요즘 Monocular Pseudo-LiDAR 의 성능을 올리기 위해서 기존 Depth estimation 방법론들을 분석하고 있습니다.
분석 중에 가장 인상 깊었던 것은 Stereo depth estimation의 성능이 였는데요. 전 이전까지는 Supervised Depth estimation 의 성능과 Stereo Depth estimation 의 성능이 유사할 것이라고 생각했었습니다. 그렇지만 결과는 그렇지 않았습니다, 아래 그림을 보시는 것 과 같이 Stereo 를 이용한 Depth estimation의 성능은 Supervised 보다 훨씬 좋은 것을 확인 할 수 있습니다.
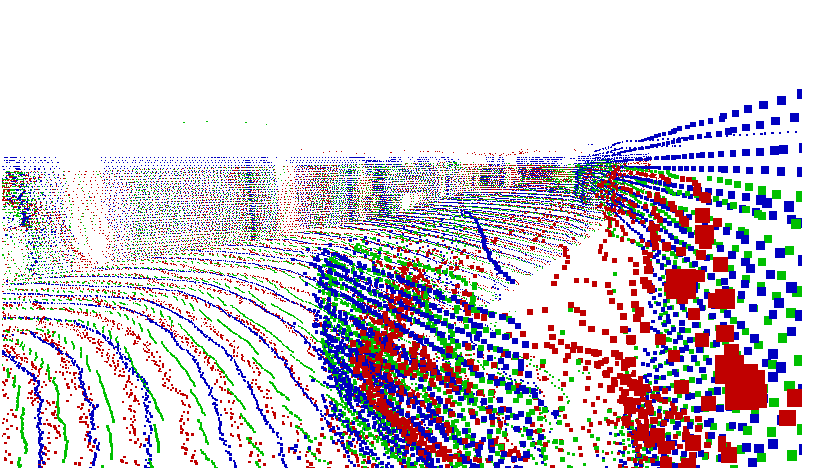
Stereo 는 Lidar와 매우 유사한 결과를 보여주며 표면이 일그러지지 않는 것을 볼 수 있습니다. 하지만 빨강색인 Monocular Supervised Depth estimation의 결과는 매우 일그러지며 처참합니다. 이러니… 아래와 같이 Pseudo-Lidar 의 성능 차이가 매우 크게 차이 납니다.
| Moderate | Valid | CAR (MAP) | Abs_rel | |
| Category | BEV | 3D | ||
| PSMNet | PL / Stereo | 57.711 | 46.8174 | 0.045 |
| —————————— | ——————— | ——————— | ——————— | |
| DORN / AVOD | PL / Sup Mono | 24.6 | 17.2 | |
| MonoDTR SOTA | Sup Mono | 25.35 | 18.57 | |
| BTS / PointRCNN | PL / Sup Mono | 22.0205 | 16.3357 | 0.092 |
| TransDSSL / PointRCNN | PL / Self Sup Mono | 18.011 | 13.3169 | 0.0139 |
따라서 Stereo Depth Estimation을 더욱 분석할 필요가 있어져서 이 논문 (PSMNet)을 읽게 됐습니다.
Stereo image를 이용한 Depth estimation은 전통적인 방법론부터 시작 됩니다.
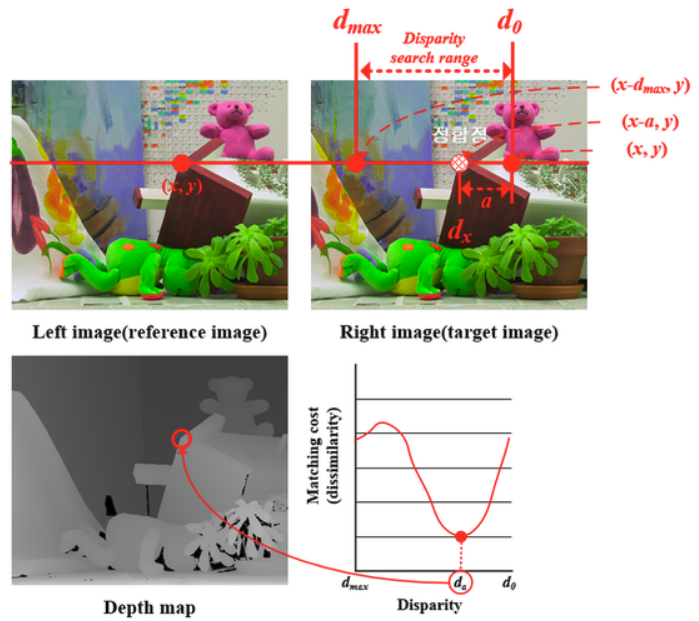
Depth=(f*B)/Disparity , f= focal length, B=baseline, 공식을 이용해서 Depth 를 구할 수 있으니 위 그림과 같은 공식을 통해서 stereo image를 매칭한 후 disparity 를 구하면 depth를 얻을 수 있습니다. CNN이 등장한 이후 아래 그림과 같이 feature 를 CNN을 이용해서 계산하고 전통적인 방법론은 이용해서 disparity를 계산하는 방법론이 등장하였습니다.
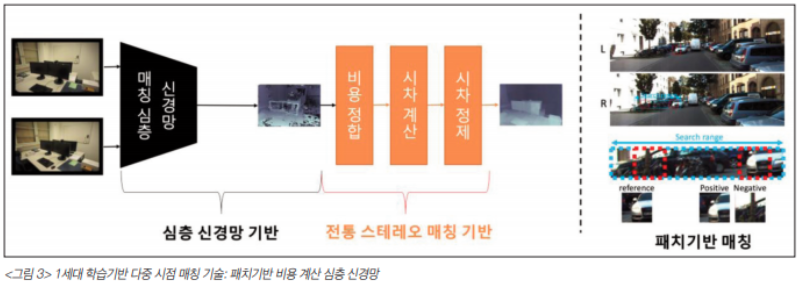
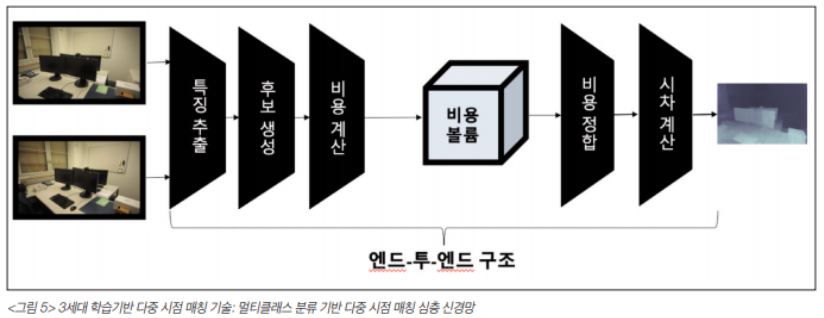
그 이후에는 depth를 regression하는 모델이 개발 되어 훨씬 빠른 속도로 깊이를 추정할 수 있게 되었으며 마지막으로 회귀 문제가 아닌 멀티클래스 분류 문제로 접근하는 연구가 나오게 되었습니다.
두 입력 영상은 동일한 2차원 Conv layers를 통과하여 특징점이 추출되고 추출된 특징점을 픽셀 단위로 이동시켜 모든 특징점을 결부시켜 다중 스케일의 3차원 컨볼루션 레이어를 통과시키는 것으로 Cost volume을 제작한다. 제작된 Cost volume은 3차원 디컨볼루션을 통해 cost volume을 집합시키고 softmax를 활용하여 깊이를 선택하게 됩니다.
이렇게 발전해온 Stereo depth estimation 에는 여전히 많은 문제가 남아 있습니다. 그 중에서 이 global context modeling에 주목했습니다. 이 논문이전에는 CNN 의 작은 receptive field를 가지고 feature 를 추정한 후에 cost volume 을 계산하지만 이렇게 될 경우 너무 좁은 범위만 계산되게 되어 정확한 깊이 추정이 어렵게 됩니다. 따라서 이 논문에서는 receptive field를 늘리기 위해 Spatial Pyramid Pooling 적용을 제안하며 3D CNN을 이용해 Cost Volume 을 정제하는 것을 제안합니다.
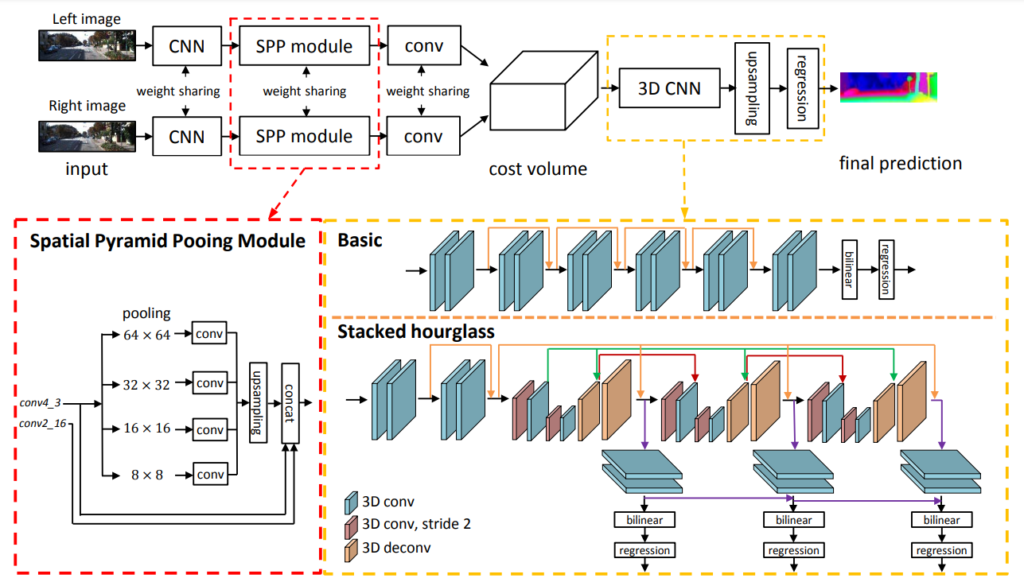
이 논문에 제안하는 방법론의 파이프라인은 위 그림 과 같습니다.
두 stereo 영상으로부터 CNN 으로 feature를 추정한 후 SPP module을 거쳐서 보다 넓은 범위의 context를 추정합니다. SPP 모듈을 통해서 전체적 맥ㄹ락을 포함하는 특징을 추정할 수 엤게됩니다. 이를 통해서 복잡하게 놓인 물체들에 대해서도 대응점을 잘 찾을 수 있게됩니다.
그리고 Cost volume 을 정제하는 과정을 기존과 달리 3D Stack hourglass 방식으로 변경해서 각 단계 별로 나온 Disprarity 로 Loss를 계산해서 깊이 정보를 각 feature 마다 강화하게 됩니다.
loss는 smooth L1 으로 gt disparity랑 비교해서 계산합니다.
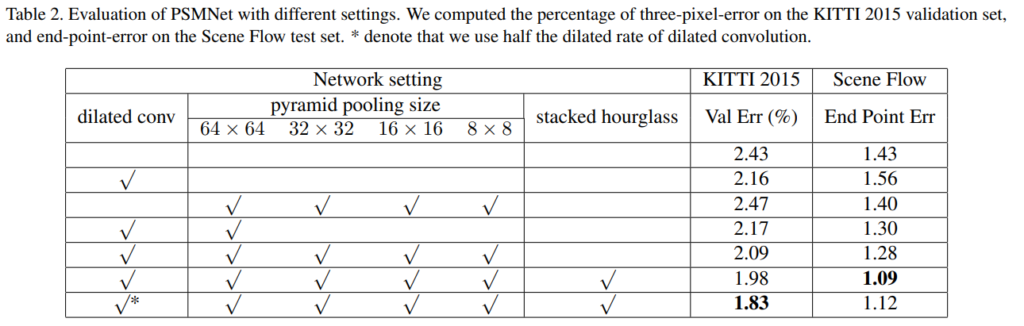
ablation study를 통해서 SPP 와 3D stacked hourglass의 효엄을 확인했습니다.
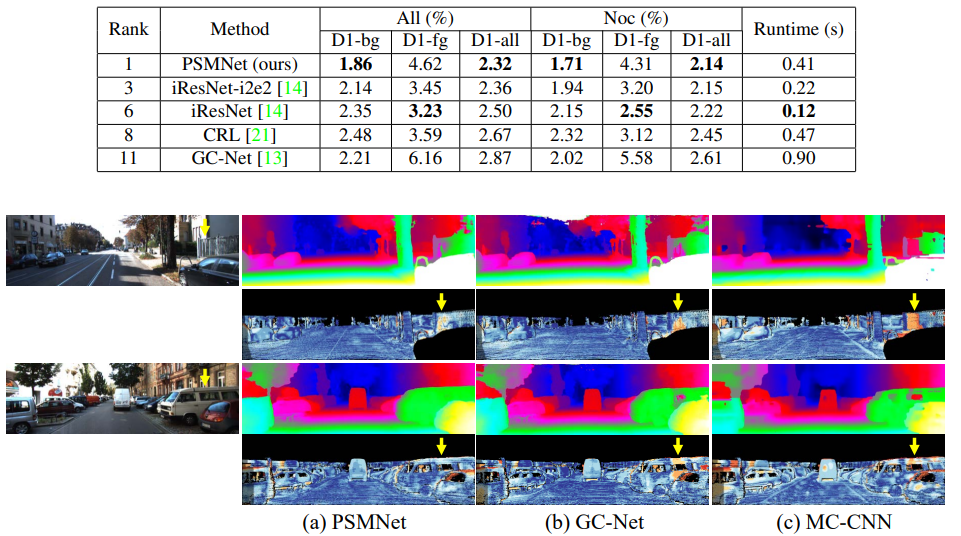
그당시 KITTI online eval에서 1등을 기록했으며 정성적 결과 더욱 조하진 것을 볼 수 있습니다.
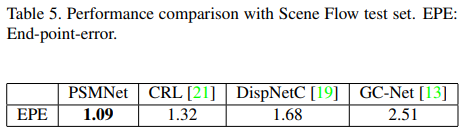

실내에서도 매우 우수한 결과를 볼 수 있습니다.
이 논문에서는 Stereo 의 특징을 찾을 수 없었지만 Cost volume을 통한 깊이 추정이 아마 Mono 보다 더욱 좋은 이유라고 판단 하고 있습니다 .
좋은리뷰 잘 봤습니다.
본 모델의 loss같은 경우 언급해주신 gt disparity 와의 L1 loss 말고 다른 loss는 없는건가요??
그리고 stereo pair에서 특징점을 추출해서 특징점 끼리의 pixel간 이동을 통한 disparity를 계산하는 방식인거 같은데, 본 논문에서의 차별점은 추출된 feature를 다중scale에서의 cost 계산을 통해 여러 receptive field에서의 비교가 가능해졌다고 이해하면 되는건가요?
++ 특징점을 추출하는 여러 방식에 따른 ablation study는 없나요?
질문이 너무 긴 거 같습니다ㅎㅎ./… 리뷰 감사합니다.
안녕하세요 한가지 의문점이 있어서 질문드립니다.
리뷰 첫 내용에서 “이전 이전까지는 Supervised Depth estimation 의 성능과 Stereo Depth estimation 의 성능이 유사할 것이라고 생각했었습니다. 그렇지만 결과는 그렇지 않았습니다, 아래 그림을 보시는 것 과 같이 Stereo 를 이용한 Depth estimation의 성능은 Supervised 보다 훨씬 좋은 것을 확인 할 수 있습니다.”
라고 하셨는데, 그렇게 생각하신 이유가 있으실까요?
당연히 monocular + supervised 조합보다는 stereo + supervised 조합이 사용할 수 있는 입력 데이터가 더 많은 만큼 성능이 더 좋다고 생각되어지는데 어떤 관점에서 supervised monocular depth estimation의 성능이 stereo와 유사하다고 생각하셨나요?