오늘은 오랫만에 video copy detection 논문으로 돌아왔습니다. 이 논문은 “Learning segment similarity and alignment in large-scale content based video retrieval”라는 제목의 후속 연구 논문으로 x-review에도 조원 연구원님이 써둔게 있으니 함께 읽으면 좋습니다. 특징이라면 중국 antgroup 논문이라… 돈이 많이 들었을 것 같던 부분들도 가볍게 해결되는게 부러웠네요… 라벨러를 30명을 써서 4달동안 데이터셋만 만들다니… 참 대단합니다.
Introduction
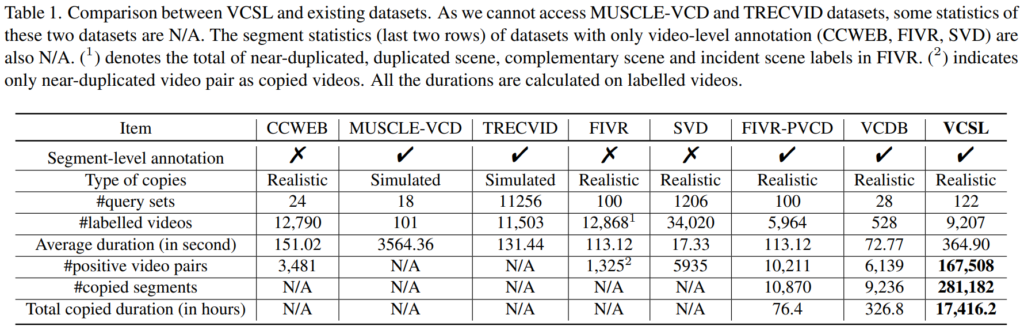
video copy detection에 대한 내용들은 연구원분들이 아실거라고 생각해서 이 부분은 넘어가고, 저자들이 주장하는 문제점에 대한 이야기를 먼저 해보려고 합니다. 기존에 비디오 연구에서 많이 사용하는 데이터셋을 위의 표에서 찾아보면, FIVR와 VCDB 정도를 대표로 보면 좋을 것 같은데요.
먼저, FIVR의 경우에는 copy detection을 위해 제시된 데이터셋이 아닙니다. 그래서 적절한 비교인지는 조금 의문이 들기는 하지만… 많은 양의 비디오가 존재하는 것에 비해 video-level annotation만 제공되기 때문에 이러한 task를 수행하기에는 조금 어려운 상황입니다. PVCD라고 후에 copied segment에 대한 segment-level annotation을 수행한 논문이 나오긴 했지만, 세그먼트 갯수가 그리 많지 않은 것이 한계입니다. 다음으로 VCDB는 copy detection을 위해 제안된 논문인데요. 많은 양의 Background dataset을 제공하지만, 실질적으로 복사된 영역을 가지고 있는 core dataset의 경우에는 528개만 제공되고 있으며, 그 영역들의 길이도 매우 짧다는 한계를 가지고 있습니다.
이렇게 데이터셋의 문제들이 있는 것에 더불어 뒤에서 설명하겠지만, evaluation metric에도 한계가 있습니다. 논문 저자들은 이 문제점들을 해결하기 위해서 이 논문에서는 VCSL이라는 새로운 video copy detection 데이터셋을 제시하면서, 이전 논문에서 제안한 video alignment module인 SPD를 바탕으로 video alignment benchmark를 제안합니다.
Dataset
Annotation
이 논문이 신기한게… 수집 과정이 따로 없습니다. 그럼 데이터셋은 어떻게 수집하냐고요? 미리 지정된 seed 비디오와 키워드를 바탕으로, 라벨러들이 유튜브와 빌리빌리(중국판 유튜브)에서 검색을 하면서 비디오도 같이 수집합니다. 시드 비디오 같은 경우에는 11개 주제 (movies, TV series, music videos, sports, games, variety show, animation, daily life, advertisement, news and kichiku)를 가지고 있는 비디오 122개를 논문 저자들이 선택했다고 합니다.
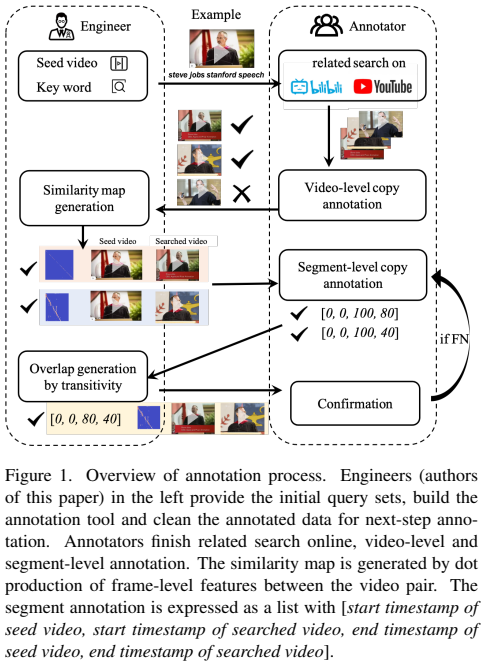
[그림 1]을 보면 annotation process를 볼 수 있는데, 사실상 데이터셋 수집도 함께라 annotation 이외의 모든 구성 과정이 포함되어 있습니다. 이 논문에서 비디오 자체 수집을 라벨러들에게 맡기는 대신, 이 프로세스를 자동화 하는 것에 집중한 것 같습니다.
라벨러들이 비디오를 찾아서 해당 비디오를 저자들에게 넘기면, 저자들은 해당 비디오가 적합한지 검토하고 Seed 비디오와의 similarity map을 생성해서 다시 라벨러에게 전달합니다. Similarity map이 생성된다는 뜻은, 정확하지 않을 수는 있어도 segment pair를 라벨러가 보고 있다는 뜻이기 때문에 이 결과를 참고해서 정확한 구간의 라벨링을 수행합니다.
그럼 이 결과를 다시 저자들이 받아서 검토 후에, transitivity property에 해당하는 비디오 세그먼트를 만들어서 다시 라벨러에게 전달합니다. ( segment A에 대응되는 복사 영역인 segment B가 있을 때, 라벨러가 A-B를 라벨링해서 넘겨줬다면, B-A도 라벨링 하는 것을 말함 ) 이러한 자동 라벨링이 적합한지에 대한 검토를 라벨러가 마치면 모든 과정이 끝나게 됩니다.
Statistics
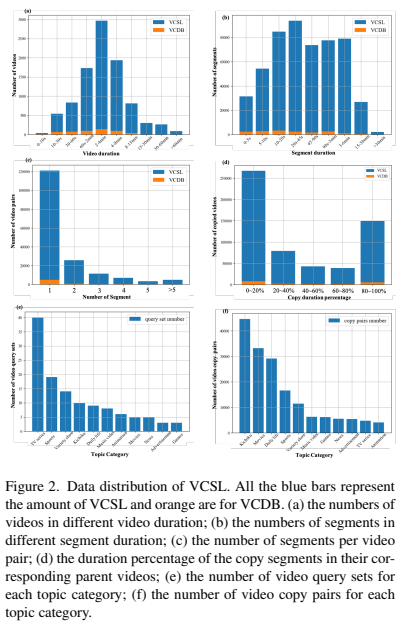
데이터셋 통계를 보면, VCDB보다 당연히 비디오 갯수가 늘어서 전반적으로 양이 많습니다. 주목해야할 점은 TV series 카테고리의 쿼리 비디오 갯수가 가장 많지만 정작 copy pair의 갯수는 적다는 점, copy pair의 갯수의 편차가 크다는 점입니다. 전반적으로 VCDB에 비해 데이터셋의 크기가 증가해서 사용하기는 적합해 보일 수 있지만 이럴 경우에는 특정 종류의 쿼리 비디오에서 alignment 성능이 전체 성능을 대표할 가능성이 있습니다. 그래서 논문 저자들은 전체 copy pair의 alignment 성능을 평균내서 성능으로 측정하는 것이 아니라, 쿼리 비디오의 성능을 계산한 다음 그 성능들의 평균을 사용합니다.
Evaluation Protocol
Background and Motivation
기존의 alignment score metric에는 비디오와 비디오 간의 alignment score를 재는 것이 아니라, GT 세그먼트와 비디오 간의 alignment score를 측정한다는 문제점이 있었습니다. 이러한 부분에서 비디오와 비디오 간의 alignment를 측정하는 새로운 metric이 필요합니다.

이와 더불어 기존 metric의 다른 문제점을 생각해보기 위해 alignment score를 측정할 때 발생할 수 있는 특이 케이스를 알아봅시다. [그림 3-a]는 긴 비디오에서 짧은 구간의 비디오가 들어가 있는 경우입니다. 그리고 [그림 3-b]는 반복적으로 복사된 영역이 들어가있는 경우입니다. 실제로 기존의 alignment를 측정할 경우에는 이러한 경우에 정확한 정렬 점수를 측정하기가 어려운 상태입니다. 이러한 문제점이 있다는 것을 인지하고 새로운 alignment 평가 지표에 대해 알아봅시다.
New Metric
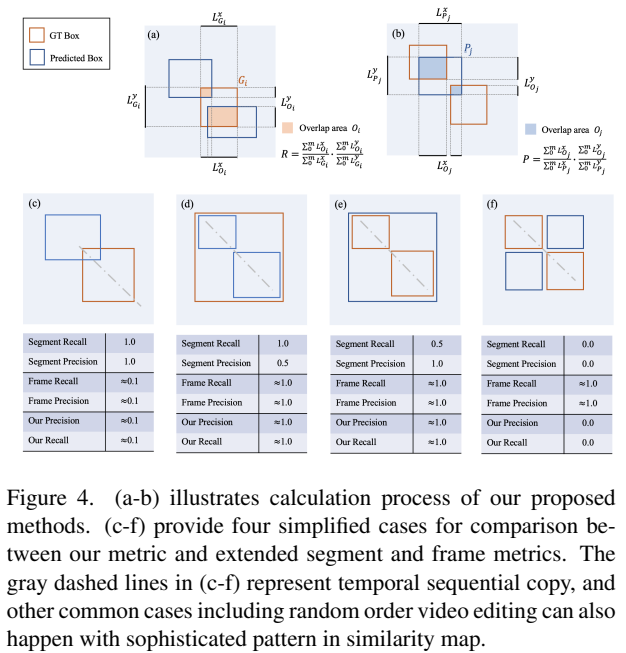
논문 저자들은 위의 경우를 만족하면서도, 합리적인 metric을 만들기 위해서 기존에 많이 쓰이는 Recall과 Precision를 채용해서 사용했습니다.
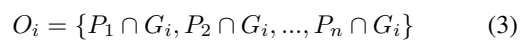
예측 영역을 \{P_j\}{1,2,3...n}라고 정의하고, GT 영역을 \{G_i\}{1,2,3...m}라고 정의할 때, 위와 같이 overlapped 영역을 O_i로 표현합니다. 예측 영역과 GT 영역의 IoU를 계산하는 것이죠.
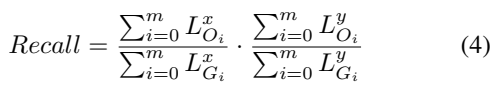
이때 Recall은 위와 같이 계산됩니다. 여기서의 차이점은 단순히 IoU를 합쳐서 계산하는 것이 아니라, x축과 y축에서의 overlapped 정도를 함께 계산합니다. 일반적으로 쓰이는 방법인 면적으로 계산하는 것을 사용하지 않고, 이렇게 길이를 바탕으로 계산하는 것은 [그림 4 d-e]와 같은 경우에 강인하게 작동한다고 합니다.
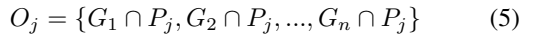
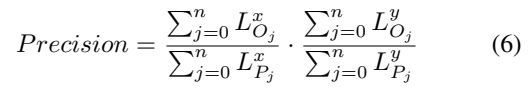
Precision도 동일한 방법으로 계산하지만, Overlapped 영역을 계산하는 것이 반대인 것을 확인할 수 있습니다.
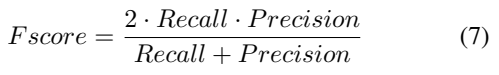
F-score 같은 경우에는 다들 계산하는 방법은 아실테니 수식만 보여드리고요. [그림 4]에서 볼 수 있듯이, 단순히 수식과 설명으로 새로운 metric이 더 좋다는 것을 증명하는 것이 아니라, 기존의 Metric 대비 새로운 Metric이 가지는 장점을 표현하니 확실히 잘 와닫는것 같습니다.
Benchmark
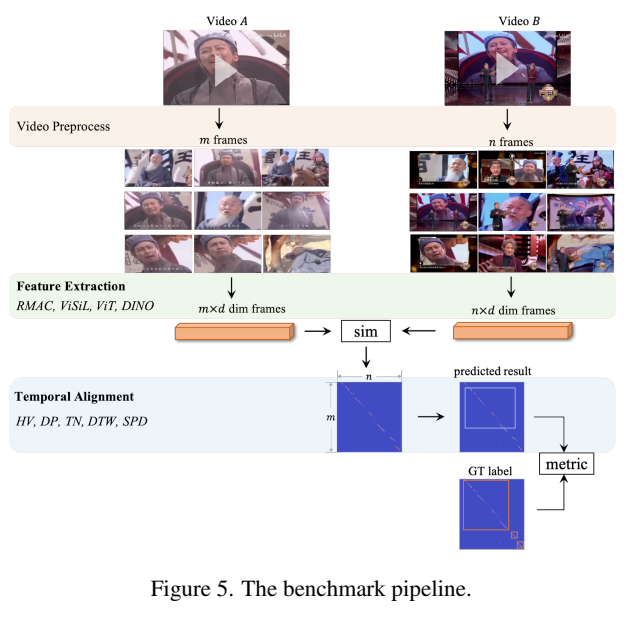
사실 비디오 정렬에서 뭔가 이렇다하게 정형화된 방법이 없는 것 같습니다. 지난 논문을 준비하면서 여러 저자들에게 메일도 보내봤지만 각자만의 방법으로 성능을 측정하는 것 같은 느낌이었습니다. 그래서 VCSL에서는 새로운 metric을 기반으로 기존의 방법론을 이용한 benchmark 또한 제시합니다. 이 새로운 benchmark를 위해서 alignment를 3가지 과정(비디오 전처리 / feature 추출 / temporal alignment)으로 분리하였습니다. 비디오 전처리에서는 일반적으로 많이 쓰이는 uniform sampling으로 통일했고, 나머지 방법론에서는 유명한 방법론들을 기반으로 성능을 측정합니다.
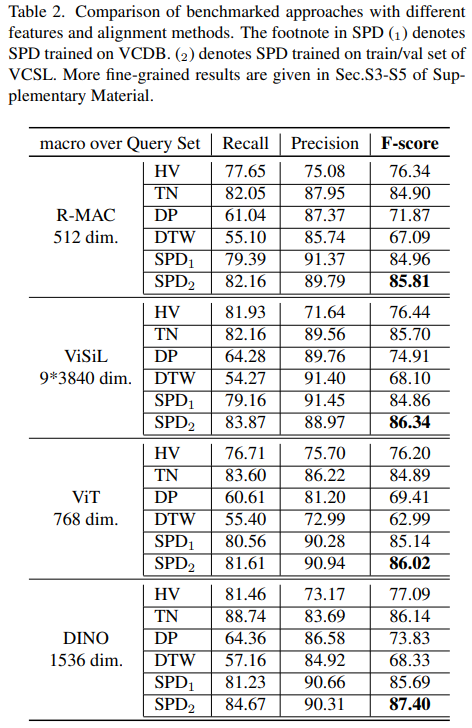
실제로 유명한 방법론들을 바탕으로, 정렬 방법론들을 붙여서 성능을 측정한 결과인데요. SPD의 경우에는 글의 서두에서 말씀드렸듯 이 논문 저자들이 지난 논문에서 제안한 정렬 방법론입니다. 사실 그때는 좀 믿음이 안갔는데… 이렇게 보니 믿음이 가네요. (숫자 1과 2의 차이는 1은 VCDB에서 학습한 경우고, 2는 SPD에서 학습한 경우입니다.)
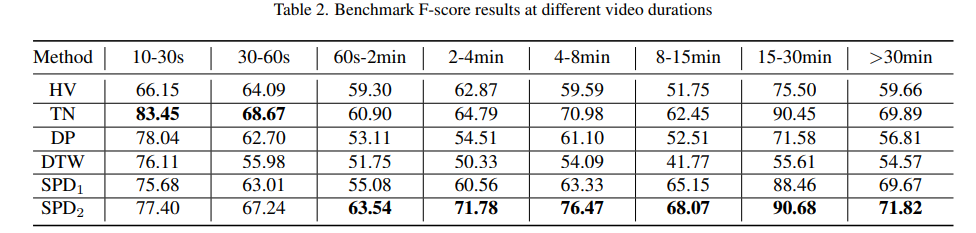
TN이라고 표시된 방법론이 Temporal Network인데, 무려 2009년 방법론입니다. 그렇게 큰 성능 차이가 없는 것에서 좀 의아할 수 있는데요. 그래서 위의 표를 가져왔습니다. 비디오 길이에 따른 정확도 분석인데요. 아무래도 짧은 비디오가 데이터셋에서 차지하는 비중이 꽤 있다보니 그 부분에서 성능이 많이 뛴 것도 있는 것 같습니다.

그리고 위는 실제로 데이터셋에 존재하는 비디오들의 예시인데요. 지금 보니 초상권이나 저작권 문제는 어떻게 해결했는지 궁금하네요. VCDB 보다는 조금 더 복잡한 비디오들이 추가되었다고 보면 좋을 것 같습니다.
Conclusion
작성해야하는 논문과 비슷한 느낌으로 풀어가면 되지 않을까 싶어서 읽었는데 역시 쉽지 않네요 ㅎㅎ… 내용적으로는 어려운 부분들이 없지만, 대용량 데이터셋의 가치와 alignment score를 측정하는데 마땅한 방법이 없는데 새로운 방법을 제시한 것이 높은 평가를 받은게 아닌가 싶습니다.