제가 이번에 리뷰할 논문은 deblurring과 관련된 논문입니다. 이 논문을 읽게 된 이유는 위치인식 과제에서 motion blur를 해결하기 위한 방법론으로 DeblurGAN-v2 방법론이 있었는데 이 방법론은 2019년에 발표된 방법론이므로 최근에 어떤 연구가 있었는 지 궁금하여 찾아보다 읽게 된 논문입니다.
Abstract
블러한 이미지로부터 선명한 이미지로 복구하는 것을 목표로 하는 이미지 deblurring을 위해 기존에는 encoder-decoder구조를 활용한 복잡한 네트워크를 이용했다. 그러나 receptive field 확장을 위한 반복적인 upsampling 과 downsampling으로 인해 texture 정보가 손실되기도 하고, 여러 단계를 거치도록 디자인 되어 수렴이 어려워지기도 한다. 따라서 dilated convolution을 활용하여 receptive field를 높여 upsampling과 downsampling을 줄이고 spatial resolution을 높인다. 또한, wavelet transform을 이용하는 새로운 모듈을 제안하여 명확한 high-frequency 텍스처 정보를 복구한다.
Introduction
이미지에 접근성이 높아짐에 따라 blur한 이미지들이 다양한 방식으로 얻어진다. 따라서 blur를 제거하고 선명한 이미지를 얻는 것이 중요해졌다. 그러나 이미지 blurring은 일대다문제(1이 clear한 이미지, 多가 블러한 이미지)이므로 어려운 테스크이다. 기존에는 clear한 이미지와 blur한 이미지 쌍 사이의 함수를 찾기 위해 최적화 기반의 방법과 학습 기반의 방법론이 연구되어왔다. 대부분의 전통적 deblurring 방식은 blur 커널을 추정하는 것이지만, blur는 복잡하기 때문에 blur 커널을 찾는 것이 어려웠고, 부정확한 커널로 인해 제대로 복원되지 못하였다.
CNN 기반 방법론들의 연구를 통해 이미지 deblurring은 상당한 발전을 하였다. 그 중 GAN 기반의 DeblurGAN과 DeblurGAN-v2는 적대적 학습을 기반으로 하여 텍스쳐 정보를 복구 하는 등의 연구들이 있었으나 여전히 단일 이미지에 대한 deblurring은 다음의 문제가 있었다.
- 다양한 receptive field를 학습하기 위한 encoder-decoder 구조는 upsampling 과 downsampling과정을 거치며 texture의 디테일한 정보를 잃게 만들어 이미지 복구를 어렵게 한다.
- 그림 1-(b)와 같은 GAN 구조는 texture의 디테일한 정보를 얻을 수 있으나 훈련을 위해 discriminator와 generator를 함께 학습해야 하므로 불안정하다는 문제가 있다.
- 그림 1-(c)와 같은 coarse-to-fine 구조는 복잡하고 연산량이 많아 모델의수렴이 느리다.
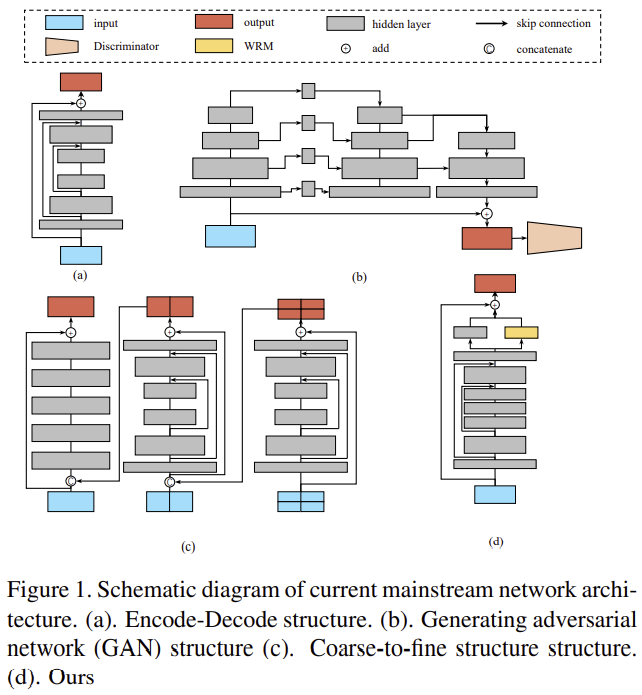
해당 논문은 dilated convolution 과 wavelet transform을 이용하여 앞에 제시한 문제들을 해결하고자 하였다. 그림 1-(d)가 해당 논문에서 제안하는 아키텍처로, wavelet 도메인에서 간단고 효율적으로 학습할 수 있는 CNN 모델을 제안하였다. dilated convolution 모듈은 receptive field를 키우도록하고, wavelet reconstruction 모듈은 주파수 영역의 특성을 활용하여 추가 정보를 제공함으로써 spatial 도메인을 재구성한다.
해당 논문의 contributio은 다음으로 정리할 수 있다.
- dilated convolution 모듈을 제안하여 upsampling과 downsampling을 사용하지 않고 다양한 receptive field에 대한 학습을 하며, 네트워크가 로컬이 아닌 feautre를 포착하고 깨끗하게 이미지를 복원할 수 있도록 한다.
- wavelet reconstructon 모듈을 제안하여 단일 공간 및 주파수 도메인에서 deblurring을 하는 것이 아닌, 주파수 도메인에서 복구한 정보를 이용하여 공간 도메인을 보완함으로써 이미지 복구에 더 많은 high-frequency detail이 포함되도록 한다.
- 새로운 CNN 기반의 deblurring 방법론을 제안함으로써, 간단하고 효과적인 네크워크를 통해 SOTA와 경쟁력 있는 성능을 보인다.
wavelet transform?
wavelet transform은 이미지의 고주파 정보와 저주파 정보를 분리하고 가역적이므로 image processing에 많이 사용된다. wavelet transform을 적용하여 blur한 이미지에서 주파수 정보를 분리한 뒤 이미지를 복구하여 이미지의 feature를 스무스하게 한다.
Proposed Method
1. Framework
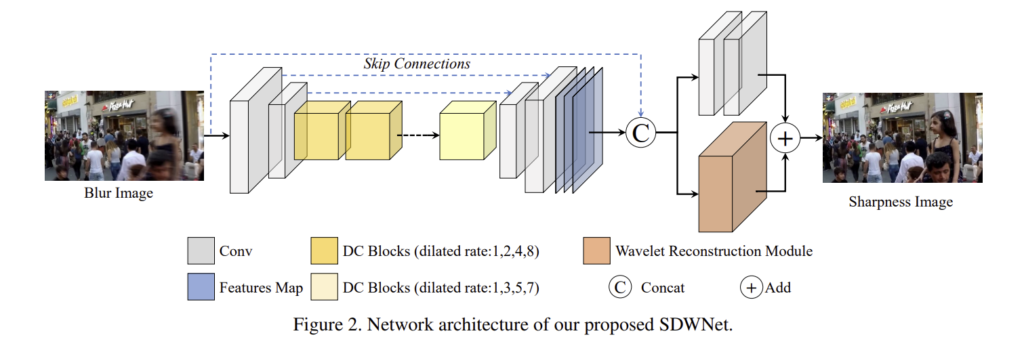
복잡한 구조는 불안정한 학습과 느린 수렴과 같은 문제를 가져올 수 있으므로 그림2와 같이 단순한 네트워크 구조를 사용하였다. SDWNet은 3가지 부분(feature를 추출하는 부분, dilated convolution(DC)모듈, 복원 모듈)으로 이루어져 있다. 더 큰 영역을 보기 위해 7×7 커널 크기를 이용하여 얕은 단에서 특징을 추출한다. 이후 다양한 receptive field 정보를 합치기 위해 dilated convolution 블록을 제안하였다. 이후 고주파 정보를 복원하는 효과적인 방법인 wavelet transform을 이용하여 최종 출력 영상의 미세 texture를 복원한다.
이때, 풍부한 receptive field를 얻기 위해 확장 비율이 다른 두 convolution 블록을 이용하였고, 이미지의 외관 정보를 최대한 활용하기 위해 skip connection을 추가하였다. 4개의 주파수 서브밴드를 직접 예측하는 wavelet transform 방식 대신 이 논문은 공유 네트워크를 이용하여 4개의 주파수 서브밴드를 별도록 복구하여 서로 다른 주파수 서브밴드의 상호작용으로 인한 아티팩트를 피한다.
blur 이미지가 \mathbf{I}_{blur}라 하고 residual image가 \mathbf{R}이라 했을 때\mathbf{R} 이미지에 \mathbf{R}를 더하여 이미지를 예측한다: \mathbf{X} = \mathbf{I}_{blur}+\mathbf{R}. SDWNet 는 다음 loss를 이용하여 학습한다.
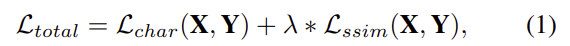
\mathbf{Y}는 GT 이미지를 나타내며, Charbonnier loss \mathcal{L}_{char}는
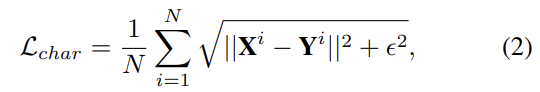
로, ϵ는 10^{-3}로 설정된 상수이며 ssim loss \mathcal{L}_{ssim}는 다음과 같이 정의된다.
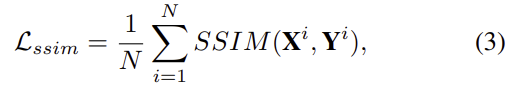
식(1)의 λ는 SSIM loss를 제어하기 위한 하이퍼파라미터이다.
2. Dilated Convolution Module
DC(Dilated convolution) 모듈은 n개의 dilated convolution blocks(DCB)이 있을 때 다음과같이 수식화 할 수 있다.
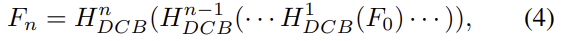
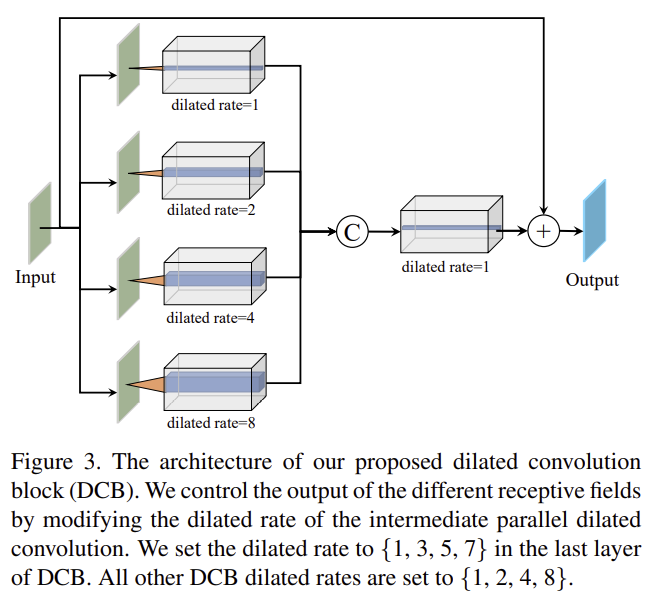
H^n_{DCB}는 n번째 DCB로, F_n과 F_1은 각각 DC 모듈의 input과 output을 나타낸다. DCB는 여러 dilated rate를 가진 convolution이 병렬적으로 구성되어있다.(그림3) 얕은 레이어는 1,2,4,8과 같이 규칙적인 비율을 이용하고, 마지막 레이어는 gridding effect(일정한 비율로 커지다 보니 보는 곳은 겹치고 보지 않는 곳은 보지 못하는 문제를 의미합니다.)를 피하기 위해 1,3,5,7의 dilated rate을 적용하였다. 이후 dilated rate이 1인 dilated convolution을 이용하여 서로 다른 receptive field를 가지는 feature들을 융합한다. 마지막으로 퓨전된 feature에 input feature를 중첩한다.
3. Wavelet Reconstruction Module
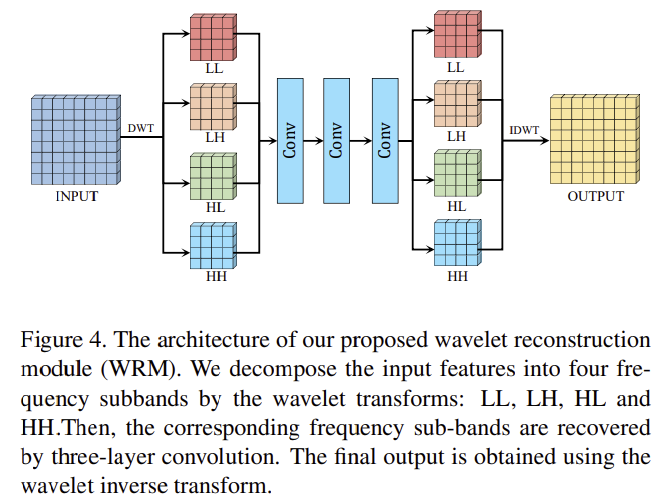
wavelet reconstruction 모듈(WRM)은 wavelet transform을 이용하여 공간 도메인 정보를 복구하기 위해 wavelet 도메인으로 변환한다. 그림 4와 같이 input feature는 4개의 sub-band 주파수로 나뉘며 다음과 같이 정의할 수 있다.
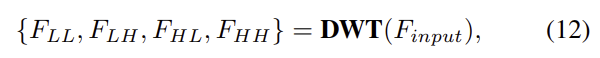
/mathbf{DWT}(·)는 이산 wavelet transform을 의미하고 F_{LL}, F_{LH}, F_{HL}, F_{HH}는 각각 4개의 주파수 sub-band feature를 의미하고, 서로 간섭을 피하고 이미지를 복구하기 위해 4개의 sub-band는 각각 3-layer를 통과한다. 마지막으로 discrete wavelet inverse transform을 이용하여 복구된 sub-band들의 output feature를 이용하여 output을 구한다.
Experiments with Analysis
Dataset
- GoPro
- GoPro Hero 4 카메라를 이용하여 240fps로 촬영하고, 연속적인 단시간 노출 프레임의 평균을 이용하여 blur한 이미지를 생성한다.
- motion blur의 일반적으로 사용하는 벤치마크로 3214장의 blurry/clear 이미지 쌍을 포함한다.
- 2103쌍을 학습에 1111쌍을 평가에 사용한다.
- HIDE
- human-aware 모션 deblurring을 위해 수집된 데이터이다.
- 2025개의 이미지가 있다.
- RealBlur
- 2가지 하위 집합이 있으며 RealBlur-J는 카메라 JPEG 형식으로 출력하고, RealBlur-R는 RAW 이미지에 화이트 밸런스, demosaicking 및 denoising를 적용하여 생성된다.
Dataset Sliding Crop
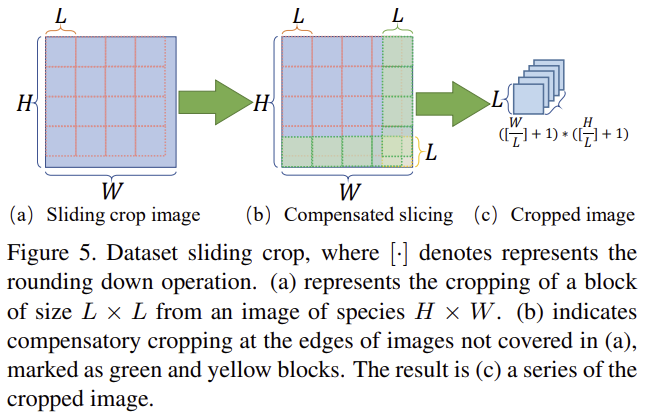
네트워크를 강인하게 학습시키기 위해 이미지에 그림 5와 같이 sliding window를 수행한다. GoPro 이미지는 1280 × 720해상도의 이미지로 240 step을 적용하여 480×480크기의 sliding window를 수행하여 각 이미지에서 24개의 패치를 추출한다. 이 과정을 통해 원래 데이터셋에서 최대 50472개의 패치를 얻을 수 있다.
Image Deblurring Results
정량적 결과
PSNR과 SSIM의 평균 성능을 정량적으로 평가하였다.
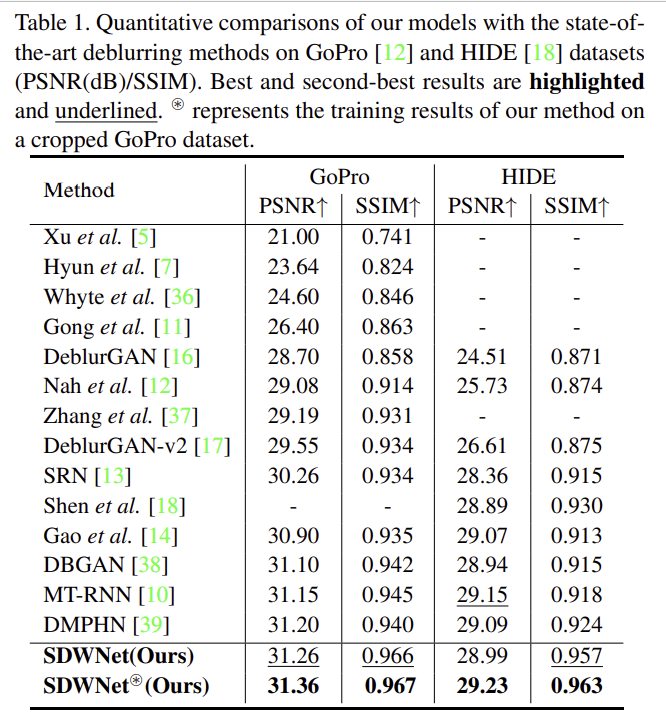
SDWNet의 성능을 기존의 우수한 방법론과 비교한 결과가 위의 표 1로 다른 방법론들과 비교했을 때 가장 좋은 성능을 달성한 것을 확인할 수 있다. GoPro 뿐만 아니라 HIDE에서도 모두 최대 성능을 달성하였다. 또한 SDWNet이 실제 상황에서도 잘 작동하는 지 일반화 성능을 입증하기 위해 아래의 표 2에 RealBlur 데이터셋에 대한 검증 결과를 리포팅하였다.
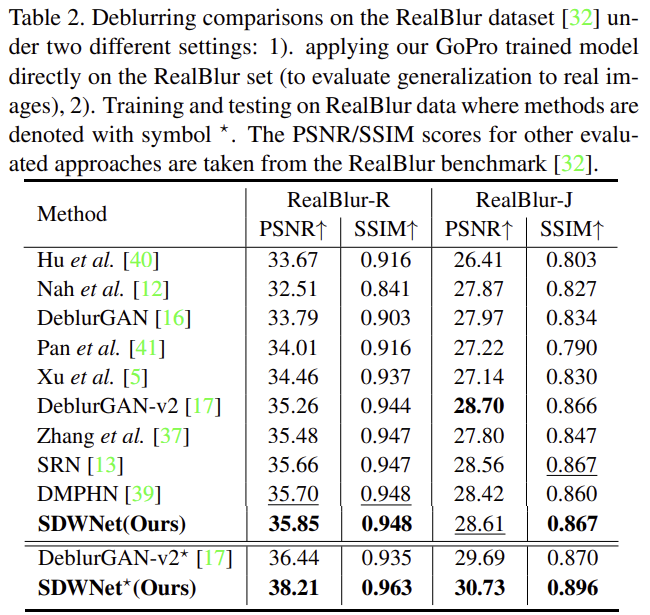
위의 표 2를 통해 확인할 수 있듯이 실제 상황엥서 촬영된 데이터에 대해 SDWNet은 RealBlur-R에서 최대 성능을 달성하였고, ReaslBlur-J데이터에서 경쟁력 있는 성능을 달성하였다.
정성적 결과

그림 6은 deblurring 효과를 확인하기 위한 정성적 결과로 세부적인 부분을 확대하였다. 두번째 이미지를 보았을 때 다른 방법론의 복구 영상은 모두 여전히 blur한 반면, SDWNet 방법론을 적용한 이미지는 이미지를 정확하게 잘 복구한 것을 확인할 수 있다.
Performance and efficiency comparison

3번째 contribution이 간단하고 빠르게 수렴한다는 것이므로 파라미터와 FLOPs를 비교하였다. 다르 방법론들에 비해 PSNR과 SSIM이 경쟁력 있는 성능을 보이며, 하이퍼 파라미터 개수와 FLOPs가 훨씬 작다. 이를 통해 제안된 SDWNet이 효율적으로 deblurring 성능을 높였다는 것을 확인할 수 있다.
Ablation Studies
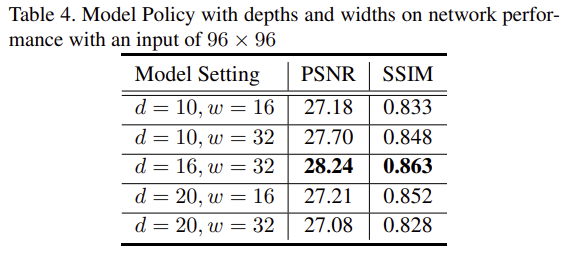
각 모듈의 유효성을 검증하였다. 표 4는 depth와 width를 다양하게 조절하여 네트워크의 성능을 확인하였다. depth보다 width가 성능에 더 큰 영향을 주는 것을 확인할 수 있었고, 최대 성능을 보인 d=16, w=32를 최종 모델의 depth와 width로 설정하였다.
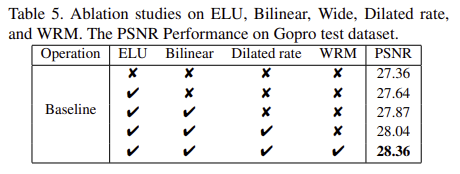
ELU활성화 함수와 bilinear upsampling 방식, DC모듈의 마지막 레이어의 확장 비율, WRM(wavelete reconstruction module)의 유효성을 검증하였다.
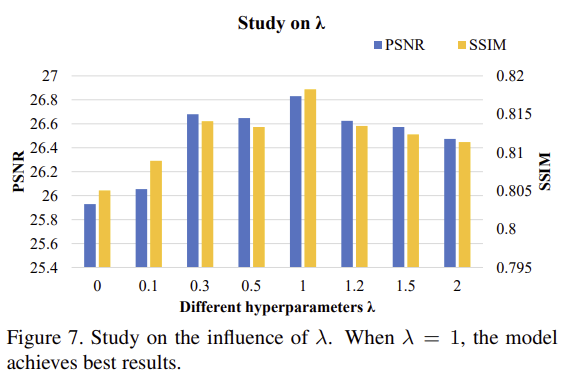
loss의 SSIM을 조절하는 λ의 값을 조절하여 최적의 파라미터값을 찾았다그 결과 1일 때 최대의 성능을 얻음을 확인하였다.
좋은 논문 리뷰 감사합니다.
해당 논문의 메인 컨셉이 기존 방법들은 컨텐츠 손실이 있기에 주파수 레벨에서 복원하자는 것 같습니다.
근데 제가 지식이 부족해서 그러는데 해당 방법론도 결국엔 주파수 레벨에서 인코더 디코더 구조로 복원하는 것 같은데 어째서 컨텐츠를 더 잘 복원하는 건가요?
기존의 Encoder-Decoder 방식이 up-sampling과 down-sampling을 통해 해상도가 줄어들었다 커지는 과정에서 손실이 생긴다고 판단하여 해상도는 유지하고 dilated convolution을 활용하여 다양한 receptive field를 보기 때문에 컨텐츠를 더 잘 복원할 수 있다고 저자들은 이야기합니다.