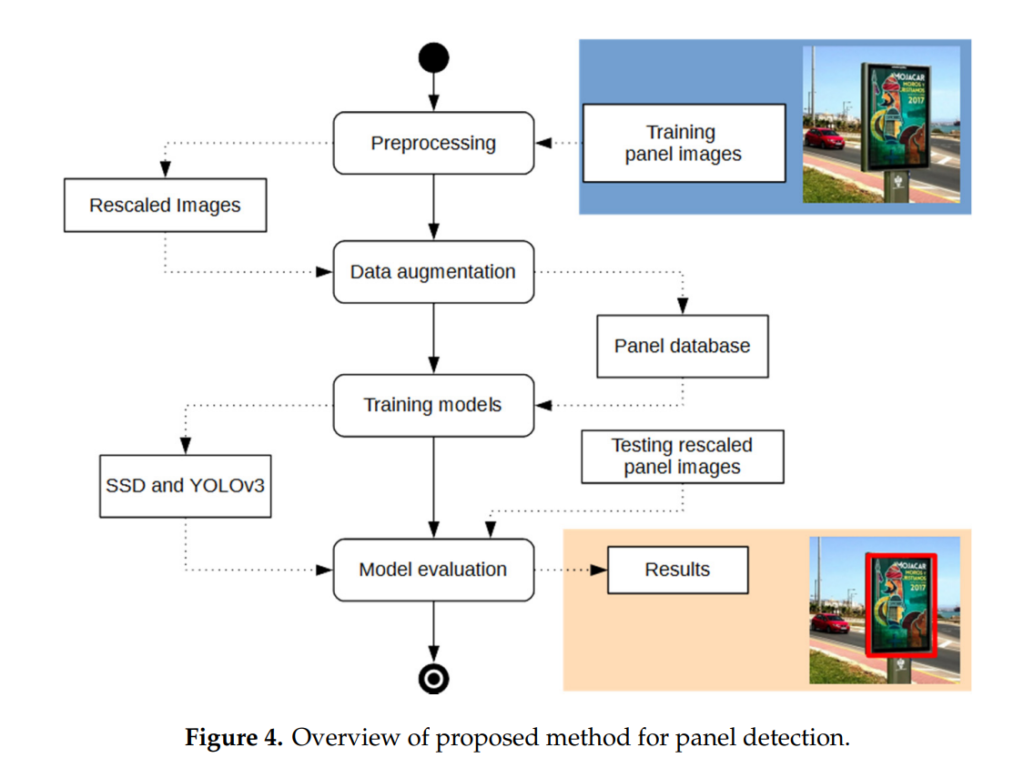
논문의 저자는 위와 같은 파이프라인을 구성하여 실험을 하였습니다. SSD vs YOLO 구도에 맞게 최대하 비슷한 세팅으로 맞추었다고 합니다. 본 논문은 알고리즘을 제안하는 논문이 아닌 SSD vs YOLO 비교분석 논문이므로 파이프라인에 대해서는 설명을 생략하겠습니다. (자세한 내용은 페이퍼 참고, 전체적인 논문의 핵심 키포인트를 캐치하는데는 마이너해보이므로 생략하였는데, 위의 그림만 봐도 쉽게 이해할 수 있을 수준이라고 생각됨.)
실험
실험을 진행할 때, 논문의 저자는 아래에 나열된거처럼 몇가지 변수들을 정의하고 YOLO와 SSD의 성능을 자체 취득 데이터셋에서 비교분석 실험 하였습니다.
- Small object
- Occlusion
- Illumination
자체 취득 데이터셋은 아래와같은 분포를 보입니다.
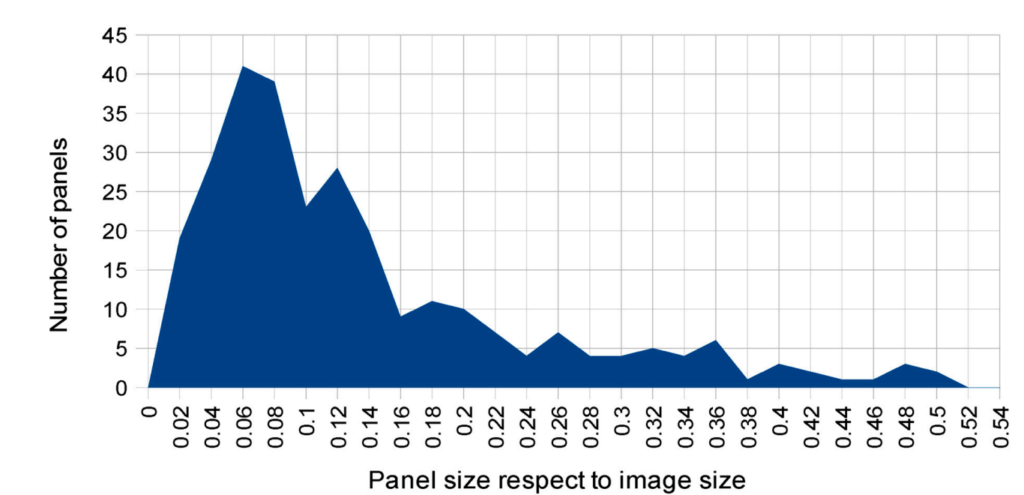

조금 아쉬운점이 데이터셋의 개수가 많이 않다는 것 인데요, train test합쳐도 1000장을 안넘는거 같네요. 분석내용 자체는 흥미로운 점들이 많았지만, 데이터셋의 개수가 적어서 신뢰할 수 있는 경향성일까? 라는 의구심이 듭니다. 그래도 2~3천장만 되었어도 그런 걱정이 적었을텐데 아쉬운 부분입니다.

위의 그림은 실험에 사용된 데이터셋의 예시 사진들입니다. Occlusion이 발생했거나, small size 등등 상황을 잘 재현해두긴 하였네요.

위의 수식은 SSD에서 사용하는 평가매트릭 수식과 동일합니다.
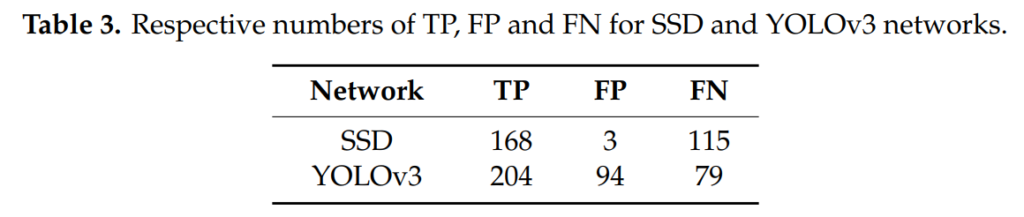

해당 수식으로 평가해봤을때, 위와같이 나왔습니다. 기왕이면, 좀 더 보기 편하게 AP도 같이 리포팅했으면 하네요.
위의 실험결과가 의미하는 것은 SSD에서는 FP를 효과적으로 잘 제거하였고, YOLOv3에서는 TP를 좀 더 잘 찾았다는 것 입니다. 상당의 유의미한 실험입니다. 왜냐면, 직관적으로 YOLO에서는 Confidence score에 IoU를 곱해서 사용하므로 전체적으로 confidence score가 낮아지게 되서 FP가 많이 발생하는데 이를 실험적으로 보였기 때문입니다.
FP를 잘 제거하지 못하는 대신에 YOLO에서는 IoU가 더 높게 나오네요, 사실상 당연한 것이 학습을 할 때, IoU를 더 높게 맞추게끔 학습이 되므로 당연한 결과라고 생각이 되긴 하네요.
기존에는 위와 같은 내용을 직접설계한 SSD, YOLO기반의 모델들을 이용한 실험의 경향성을 통해서 추측만 하였었는데, 저와 비슷한 생각을하고, 직접 논문으로 분석적인 글을 작성한 사람이 있단게 신기했습니다. 개인적으로 머릿속에 혼잡하던게 교통정리되는 기분이네요.
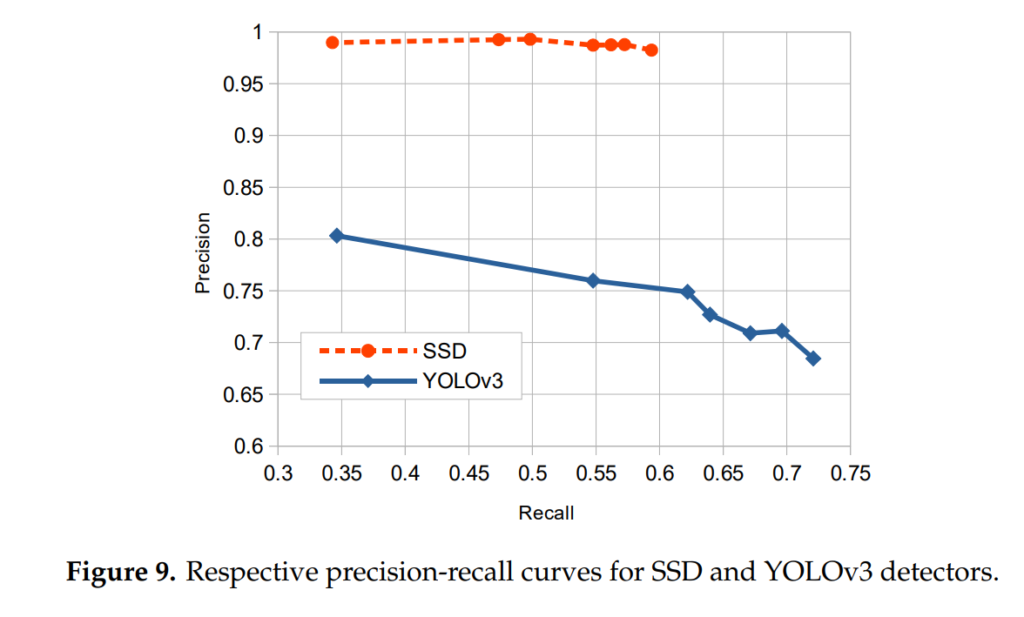
Precision-Recall 커브 결과입니다. AP가 리포팅 되지 않아서 아쉽지만, AP는 해당 그래프에서 아래면적에 해당합니다. 전체적으로 보면 AP에 큰 차이가 없어보이나, SSD는 precision 이 높은 반면에 YOLO는 precision보단 recall이 높은게 흥미롭네요. 쉽게 말하자면 SSD는 좀 더 정확하게 찾고, yolo는 부정확하게 찾아도 결국에 더 많이 찾는단 의미가 됩니다.알고리즘들을 적용하는 도메인에서 정확성과 어떻게든 찾아내는 것 중에서 무엇이 더 중요한지에 따라서 모델을 선택하면 되겠다는 생각이 드네요.
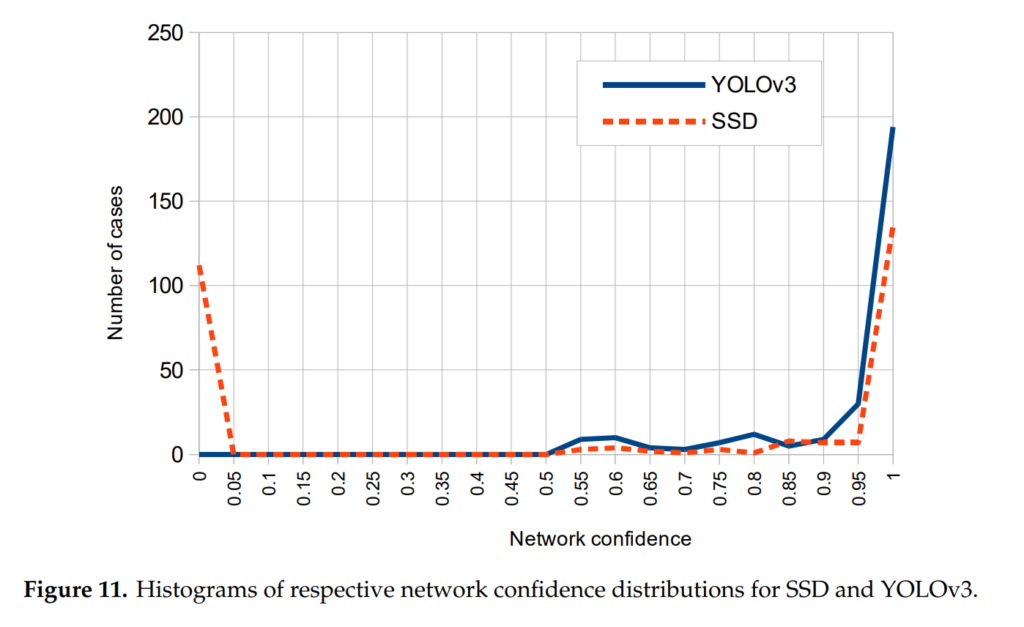
위의 그래프는 또 다른 흥미로운 결과입니다. SSD와 YOLO의 Confidence distribution에 대해서 분석한 내용인데요. SSD에서는 confidence가 낮은 얘들과 높은 얘들이 극과 극으로 갈리는 반면에 YOLO에서는 전반적으로 고르게 분포하고 있습니다. Confidence score에 IoU를 곱해서 사용하는 YOLO의 특징때문에 발생한 문제라고 생각이됩니다. YOLO에서 FP가 왜 높게 나오는지 설명해주는 그래프네요.
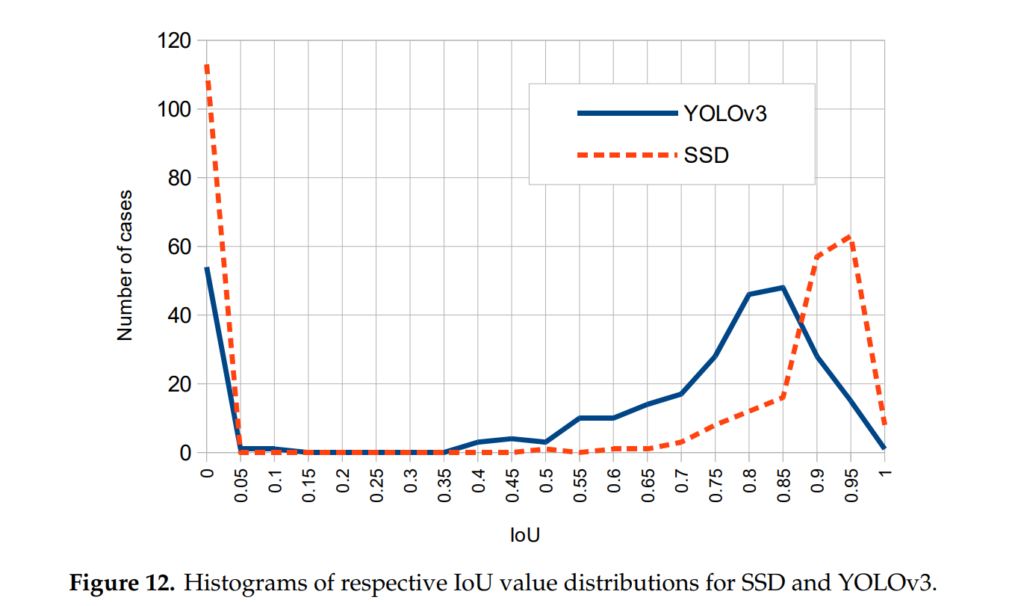
위의 그래프는 IoU와 Number of cases를 보여줍니다. 얼핏보면 YOLO가 IoU가 더 낮게 검출된거 같지만, 실제로 검출된 결과의 평균 IoU를 비교했을때, YOLO가 15% 정도 더 높았다고 합니다. 기존에 저는 YOLO는 IoU를 direct하게 고려하므로 좀 더 정확한 위치를 찾는데 유리하다고 생각하였는데, 그것도 아닌거 같네요. 대신 YOLO는 True positive를 좀 더 잘 찾는데 특화된거 같습니다. 맞는 표현인지 모르겠지만, YOLO는 잘모르겠으면 찍어서라도 맞추고, SSD는 확실한거만 답안지에 마킹을 한다고 생각하면 이해하기에는 편할거 같네요.
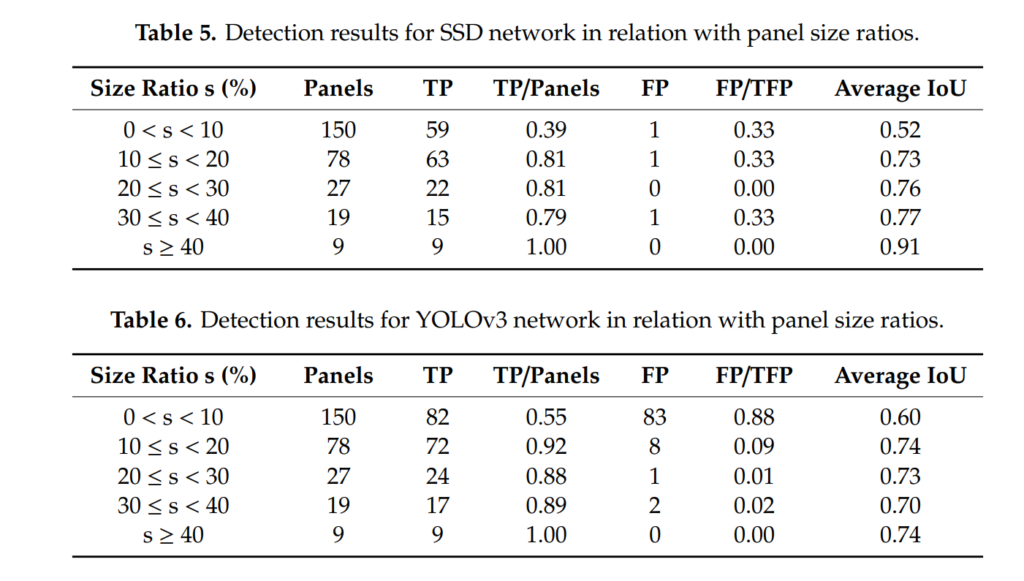
Small object에 대해서 두 알고리즘간의 차이는 어떨까요? SSD랑 YOLO중에 뭐가 더 small object를 잘 찾을까요? 위의 실험결과를 보기전에 답변할 수 있나요?
실험 결과가 말하기를 YOLO가 TP/Panels의 비율이 높고 IoU가 높은걸로 보아 small object를 찾는데 좀 더 효과적이네요. 근데 FP가 높은건 또 단점이기도 합니다.
두가지 알고리즘 모두 easy case에 대해서는 모두 찾을 정도로 어느정도 잘 워킹하는 모델이긴 한거 같습니다.
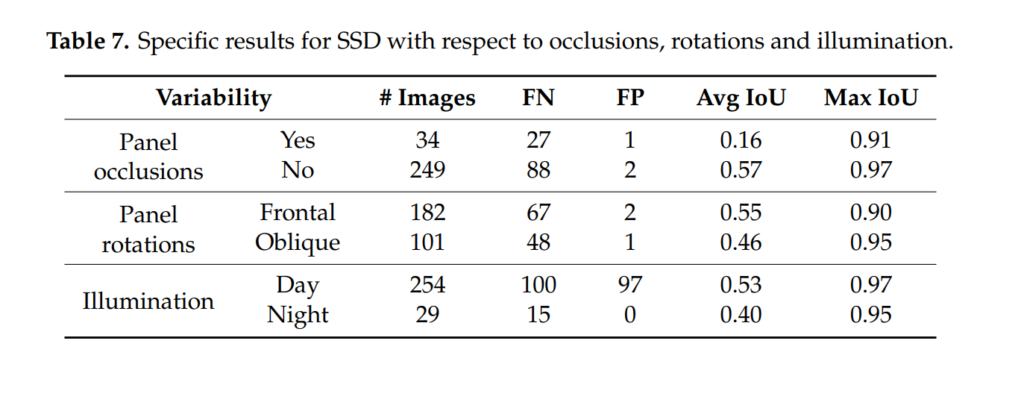
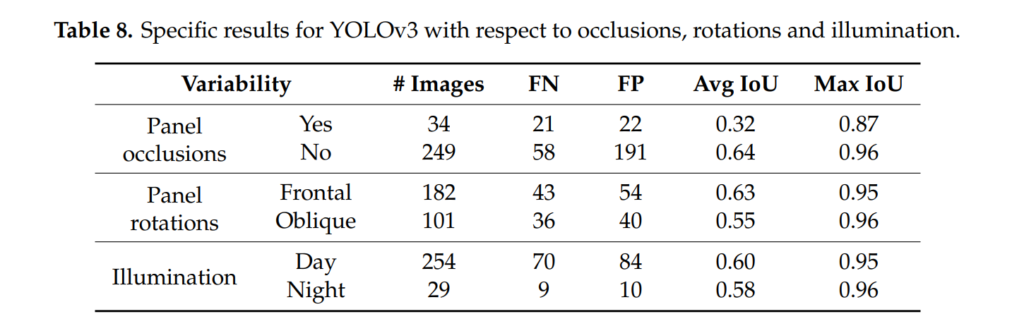
Occlusion이나 Rotation, Illumination 차이에 대한 YOLO와 SSD의 비교실험입니다. YOLO에서 FP가 높은 경향성은 동일하게 나왔네요. 그런데 좀 흥미로운 점은 IoU를 고려했을때, SSD에서는 Occlusion, Rotation, Illumination 상황 모두 Avg IoU 드랍이 YOLO대비 크게 관측이 되었습니다. 이를통해 YOLO가 좀 더 저러한 변화에 강인하다고 저자는 언급을 하는데 사실 FP 까지 고려했을때 과연 YOLO가 더 강인할까? 라는 의문이 들긴 합니다. 다만, 아예 검출을 못하는것보다는 FP가 높더라도 검출하는게 Safety 측면에서는 좀 더 논리적이므로 robutness가 중요시되는 환경에서는 YOLO를 선택하는게 맞을거 같네요.
결론
본 논문은 SSD와 YOLO를 비교하는 논문이었으며, YOLO와 SSD의 성능적인 차이를 잘 분석하였습니다. 실험결과가 흥미롭고 향후 SSD, YOLO기반 실험 설계를 할 때 도움이 될만한 논문이었습니다.
다만, 몇가지 아쉬운점은 우선, 실험을 진행한 자체취득 데이터셋이 너무 숫자가 작다는 점이 우려가 됩니다. 그리고 Miss-rate로도 같이 평가하여 리포팅했으면 좋았을거 같네요. YOLO는 FP가 높아서 Miss-rate로 평가하면 AP보다 성능 드랍이 심하게 관찰되는 현상이 있었는데, 그러한 이슈들을 논문에서 다루고, 과연 miss-rate와 AP중에 어떤 평가방식이 사용되어야 하는지에 대한 고찰을 좀 담았으면 좋았을거 같은데 아쉽습니다.
결국 평가매트릭이란게 각 사용환경에 맞게 설계가 되어야 된다고 생각하는데 miss-rate와 AP 중에 task의 특성별로 어떠한 평가매트릭을 고를 것인지에 대한 고민을 덜어주는 논문이 되었으면 좋았을텐데 말이죠. 거기에 새로운 평가매트릭까지 제안하면 금상첨화이고요.
아쉬운점이 다소 있었지만, 그럼에도 불구하고 본 논문은 평소 간지럽던 부분들을 긁어주는 느낌을 주는 괜찮은 논문인거 같습니다. 평소에 생각하고 있던 것들이 실험적으로 증명이 되었고, 앞으로 논문을 쓸때도 비슷한 내용을 언급할 때, 본 논문을 레퍼런스 걸면 되겠네요.
이상 리뷰 마치겠습니다. 질문은 댓글로 남겨주세요.
리뷰 잘 봤습니다.
내용이 상당히 흥미롭네요.
몇 가지 궁금점이 있는데, 가장 먼저 해당 논문에서는 Ad pannel에 대해서 SSD와 YOLO를 비교한 이유가 있나요? 리뷰에서도 지적해주신 대로 데이터 셋의 개수가 적다 보니 신뢰성이 조금 떨어진다고 하셨는데, SSD와 YOLO를 비교하는 것이 논문의 주요 내용이었다면 가장 대표적인 Pascal이나 COCO를 활용했어도 됐을텐데 말이죠. 논문에서 혹시 이와 관련된 이유가 명시된게 있을까요?
그리고 두 번째는 리뷰 내용 중 SSD는 좀 더 정확하게 찾고, yolo는 부정확하게 찾아도 결국에 더 많이 찾는다고 하셨는데, 만약 자율주행 상황에서는 그럼 어떤 모델이 더 좋다고 볼 수 있을까요? 제가 생각했을 땐 검출량은 적지만 그나마 더 정확하게 찾는 SSD가 더 좋지 않을까 하는데 YOLO처럼 일단 많이 찾아놓고 후처리과정에서 해결하는 방법도 있을까요?
1. AD Panel에 대해서 하는건 제 생각엔 과제와 연관을 시키지 않았을까요? 혹은 ssd vs yolo로만은 contribution이 부족하니 아직 미개척 분야에서 데이터셋도 찍고 해봤다 정도로 이해해도 될거같네요. 진실은 저자만이 알겠지요. 근데 제 생각엔 ssd vs yolo 말고 다른 부분은 굳이… 왜 싶은 내용이 많네요. (별로 유익한 내용이 아닌거같아 x-review에서는 다루지 않았습니다.)
2. 그건 논문의 저자마다 다른거 같아요. 어떤 논문에서는 accumulated recall을 중요시하고, 어디선 miss-rate를 중요시하고… 등등. 둘다 중요하지만 제 개인적인 생각으론 SSD가 더 낫다고 생각이되네요. 테슬라 차가 FP 때문에 사고가 발생한적이 있는거 처럼 FP를 많이 만들면서 TP를 높이는건 올바른 접근이란 생각이 안들어서요.
적외선센서, 초음파 센서 같이 장애물 인지 센서로 부터 얻은 신호, 라이다센서로 부터 얻은 정보를 모두 고려해서 사고 위험여부를 판단하는 방법도 고려해볼 수 있겟죠. 다만 자율주행은 실시간성이 보장되야 하므로 후처리과정에서 처리하는건 좀 한계가 있지 않을까 싶은게 개인적인 의견입니다.
왜 패널 탐지가 필요한지 원문을 보고왔는데 ㅎㅎ… 뭔가 좀 부족한 느낌이네요. 윗 댓글에서처럼 과제 막기용으로 보이네요. 목적에 대해서 좀 궁금한 부분이 있습니다. 운전자와 보행자 관점에서 패널 탐지의 필요성에 대해서 이야기를 하는데요. 데이터셋에서 보행자 관점과 운전자 관점의 데이터셋 비율 차이도 명확하게 언급되어 있나요? 예시를 보면 두 상황에서 발생하는 occlusion이나 잘 보이는 정도 차이가 발생해 보이는데 분석이 있는지 궁금합니다. 추가적으로 “Small object에 대해서 두 알고리즘간의 차이는 어떨까요? SSD랑 YOLO중에 뭐가 더 small object를 잘 찾을까요?”이 질문에 대해서 형준 연구원님의 의견도 궁금합니다.
왜 패널탐지가 필요한지에 대한 설명이 부족한건 공감하지만, 사실 제가 논문을 읽을때 관심분야가 아니라 크게 게의치 않았습니다. 데이터셋의 비율은 명시된건 없는걸로 기억합니다. 사실 데이터셋 크기가 300개정도? 인걸로 기억하는데 그 작은 데이터셋을 나누는게 큰 의미가 있을까 싶네요. occlusion이나 small object에 대한 분석내용은 본 논문 및 리뷰에서 다루고있는데.. 놓치신듯 합니다. 제 의견을 물으신거라면 저도 저자랑 해당부분에서는 같은생각입니다.
안녕하세요. 이전 글이지만 다음 주 부터 Yolo를 실습하는 과정에서 이미 알고 있는 SSD와의 비교 글이 흥미로워보여 읽게 되었습니다. 자체 데이터셋인 AD Panel 데이터셋을 활용한 모습이 흥미롭긴 했지만 말씀하신 것과 같이 그 수가 절대적으로 적은 것이 많이 아쉽습니다. 심지어 특정 상황에서 데이터 셋이 많이 차이나는데, 데이터셋을 다음과 같이 한 상황 (occlusion, illumination 등)에서의 두 레이블의 데이터 셋을 차이나게 둔 것은 특정한 이유가 있을까요?
또한 논문에서의 실험 결과를 보면 어쩌면 SSD와 그나마 비슷하게끔 설정되어 있는 Yolo v3에서 TP, FP 등을 비교하는 글을 쓴 것으로 보이는데, 해당 결과가 어찌보면 두 모델의 특성을 그대로 보여주고 있을 뿐 새로이 던지는 메시지가 없다고(논문에서 말하고자 하는 바를 명확히 모르겠다) 해석되는데, 그렇다면 연구원님 개인적으로 봤을 때는 두 모델의 차이를 명확히 보여주기 위해서는 결국 AP가 함께 있는 것이 좋다고 보시나요?
약 2-3달 전의 글이지만 좋은 리뷰 감사합니다!