monocular depth estimation을 계속 연구하면서 요즘 드는 생각은 Self-supervised 와 supervised 가 그렇게 큰 차이가 있지 않다는 것입니다. 물론 supervised 가 성능이 조금 더 좋긴하지만 생각만큼 큰 차이를 보이지는 않습니다. 다만 supervised의 경우 좀 더 다양한 augmentation을 적용할 수 있기 때문에 overfitting의 관점에서 더욱 큰 성능 향상을 보여줍니다.
이러한 문제 때문에 다양한 연구에서 Supervised 와 self-supervised를 상호보완적인 관계로 두고 더욱 높은 성능 향상을 이룰 수 있도록 semi-supervised로 다루고 있습니다. 하지만 이러한 연구들은 두 학습 방식의 한계를 서로 상속하며 서로의 오류를 누적하는 결과를 보여줍니다.
이러한 기존 semi-supervised learning의 단점을 해결하는 것이 리뷰드리는 논문의 key contribution 입니다.
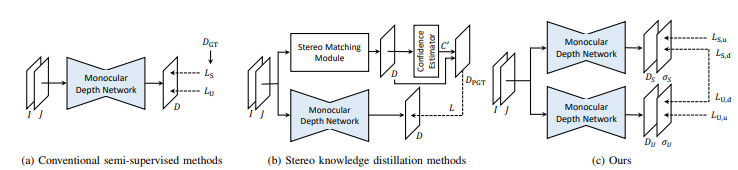
기존에는 (a) 와 (b) 같이 loss function이 한 모델에 동일하게 들어가거나 하나의 output이 다른 모델에 직접적으로 영향을 끼치는 구조였다면 제안하는 논문은 그렇지 않습니다. (1) 각 학습 방식을 위한 모델을 분리하고 각각 depth 와 confidence map을 추정합니다. 그리고 각각이 서로의 GT가 되는 방식으로 학습이 진행됩니다. (2) 이때 supervised 는 sparse 한 영역 학습하니 dense 한 영역을 볼 수 있도록 point fitering loss를 제안합니다. 그리고 (3) augmentation을 따로 적용해서 더욱 학습 성능을 올렸습니다. 이렇게 제안된 방식들로 supervised 와 self-supervised 모두 높은 성능 향상을 보여줬습니다.
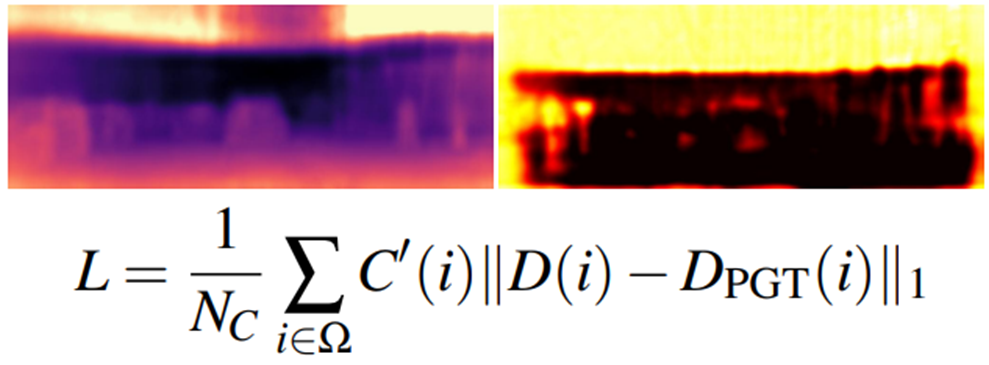
제안된 방법론을 설명하기 앞서 confidence map을 알아야합니다. 뭐 사실 다양한 분야에서 사용되고 있는 것인데 요기서도 동일하게 사용됩니다. depth 가 유효한 것 같은 부분을 예측하고 유효하지 않을 것 같은 부분은 학습하지 않는 것입니다. 식에선 C’ 이라고 생각하시면됩니다. 위 식은 간단하게 표현 한 것이고 아래 식이 confidence map을 학습합니다.
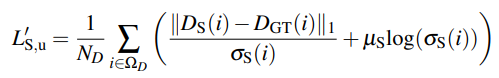
여기 식에서 log 가 있어서 무슨 소린가했는데, 그냥 log 가 아니고 maximum log likehood를 계산한다고 합니다. 따라서 특정 분포를 따르도록 학습이 되며 옆에 항을 통해서 confidence map이 작으면 loss 를 키우고 confidence map이 1에 가까울 수 록 loss는 작아지는 식으로 해서 학습이 되어야할 부분을 강조하는 것이라고 보면 됩니다.
이 방식을 통해서 그림 1 (b) 와 같은 방식을 띄는 방법론에서 부정확한 Pseudo-Label을 student model 이 학습하지 못하도록 합니다. 하지만 속도나 cost volume 의 오작동 등의 문제로 성능 향상에는 한계가 있었습니다.
intro 에서 설명한 문제와 위에서 언급한 문제를 해결하기 위해 제안된 것이 아래와 같은 framework 입니다.
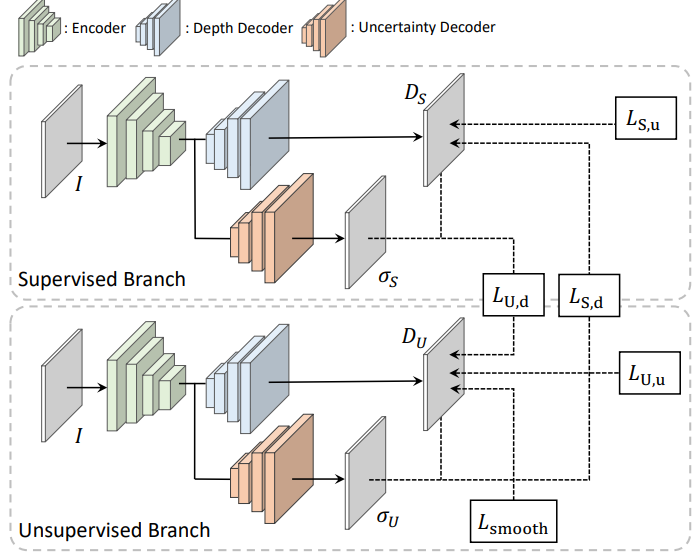
위 그림을 통해서 이 framework 가 어떻게 동작하는 지 알 수 있습니다.
각각 Supervised 와 self-supervised로 학습되며 Lu,d 와 Ls,d 를 통해서 서로 보완하고 있다 생각하시면 됩니다.
그럼 각 loss term에 대해서 봅시다. 먼저 supervised의 식을 보면 다음과 같습니다.
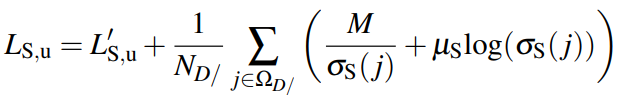
L’su는 저 위해서 보여드린 식과 같고 옆에 항은 supervised 니까 sparse 한 영역외에 confidence map을 어떻게 처리하느냐에 관해 제안한 부분입니다. D/ 은 lidar 가 없는 pixel을 뜻합니다. depth 정보가 없는 영역 도 동일하게 confidence map을 생성하며 저기서 M은 하이퍼 파라미터이며 이를 통해서 괜찮은 성능을 보여준다고 하며 효과를 아래와 같이 볼 수 있습니다.

(d)는 filtering 이 적용 안된 것이고 (f)는 적용된 것인데 확실히 sparse 한 영역 외에 전체에 유사한 confidence map이 생성된 것을 볼 수 있습니다.
다음은 self-super의 loss 입니다.
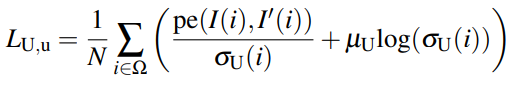
pe는 appearance matching loss라고 보시면 됩니다.
Distillation of Depth with Uncertainty
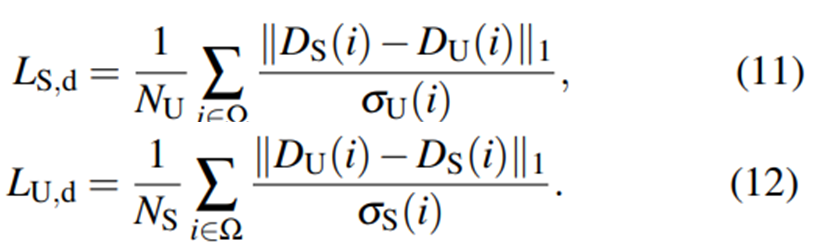
각 모델의 성능을 넘기기 위해서 위와 같은 식을 사용했습니다. 굉장히 간단하죠, 각 네트워크에서 제안된 confidence map을 cross로 이용해서 각 네트워크의 특징을 넘겨줍니다.
Results
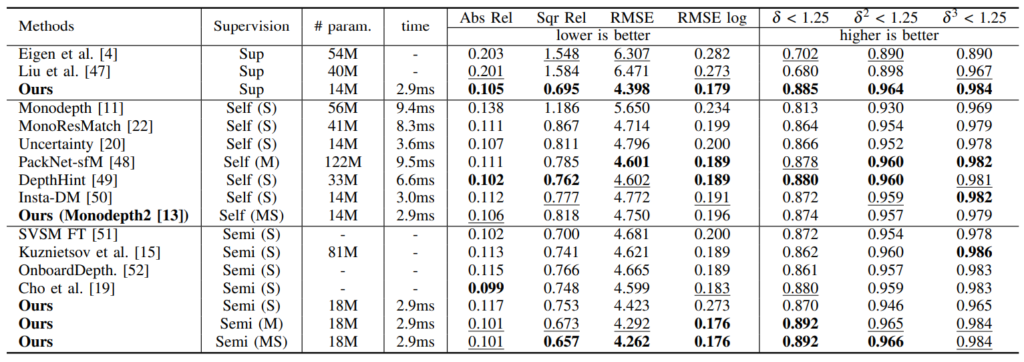
KITTI에서 높은 성능을 볼 수 있습니다. 확실히 Supervised 의 성능과 self-supervised의 성능 차이가 얼마 안나는 것을 볼 수 있으며 Semi로 됐을때 매우 높은 성능 향상이 된 것을 볼 수 있습니다. 근데 요기서 의하한게 Stereo 로 학습한 것이 성능이 매우 낮은게 의아합니다. 신기한 부분인 것 같아서 이것에 대한 내용이 없나 봤는데 없어서 … 흠 … 신기한 것 같고 MS는 오히려 M 보다 높은 것 또한 … 신기한 것 같습니다.
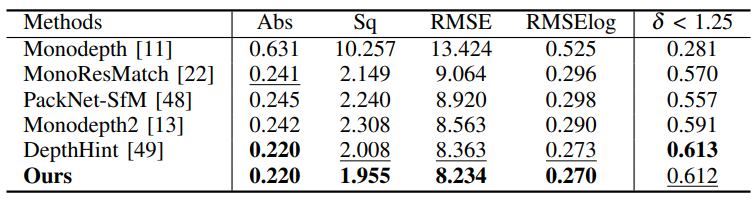
Cityscape 에서 성능 평가 입니다. 높은 성능을 볼 수 있습니다. 근데….음 ..왜 Supervised 방법론들과는 비교 안했는지 .. 참 … 그건 쫌 그렇네요
ablation study 입니다.
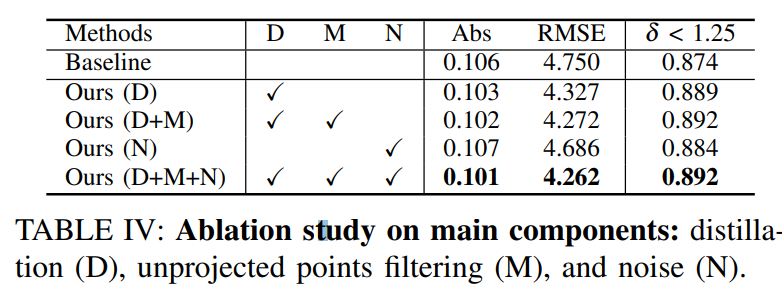
각 방법론에 대해 성능이 올라 간 것을 볼 수 있습니다. filtering 이 성능향상이 클줄 알았는데 그렇지 않은게의외였습니다.
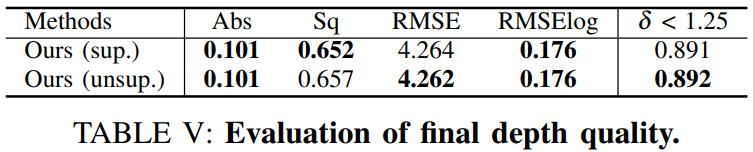
마지막으로 superivsed 네트워크와 self 네트워크 각각의 성능입니다. 보면 각각이 성능이 올라간 것을 볼 수 있습니다.
리뷰 잘 봤습니다.
초반부에서 augmentation을 따로 적용해서 성능 향상을 시켰다고 나와 있었는데,
supervised 방식의 depth estimation 방법론에서 적용하는 augmentation에는 어떠한 것들이 있나요???