이번에 제가 리뷰할 논문은 Timm Linder라는 저자가 작성한 논문으로, 저자는 현재 보쉬에서 일하고 있습니다.
제가 2주전에 발표했던 yolo기반의 detection 및 centroid regression과 동일한 저자이며, 해당 연구에서는 intralogistics 도메인에서의 human detection을 다루고 있습니다.
좀 더 구체적으로 페이퍼에서는 멀티모달 센서들을 사용하여 intralogistics에서 사람 검출을 수행하는데, 어떠한 멀티모달 센서 조합이 가장 최적의 솔루션이 될까? 라는 질문에 대답하기 위해 연구를 진행합니다.
먼저, 저자가 말하기를 사람검출 분야에서 main stream을 이루는건 보통 autonomous driving cars를 위한 경우라고 합니다. 그래서 대부분 알고리즘과 센서셋업이 driving conditions에 맞게 되어있는 경우가 많으며, 논문에서 다루는 것처럼 도메인이 다른경우 성능드랍이 많이 생깁니다. 이말은 즉슨 기존의 SOTA모델을 사용해도 도메인이 바뀌면 새로운 도메인에서는 잘 워킹하지 않을 수 있다는 소리가 됩니다.
이러한 domain gap은 단순히 환경적인 요소만 작용하지 않습니다. 같은 driving scene이라고 하더라도 센서의 종류에따라 다르고, 센서를 어떤식으로 배치했는지에 따라 또 다릅니다. 그 밖에도 날씨나 조도같은 환경적 변수와 지형, 촬영장소 등 지리적변수도 domain gap을 야기시킵니다.
이러한 문제점을 다루기 위해서, 특히나 main stream이 아닌 도메인에서의 사람검출을 하기위해서 저자는 기존의 knowledge를 transfer하여 적절히 활용하는 것이 필요하다고 합니다. 그래서 제가 지난번에 발표했던 저자가 직접 제안하였던 yolo기반의 2.5 검출모델을 통해 사람을 검출하고, 검출된 사람의 centroid를 regression한 정보를 활용하며, 이러한 prior knowledge를 이용해서 3D 포인트 클라우드상에서 사람을 검출하는 방법을 제시합니다.
즉, 본 논문에서는 멀티모달 센서들(2D 라이다, 3D 라이다, RGB-D)센서와 SOTA 알고리즘들을 적절히 활용하여 도메인이 바뀔때 어떠한 조합이 가장 좋은지에 대한 분석을 수행합니다. 그리고, 기존에 제안했던 yolo기반의 2.5D 검출기를 확장하여 도메인이 바뀔때 어떤식으로 활용할 수 있는지 보여줍니다.
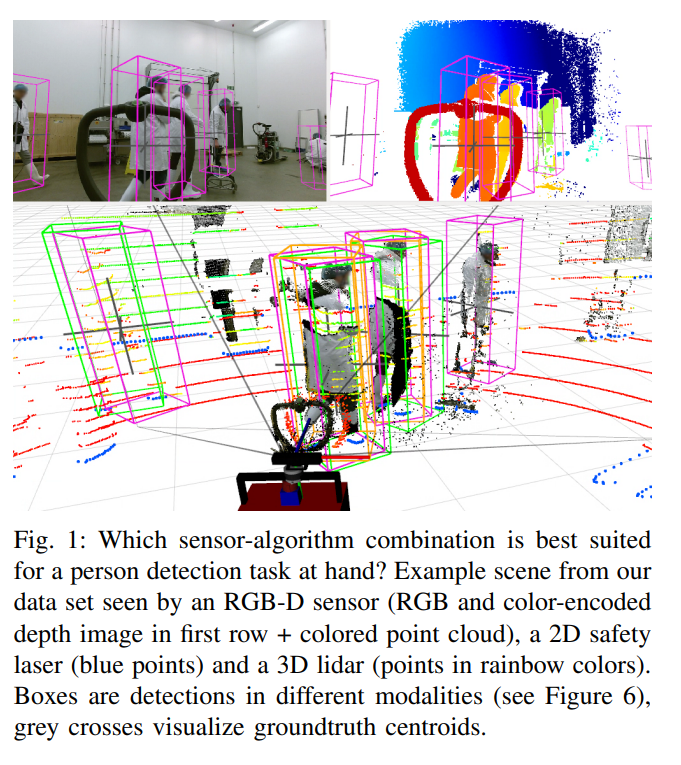
위의 그림1은 실험결과를 직관적으로 잘 보여줍니다. 그림에서는 포인트클라우드 데이터와 corresponding하는 RGB영상과 depth영사을 보여주고 있습니다. 보이시는 것처럼 색깔에 따라서 포인트 클라우드상에서 얼마나 사람을 잘 검출하나 보여주고 있습니다. 각 색깔이 무슨 모달리티를 의미하는지는 위의 캡션을 참고하시기 바랍니다.
참고사항으로 모델의 결과값은 bbox의 centroid좌표인 x, y, z와 centroid로 부터 어느정도의 크기인지를 나타내는 w, h, d 및 bbox가 얼마나 회전되어있는지 나타내는 회전각입니다. 이때, 회전각은 yawing에 대해서만 다루고 있으며, 사람의 bbox는 항상 지면에 수직으로 서있다고 가정합니다. 이러한 가정은 사실 자율주행분야에서 DoF를 줄여서 문제를 보다 쉽게 풀기위해 많이 사용 되는 가정이며 reasonable 해보입니다. 또한, bbox가 지면을 뚫고 들어가는 케이스에 대해서는 지면에 닿는 높이까지만을 고려하고 나머지는 ignore하였습니다. 기존에도 이러한 평가방법을 사용하고 있었으므로 fair comparison을 위해 그렇게 사용하였다고 합니다.
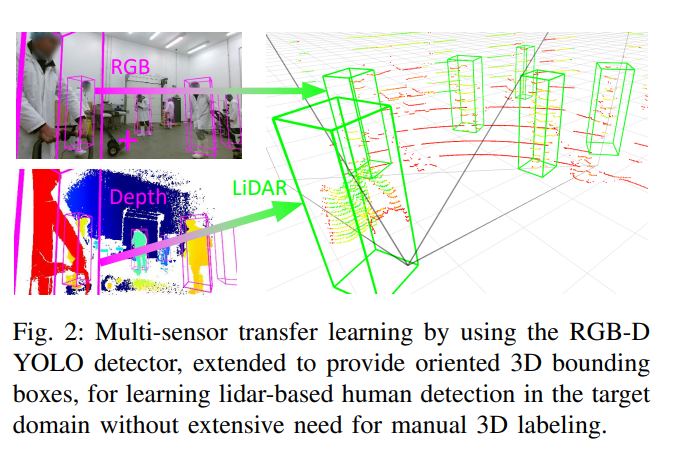
모달리티에 따른 성능비교와 더불어서 본 논문에서 주장하는 알고리즘적 contribution에 대해서 설명드리겠습니다. 본 논문에서는 위의 그림 2처럼 RGB-D카메라로 부터 취득한 RGB영상과 Depth영상을 이용하여 1차적으로 detection을 하고 해당 정보를 라이다 기반의 3D 검출기에 전달하는 방식을 사용합니다. 이때, 1차 detection을 위한 모델은 synthetic dataset에서만 학습되며 이는 제가 2주전에 발표했던 yolo기반의 2.5D detection에서 설명하였습니다. 다시 간단히 설명드리자면, 시뮬레이션 상에서 모델 학습을 위한 데이터를 만들고, 그 데이터를 이용하여 yolo기반의 2.5D detector를 학습하였습니다.
즉, 다시 정리하자면, 본 저자는 이전 연구인 yolo기반의 2.5D detector를 좀 더 확장하여 bbox의 w, h, d 과 yaw angle을 추가로 regression하는 모델을 설계하였습니다. 그리고, 해당 모델을 synthetic 데이터셋에서만 학습하여 라이다기반의 검출기를 가르치기위한 teacher 모델로 사용하였습니다. 이러한 과정을 거치면서 domain gap이 발생해도 weak-supervision만으로 성능을 끌어 올렸습니다. 전체적인 파이프라인은 아래와 같습니다.
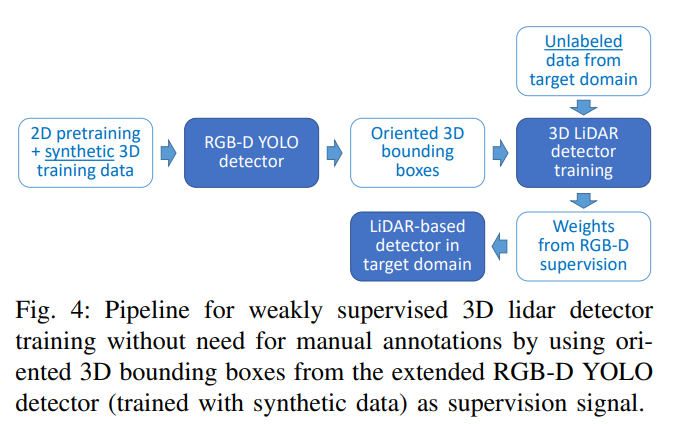
위의 그림4 에서는 제가 설명했던 내용을 그림으로 잘 보여줍니다. 결국에 최종적인 목표인 LiDAR-based Detector를 학습시키기 위해 synthetic data로 학습한 RGB-D YOLO Detector를 사용하였습니다.
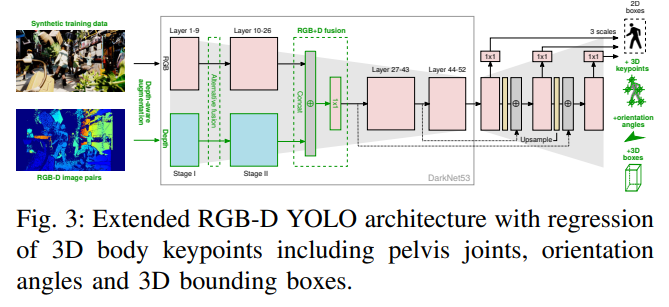
사용한 RGB-D YOLO detector의 파이프라인 입니다. 사실 특별할건 없고 욜로3의 기본적인 구조를 멀티모달 영상입력에 맞게 변형하여 설계하고, 아웃풋을 3D bbox에 맞게 바꾸어준 것 뿐입니다. 아키텍쳐에 대해서 더 궁금하신 분들은 제가 이전에 했던 리뷰 를 참고하시면 될듯합니다. 간단히만 말씀드리자면, 그냥 미들레벨에서 서로다른 모달리티를 concat하고 1×1 conv를 이용해 downscale하였습니다. depth-aware augmentation 등 추가적인 내용이 있긴한데 그러한 내용은 위에 링크걸어둔 리뷰를 참고해주세요.
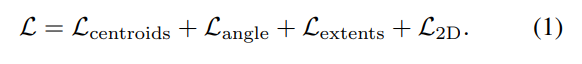
RGB-D YOLO의 loss함수는 심플합니다. 기존에 사용했던 거와 2D loss / centroid는 동일하며 w, h, d regression loss에 해당하는 extents의 경우 단순 l1 loss를 사용합니다. 이는 실험을 통해 얻어진 결과라고 합니다. yawing을 나타내는 angle에 대해서는 cos, sin으로 representation 하였으며, loss로 cosine similarity loss를 사용합니다.

전체적인 시스템은 위와 같이 구성하였으며, 센서는 총 3가지를 사용하였습니다.
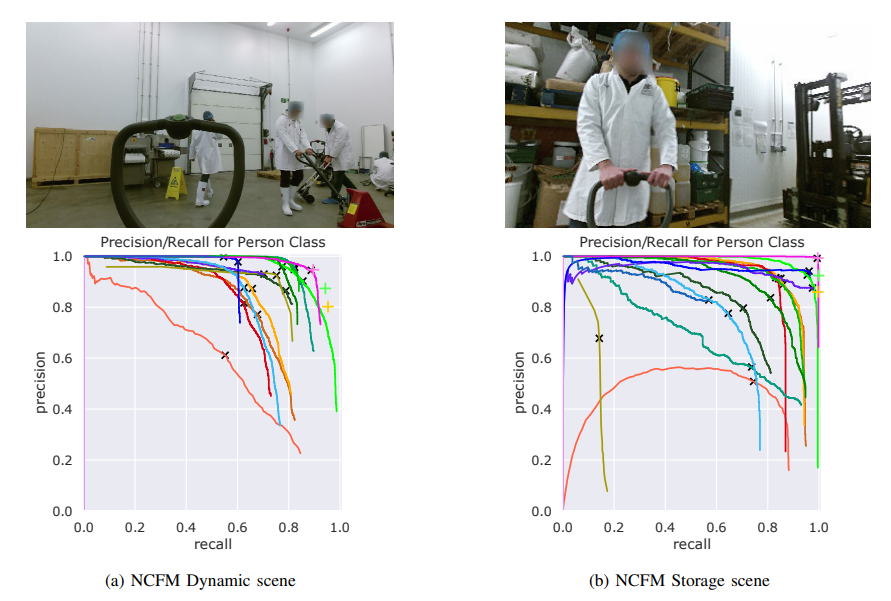
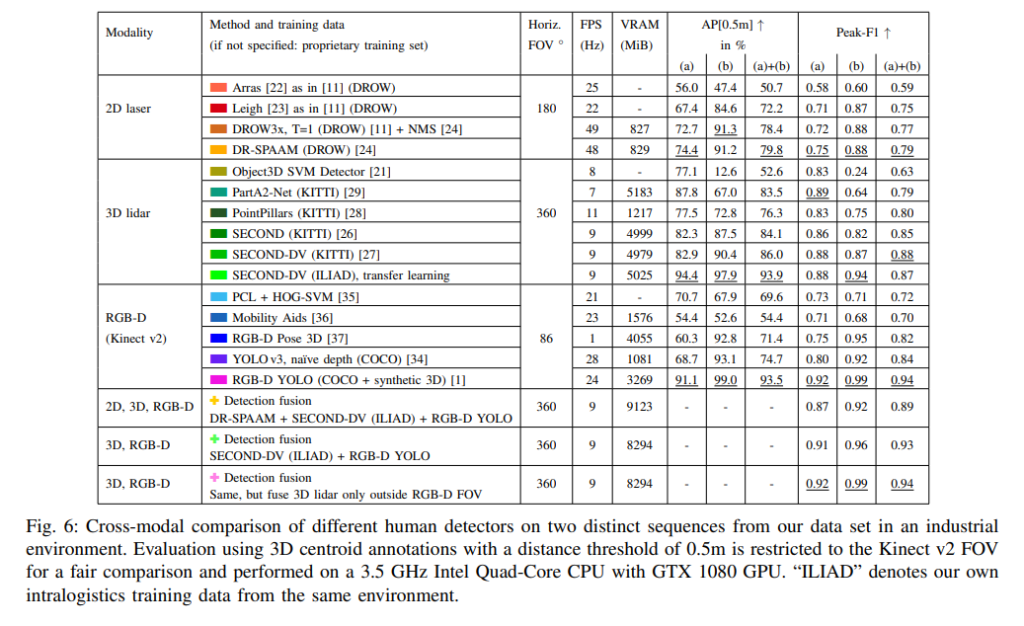
각 모달리티마다 대표하는 SOTA 방법론들을 이용해서 구한 결과와 논문에서 제안하는 방법론을 이용해서 구한 결과를 비교하는 실험을 하였습니다. 이로써 domain이 달라졌을때, 제안하는 방법이 효과를 가지는 것을 입증하였습니다. 맨 아래 행에서 2번째를 보면 논문에서 제안하는 RGB-D YOLO를 이용해서 LiDAR-based 방법론인 SECOND-DV를 이용하였을때 좋은 결과를 보였습니다. 그리고 여기에 추가적으로 RGB-D FoV를 벗어나는 경우 영역에서는 lidar를 추가로 사용하여 보완하였을때 성능이 더 올라 f1 스코어 기준 가장 좋은 결과를 보였습니다. 그런데 RGB-D 데이터만을 사용했을 때의 결과도 동일하네요.
결국에 위의 테이블에서 정리한 것처럼 모달리티에 따라 SOTA 모델들을 사용하여 비교실험을 하였으며, 결과만 놓고 보자면 2D 라이다를 쓰는게 오히려 노이즈로 작용한다고 생각을 해야될거 같네요. 또한 실험결과만 놓고 보자면 굳이 3D 라이다를 사용하지 않고 RGB-D 센서만을 사용해도 intralogistics에서는 충분해 보이네요. 다만, 실험데이터셋이 공개되지 않았고 성능이 saturation된 점을 고려할 때 실험 결과를 신뢰할 수 있는지에 대한 아쉬움이 남네요. 좀 더 챌린징한 데이터셋에서는 경향성이 다를 수도 있으니까요.
개인적인 생각으로는 해당 논문의 목적성이 새로운 도메인에서 어떠한 모달리티의 조합이 베스트이냐? 인데, 전이학습을 이용한 경우와의 비교가 적고 실험 대부분이 일반적인 세팅에서 모달리티만 다른경우라 아쉽네요. 또한 domain adaptation도 고려했으면 더 좋았을거 같고요.