저번 Mono Depth1 에 이어서 오늘은 ‘Digging Into Self-Supervised Monocular Depth Estimation’ 라는 논문을 리뷰하고자 합니다. Mono Depth2 라고도 불리는 논문입니다. 그럼 리뷰 시작하겠습니다.

Abstract & Introduction
Mono Depth 1과 2는 모두 1장의 image로 depth를 추정하는 self-supervised monocular depth estimation 방법론입니다. 이 둘의 차이라고 한다면 training 과정에서 존재하게 됩니다. 1의 경우 2장의 left & right image로 학습을 진행하는 반면, 2의 경우엔 시간 frame에서의 image pair를 사용해서 학습을 진행하게 된다는 점입니다.
본 논문에서 제안하는 3가지는 아래와 같습니다. 관련된 자세한 설명은 아래 method, loss부분에서 추가하겠습니다.
- pixel의 occlusion에 강인하도록 설계된 minimum reprojection loss
- view artifact를 줄이는 full-resolution multi-scale sampling method
- camera의 motion가정을 위반하는 pixel을 무시하기 위한 auto-masking loss
(camera가 멈추거나, camera와 같이 움직이는 object일 경우)
그렇다면 monodepth1과 monodepth2의 또 다른 차이점에 대해 말씀드리겠습니다.
위에서 말씀드린 것 처럼 monodepth1는 stereo pair(left & right) 로 train하고,
monodepth2는 monocular video(t-1, t ,t+1)로 train을 하게 됩니다. monocular video는 training을 위한 dataset을 구축할때도 1개의 camera만 존재하면 된다는 장점이 있지만, 하나의 문제점이 존재하게 됩니다. 바로 monocular frame image pair 사이에서 camera의 pose변화인 ego-motion을 알아야 한다는 것입니다. monocular video방식에서는 이를 예측하기 위한 pose estimation network가 추가적으로 존재하게 됩니다.
Method
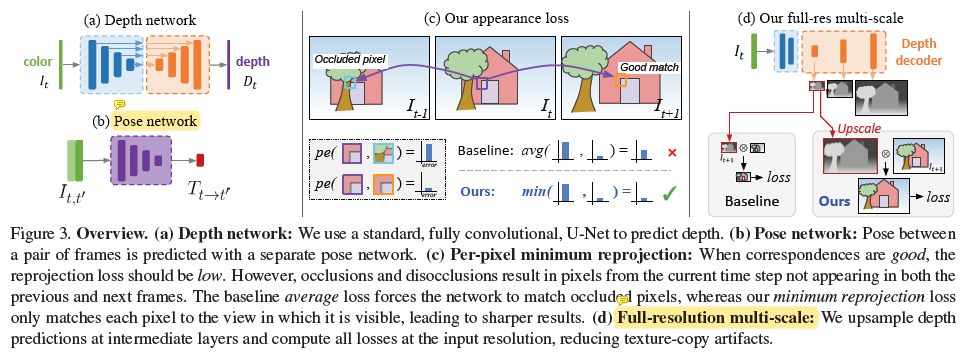
전체 모델은 depth network와 pose network 2가지로 구성되어 있습니다.
(a)는 1장의 single image로부터 depth를 예측하는 Depth Network 구조입니다. encoder-decoder로 이루어진 U-Net의 구조를 사용했고, 중간중간에 skip-connection도 이루어지고 있습니다.
(b)는 frame image pairs 로 부터 해당 두 이미지 사이의 pose 변화를 추정하는 Pose network 입니다. monocular video 방식에서는 이와 같은 pose변화 추정이 필수적입니다.
(c)는 pixel의 occlusion에서 비롯된 부정확한 depth 추정을 해결하는 방법에 대한 설명입니다. 기존 Baseline 방법론에서는 특정 pixel에서의 photometric error(pe) 를 계산할때 pe(t-1,t)와 pe(t,t+1) 의 평균치를 사용했다면, 본 논문에서는 최소값을 사용하겠다는 것입니다.
frame이 이동하면서 특정 pixel이 가려진 경우를 무시하고, pixel간의 pe가 작은 영역인 곳만 error에 반영하겠다는 취지입니다. 아래 Per-Pixel Minimum Reprojection Loss 에서 추가적인 설명 이어가겠습니다.
(d)는 depth decoder에서 나온 4가지 scale의 depth map을 활용해서 reprojection error를 구할 때, 서로 다른 scale의 depth map을 input image resolution에 맞게 upsampling 한 뒤에 reprojection error를 구하는 방식입니다.
기존의 방식들에서는 input image를 서로 다른 4가지 scale의 depth map에 맞춰서 downsampling 하고 나서 reprojection error를 구했는데, 이와는 사뭇 다른 접근입니다. 이를 통해 texture copy artifacts를 줄일 수 있다고 합니다. 그 이유는 아래의 Multi-scale Estimation 에서 설명드리도록 하겠습니다.
Per-Pixel Minumum Reprojection Loss

Method 그림의 (c) 에 해당하는 loss입니다.
t frame의 특정 pixel이 t-1에서는 잘 보이지만 t+1에서는 occluded 되었을 경우에 occluded 된 곳을 무시하고자 하는 loss 입니다. 위 그림과 참고해서 보시면 이해가 더 잘 가실겁니다.
이렇게 pixel이 가려지는 경우는 크게 2가지 이유로 나타날 수 있습니다.
- image내의 object boundary 에서의 ego-motion에 의해 비롯된 out-of view pixel
- 이미지 좌,우 경계의 disocclusion
(카메라가 우측으로 움직인다면, 그때 사라지게 되는 좌측 경계의 영역)
1번의 경우는 위의 min 방식으로 해결이 되는데 2번의 경우는 해결이 되지 않는다고 합니다.
사실 2번의 disocclusion같은 경우에 monodepth1에서 Post-Processing 이라는 방법론으로 해결책을 제시 했습니다. 이는 제 monodepth1 리뷰에 설명이 담겨있으니 생략하도록 하겠습니다.
아래 표는 post processing에 따른 성능 차이를 나타낸 실험입니다. 조금의 성능 향상이 있는것을 볼 수 있습니다.
Auto-Masking Stationary Pixels
사실 self-supervised monocular training 정적인 scene을 가정한 채로 camera가 움직이면서 image를 촬영합니다. 그렇게 해야 disparity와 depth를 정확히 계산할 수 있겠죠??
하지만 여기서 1) 카메라가 정지하거나, 2) scene에 object가 움직이는 경우에는 성능이 크게 저하가 됩니다.
disparity 를 통해서 depth를 구하는 식을 생각해봅시다.
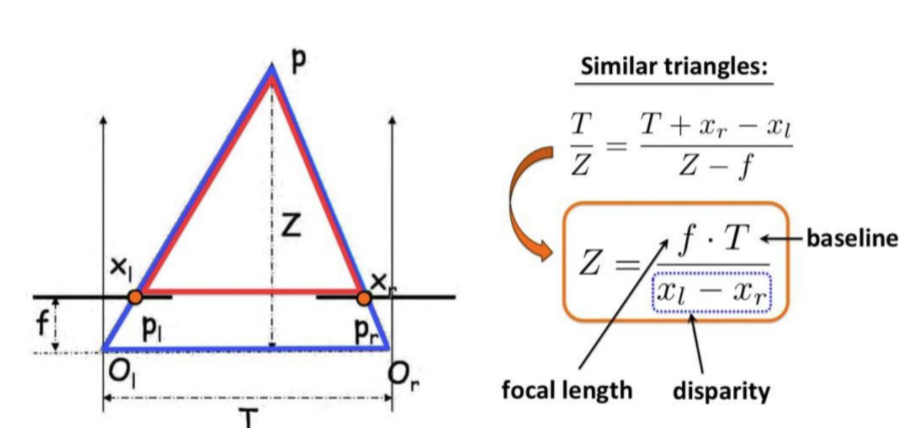
카메라가 정지하거나, scene에서의 object가 camera와 동일한 속도로 움직이는 경우
disparity는 0에 수렴하게 되고, 이에따라 depth는 무한대로 발산하게 됩니다. 이를 infinite depth hole이라고 표현 하는데, 아래의 그림에서 살펴보실 수 있습니다.

이러한 문제를 해결하고자 간단한 auto-masking 방법론을 제시하게 됩니다.
사용하는 mask는 한 frame에서 다른 frame으로 옮겨갈 때 모양을 변경하지 않는 pixel을 필터링 해 주는 mask 입니다.
mask는 0과 1의 값을 가지는 binary mask이고 식은 아래와 같습니다.
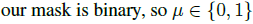
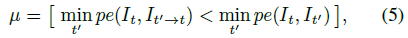
위의 auto-masking을 사용한 정성적인 결과는 아래와 같습니다.
위쪽 row에선 camera와 같은 속도로 움직이는 자동차가 filtering된 것을 볼 수 있습니다.
아래 row에선 camera가 멈춰있는 상황에서, 대부분의 픽셀이 filtering 되는 것을 볼 수 있습니다.

모델의 출력으로 4가지 scale의 depth map이 나오게 되는데, 각 scale별로 위 loss가 나오게 됩니다.
각 scale별로 minimum reprojection loss L_p 에다가
아래에 나오는 smoothness loss L_s 를 더한것이 최종 loss입니다.
smoothness loss는 monodepth1에서와 동일하니 설명을 생략하도록 하겠습니다.
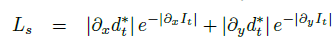
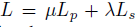
Multi-scale Estimation
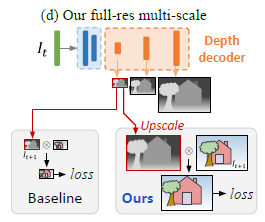
그렇다면 각 scale에서 계산된 depth map으로 어떻게 reprojection error를 계산할까요?
(아 참고로, depth decoder의 4개의 층에서 각기 다른 scale의 depth map이 출력되게 됩니다.)
이는 본 글 상단의 Method 그림 중 (d) 에 해당하는 부분입니다.
기존의 방식들은 input image를 각 depth map resolution에 맞게 downsampling 시키고 reprojection error를 계산합니다. 이 경우를 잘 생각해 보겠습니다. input image 를 downsampling 시킨다는 것은 원본 이미지 해상도가 아니라 low scale에서 reconstruction error 를 계산한다는 뜻입니다. 원본 이미지에서 low texture를 가지는 영역처럼 주변 pixel과의 차이가 별로 없는 영역같은 경우, low scale로 낮춰서 비교를 할때는 같은 pixel인 것 처럼 보이지만, 실제로는 다른 pixel이고 depth 도 다릅니다. 실제로는 다른 영역을 나타내는, 이러한 large-low texture 영역을 low scale에서 비교하게 되면 disparity가 0에 수렴하는것으로 보이게 되고, 이는 depth hole을 초래하게 됩니다.
따라서 본 논문에서는 input image를 downsampling 하는것이 아니라, 4가지 서로다른 scale의 depth map 을 input image resolution에 맞게 upsampling 한 뒤에, reconstruction loss를 계산함으로써 이러한 문제점을 해결합니다.
Experiment
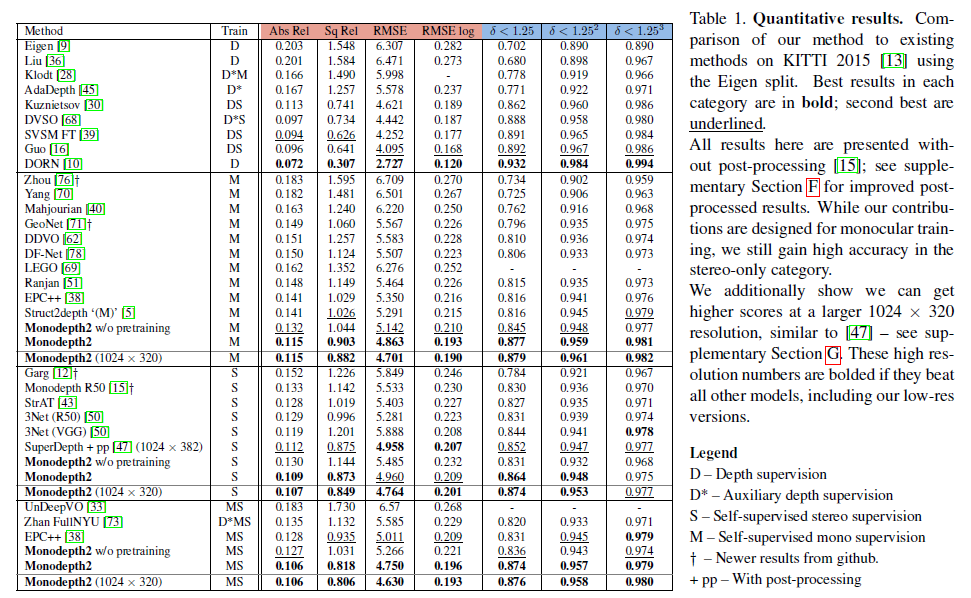
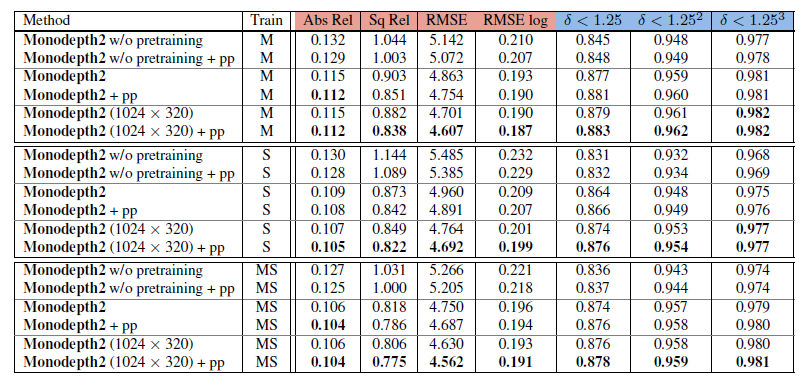
전체적인 성능을 나타낸 표입니다.
본 방법론은 monocular 방식으로 설계가 되었지만, Stereo 성능에서도 높은 결과를 달성한 것이 흥미롭습니다.
위의 결과는 post-processing 을 진행하지 않았을때의 결과입니다. 본 결과에 post-processing까지 적용한다면 위에서 보여드린 표처럼 성능이 소폭 상승하게 됩니다.
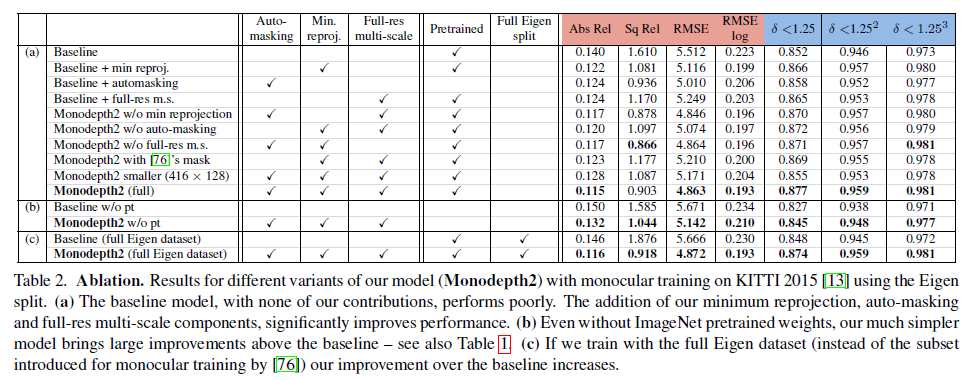
Ablation study의 결과는 위와 같습니다. 논문에서 제안한 방법론 하나씩을 빼고 더할때 생각보다 엄청난 성능차가 있는 거 같지는 않아 보입니다.
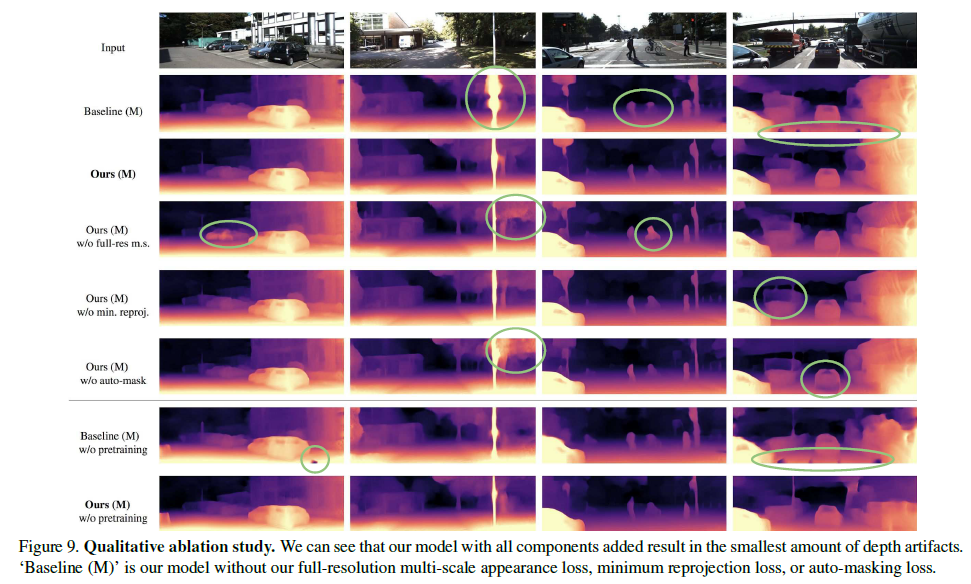
위의 Figure은 ablation에 따른 정성적 결과입니다.
w/o auto-mask 의 결과가 흥미로운데, camera와 함께 움직이는 자동차에 대해 depth 예측이 정확하지 않은것을 볼 수 있습니다.

실패 case 도 존재합니다. 빛의 반사가 심한 영역이나, 채도가 높은 영역에서는 depth가 부정확하다고 합니다.
reprojection loss를 구할 때, low texture에서의 정확도가 낮은것과 비슷한 맥락이라고 추측됩니다.
요즘 depth 논문들을 열심히 읽고 있는데, camera calibration 등의 기하학적인 부분이 참 중요하다고 느끼는 중입니다. 공부를 더 열심히 해야할 거 같습니다. 그럼 오늘 리뷰 이만 마치겠습니다. 감사합니다.
포즈 계산이 필수라 하셨는데 왜그런가요?
여기서 말하는 pose란 translation과 rotation 변화를 말합니다. monocular 방식에서는 예측된 pose를 사용해서 source->target으로 reconstruction이 이루어지고 loss까지 계산이 됩니다. 따라서 reconstruction을 위해서는 frame 끼리의 pose 계산이 필요하게 됩니다.