Before Review
이번 논문은 Weakly Supervised Temporal Action Localization로 읽었습니다.
개인적으로는 Code가 공개되지 않아서 아쉬움이 드는 논문입니다. 방법론이 인상 깊어서 원복을 해보려고 코드를 짜보고 있는데 K-Means에서 막혔네요. GPU를 이용해도 K-Means가 너무 오래 걸리는 거 같은데 저자는 어떻게 처리했는지 궁금하네요.
무튼 이번 논문의 키워드는 1) Contrastive Learning 과 2) Pseudo Labeling 입니다.
리뷰 시작하겠습니다.
Introduction
Weakly Supervised Temporal Action Localization(이하 WTAL)은 제가 이전 리뷰에서도 많이 다뤘기 때문에 자세히 설명하지는 않겠습니다. 제대로 이해하고 싶은 분이 있다면 저의 이전 리뷰들을 차근 차근 읽어보는 것을 추천 드립니다.
Weakly Supervised Temporal Localization(이하 W-TAL)은 Snippet Level의 Feature를 추출하고 Temporal-Class Activation Sequence (이하 T-CAS)를 생성하여 thresholding을 거쳐 Localization을 수행하는 것이 일반적인 Process 였습니다. 그리고 T-CAS를 이용하여 Video-Level의 Score vector를 만들고 Video-level에서의 Classification을 수행하여 Video level의 classification에 도움이 되는 snippet을 찾아서 grouping 하는 것이 핵심이라 볼 수 있습니다.
그런데 Video-level 만을 가지고 Classification으로 T-CAS를 학습시키게 되면 당연히 한계가 존재합니다. 그래서 WTAL 관련 논문들은 다양한 방식으로 Classification이 아닌 다른 Loss function을 정의해서 좀 더 T-CAS를 정교하게 학습을 시킵니다.
예를 들면 Attention 기반의 방식을 사용하여 Foreground-Segment와 Background Segment를 구분하는 attention weight를 학습시켜 T-CAS를 좀 더 잘 만들기도 합니다. 또한 비슷하게 Contrastive Learning을 이용하여 Foreground Feature와 Background Feature의 representation을 학습시켜 좀 더 discriminative한 embedding space를 학습시키기도 합니다.
이것 말고도 다양한 아이디어를 활용해 T-CAS를 좀 더 잘 만들기 위해서 많은 연구들이 진행됐고, 진행되고 있습니다.
여기서 본 논문은 Contrastive Learning에 집중을 합니다. 일반적으로 feature embedding space는 다음과 같은 성질을 가져야만 합니다.
- Action Snippet들은 Class에 상관없이 일단 Background Snippet과 분리 될 수 있어야 한다.
- Action Snippet들은 같은 Class라면 다른 Class feature에 비해 좀 더 가까워야 한다.
자 그러면 일반적인 Contrastive Learning의 framework를 도입하면 위의 embedding space를 학습할 수 있을 것 같습니다. 하지만 이전까지의 방법론들은 전체적인 global contrast를 적용하지 않았기 때문에 완전하게 feature를 분리할 수 없다고 얘기합니다. 무슨 소리인지는 아래의 그림을 통해서 확인하도록 하겠습니다.
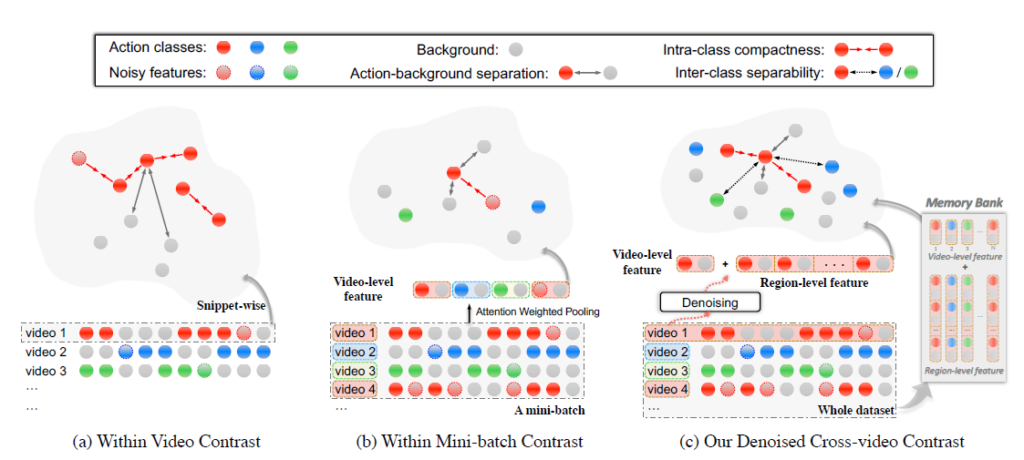
이전까지의 Contrastive Learning은 (a) 아니면 (b)의 상황을 가정하고 진행하게 됩니다.
(a)의 상황은 하나의 비디오에서만 Contrast를 다루는 경우 입니다. 단일 비디오 내에서 action과 background를 구분하고 positive / negative를 정의하여 contrastive learning을 진행합니다. 물론 안하는 것보다는 낫겠지만, Positive / Negative Pair가 다양하지 못해 embedding space를 완전하게 학습하기 어렵습니다.
(b)의 상황은 Mini-Batch 상황에서의 Contrast를 다루는 경우 입니다. Mini-batch이다 보니 단일 비디오만을 고려하는 것보다는 효과가 있지만 역시나 조금 아쉬운 상황입니다.
(c)의 상황이 저자가 제안하는 방식입니다. 위에서 (a) , (b)에 대한 설명을 보면 느낄 수 있습니다. 결국 전체를 봐야한다는 것 입니다. 우리가 Positive / Negative Pair를 구성할 때 데이터셋의 일부분만을 보고 구성하는 것이 아니라 전체를 보고 구성을 해야한다는 의미입니다.
전체 비디오에 대한 embedding feature를 다루다보니 무언가 저장할 공간을 따로 처리를 해줘야 할 것 같습니다. 그래서 저자는 Memory Bank를 만들어서 feature 들을 관리하게 됩니다.
일단 여기까지가 간단하게 Contrastive Learning 방향입니다.
이제 핵심은 어떻게 embedding feature를 정의하고 pair를 구성할 지 인데, embedding feature를 정의하는 과정에 Pseudo Label 개념이 들어가게 됩니다. WTAL 상황에서는 라벨이 비디오 레벨 밖에 없다보니, Classification으로 학습이 되는 데 이는 Localization task에 있어서 sub-optimal 한 상황이라 볼 수 있습니다. 즉, 원래 Localization task에 적합할 수 있게 구간에 대한 Pseudo-Label을 만들어내는 것이지요.
조금 두서 없이 설명했는데… 다시 차금차금 설명하도록 하겠습니다.
Method
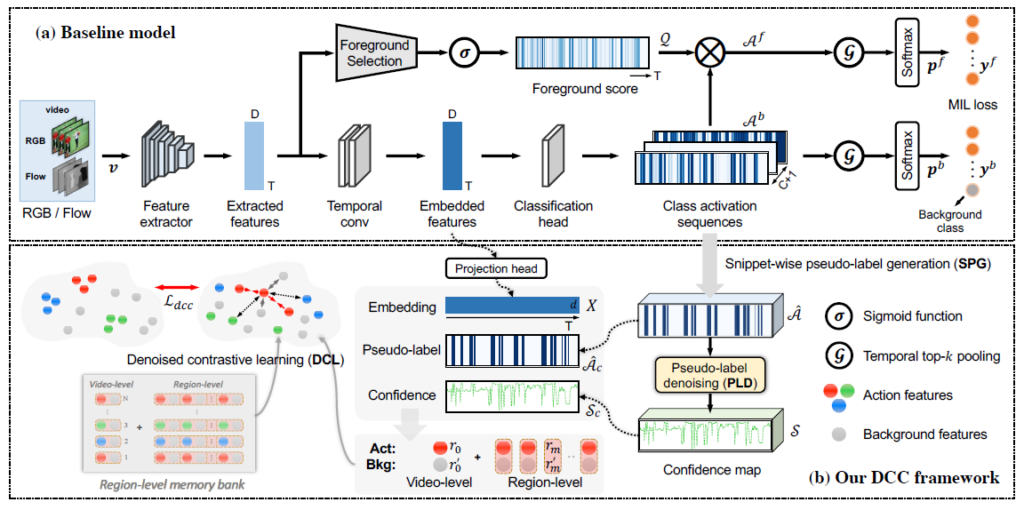
Baseline Setup
대다수의 WTAL 논문은 Baseline은 굉장히 간단하게 설계됩니다. 그냥 우리가 알고 있는 정보가 Video-level annotation 뿐이니깐 일단 Classification Loss로 베이스라인을 잡는 것이지요.
비디오 전체 구간에 대해서 Snippet-Level feature를 추출하고 이를 Embedding Layer를 거쳐서 T-CAS(Temporal-Class-Activation-Sequence)를 생성합니다.
T-CAS는 결국 비디오 구간 전체에 대해서 각 클래스에 대한 확률 분포를 의미합니다. 그리고 이를 잘 aggregate 해서 Video-level classification을 할 수 있습니다. 각 클래스 별로 확률이 높은 k개의 snippet 들의 확률을 평균 내서 video-level score vector를 만들게 됩니다. 그리고 Cross Entropy Loss로 Embedding Layer들이 학습된다고 보면 됩니다.
이 정도가 가장 간단한 베이스라인인데 저자는 여기에 Bas-Net의 구조를 그대로 사용합니다. 즉, Bas-Net을 베이스라인으로 사용한 것이라 보면 되는데, 두 가지 상황에 대해서 Classification을 한다고 보면 됩니다.
일단 일반적으로 우리가 사용하는 데이터셋은 모두 Untrimmed Video이기 때문에 항상 Background Class가 존재 합니다. 그렇기 때문에 Background Class에 대한 라벨은 항상 1로 고정시킬 수 있습니다. 근데 이렇게 되면 Background에 대해서 Negative Sample이 없기 때문에 수렴이 trival solution으로 빠질 가능성이 있습니다.
그래서 attention이 도입됩니다. attnetion의 목적은 background를 suppression하는 것으로 이상적으로 background가 suppression 되었다면 T-CAS에는 Background에 대한 확률 분포는 적어졌을 것이고, Background Class에 대한 라벨은 0으로 두는 것이 맞겠죠.
방금 제가 설명한 아이디어는 정확히 Bas-Net에서 제안한 아이디어와 동일합니다. 저자도 그 부분은 밝히고 있구요. 무튼 이에 대한 자세한 설명은 이전 리뷰인 Bas-Net에 있기 때문에 이 정도로 설명하고 이제 저자가 직접 제안한 모듈에 대해서 알아보도록 하겠습니다.
Denoised Cross-Video Contrastive Algorithm(DCC)
저자는 세가지 모듈을 추가적으로 제안합니다.
Snippet-wise Pseudo-label Generation
Pseudo-label을 생성하는 목적 자체는 다음과 같습니다. 우리가 Localization task이지 Classification task가 아니다. 결국 Localization이 조금 더 완전해지기 위해서는 Pseudo-label 이지만 구간에 대한 정보가 있어야 한다. 뭐 Pseudo-label 방법이야 Unsupervised 상황이나 Semi-superivsed 상황에서 자주 사용하기 때문에 목적 자체는 직관적으로 받아들일 수 있을 것 같습니다.
본 논문 같은 경우는 굉장히 간단하게 처리합니다. 각 클래스 별로 mean-thresholding을 처리해주는 것이죠. 아래 그림을 보면 쉽게 이해할 수 있습니다.
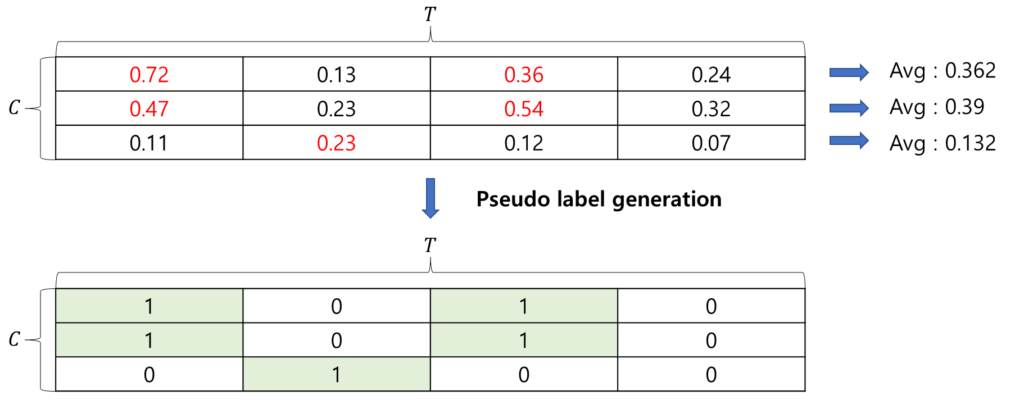
그런데 저렇게 thresholding 만 했다고 해서 Pseudo label이 잘 생성되길 기대하기는 어렵습니다. 따라서 생성된 Pseudo label에 noise를 제거해주는 작업이 필요합니다.
Pseudo-label Denoising
조금 더 trustworthy한 label을 만들기 위해선 noise한 label을 denoising 하는 작업이 필요합니다. 여기서 Clustering이 등장합니다. Clustering을 한번 돌리고 난 다음을 생각했을 때 같은 Cluster에 있다는 것은 비슷한 표현력을 가지기 때문에 same action category일 확률이 높습니다.
즉 우리의 Pseudo label을 이렇게 refine 시킨다고 보면 됩니다.
- 같은 Cluster이고 같은 Pseudo-Label 일 때 confidence를 높게 부여
- 다른 Cluster이고 같은 Pseudo-Label 이거나 같은 Cluster이고 다른 Pseudo-label 이라면 condifence를 낮게 부여 -> 이 경우는 noise라 판단하였나 보네요.
그래서 새롭게 만들어주는 Confidence Map의 formulation은 아래와 같습니다.
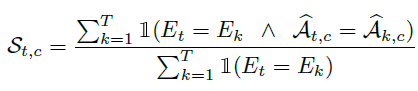
분모항은 같은 Cluster가 몇개 있는지 나타내는 항입니다.
분자항이 핵심인데 저 조건이 True 일 때 1 아니면 0이 되는 Indicator function의 형태로 되어있습니다. 풀어서 설명하자면
- 같은 Cluster 이면서 같은 Pseudo Label 일 때 -> 1
- 그 외 모든 경우는 0
즉, 같은 Cluster 이면서 같은 Pseudo Label인 확실한 경우만을 사용하겠다라는 뜻으로 보면 될 것 같습니다.
간단한 toy-example을 준비했으니 한번 보도록 하겠습니다.
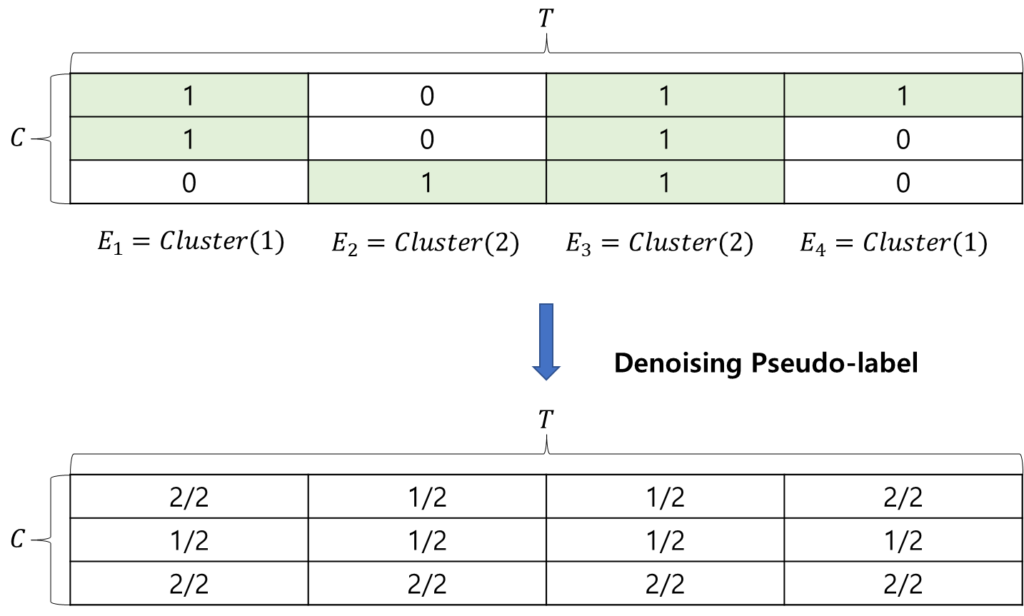
Denoising 후 만들어지는 Confidence Map을 보았을 때 값이 낮을 수록 Pseudo-label이 noise 하다고 볼 수 있으며 값이 클 수록 Pseudo-label이 confident 하다고 볼 수 있습니다.
Denoised Contrastive Learning
앞서 우리는 Pseudo-Label을 만들었고, 이에 해당하는 Confidence Score 까지 구했습니다.
이를 토대로 좀 더 정교한 Contrastive feature를 만들고 contrastive learning을 할 차례 입니다.
그 전에 일단 다시 Notation을 제대로 표기하고 시작하겠습니다.
- \hat{A} \in R^{\left( C+1\right) \times T} : Pseudo Label Map 입니다.
- S\in R^{\left( C+1\right) \times T} : Confidence Map 입니다.
- X\in R^{T\times d} : embedding feature를 한번 더 Projection 시킨 feature 입니다. 조금 더 compact한 representation을 얻기 위해 차원을 d=512로 줄여준 것이라고 하네요.
그래서 우리는 특정 클래스 c에 대한 Denoised Video feature를 다음과 같이 구할 수 있습니다.
- F_{t,i}=\hat{A}_{t,c} \times S_{t,c}\times X_{t,i} : element-wise 방식으로 곱해집니다.
결국 우리가 구한 Pseudo Label이랑 Confidence Score를 가지고 attention을 준다고 봐도 무방합니다. Toy example을 한번 보도록 하겠습니다.
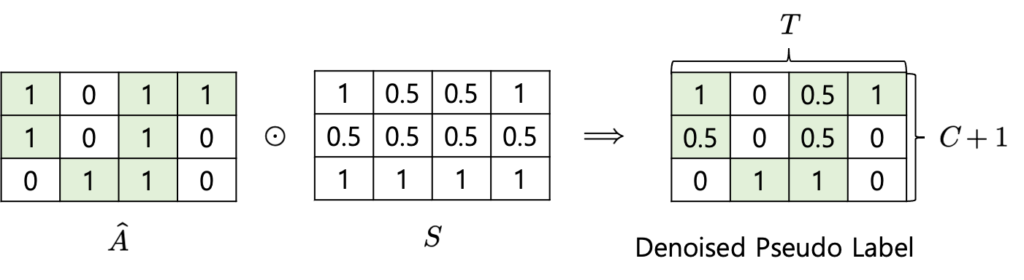
일단 element-wise 방식으로 pseudo-label과 confidence score를 곱해줍니다. 그리고 이 denoised pseudo label을 가지고 projection 된 feature에 attention을 가해줍니다. 여기서 핵심은 클래스별로 attention을 가해주는 것 입니다. class 별로 attention을 가해주기 위해 denoised pseudo label을 class별로 쪼개서 처리합니다.
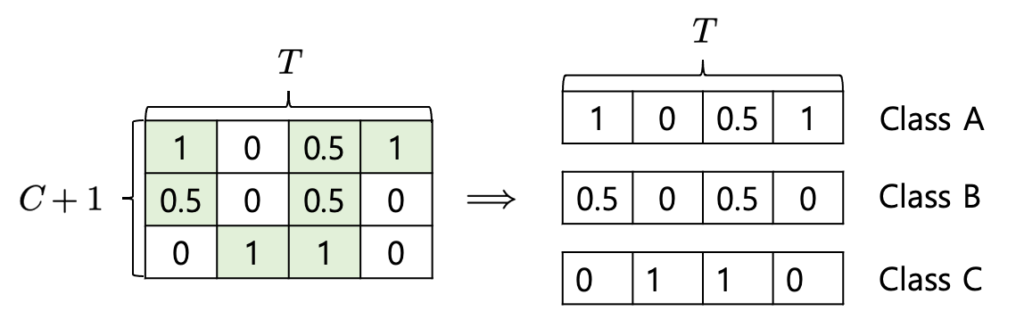
저렇게 Class 별로 attention score를 구해준다음에 Class 별 denoised video feature를 구할 수 있습니다. 예를 들면 Class A에 해당하는 denoised video feature는 temporal 축에 대해서 attention 연산을 취해준다고 보면 됩니다.
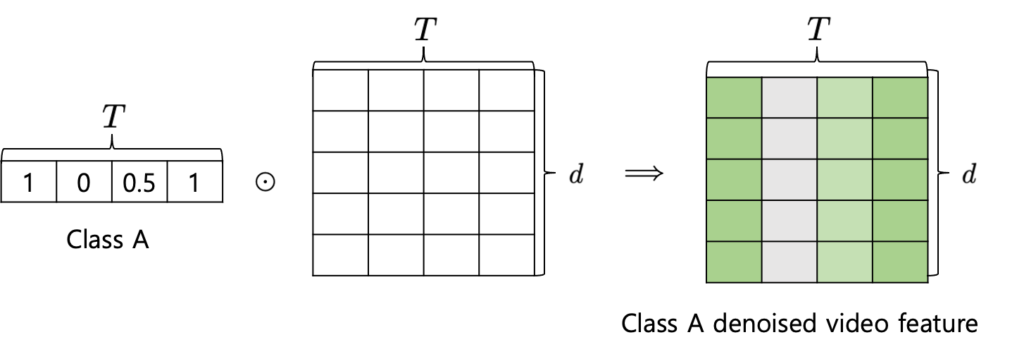
그래서 모든 Action에 해당하는 denoised action video feature를 얻을 수 있습니다. 반대로 background에 대해서는 pseudo-label을 반대로 취해주면 background가 되기 때문에 아래와 같이 구할 수 있습니다.
- F^{bg}_{t,i}=(1-\hat{A}_{t,c} )\times S_{t,c}\times X_{t,i}
그래서 각 Action Class에 해당하는 Feature와 Background에 해당하는 Feature를 모두 얻을 수 있었습니다. 다음으로 Temporal 축에 대해서 Region을 나누게 되는데요. 논문에서 5개의 구간으로 나눈다고는 나와있지만 사실 어떻게 나누는지 까지는 논문에 나와있지 않아 정확히는 모르겠습니다.
예를 들어 비디오가 100초라면 0~20초 , 20~40초 , 40초~60초, 60~80초 , 80~100초 이렇게 균등하게 나누는 것이 아닌가 싶습니다. 코드가 공개되지 않아 이부분은 자세히 모르겠네요.
무튼 구간을 나눴을 때 다음과 같이 표기합니다.
- F\Longrightarrow \{ R_{m}\}^{M}_{m=0}
영역을 나누었다면 그 영역에 해당되는 action feature들과 background feature들을 얻을 수 있습니다. Projection feature들에 대해서 해당 구간에 속하는 Snippet feature들을 average pooling하는 방식으로 region feature를 얻을 수 있습니다.
- \{ r_{m}\}^{M}_{m=0} : action에 대한 region feature들 입니다.
- \{ r^{\prime }_{m}\}^{M}_{m=0} : background에 대한 region feature들 입니다.
Region feature를 만드는 과정을 이렇게 이제 모든 training video에 대해서 이러한 작업을 진행해주면 region memory bank를 구축할 수 있습니다. Contrastive Learning을 할 때 모든 training video를 고려하기 위함이죠. 근데 이 부분도 설명이 한줄밖에 없어서 정확히 어떻게 처리하는 지 궁금하네요.
무튼 모든 training video에 대해서 action region feature, background region feature를 구했으니 이제 positive/negative pair를 구성할 차례입니다.
임의의 action region feature에 대해서 positive pair는
- action region feature from same video with the same action class
- action region feature from different video with the same action class
임의의 action region feature에 대해서 negative pair는
- background region feature from same video
- background region feature from different video
- action region feature from different video with different action class
Contrastive Loss는 많이 사용되는 InfoNCE Loss를 사용했다고 합니다.
- L_{dcc}=-\frac{1}{M} \sum^{M}_{m=0} log\frac{\sum\nolimits_{r^{+}_{m}\in Pos} exp\left( r_{m}\cdot r^{+}_{m}/\tau \right) }{\sum\nolimits_{r^{\pm }_{m}\in Pos\bigcup Neg} exp\left( r_{m}\cdot r^{\pm }_{m}/\tau \right) }
Positive Pair를 보면 같은 비디오와 다른 비디오 내에 있는 action class끼리 당기기 때문에 Intra-class compactness를 챙길 수 있습니다. 같은 class 끼리 더욱 뭉친다는 의미입니다.
Negative Pair를 보면 action과 background를 구분하기도 하지만 다른 비디오 다른 action 끼리도 분리하기 때문에 Inter-class separability를 챙길 수 있습니다. 일단 action과 background는 클래스 구분없이 멀어짐과 동시에 action 끼리도 서로 다른 class라면 조금 멀어지는 방향이죠.
이렇게 정교하게 만들어지는 contrastive framework 속에서 우리가 원하는 embedding space를 학습할 수 있게됩니다.
Overall Training Objective and Inference
그래서 정리하면 학습에 사용되는 최종 Loss term은 다음과 같습니다.
- L_{final}=L_{base}+\beta L_{dcc}
이때 \beta는 balancing factor라고 해서 학습 초반에는 0.1로 사용하다가 학습이 끝날때는 10000으로 조정이 됩니다. 학습 초반에 DCC 모듈에 큰 가중치를 부여했다가 수렴이 제대로 되지 않아 초반에는 Base Model에 집중하여 안정성을 꾀하다가 궤도에 올라오면 DCC 모듈에 좀 더 집중하는 방식을 취했다고 볼 수 있습니다.
DCC 모듈은 학습 과정에서만 사용되고 Inference 단에서는 사용되지 않는 다고 합니다. 우리가 필요한 건 정교한 T-CAS 뿐이니깐 Inference 과정에서 DCC 모듈이 할 역할이 없기 때문입니다.
Experiments
Ablation Studies
Effect of each component
크게 베이스라인과 Denoising 과정 그리고 DCC 모듈 전체를 비교하는 ablation 입니다. denoising 과정을 제거하면 1.7% 정도의 성능 drop이 발생하네요. 제가 아직 실험을 본격적으로 들어가지 않아 이게 큰 차이인지는 아직 감이 안잡히네요. 그래도 분명히 K-Means Clustering을 통한 denoising 과정이 효과가 있는 것 같습니다.
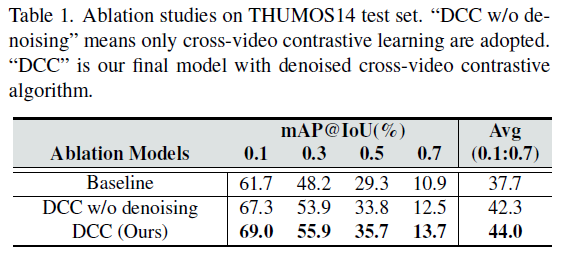
Action-background separation
우선 action-background separation에 대한 T-SNE 시각화 입니다. 확실히 Baseline 대비 action과 background feature 간의 경계가 뚜렷하게 보이는 것 같습니다.
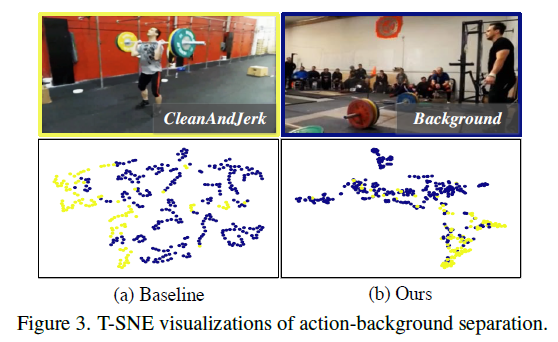
Intra-class compactness & inter-class separability

다음으로는 Intra-class compactness & inter-class separability 를 확인할 수 있는 T-SNE 시각화 입니다. action이라 할지라도 같은 class 끼리는 좀 더 가까이 분포하는 게 좋을 것 같습니다. 시각화를 보면 알 수 있지만 Baseline 대비 같은 class일 때 compactness가 더 좋게 분포하고 있습니다. 또한 서로 다른 class 간의 구분도 더 잘 되는 것 같네요.
이를 통해 Denoised Contrastive Learning이 잘 진행되어 discriminative한 feature를 얻을 수 있었던 것 같습니다.
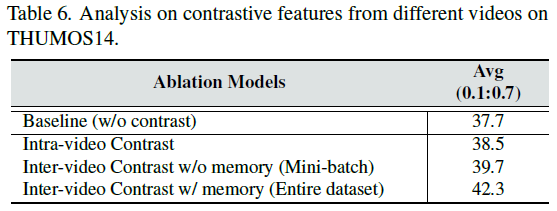
Contrastive features from different videos
Contrastive pair를 구성할 때 단일 비디오에서 sampling하는 방식과 Mini-batch에서 sampling 하는 방식 그리고 Memory Bank를 이용해 전체 비디오에서 sampling 하는 방식을 비교한 ablation 입니다. Constarive pair를 구성할 때 데이터가 많으면 많을수록 성능이 좋다고 알려져 있는 데 딱 그러한 경향성을 보여주는 테이블 입니다. 더욱 다양한 상황에서의 Negative를 만나서
Comparision with State-of-the-Arts
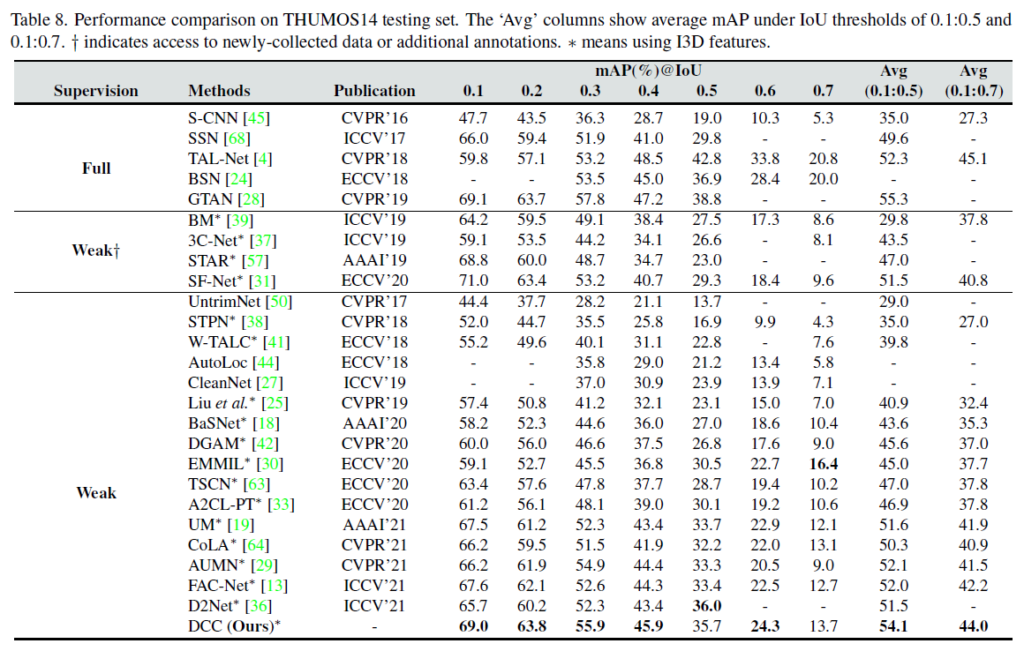
마지막으로 벤치마킹입니다. 전년도(2021년도)에 비해 우수한 성능을 달성하여 본 방법론의 effectiveness를 증명했습니다. 우선 THUMOS에서의 성능입니다. 이번 2022년도 다른 방법론에 비하면 조금 낮은 성능이지만 전년도와 비교했을 때는 확실히 가장 높은 성능을 보여주고 있습니다.
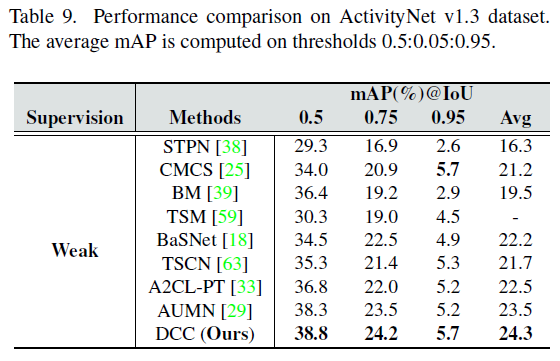
ActivityNet에서도 같은 경향성을 보여주고 있습니다.
Conclusions
개인적으로 조금 참신함을 느꼈던 부분은 Contrastive Learning을 할 때 데이터셋의 부분만을 고려하지 않고 전체를 고려한다는 점과 Pseudo-Label의 Noise를 줄이기 위해 K-Means Clustering을 도입했다는 점이 저는 인상 깊었습니다.
논문만 읽었을 때 이 정도는 금방 원복할 듯..? 이렇게 생각 했는데 생각보다 조금 어렵네요. 아이디어랑 방법론 자체의 결이 이번 에트리에 가져가면 좋을 것 같은 아이디어라 어떻게든 원복 성공해보도록 하겠습니다.
좋은 리뷰 감사합니다.
1. action / background snippet feature를 추출하여 T-CAS를 생성하는 것으로 이해를 했는데 snippet은 clip과 비슷하게 단순히 고정된 크기의 비디오 내부 단위를 의미하는 것인가요?
2. contrastive learning을 위해 pos/neg pair를 구성하는 과정에서 background끼리 서로 멀어지게 학습하는 이유는 무엇인가요? 같은 background 클래스에 속하더라도 feature의 특성이 제각각 달라 가까워지도록 학습하면 오히려 background를 제대로 분류할 수 없게 되는 것인가요?
1. snippet은 16frame의 고정된 크기의 clip을 의미합니다.
2. background 끼리 멀어지는 것이 아니라 action과 background 끼리 멀어지는 것 입니다.
리뷰 내용에서 언급한 것처럼 GPU를 이용해도 느리다고 하는데, 방법론을 잘 읽어보면 느릴 수 밖에 없을 것 같은데 논문 저자들은 학습을 어떻게 했는지 저도 궁금하긴 하네요. 설명만 보면 MoCo를 가져다가 쓴 것 같기도 하고요.
Contrastive Learning을 수행할 때, negative pair의 두번째 조건으로 “background region feature from different video”를 추가하는 이유는 혹시 따로 있나요? 제가 생각했을땐 다른 비디오의 백그라운드일지라도 명확한 action 영역이 아니니 학습에 좋은 영향을 미칠 것같다는 생각과 오히려 다른 클래스의 액션 구간과 같이 negative pair로 사용하면 백그라운드의 분별력을 학습하는데 방해가 될 수도 있을 것 같다는 생각이 들어서 질문드립니다.
negative pair의 두번째 조건은 직관적이다라고 저는 생각합니다. 말 그대로 action과 background(같은 비디오이든 다른 비디오이든)를 구분하기 때문입니다.
오히려 세번째 조건인 다른 비디오의 다른 action class와 멀어지는 방향으로 학습이 되는 것이 헷갈릴 수 있는데 이는 서로 다른 클래스 끼리는 어느정도 representation이 구분이 될 수 있게 해주는 효과로 기대할 수 있습니다.