이번에 리뷰할 논문은… Self-supervised depth estimation관련 논문입니다. 따라서 이론적 배경 설명은 생략하겠습니다.
Self 관련 연구를 하다가 배신을 하고 잠시 supervised 에 빠져있었지만 … 다시 잠시 한번 회귀해봤습니다.
이번 논문 또한 Pseudo-Label이 있어서 저희 Transdssl 과 얼마나 다른 것인가 무엇이 다른 것인가를 중점적으로 봤던것 같습니다. 이렇게 보면 요즘 Self-supervised 쪽에서는 Pseudo-Label을 통해서 ill-posed problem을 우회하려는 움직임이 많이 보이는 것 같습니다. 뭐 이 논문 또한 그러한 측면으로 나온 것 이지요 하하 ..
Contribution
- two stage로 학습 첫번째 스테이지는 high-resolution 을 입력으로하는 network 두번째 스테이지는 high-resolution depth를 GT로 학습
- Nover architecture (?)
- self-supervised 는 어쩔 수 없이 scale ambiguity 가 발생하니 첫번째 스테이지 모델과 두번쨰 스테이지 모델의 scale이 다른 문제를 해결 (?)
- filtering 을 통해 pseudo label로 사용되는 Depth 의 에러를 해결
Method
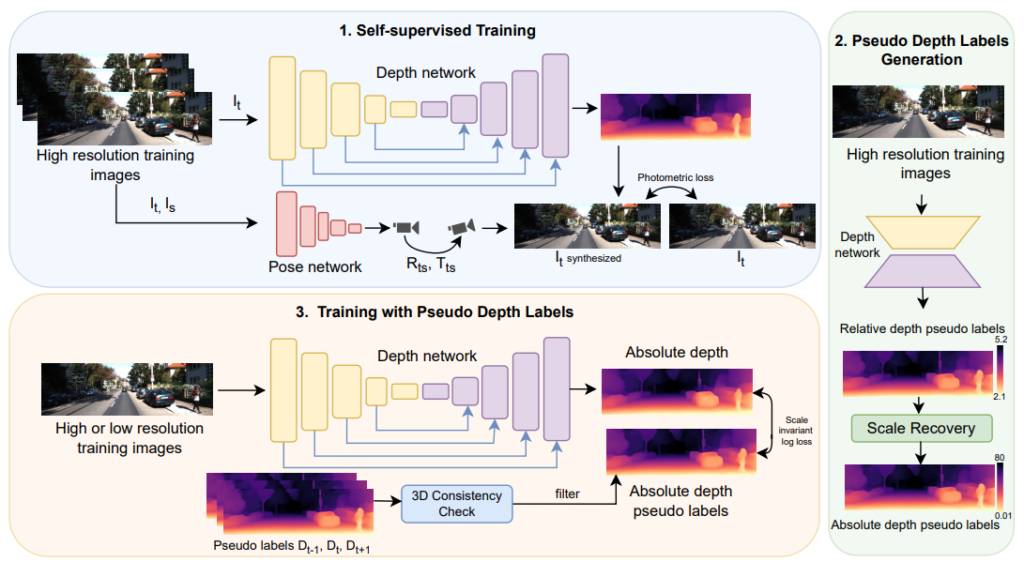
Self-Distillation based Training Pipeline
contrbution에서 언급한대로 이 논문의 key contribution 은 high-resolution image를 이용해서 Pseudo-Label을 생성한 후 이것을 low resolution 및 high-resolution을 입력으로하는 depth network의 GT로 사용해서 학습합니다. 굉장히 간단하죠.
Depth Network Architecture
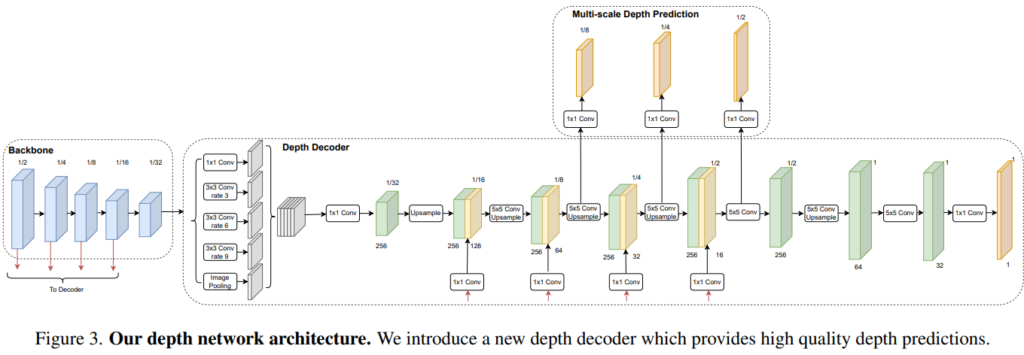
최근 연구실에 와주셔서 세미나를 해주신 김다훈 박사님의 세미나 에서 언급하신 panoptic segmentation에서 제안된 네트워크를 차용했으며, semantic information을 강화할 수 있어서 사용했다 합니다.
Scale Recovery in Pseudo Labels
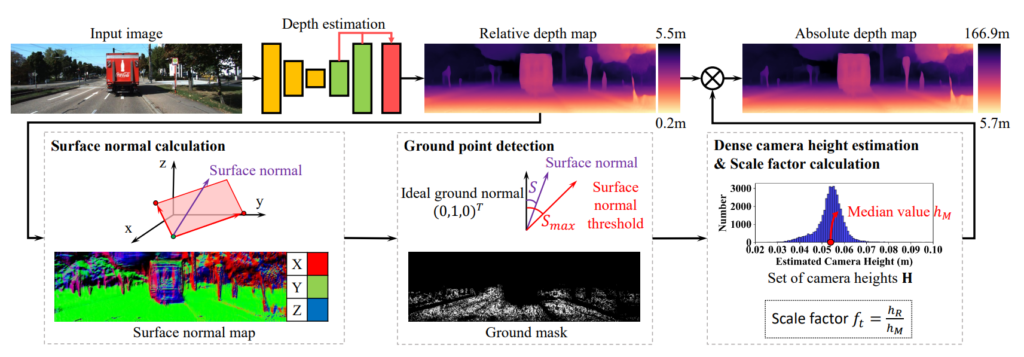
teacher network 와 student network 간에 생기는 scale embiguity를 해결하기 위해서 Scale recovery를 사용했다고 합니다. 이것또한 기존에 있는 방법론을 가져다가 썼는데요. 위 그림과 같은 순서로 예측된 깊이 값을 실제 깊이 값의 scale로 변경해준다고 합니다. 간단하게 말하면 예측된 뎁스의 높이를 실제 카메라 높이로 정규화하는 방식으로 scale이 맞춰집니다. 더욱 자세한 설명은 [1]을 참고하시길 바랍니다.
Filtering Errors in Pseudo Labels
마지막으로 더욱 정확한 Pseudo-Label을 사용하기 위한 filtering 방법론입니다.
아래 식과 같인 Source image 에서부터 예측한 Depth 들을 target depth 로 warping 했을때 차이가 가장 적은 pixel의 depth 을 사용하고 또한 Thresholding 을 넘으면 학습에 사용하지 않는 방법론입니다.
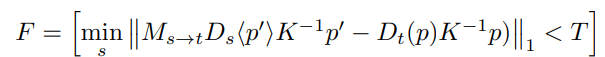
Experiments
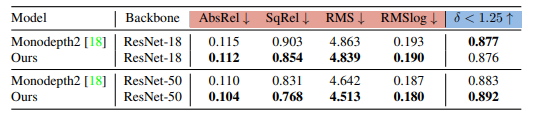
ablation study 입니다. 먼저 depth network를 변경했을 때 결과인데, Resnet50에서 확실한 성능 향상을 보여줍니다.
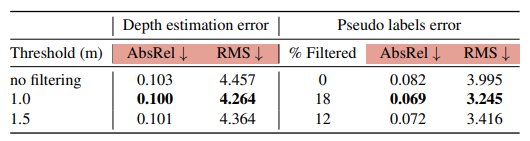
다음으로 filtering 을 했을떄 성능 향상입니다. filtering을 해줬ㅇ르때 확실히 성능 이 높아지는 것을 볼 수 있습니다.
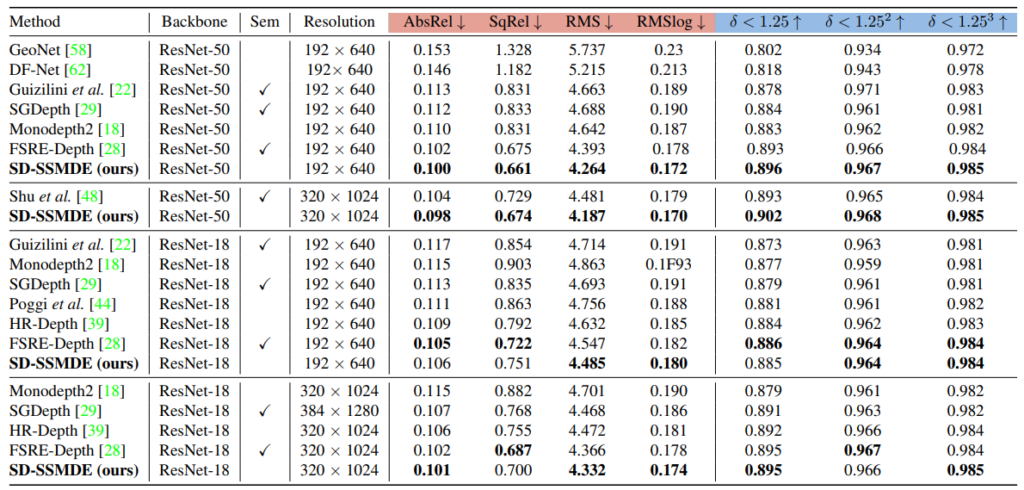
KITTI에서 정량적 성능을 보면 기존 방법론들 대비 높은 성능 향상이 있는 것을 볼 수 있습니다.
References
[1] Toward Hierarchical Self-Supervised Monocular Absolute Depth Estimation for Autonomous Driving Applications
평가를 보면 high resolution에서 오히려 성능이 드랍이 되는 경우도 있는거 같네요. 성능이 오른것도 큰차이가 없는거 같은데, high resolution을 사용하는 이유가 따로 있을까요? 특히나 첫번째 스테이지에서 pseudo-label을 만드는 같은경우엔 high-resolution이 고정인거 같아서요.
음.. 드랍이 된다고 판단하신게 마지막 표라면 백본이 변경되는걸 못보신 것 같습니다.
리뷰 잘 봤습니다.
scale ambiguity 를 해결하는 부분에서 depth의 높이를 실제 카메라의 높이로 정규화 한다고 하셨는데, 높이라는게 어떤걸 말하는건가요??
그리고 마지막 실험 표에서 resolution은 teacher model의 input resolution을 말하는건가요, student model의 resolution 을 말하는건가요?
첫번째 질문 같은 경우는 논문에 실린 방법론을 제가 정확히 이해를 하지 못해서 확실하게 적어두진 않았지만 높이는 아마 카메라 입력 resolution이지 않을까 싶은데 확실해지면 다시 알려드리도록 하겠습니다. 그리고 두번째는 student 입니다.
source view에서 추출된 depth를 target view로 warping한 다음 이때 가장 차이가 적은 값들을 활용했다고 하셨는데, 그렇다면 pseudo label을 생성하기 위해 t frame의 depth만 뽑는 것이 아닌 t-1, t+1 frame의 depth를 모두 뽑아야만 하는 것인가요?
그리고 만약 그렇다고 했을 때 사실 pseudo label로 student 모델이 어떻게 학습한다는 것인지 감이 잘 잡히지 않네요. overall framework에서는 student model이 t프레임 한장을 입력으로 depth를 뽑게 되면 그 이후에 그와 대응되는 pseudo label t depth를 supervised로 학습해야할 것 같은데 여기서 t-1, t+1의 depth를 warping 후 둘을 비교하여 작은 값을 활용한다는 의미가 정확히 무엇인가요?
min loss를 생각하시면 될 것 같습니다. 앞뒤 다 뽑고 둘 중에 보다 정확한 값을 사용하겠다 라고 이해하시면 됩니다.