

오늘 리뷰할 논문은 Feature Fusion에 관해 다룬 논문입니다. 현재 iMAC이라는 fused feature를 통해 실험하고 있는데, 해당 feature를 다루는 데에 있어 어떻게하면 더 나은 성능을 보일 수 있을까하며 검색하다가 해당 논문을 발견하고 리뷰하게 되었습니다.
1. Motivation
제가 실험에 활용하는 iMAC이라는 fused feature는 Backbone network 내 중간 레이어들에서 얻은 activation map에 R-MAC 기법을 적용하고 concat되는 것으로 기술됩니다. 이런 식으로 여러 레이어 간의 feature fusion 방식도 많이 사용되고 있으나, 실제로 단일 레이어 내에서의 fusion도 많이 사용되곤 합니다. 예를 들어, ResNet의 각 block 안에서는 residual 연산된 feature와 입력 feature 사이의 fusion이 진행 되며, InceptionNet에서는 입력 feature에 대해 서로 다른 크기 커널로 convolution 연산을 한 feature 사이의 fusion이 진행 됩니다.
이렇게 다양한 방식으로 fusion이 진행되지만, ResNet에서는 sum, InceptionNet에서는 concat 방식으로 linear하게 fusion하듯이, nonlinear한 fusion 연산에 대한 연구는 많지 않았습니다. 또한, 그나마 nonlinear한 fusion 연산에 대해 다뤘던 연구인 Selective Kernel Networks (SKNet)과 ResNeSt는 “같은 레이어 내 fusion” 및 “global channel attention 기반” 이라는 특징을 가지고 있었고, 저자는 이러한 특징에 대해 세 가지 문제를 지적하였습니다.
첫번째 문제는 해당 연구들은 같은 레이어 내만을 고려하고 있기에, 흔히 맞닥드리는 cross-layer 간의 feature fusion 문제를 해결하지 못했다는 것입니다. 두번째 문제로는 어떤 feature를 fusion하는 과정은 특정 feature들을 직접적으로 fusion 하기 전 처리 과정을 의미하는 initial integration module과 이를 입력으로 받아 attention을 주는 attention module로 구성되는데, 해당 연구들에서는 initial intergration이 이후 attention quality에 크게 기여함에도 불구하고 addition과 같은 간단한 연산으로 설계되었다는 것입니다. 마지막으로 세번째 문제로는, 해당 연구들이 global context만 고려하기에 local context를 놓쳤다는 점입니다.
이렇게 지적된 문제들에 대한 해결책으로 본 논문의 저자들은 Multi-Scale Channel Attention Module (MS-CAM) 이라는 모듈과 Attentional Feature Fusion (AFF) 방식을 제안하였습니다.
2. Method
2.1 Multi-scale Channel Attention
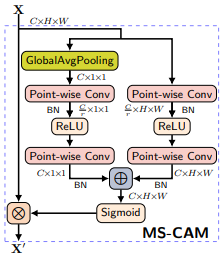
앞서 지적된 연구들 이외에도 global context만을 다루는 방법 중 SENet이라는 방법론의 경우, 입력 feature에 global attention을 주기 위해 식 (1)과 같은 weight를 생성하였다고합니다.
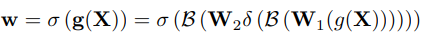
식 (1)에서 X는 (C,H,W) 크기의 intermediate feature이고, g(*)는 GAP, B(*)는 batch normalization, \delta(*)는 ReLU, \sigma(*)는 sigmoid를 의미합니다. 또한 W1은 channel 크기를 줄여주는 FC Layer, W2는 channel 크기를 원래대로 돌려주는 FC Layer 입니다. 여기서, 입력 feature X의 (H,W)가 GAP 연산을 통해 1로 바뀌며, 이는 이미지 내의 small object의 signal을 제거하고 large object의 signal 만을 남기게 됩니다.
이와 같이 feature fusion의 두번째 과정인 attention module에서 global context에만 bias되는 것을 막기 위해 식 (2)와 같이 local context를 계산하는 과정을 거쳤습니다.
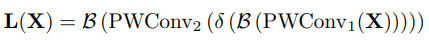
입력 feature X에 대해 point-wise convolution(1×1 convolution)이 적용되며, 첫번째 적용시에는 위와 마찬가지로 channel을 줄이고 두번재 적용시에는 channel을 되돌리게 됩니다. 실제로 식 (1)에서 global context weight를 계산 시에 사용된 W1과 W2의 경우도, 입력으로 GAP연산을 한 (즉, HxW가 1×1 크기인) feature map을 받았기에 point-wise convolution을 했다고 볼 수 있지만, 식 (2)에서의 다른 점은 feature의 spatial area인 HxW의 각 point 마다 연산이 되어 local context에 초점을 맞췄다는 부분입니다.
이렇게 연산된 local context weight는 앞선 global context weight와 식 (3)에서와 Fig 2에서처럼 sum 연산 이후 sigmoid를 거쳐 weight를 주게 됩니다. 참고로 local context weight는 각 point마다 계산되어 CxHxW 크기이기때문에 C 크기인 global context weight에 맞춰 더해지기 위해 broadcasting sum 연산되었다고 합니다. (C 크기의 값을 CxHxW로 중복시켜 합 연산이라 생각하시면 됩니다.)
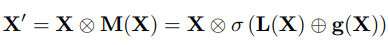
2.2 Attentional Feature Fusion
앞선 MS-CAM 방식의 attention module을 실제 feature fusion 시나리오에 적용했을 경우 식 (4)와 같이 나타내지게 됩니다.
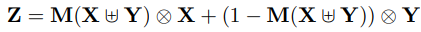
식 (4)에서 X와 Y는 fusion될 feature들이며, Y의 경우 더 큰 receptive field를 가지고 있는 high-level feature를 의미합니다. 또한 \uplus 기호는 fusion의 첫 과정인 initial integration을 의미하며 여기에 정의되는 방식에 따라 두 가지 variance를 가지게 됩니다.
먼저, initial integration을 linear 연산인 sum으로 넣은 경우 Fig 3의 왼쪽에서 나타나듯 Attentional Feature Fusion (AFF) 방식을 존재합니다. Sum 연산이 적용되어 하나의 feature로 바뀐 X, Y에 대해 MS-CAM을 통해 weight를 계산하고, 그 값과 (1-weight)값이 각각 X와 Y에 가중치를 주고 sum되는 구조로 feature fusion이 진행됩니다.
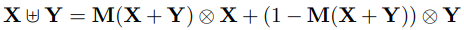
두번째로는 식 (5)와 같이 initial integration 방식을 AFF 방식으로두고 그것을 기준으로 한번더 AFF 방식을 통해 fusion하는 iterative AFF (iAFF) 방식이 존재합니다. 이를 통해 단순히 linear한 방식의 간단한 initial integration 방식을 사용한 것이 아닌, 좀 더 높은 quality의 initial integration을 활용할 수 있었다고 합니다.
3. Experiments
3.1 Setup

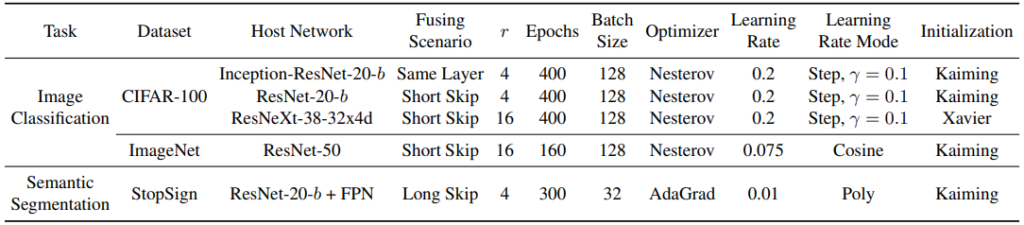
제안된 AFF 방식과 iAFF 방식은 결국 입력 X, Y에 대한 fused feature Z를 만들어내기 때문에, fusion 메커니즘을 활용하는 모든 방법론에 활용될 수 있습니다. Fig 4는 AFF/iAFF 방식이 각각 InceptionNet, ResNet, FPN 구조에서 대체된 위치를 의미하며, 이와 같이 대체되어 비교실험이 진행되었습니다. Table 1은 각 데이터 셋과 활용된 구조에 따른 implementation detail입니다.
3.2 Ablation Study: Impact of Multi-Scale Context Aggregation
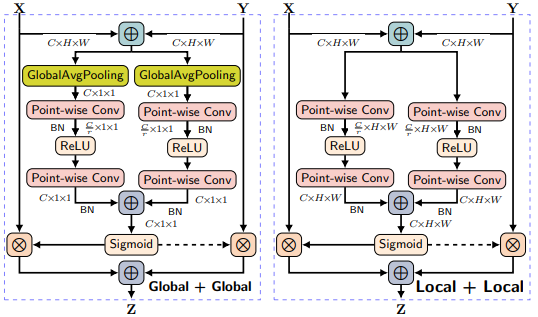

Table 2는 Attention 시 Global context 뿐만 아니라 Local context도 중요하다는 것과 제안된 MS-CAM이 이 두 가지 context를 잘 활용하고 있음을 보여주는 실험 성능 입니다. 이 실험에서 Local+Local은 Fig 5의 오른쪽, Global+Global은 Fig 5의 왼쪽과 같이 한 context에만 bias되도록 설계되었습니다. 또한, 세 가지 세팅 모두 동일한 파라미터를 가지도록 설계되었습니다. 이러한 세팅하에 실험했을 때, 사용된 모델 구조가 깊어짐과 상관없이 (b 값이 커지는 것과 상관없이) Global+Local의 성능이 가장 높으며, 이는 attention 과정에서 두 종류의 context를 모두 보는 것이 중요함을 의미합니다.
3.3 Ablation Study: Impact of Feature Integration Type
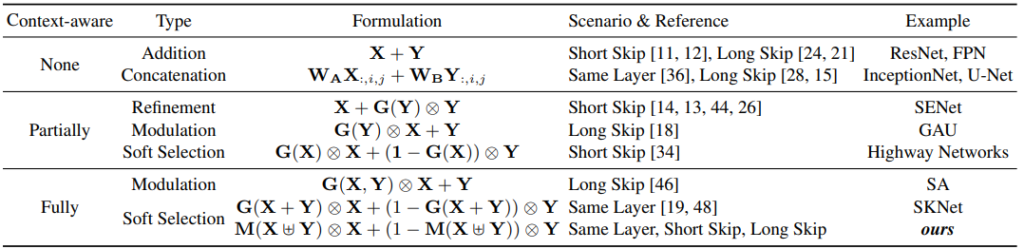
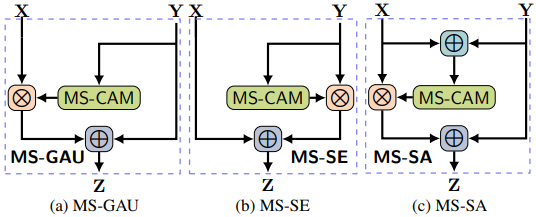
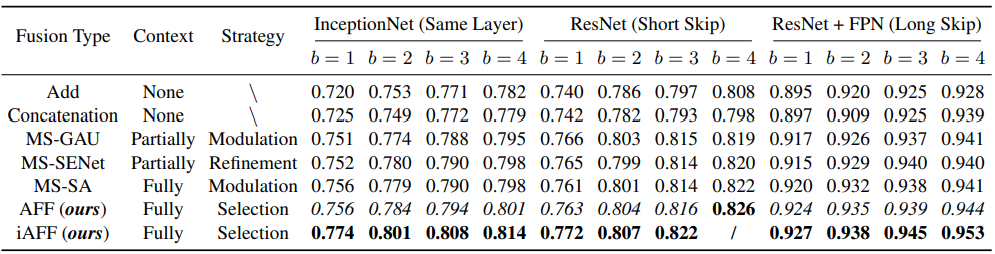
Table 4는 MS-CAM 방식과 AFF/iAFF 방식 각각의 성능 향상 점을 확인하기 위한 실험 결과입니다. 이때, AFF/iAFF의 효력을 다른 방법론들과 비교하기 위해 (다른 방법 구조는 Table 3 참고), Fig 6과 같이 다른 방법론들의 attention 과정을 MS-CAM으로 고정시켜 실험하였습니다. 당연하게도, 단순하게 linear fusion하는 Add 및 concat 연산보다는 제안된 방식의 성능이 높았습니다. 또한 다른 방법론에 MS-CAM을 넣은 MS-GAU와 MS-SENet, MS-SA의 성능을 AFF와 비교했을 때, 모든 경우에서 이보다 높은 성능을 보여, attention 방식 뿐만 아니라 Feature fusion 구조 자체도 효율적임을 보였습니다. 마지막으로 iAFF는 AFF 대비 꽤나 높은 성능 차이를 보이며, initial integration 방식이 성능에 큰 영향을 미치는 것 또한 보였습니다.
3.4 Ablation Study: Impact on Localization and Small Objects
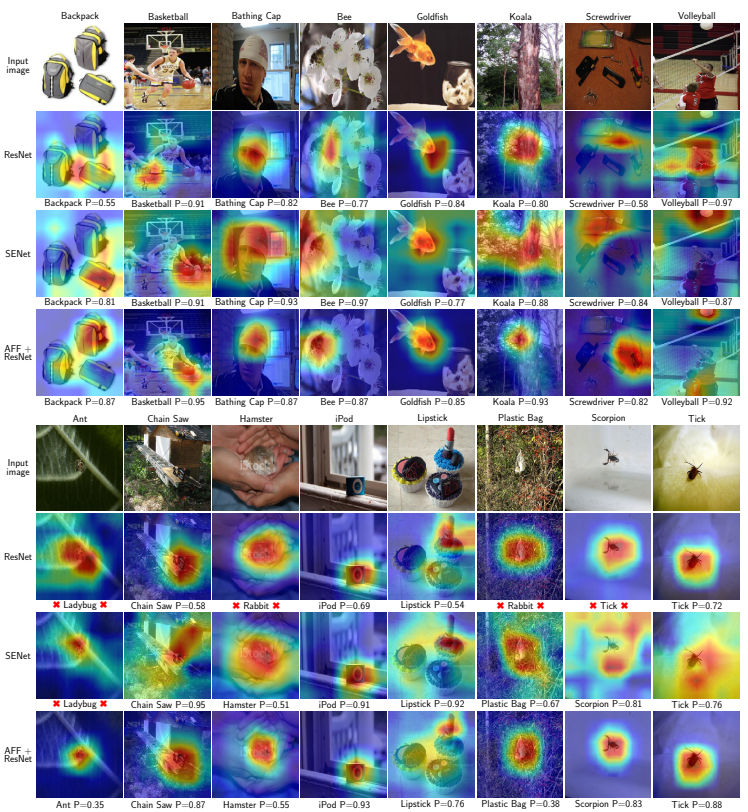
Fig 7은 제안된 방식과 타방법론들의 Grad-CAM 비교입니다. x 표시는 클래스를 잘못 예측한 경우를 의미하며, P는 예측된 확률입니다. 현존하는 방식들)(ResNet, SENet)이 global context만을 사용했던만큼, 상단의 1~4행까지 큰 object의 경우 현존하는 방식들도 object의 위치를 잘 예측하는 것을 확인할 수 있습니다. 하지만, 5~8행까지 보이는 small object의 경우, 현존하는 방법들이 object를 잘 localize 하지 못하는 반면, 제안된 AFF 방식을 ResNet과 활용할 경우 잘 찾는 것을 확인할 수 있습니다. 이를 통해 제안된 방식이 global context에만 bias되지 않았음을 알 수 있습니다.
3.5 Comparison with State-of-the-Art Networks
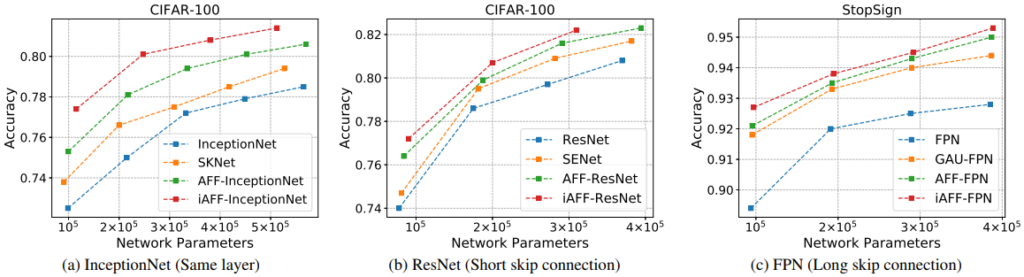
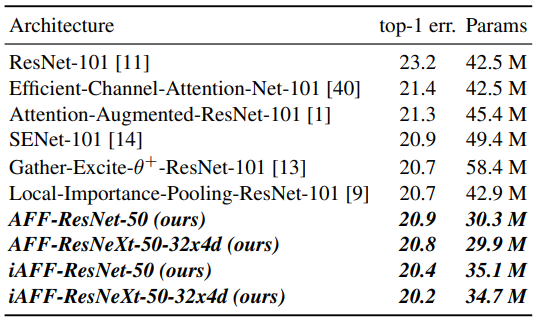
Fig 8과 Table 5는 다른 SOTA들과의 비교 성능입니다. Ablation에서 잘 증명하였듯, 다른 방식들에 비해 높은 성능을 보였으며, 심지어 Table 5를 보시면, 더 적은 파라미터를 활용하였는데도 불구하고 제안된 fusion 방식을 활용할 경우 더 높은 성능을 보여주었습니다.
4. Reference
[1] https://openaccess.thecvf.com/content/WACV2021/papers/Dai_Attentional_Feature_Fusion_WACV_2021_paper.pdf