이번에 소개드릴 논문은 CVPR2022에 나온 backbone 관련 논문입니다. 제목을 보시면 상당히 흥미롭다고 느껴지실 수도 있는데, 컨볼루션 크기를 매우 크게 키워서 백본을 구성하면 좋은 성능을 달성할 수 있다는 것입니다.
Intro
일단 먼저 인트로에서는 가장 먼저 ViT의 성공에 대해서 집중합니다. 아시다시피 ViT가 20년도?쯤에 나타나면서 backbone과 관련된 paper에서는 항상 ViT가 언급이 됩니다. ViT의 가장 핵심적인 포인트는 잘 아시다시피 Multi-Head Self-Attention이라고 볼 수 있습니다.
그렇다면 이 MHSA는 도대체 어떠한 역할을 수행하기에 대부분의 컴퓨터비전 분야에서 좋은 성능을 보여주는 것일까요? 기존의 연구들에서 흔하게 주장하는 바로는 이 MHSA이 flexible하고, inductive bias가 적어 capable하며, 왜곡에도 강인하고 long-range dependencies를 잘 모델링할 수 있기 때문이라고 주장합니다.
물론 그 외에도 다양한 시각으로 ViT가 이래서 잘 동작하는 것이다라는 논문들도 있지만, 위의 내용이 경험적으로 가장 많이 나타내는 주장들로 판단됩니다.
아무튼 저자는 이러한 다양한 시각들 중에서 한가지에 집중을 하였는데, 이는 바로 Large Receptive Field입니다.(위의 주장들 중에서는 modeling long-range dependencies에 해당하게 되겠네요.)
기존의 ViT도 그렇고, 그 이후에 파생된 PVT나 Shunted Vision Transformer 등등 다양한 Transformer들은 feature map에 전체를 MHSA 연산을 수행하는 global 방식을 활용하고 있으며 local한 방식을 활용하는 Swin transformer 같은 경우에도 window의 크기가 3×3과 같은 작은 사이즈가 아닌 제법 큰 사이즈를 활용하고 있습니다.
즉 Transformer의 MHSA는 넓은 영역에 대해서 적용함으로써 정보를 수집하고 있다고 생각하시면 될 것 같습니다. 반면에 CNN의 경우에는 Large Kernel Size를 잘 활용하지 않는 모습을 저희는 쉽게 볼 수 있습니다. 대부분의 CNN은 small kernel size(e.g. 3×3)을 반복적으로 깊게 쌓음으로써 receptive field를 점차 넓혀나가는 방식으로 설계가 되어있습니다.
여기서 저자는 만약 우리가 CNN을 작은 커널 사이즈를 가지는 레이어들을 반복적으로 쌓는 것이 아닌 매우 큰 커널 사이즈를 가지는 레이어를 소수로 구성하면 어떻게 될 것인가?에 대한 의구심을 가지게 됩니다.
즉 CNN과 ViT의 성능의 차이가 만약 Large receptive field에서 오는 것이라면 CNN의 receptive field를 크게 키우면 성능의 갭을 다 따라잡을 수 있을까? 라는 것이죠.
그래서 저자가 새롭게 제안하는 백본의 컨셉은 매우 단순합니다. 기존의 CNN에서 3×3 layer를 31×31 크기의 Depth-Wise convolution으로 변경한 후 레이어의 수를 조금 더 shallow하게 가져가는 것이죠.
결과적으로 저자는 5가지 정도의 경험적인 가이드라인을 제시하였는데 이는 다음과 같습니다.
- Large 커널을 CNN에서 활용하는 것이 실제로 효율적이다(메모리 관점)
- 매우 큰 large 커널을 활용할 때 Identity shortcut은 매우 중요하다.
- re-parameterizing 기법은 large kernel 모델이 안정적으로 수렴하는데 도움을 준다.
- Large 커널은 imagenet 뿐만 아니라 특히 down-stream task에 상당히 우수한 성능 향상을 보인다.
- Large 커널은 심지어 작은 사이즈의 feature map에 적용하더라도 효과적이다.
Guidlines of Applying Large Convolutions
그럼 위에서 언급한 5가지 가이드라인에 대해서 하나씩 자세하게 알아보도록 합시다.
첫번째 가이드라인은 Large convolution이 과연 메모리 측면에서 효율적인가에 대한 답변입니다. 이는 먼저 Large kernel을 그동안의 CNN 백본들이 활용하지 않았던 이유는 간단합니다. 연산량과 FLOP이 많이 소모된다는 것이 가장 큰 문제였죠. 그래서 저자는 Depth-Wise conlolution을 활용하여서 이 문제를 간단하게 해결하고자 합니다.
실제로 저자가 제안하는 RepLKNet의 경우에는 kernel size를 기존 모든 스테이지가 3×3 컨볼루션 이었다면, 이를 [31, 29, 27, 13]으로 변경하였음에도 불구하고 FLOP과 파라미터 수가 이전 대비 18.6%, 10.4% 밖에 오르지 않았다고 합니다.
두번째 가이드라인은 Identity shortcut은 large kernel를 가지는 네트워크에 매우 중요하다는 것입니다. 이에 대한 실험으로 저자는 mobileNet-v2에 대하여 ShortCut 적용 여부에 따른 Large Kenrel의 성능 향상 폭을 실험하였습니다.

위의 표가 그 결과를 보여주고 있는데, 보시다시피 일단 shortcut은 일종의 서로 다른 receptive field를 가지는 여러 모델들 간에 앙상블 기법으로 볼 수도 있으며 이러한 관점에서 Large Kernel을 사용하게 될 경우 성능의 향상이 기존 small kernel보다 존재하지만, 만약 shortcut이 없다면 성능이 더 크게 감소하는 것을 확인할 수 있었습니다.
그리고 이러한 경향성은 ViT에도 동일하게 적용된다고 합니다. 여기서 저자는 비록 ViT의 MHSA과 CNN의 연산 방법은 확연히 다르지만, 결국 shortcut이 없으면 네트워크가 local한 detail을 학습하는 데 있어 어려움이 될 수 있다고 주장합니다.
3번째 가이드라인으로는 바로 Large Kenrel에서 Re-parameterizing with small kernel이 모델 수렴에 도움을 준다는 것입니다. 여기서 Re-parameterizing에 대하여 잘 모르시는 분들도 있으실 겁니다. 해당 기법은 아래 그림을 먼저 보시는 것이 더 이해에 도움이 되지 않을까 합니다.

위의 그림2 좌측을 보시면 input에 대하여 한번은 7×7 커널을, 또 한번은 3×3 커널을 각각 연산해줍니다. 그리고 나서 7×7 커널에 3×3 커널을 더해주는 방향으로 모델은 학습을 하게 됩니다. 이렇게 할 경우 다양한 커널 사이즈로 연산을 수행하여 모델은 더 다양한 receptive field를 가지게 되고 이는 성능에 좋은 영향을 줄 수 있게 됩니다.
하지만 이렇게 병렬적으로 연산을 수행하게 되면 발생하는 문제점이 있습니다. 바로 연산량의 문제가 되겠죠. 그래서 re-parametrizing이라는 기법은 학습 때는 그림2 왼쪽과 같이 병렬적으로 각각의 커널에 대해 독립적인 계산을 수행하지만, 실제 inference 단계에서는 두 weight를 합쳐서 하나의 컨볼루션 레이어로 만드는 기법을 의미합니다.
즉 7×7 컨볼루션과 3×3 컨볼루션의 wieght를 합쳐주고 Batch-Normalization도 합쳐서 하나의 7×7 컨볼루션을 재활용할 수 있다는 것입니다. 물론 이것은 해당 논문에서 제안하는 방식은 아니고, 해당 논문의 저자가 이전에 작성했던 논문의 내용이라.. 관심 있으신 분들은 논문을 타고 타고 가서 한번 확인해보시면 좋을 것 같습니다.
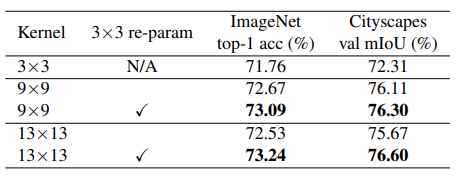
아무튼 저자는 이러한 re-parameterizing이 large kernel을 활용할 때 상당히 큰 이점이 있다고 주장합니다. 한 예시로 3×3 컨볼루션에서 9×9, 13×13으로 커널 사이즈를 키웠을 때 9×9 키운 것 대비 13×13의 성능이 조금 더 작은 것을 관측할 수 있습니다(72.67 vs 72.53, 76.11 vs 75.67) 하지만 Re-param 기법을 적용하였을 경우의 성능에서는 ImageNet과 Cityscape에서 모두 더 좋은 결과를 보여주고 있습니다.
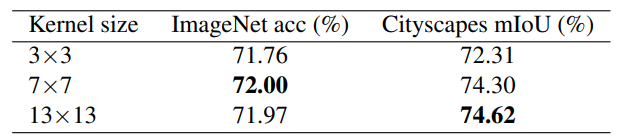
그리고 한가지 더, ImageNet과 비교하여 down-stream task에 해당하는 Cityscape에서는 3×3과 같은 small kernel보다 Large kernel을 활용하게 될 경우 더 큰 폭의 성능 향상을 보여주고 있습니다. 이것은 바로 뒤에서 언급할 가이드라인4와 연관됩니다.
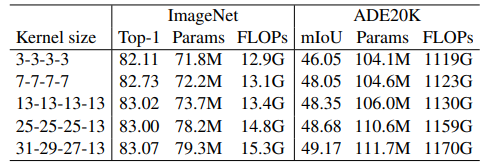
가이드라인4의 내용은 인트로에서도 언급했다시피, Large conlvolution이 down-stream task에 보다 더 효과적이라는 점입니다. 위에 표에도 그렇고 아래 표에서도 확인하실 수 있다시피, ImageNet에 대한 classification 성능 대비 Semantic Segmentation과 같은 down-stream task에서 3×3 convolution 대비 large kenrnel의 성능 향상 폭이 상대적으로 더 크게 다가옵니다.
그렇다면 이러한 현상이 발생하는 이유가 무엇일까요? 저자는 Large kernel을 활용하는 것이 feature의 texture보다는 shape에 더 집중할 수 있다고 주장합니다. 이전 연구들에 따르면, ImageNet 속 사진들은 각각의 texture와 shape에 따라서 올바르게 분류가 가능하다고 합니다.
하지만 일반적으로 사람의 시각 체계는 물체를 인식할 때 texture 보다는 물체의 shape에 더 큰 초점을 두고 진행하게 됩니다. 이러한 관점에서 모델이 만약 texture보다 shape에 더 큰 bias를 가지게 된다면 down-stream task에서 더욱 잘 동작할 수 있을 것으로 판단됩니다.(object detection, semantic segmentation 등등)
최근 연구에 따르면 ViT의 경우 Shape bias가 CNN보다 더 뛰어나기 때문에 다양한 transfer task에서 잘 동작한다는 주장이 등장하고 있습니다. 이와 대조적으로 ImageNet으로 사전학습된 일반적인 CNN의 경우 texture에 bias가 되는 경향성이 있습니다.
저자는 이러한 관점에서 다행히 Large Convolution을 활용하게 될 경우 모델이 shape bias에 더 치중하도록 학습을 진행시킬 수 있다고 주장합니다.
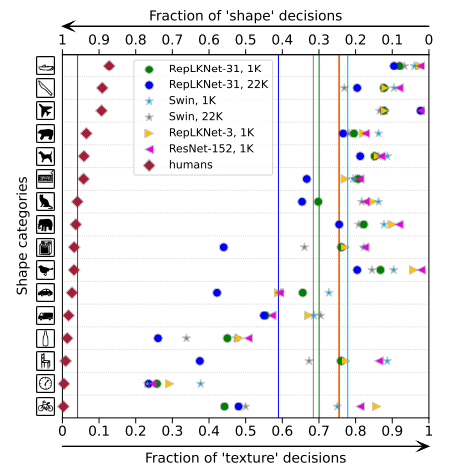
위의 그림은 저자가 제안하는 RepLKNet, Swin, ResNet이 각각 얼마나 shape bias를 가지는지에 대해 보여주는 그림입니다. 좌측에 도달할수록 shape bais한 성향이 강한거이며, 우측에 가까울수록 texture bias가 크다는 것을 의미합니다.
제일 좌측에 붉은색 라인은 사람이 각 카테고리별로 얼만큼 shape bias를 가지는지를 보여주고 있습니다. 이와 반면에 ResNet은 texture decision의 평균값이 0.7후반대로 상당히 우측에 기울어져있는 것을 볼 수 있습니다.
Swin Transformer 역시 local한 윈도우 내에서 MHSA 연산을 수행하다보니 아무래도 shape bias한 성향보다는 texture bias한 성향이 더 강한것으로 표현이 되고 있습니다. 하지만 저자가 제안하는 RepLKNet의 경우 다른 모델과 비교하였을 때 평균적으로 더 좌측에 위치하는 경향성을 보여주고 있습니다.
물론 이러한 RepLKNet의 경우에도 kernel size를 일반적인 CNN과 유사하게 3×3 커널을 활용하게 될 경우에는 ResNet, swin과 유사한 texture bias를 가지게 됩니다. 이러한 관점에서 저자는 large kernel이 shape bias에 더 치중될 수 있다는 점에 주목하고 있습니다.
마지막 가이드라인은 바로 large kernel(e.g. 13×13)이 small feature map(e.g. 7×7)에도 효과적이라는 점입니다.
저자는 이를 증명하기 위해 mobilenetV2에서 제일 마지막 스테이지의 7×7 feature map에 각각 7×7과 13×13 Depth-Wise convolution을 적용하였습니다. (물론 여기서 13×13 convolution의 경우 가이드라인 3에서 제시한 re-param 기법을 활용했다고 합니다.)
이때의 정량적 결과는 위의 표와 같습니다. 비록 마지막 스테이지의 feature map의 해상도가 작더라도, 이 보다 더 큰 크기의 kernel을 활용하였을 때 3×3 커널보다 더 큰 성능 향상을 보이고 있으며 특히 down-stream task에서 더더욱 좋은 효과를 보여주었다고 합니다.
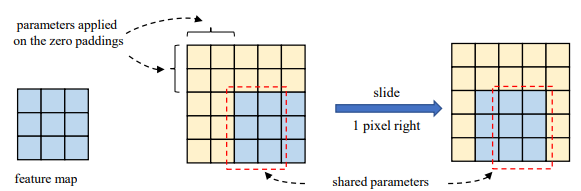
그렇다면 이렇게 성능 향상이 발생할 수 있었던 이유는 무엇일까요? 저자는 kernel size가 크게 될 경우에는 CNN의 translation equivariance가 엄격하게 지켜지지 않는다고 주장합니다. 즉 위의 그림처럼 인접한 공간에서의 두 출력은 커널 가중치의 일부만을 공유하게 됩니다.
또한 ViT 쪽 논문들을 쭉 살펴보면 최근에는 relative positional encoding이라는 개념을 모두 depth-wise convolution으로 대체하고 있습니다. 즉 large kernel은 상대적인 포지션을 학습하는데 도움을 주는 것 뿐만 아니라, padding effect를 통해 절대적인 포지션을 인코딩할 수 있다고도 합니다.
RepLKNet : a Large Kernel Architecture
앞에 내용이 너무 길었던 것 같습니다. 이제는 저자가 새롭게 제안하는 RepLKNet에 대한 구조적인 부분들 및 정량적 결과를 보이고 리뷰를 마치도록 하겠습니다.
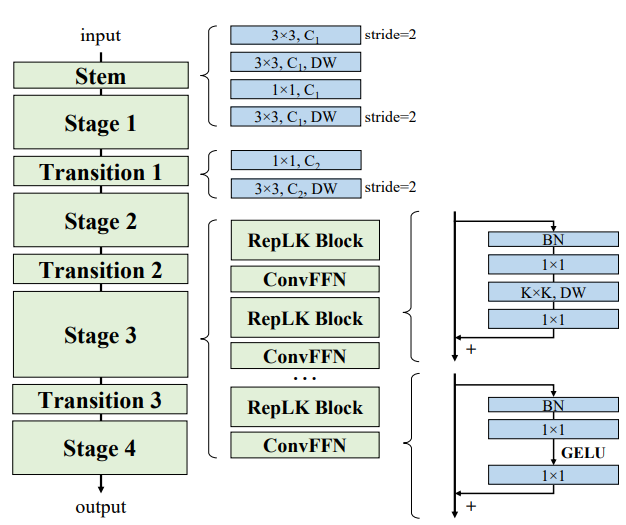
일단 네트워크의 구조는 위의 그림과 같습니다. 일반적인 backbone들처럼 stage가 4개로 구분이 되어있으며, 하나의 스테이지 안에는 RepLK Block과 Convolution Feed Forward Network로 구성이 되어있습니다.
RepLK Block은 그냥 단순한 bottlenect layer라고 보시면 될 것 같은데, Batch Norm과 1×1 conv – KxK DW conv – 1×1 conv로 구성이 되었습니다. 그리고 Feed-Forward network 역시 Batch Norm과 1×1 conv – GELU – 1×1 conv로 구성되어있습니다.
일반적인 backbone 논문들은 대부분 Layer norm을 활용하는 반면에 해당 논문에서는 기존처럼 batch norm을 고집하는 이유는 가이드라인3에서 언급한 re-param 기법을 적용하는데 있어 batch-norm이 보다 더 간편하게 적용가능하기 때문이라고 주장합니다.
그리고 아시다시피 각 stage 별로 Kxk DW conv에서 K는 [31, 29, 27, 13]으로 구성이 되어있습니다.
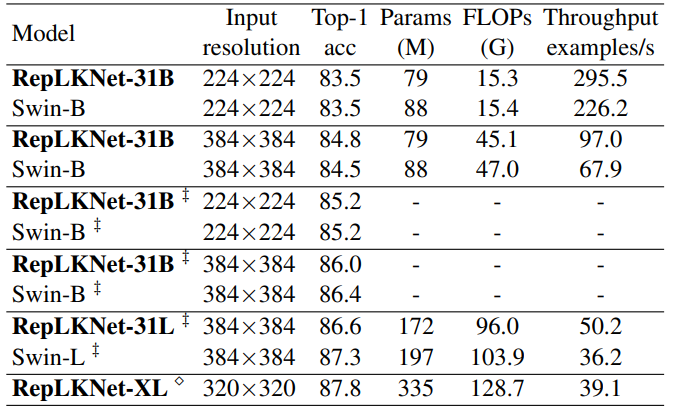
위에는 ImageNet의 정량적 결과입니다. 정량적 결과를 비교하는데 있어 단순히 Swin Transformer와 밖에 비교를 하지 않았는데, 아마도 해당 방법론이 ImageNet보다는 Down-stream task에 더 큰 성능 향상을 보이고 있기 때문에, ImageNet에서의 실험 비중 및 비교 대상을 대폭 감축시킨 것으로 판단됩니다.
아무튼 RepLKNet의 경우 Swin-Transformer와 비교하여 파라미터 수 및 FLOP이 작거나 비슷한 경우에도 불구하고 유사하거나 더 좋은 성능을 보여주고 있습니다. 하지만 아쉽게도 ImageNet22-K 데이터셋에서는 RepLKNet의 성능이 Swin Transformer보다 더 낮게 나오는 것을 확인하실 수 있습니다. 이러한 관점에서 데이터 셋이 많아지면 왜 성능이 더 낮게 나오는가에 대하여 한계점이 명확하게 나타나는 모습입니다.
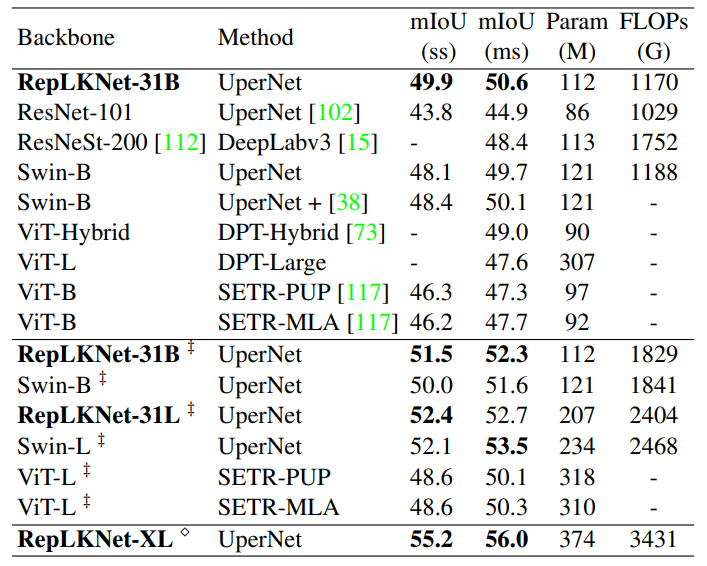
다음은 저자가 그토록 강조?했던 down-stream task에 대한 정량적 비교 결과입니다. ADE-20K에 대한 semantic segmentation에 대한 결과로 보시면 될 것 같고, 비슷한 크기와 속도 측면에서 높은 성능 향상을 보여주고 있다는 점에서 상당히 인상적입니다. 특히 ImageNet-22k에서는 Swin보다 성능이 낮게 나왔지만 이러한 사전학습 모델을 ADE-20k에서 전이학습 후 평가하였을 땐 성능에서 나름 차이가 있다는 점이 유의미하다고 생각됩니다.
결론
제가 리뷰에는 다 담지 못하였지만 해당 논문에는 Large Kernel에 대한 매우 깊이 있는 실험 및 분석이 담겨져 있습니다. 그래서 한번쯤은 가볍게 읽어보시는 것도 좋다고 생각되는 논문이며 저도 추후에 시간을 더 들여서 세미나를 진행하고자 합니다.