안녕하세요. 오늘은 self-supervised contrastive video representation learning 방법론에 대한 논문을 가져왔습니다. 제가 요즘 제작하고 있는 데이터셋을 기존 비디오 검색 모델(ViSiL/TCA 등등)에서 학습을 시도하고 있는데요. 이 부분에서 ViSiL에서 학습이 잘 안되는 문제점을 겪고있습니다. 여러가지 부분을 논의해봤는데, data augmentation이 문제일 수 있다는 의견이 있어서 해당 논문을 추천받아 논문의 방법을 이식해서 실험을 진행해보려고 합니다. 그럼 시작하겠습니다.
Introduction
일단 기본적으로 feature의 표현력을 배우는 것은 공통적으로 중요한 부분입니다. 이러한 맥락에서 self-supervised 방법론들이 비디오와 이미지에서 서로 다른 차원을 배우려고 하는 방향으로 계속해서 방법론들이 발전해왔습니다.
이러한 맥락에서 논문 저자들은 unlabled 비디오에서 spatiotemporal한 표현력을 학습할 수 있는 Contrastive Video Representation Learning(CVRL) framework를 제안합니다. 모델의 프레임워크에 대한 설명은 Method에서 다룰 예정이니 바로 본문으로 넘어가봅시다.
Method
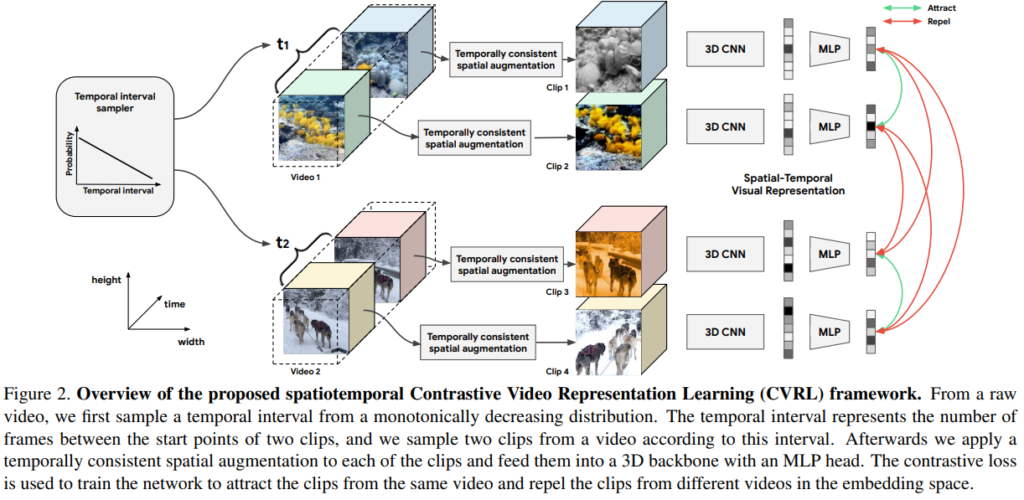
[그림 2]를 보면 CVRL의 학습 전략을 쉽게 파악할 수 있습니다. Contrastive learning을 하긴 하는데, self-supervised기 때문에 아무런 정보가 없죠? 그러니까 비디오 끼리 학습을 할때, 각 비디오 내에서 클립을 나누고, augmentation을 적용하여 비디오를 분할해서 비디오 마다 2개의 augmentation된 클립 쌍을 만듭니다. 그런 다음 그 쌍을 서로 positive / negative로 두고 학습을 진행하는 것입니다.
Video Representation Learning Framework
학습 자체는 많이들 들어보셨을 텐데요. InfoNCE Loss를 채용해서 사용했습니다. z_i, z_i^{'}를 각각 i 번째 비디오의 augmentation된 클립 2개라고 정의할 때, 아래와 같은 Loss function을 가집니다.
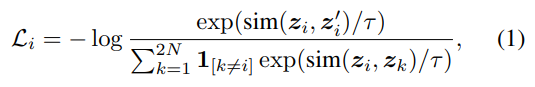
유사도 sim(z_i, z_i^{'})는 u^{T}v/||u||_2 ||v||_2로 L2 정규화된 두 벡터의 내적으로 계산합니다. 수식을 보시면 아시겠지만 cosine similarity를 사용한거고요. 사실 Loss 자체는 평범한데, 이 Loss에 넣어줄 입력이 이 논문의 핵심 같습니다.
Video Encoder
Encoder는 R3D를 사용했는데, 그냥 사용한 것은 아니고 여기에 SlowFast Network에서 쓰이는 slow pathway의 방법론을 따르고, 커널 사이즈 정도 바꾸는 수정을 거쳤다고 합니다. (Slow pathway 같은 경우에는 샘플링 크기는 변할 수 있긴 한데, 원본 논문 기준으로 16프레임마다 샘플링을 수행하는 것입니다.) 추가적으로 학습때만 Multi-layer projection layer를 추가해서 백본의 output을 128 차원으로 인코딩해서 학습합니다. 평가때는 백본 output 2048차원의 벡터를 바로 사용하고요. 이건 SimCLR에서 제안한 방법이라고 합니다.
Data Augmentation
이 논문의 중요한 부분이자… 제 학습 실험에도 중요한 부분입니다. 논문에서는 이 부분을 temporal 과 spatial로 나누어 설명합니다.
Temporal Augmentation
이 논문에서는 하나의 비디오를 클립 2개로 나눈다고 [그림 2]를 설명하면서 말했는데요. 그럼 그 클립은 어떻게 나눌까요? 여기서 이 클립을 자르는 방법에 대한 고민이 필요합니다. 비교적 클립을 멀리 잘랐다고 생각해보면, 길이가 긴 비디오의 경우에는 클립 안의 컨텐츠가 유사하지 않을 수도 있습니다. 그렇다고 아예 붙여서 2개의 클립을 사용하게 되면? 클립 끼리의 구별력이 없게됩니다.
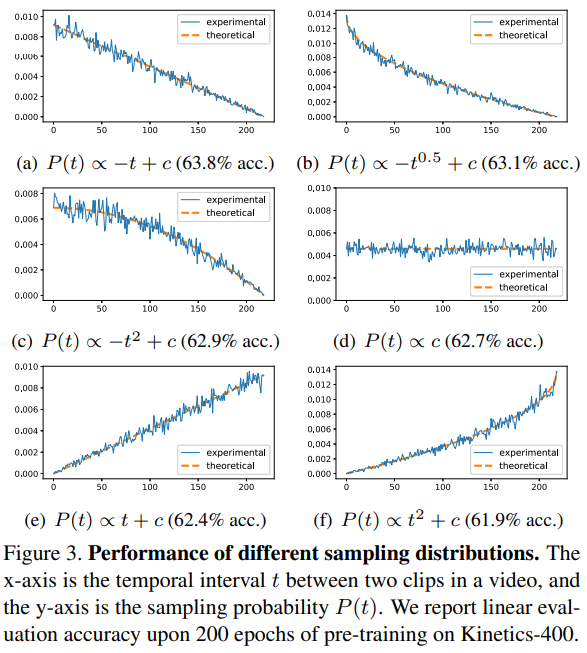
CVRL에서는 이 문제를 distribution에 달려있다고 생각했습니다. [그림 3]은 이러한 실험 결과인데요. 위의 표에서 X축은 비디오에서 두 클립 사이의 간격 t를 뜻합니다. 그리고 Y축은 t에 따른 샘플링 확률을 의미합니다. (비디오 클립 사이의 간격이 크도록 만들어질 확률이 적다는 뜻) 실험 결과 분포가 감소하는 형태의 [a-c]의 경우가 성능이 가장 좋았다고 합니다. 이 말은 결국 클립 사이의 거리가 멀어질수록 성능이 떨어진다는 뜻이 됩니다. 그래서 위의 논문 저자들의 주장(길이가 멀면 컨텐츠 구별력이 유사하지 않다)이 증명됩니다.
Spatial Augmentation
Spatial augmentation 자체는 이미 이미지에서 많이 쓰이고 있습니다. 문제는 비디오에서 어떻게 적용할지가 문제입니다. Random crop이나 color 변화 같은 방법은 temporal cue를 망가뜨릴 수 있다는 문제가 있기 때문입니다. 그래서 이 논문에서는 temporal 차원을 따라서 spatial augmentation을 한번에 적용합니다. 쉽게 생각하면 기존에는 프레임 단위로 랜덤 시드에 따라 적용되던 augmenation을 랜덤 시드를 고정해서 클립 단위로 한번에 바꿉니다.
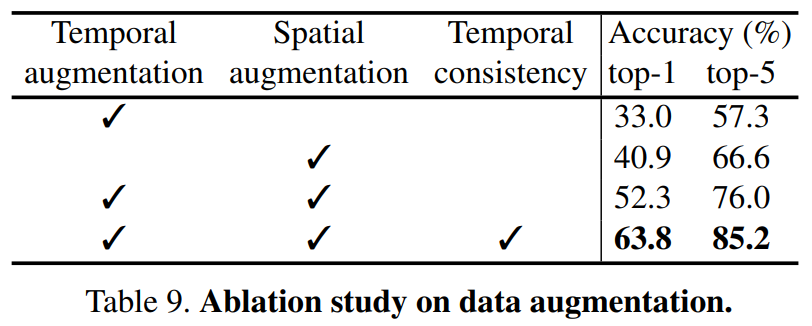
실제로 되게 간단해보이는 방법론인데 적용했을 경우에 [표 9]를 보면 성능 차이가 11% 정도로 상당히 있습니다. (Spatial augmentation이 체크된 상태에서 Temporal consistency가 있고 없고를 보면 됩니다)
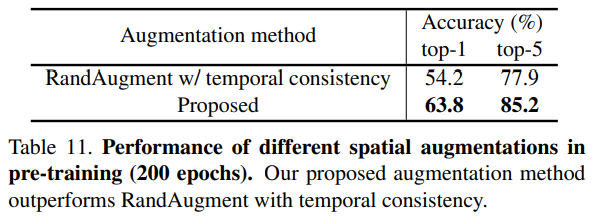
여기서 Temporal consistency가 중요해서 성능이 오른 것 아니냐고 생각할 수도 있는데요. Supplementary에 있는 추가 실험을 보면 그런 것이 아닌 것도 알 수 있습니다. Temporal consistency를 고려하는 random augmentation보다 제안된 방법론의 성능이 더 좋은 것을 볼 수 있습니다.

실제 적용 예시는 [그림 7]과 같습니다.
Experiments
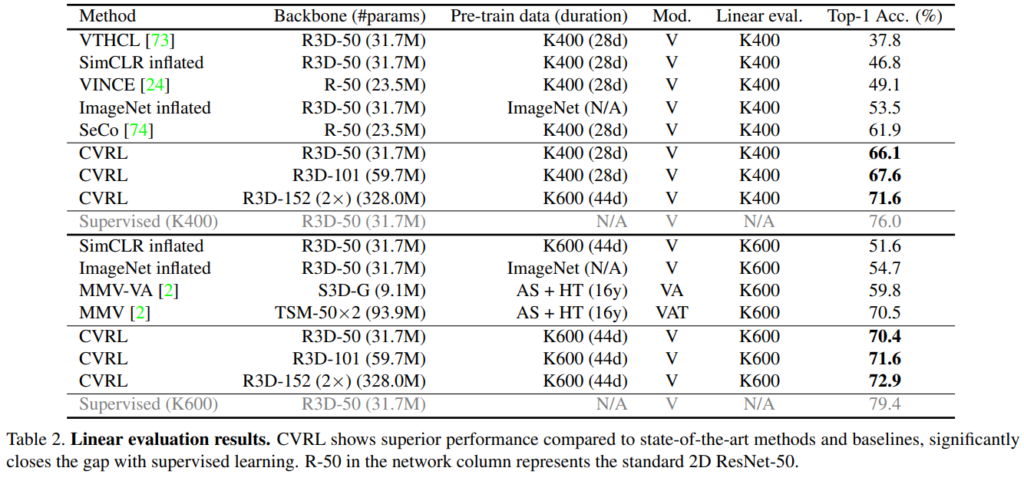
사실 self-supervised 방법론에 관심이 없어서 다 처음 보는 방법론이긴 한데요. Linear evaluation은 feature extractor에 linear layer 하나만 붙여서 성능을 측정하는 방법론으로 보입니다. 표현력 자체를 얼마나 잘 학습했는지 평가하는 방법 같네요. 모델 크기나 학습 데이터의 크기를 고려하면 확실히 큰 성능 향상을 보여주고 있습니다. AS+HT 같은 경우에는 HowTo100M이나 YouTube8M 같이 대용량 데이터셋을 다 합쳐 부르는 것인데요. 다 합치면 학습 양의 차이가 어마어마하게 나는데도 불구하고 CVRL이 훨씬 더 적은 데이터로 더 좋은 성능을 보이는 것을 볼 수 있습니다.
Conclusion
Self-supervised 관점에서 더 심오한 분석이 있는데, 제가 필요했던 부분은 학습 전략에 관한 부분을 가져다 써야해서 그 부분만 중점적으로 리뷰했습니다. 생각보다 더 간단한 방법론이어서 적용할 때 어려움은 없을 것 같은데… 실제로 해보면 어떨지 모르겠네요.
안녕하세요 좋은 리뷰 감사합니다.
contrastive learning 중 학습이 잘 안되시어 위 논문의 augmentation 방법론을 차용하신다는 것으로 이해하였는데,
그렇다면 기존의 학습에서는 어떤 방식으로 positive와 negative 쌍을 만들어주셨던건가요?
일단 VCDB에서 positive/negative를 만드는 방법에 대해서는 ViSiL 논문에 나와있습니다. 결국은 실제로 간단한 모델로 유사도를 계산해서 가장 유사한 비디오 쌍에 대한 가장 유사하지 않은 비디오 후보군을 만들어주는 작업을 거쳐서 positive/negative triplet을 생성하는데요. 지금 학습하는 방법의 경우에는 같은 물체 중심 데이터셋이라, 같은 카테고리 내의 비디오면 positive로 두고 다른 카테고리의 비디오들 중에서 negative를 선택하는 형식입니다.
CVRL 방식은 untrimmed video 기반의 데이터 셋에서도 잘 작동하나요?
일단 논문에서는 trimmed video라는 가정을 가지고 실험을 수행하는 것으로 보입니다.
안녕하세요 좋은리뷰 감사합니다
리뷰를 읽다가 하나가 궁금해졌는데
Spatial Augmentation에서 먼저 color를 통해 temporal cue가 망가지는 경우가 궁금합니다
둘째로는 Spatial Augmentation에서 frame을 따라 모두 crop을 적용해준다고 하셨는데 해당 부분에 action이 포함되어 temporal cue가 망가지는 경우가 생길수도 있지 않나요? 먼저 action 영역을 예측한 후 해당 영역을 보존하여 autmentation 하는 접근도 있는지 궁금합니다
감사합니다
Spatial Augmentation에서 먼저 color를 통해 temporal cue가 망가지는 경우에 대해서는 [그림 7]의 가운데 예시를 보면 될 것 같습니다. 두번째 질문에 대해서는 crop 하는 영역에 대해서 특정 action 영역이 포함되어서 temporal cue가 망가진다는 가정을 하기 시작하면, 기존의 방법론(temporal cue에 대한 고려 없이 random crop 하는 방법)에서도 역시 똑같이 문제가 있는 부분이기 때문에 이 방법론에서 고려할 부분은 아닌 것 같습니다.