해당 리뷰를 읽으면 도움이 될 분들?
해당 리뷰는 나온지 몇주 되지않은 최신 yolov7에 대한 리뷰글 입니다. 욜로1~3 시리즈에 대한 이해도가 없으면 본 리뷰를 읽어도 이해하기 힘들 수 있습니다. 그리고 yolov4 논문을 아직 읽어보지 않으신분들은 개인적으로 v7을 읽는것은 추천드리지 않습니다. 개인적으로 v4를 읽었을때의 “대단하다” 라는 느낌이 욜로7에서는 별로 없네요… yolov1~v3와 yolov4에 대해서는 제가 x-review를 작성한적 있으니 참고해보세요.
욜로 시리즈에 대한 간략한 소개
다들 아시다시피 욜로는 조셉 레드먼 이라는 원저자가 1~3 버전을 개발하였고, 이후의 버전들은 다른저자들에 의한 variant들 입니다. v1~4까지는 C기반으로 작성되었는데 처음으로 오피셜하게 나온 python 코드가 v5 입니다. v5이후 yolo-r , yolo-x 등이 나왔었는데, yolov6가 나오기까지는 한참의 시간이 걸렸네요. 근데, 이상하게도 yolov6하고 yolov7하고 나온 간격이 1~2주 정도밖에 차이가 나지 않습니다. yolo버전을 관리하는 사람이 한사람이 아니라 발생한 문제같네요. 페이스북에 Computer Vision이라는 커뮤니티에서도 버저닝 관련으로 누군가 이슈라이징 하였었는데 이후 욜로버전들의 버전은 어떤식으로 관리될지 모르겠네요. 6는 건너뛰고 7을 리뷰하게된 이유는 yolov6에 비해 v7이 훨씬 퀄리티 높고 저자들중에 이전 욜로시리즈에 참여한 저자들이 3명정도 포함되어있다고 알고 있습니다. 그래서 yolov7에 흥미가 생겨서 리뷰하게되었습니다. 일단 yolov7도 오피셜 코드가 파이썬이란점이 맘에 드네요.
본격적인 논문 리뷰에 앞선 후기
논문 후기를 먼저 작성하는 이유는 후기를 읽고 나서 제 리뷰를 읽고싶지 않은 분들이 있을거 같아서 그러한 분들을 위한 배려입니다. 쇼핑을 할때도 후기를 먼저 보듯이 짧게나마 논문에 대한 논평을 적어두면 여러분들의 소중한 시간을 낭비하지 않을수도 있으니까요. 결과론적으로 해당 논문은 v4와 컨셉이 비슷합니다. 추론타임을 증가시키기 않지만, 성능에 영향을 주는 bag-of-freebies를 정의하고 그에대한 실험을 하는 그런 형식입니다. yolov4를 읽어보신분들은 이러한 컨셉이 익숙하리라 생각됩니다. 그러나, 실험의 다양성이 v4에 비하면 많이 떨어지는게 사실입니다. 논문자체는 훌륭하지만, 과연 욜로라는 main stream 알고리즘의 버전을 다르게 새길만큼의 컨트리뷰젼이 있는지는 의문입니다. 따라서, 최신 욜로알고리즘을 베이스로 모델을 설계하고 싶으신 분들은 읽어보면 좋을거 같으나, 학습을 위한 목적으로는 v7이 별로일 수 있습니다.
논문 리뷰
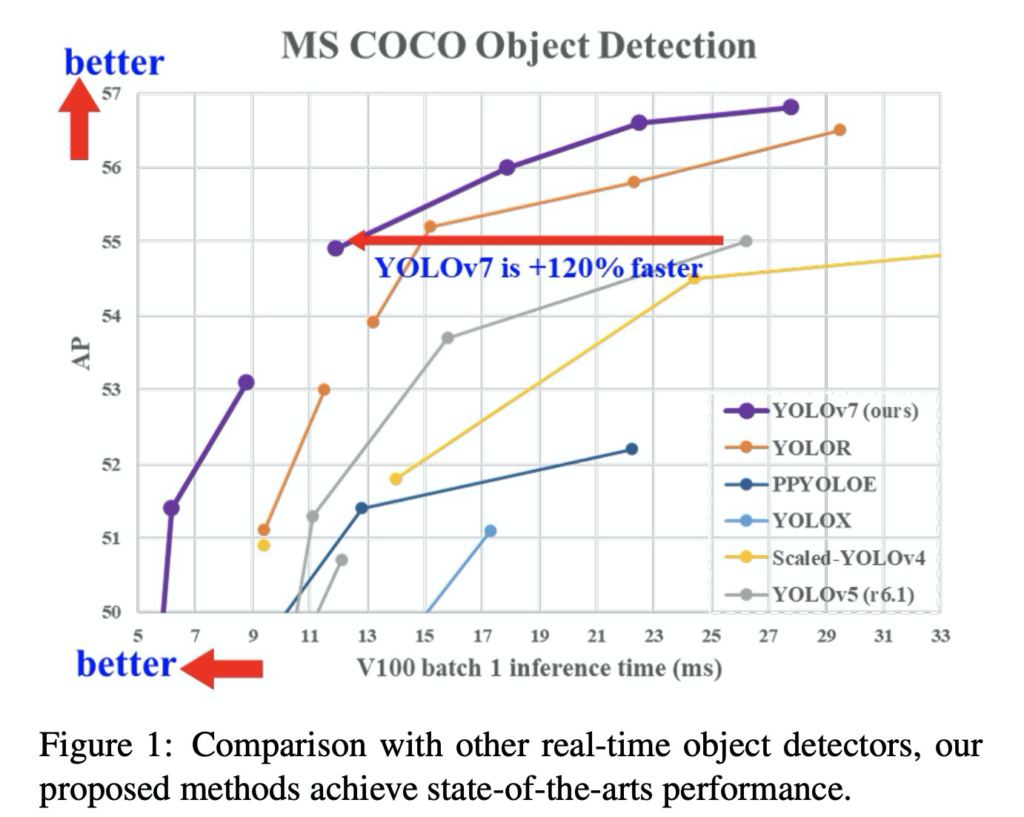
해당 논문의 가장 큰 contribution은 성능과 속도 모두 코코데이터셋 기준으로 기존 욜로알고리즘을 뛰어넘었단 것 입니다. 사실상 이러한 성능을 도출한 방법은 기존에 이미 사용하던 방법들을 조금만 변경하여 사용하였습니다. 그 방법들이 다소 낯설수 있습니다. 저 또한 생소한 방법론들이 많아서 참고자료들을 많이 읽어보았는데, 제가 참고했던 자료들을 같이 소개하며 설명드리겠습니다. 참고자료들을 읽어보지 않고 본 리뷰에서 다루는 내용만으로 v7을 이해하기에는 조금 버거울 수 있습니다. v7을 이해하려면 배경지식이 많이 필요한거 같습니다. 모든 배경지식을 본 리뷰에서 다루는건 좀 무리라고 생각되서 참고자료로 대체한점 양해 부탁드립니다.
먼저, 욜로v7에서 핵심이 되는 contribution은 아래와같이 정리됩니다.
- training에 도움이되지만, inference시에 속도에 영향을 안미치는 요소들을 bag-of-freebies라고 정의하고, 다양한 bag-of-freebies 적용실험을 통해 기존 욜로의 성능 및 속도를 개선하였다. (v4에서의 컨셉과 동일합니다.)
- re-parameterized module / dynamic assignment strategy를 욜로에 맞게 적용합니다.
- 다양한 스케일링 기법을 적용한 compound scaling을 욜로에 맞게 적용합니다.
- 기존 욜로 버전들 보다 더 높은 성능과 더 빠른 추론 속도를 달성합니다.
그럼 각 contribution 별로 하나씩 설명드리겠습니다.
1. Extended efficient layer aggregation networks
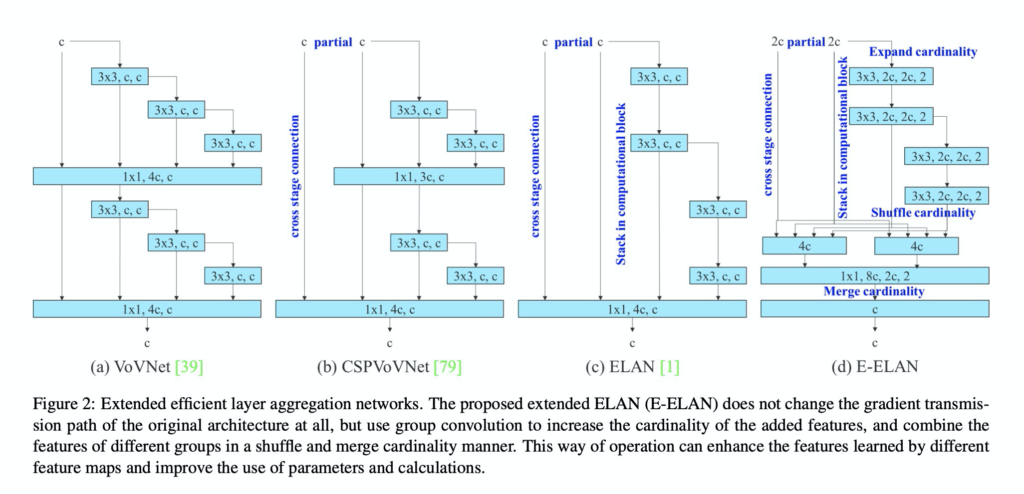
먼저 첫째로 욜로v7에서는 위의 그림과같이 aggregation layer를 사용합니다. ELAN이라는 기존의 방법론에서 아래부분에 cardinality만 shuffle해서 섞어준다음 merge해주는 방법으로 aggregation 해주었습니다. 해당 방식에서는 gradient transmission path를 바꾸지 않고, 아래에 소수의 group convolution 만을 사용하기 때문에, cardinality를 증가시킨다고 합니다. (cardinality라는 용어가 익숙치 않았는데, 쉽게 이야기하면 중복도를 낮춘다는 말을 좀 어렵게 표현한거 같네요.)
위에 일단 논문 표현대로 설명드렸는데, 쉽게 이야기하자면 그냥 기존 ELAN에서 aggregation 하는 방식에서 아래에 convolution 모듈들과 shuffling 을 추가하여 새로운 E-ELAN을 설계했다고 생각하시면 됩니다.
2. Model scaling for concatenation based models
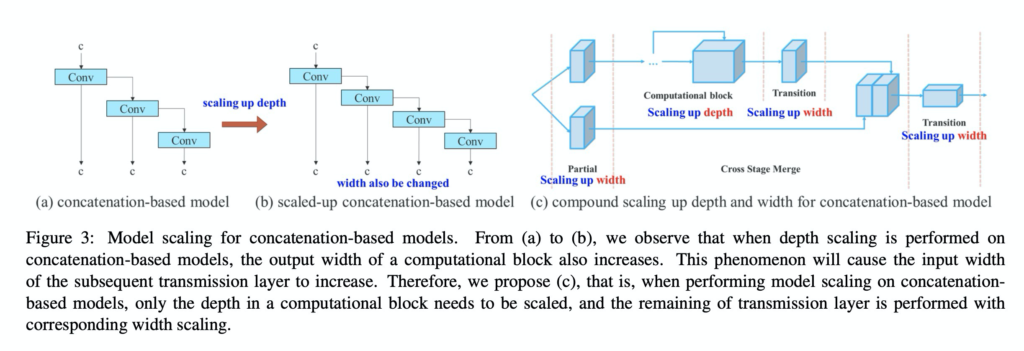
욜로 v7에서는 위의 그림 (c)와 같이 다양한 model scaling 기법을 혼용하여 사용합니다. 저는 개인적으로 해당 부분을 보고 이해가 안가서 구글링해서 참고자료(그림)을 보고 이해하였습니다.
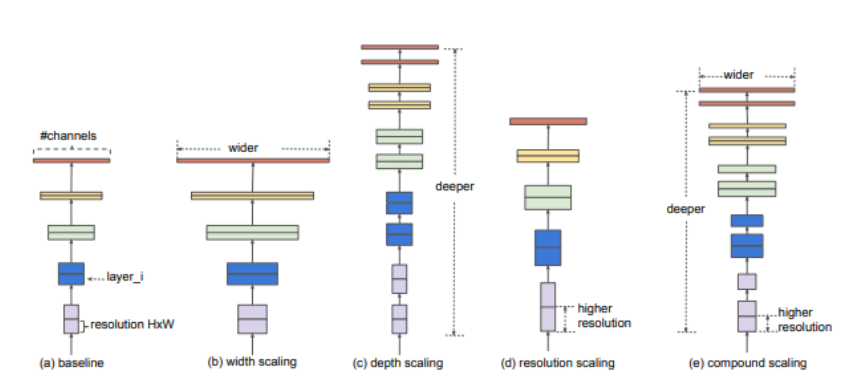
위의 그림에는 스케일링의 종류에 대해서 잘 표현되어 있습니다. depth, resolution, width의 scaling을 적절히 섞은 compound scaling (위 그림 e)이 yolov7에서 사용한 스케일링과 유사합니다.
그림3의 (c)와 바로위의 그림 (e)를 비교해가면서 보시면 이해에 좀 더 도움이 될거라 생각합니다.
3. re-parameterization
먼저 (RepVGG) 를 참고하시고, RepVGG를 이해해보시면 이해하는데 도움이 될거라 생각합니다. RepVGG에서는 아래 그림과 같이 vgg의 기존 아키텍쳐를 resnet에서 사용하는 residual block과 비슷하게 변형하여 사용합니다. 그런데 이때, residual block이 단순히 identity layer만 있는것이 아니라 아래그림처럼 1×1 커널을 이용하여 구한 피쳐맵도 같이 사용합니다. 그러나 1×1 과 identity 레이어를 이용한 residual layer는 3×3 커널을 사용하는것보다 속도면에서 효율적이지 않다고 주장하며, 아래 그림과같이 변경하여 사용합니다.
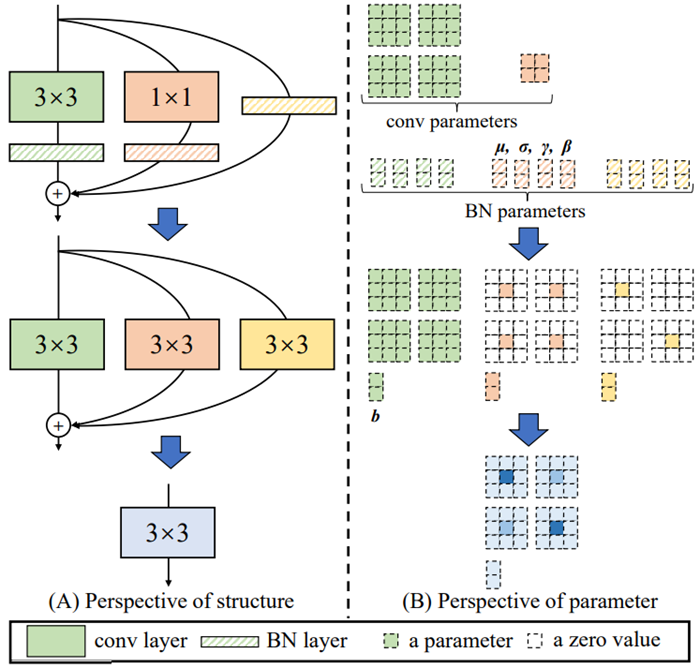
즉, 3×3 커널을 사용하여 기존 1×1 과 identity layer 같은 효과를 보이도록 모듈을 설계하였으며, nvidia gpu 에서 3×3 커널이 가장 속도측면에서 효율이 좋은점을 이용하기 위함이라고 합니다. 그리고 이렇게 설계한 residual layer들은 학습에만 사용하고, 추론에는 사용하지 않는다고 합니다. 이렇게 학습에서 추가적인 레이어를 사용하고 추론에는 사용하지 않는 방법은 re-parameterization 기법으로 가능하다고 합니다. 개인적으로 익숙하지 않은 개념이라 저도 구글링을 해보았는데 RepVGG에서 가장 잘 설명하고 있습니다.
욜로 v7에서는 이러한 RepVGG를 변형하여 사용합니다. 다만, RepVGG를 그대로 사용하지않고 아래처럼 변경하여 사용합니다.
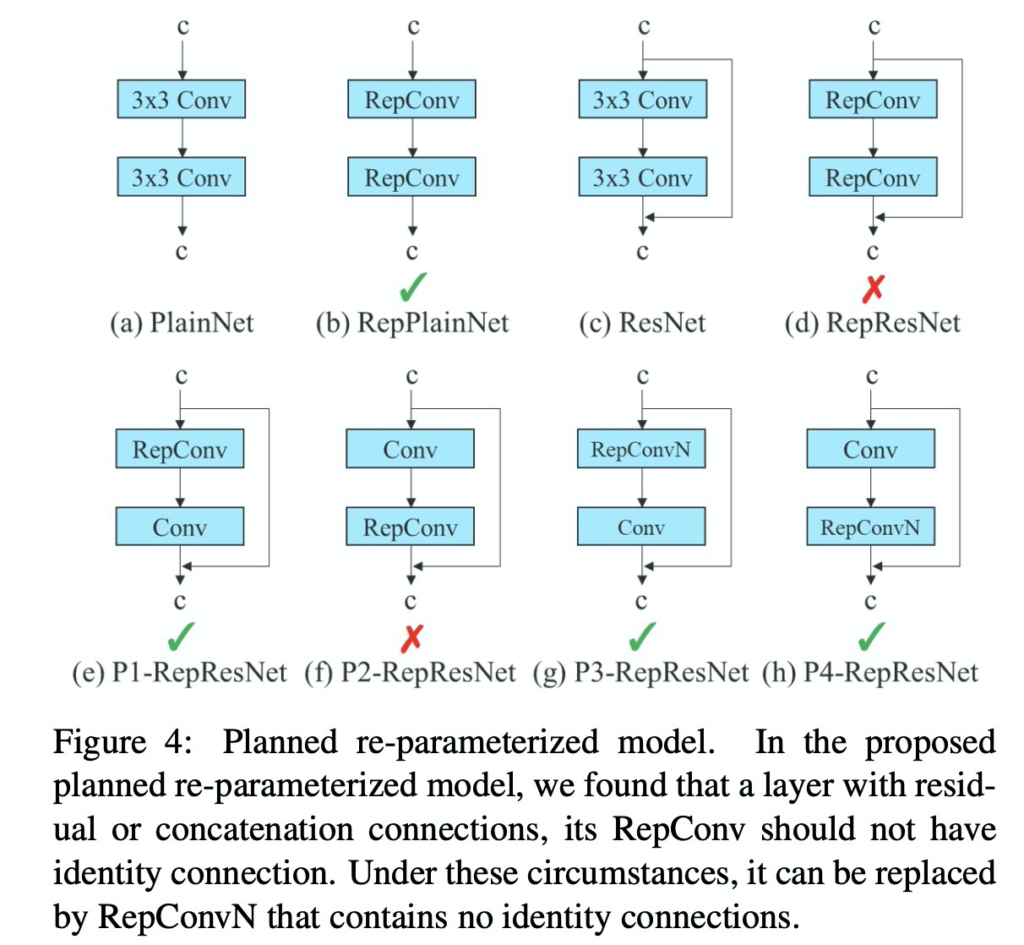
그리고 이유를 아래와 같이 설명합니다.
RepConv actually combines 3 × 3 convolution, 1 × 1 convolution, and identity connection in one convolutional
layer. After analyzing the combination and corresponding performance of RepConv and different architectures,
we find that the identity connection in RepConv destroys the residual in ResNet and the concatenation in DenseNet,
which provides more diversity of gradients for different feature maps. For the above reasons, we use RepConv without identity connection (RepConvN) to design the architecture of planned re-parameterized convolution.
요약하자면 residual connection이 residual 정보와 DenseNet에서의 concatenation 정보의 소실을 가져온다고 하네요. residual에 대해서는 직관적으로 이해가 될거 같은데, DenseNet에서의 concatenation에 대해서는 제가 yolov4를 리뷰할때, CSPNet을 설명하면서 잠깐 언급하였었는데 해당 리뷰를 참고하시면 도움이 될듯하네요. (v7 자체가 굉장히 논문이 이해하기 쉽게 작성되어있으나, 중간중간 생략된 내용들이 많네요. 어느정도 욜로에 대한 배경지식이 있다는 전제로 글을 쓴듯 합니다.)
어찌됐든, 핵심적인 내용은 residual connection을 없이 ResConv과 re-param 기법을 사용하였다고 합니다.
4. Label assignment
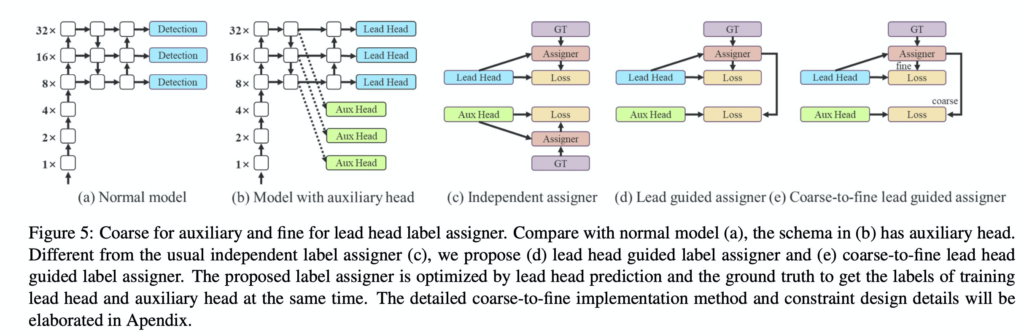
다음으로 소개해드릴 부분은 욜로v7에서 사용한 label assignment 방법입니다. 과거에는 GT label로 hard label을 사용하는게 당연하게 받아들여지던 시대가 있었습니다. 그러나 최근에는 GT label로 soft label을 사용하는 방법들이 많이 등장했습니다. 예를들어 욜로에서는 bbox의 confidence score에 iou를 곱해서 사용합니다. 즉, box이면 1 아니면 0으로 GT라벨을 부여하는게 아니라. GT box와의 오버랩된 정도를 곱해서 0~1 사이의 소수로 표현하는 것 입니다. 이러한 soft labeling 방식은 아무래도 학습에 더 도움이 되었습니다. v7에서는 이러한 개념을 detection head 에 적용합니다. 위의 그림에서 labeling 하는 모듈을 label assigner라고 표현하였습니다. v7에서는 구체적으로 Lead Head와 Aux Head 에 어떤식으로 labeling을 할지에 대하여 이야기합니다. 결론적으로 (e) 처럼 Lead head로 부터 구한 prediction을 이용하여 Aux head 에도 guide를 해주었다고 합니다.
평가
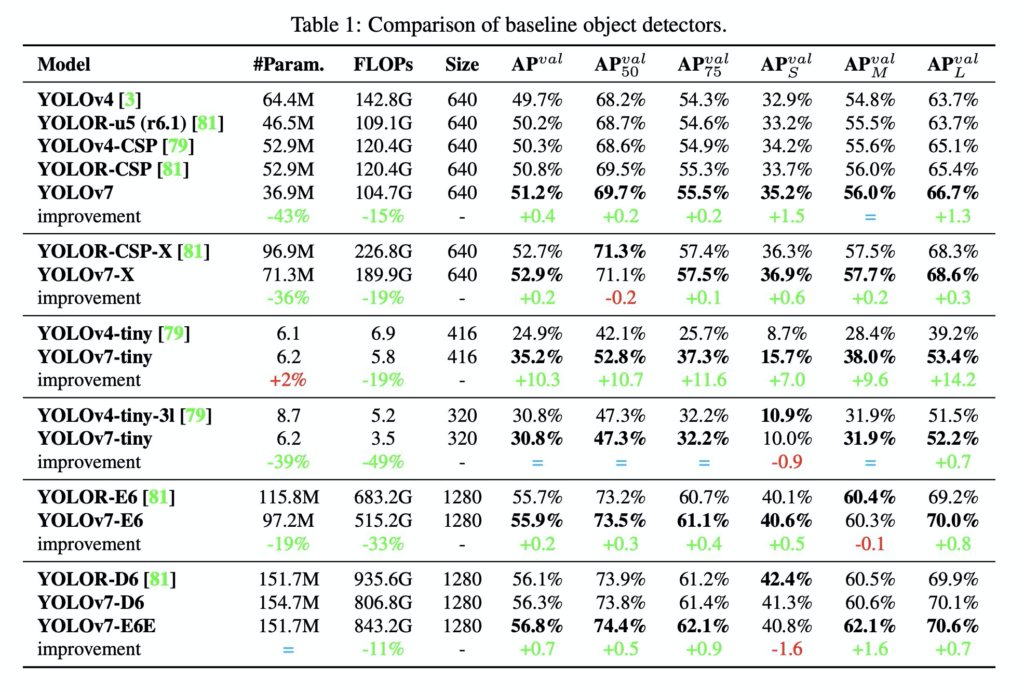
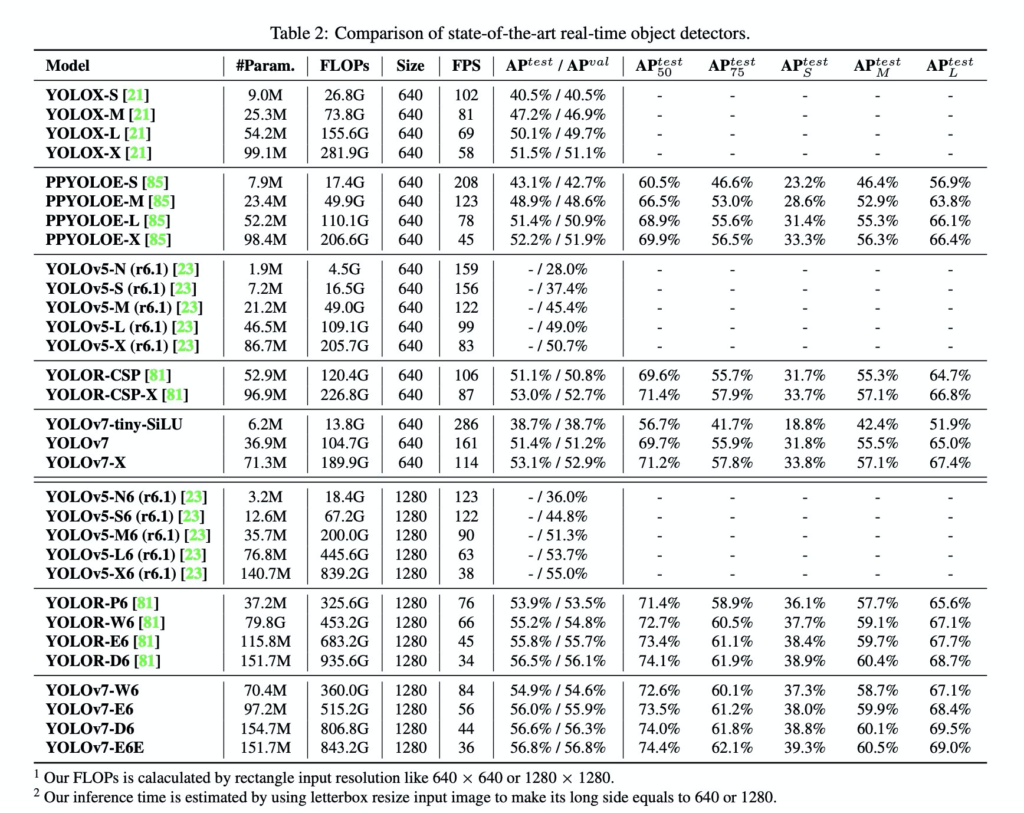
결과론적으로 v7은 추론속도와 accuracy의 trade-off관계를 고려했을 때, 기존 욜로모델들을 높은 성능차이로 이겼습니다. 확실히 실험결과가 유의미해보이네요. 개인적으로 뭔가 참신하다는 느낌은 못받았지만, 성능측면에서는 엄청난 발전인거 같습니다. 기대가 너무 큰 상태로 읽은 논문이라 조금 아쉽지만 성능과 가독성 측면에서는 좋은논문인거 같네요. 기존에 팔로우업 못한 최신 object detection에서 사용되는 트렌디한 기술들을 많이 접한거 같습니다. (v4볼때만큼은 아니지만 어느정도 만족 합니다.)
이상 리뷰를 읽어주셔서 감사합니다. 질문은 댓글로 달아주세요.
뭔가 새로운 단어도 많이 나오고 정보들이 많이 등장하네요. GPU가 3×3에서 빠르다거나… 용어들이 특히나 엄청 새롭네요. 먼저, Label assignment에 대해서 질문이 있는데요. 처음 보는거라 검색을 조금 해봤더니 일반적으로는 소프트 라벨을 기존 라벨을 아예 대체해서 사용하는 것으로 처음엔 이해했는데요. 다만 그림 5-e를 보면 Lead Head와 Aux Head가 등장하면서 fine/coarse를 Assigner가 할당하는 것을 볼 수 있습니다. 그러면 여기서 이 fine/coarse를 하드 라벨 / 소프트 라벨로 각각 이해하면 될까요? 그리고 이전 버전들을 봐도 lead head와 aux head에 대한 설명이 등장하지 않는데 각각 무엇인지 궁금합니다.