예전에 한번 Generic Event Boundary Detection(GEBD)에 대한 논문을 리뷰한 적 있는데요. 이번에 둘러보니 CVPR 2022에 나온 논문인데, 연세대학교에서 나온 논문이 있어서 한번 읽어봤습니다.
Introduction
지난번 GEBD에 대한 리뷰에서는 MPEG-4의 압축 방법론에 대한 이야기를 주로 다뤘습니다. 그래서 GEBD에 대한 내용이 조금 부족했던 것 같아 이 내용을 여기서 좀 보충하려고 하는데요.
우리가 일반적으로 비디오를 전처리할 때, unifom sampling을 사용하고 있는데요. 이런 방법론은 비디오의 내용에 상관 없이 처리되고 있는 것이죠. 하지만, GEBD는 비디오의 내용을 고려해서 비디오를 분할합니다. 이러한 맥락에서 보면 논문 저자들은 GEBD가 인간의 인지 매커니즘을 이용해서 비디오를 이해하는 방법론으로 볼 수 있다고 생각합니다.
그리고 결국은 비디오에서의 temporal한 영역을 찾는 문제로 귀결되기 때문에 Temporal Action Localization과 연관되어 많은 방법론들이 시도되어지고 있고, 여러 방법론들이 적용되고 있는데… 궁극적으로는 Classification용으로 학습된 백본의 feature로는 이러한 scene의 변화를 인지할 수 있을 정도의 정보량이 부족하다고 합니다. (프레임 끼리의 관계를 알 수 있는 정보가 필요하다고 하네요.)
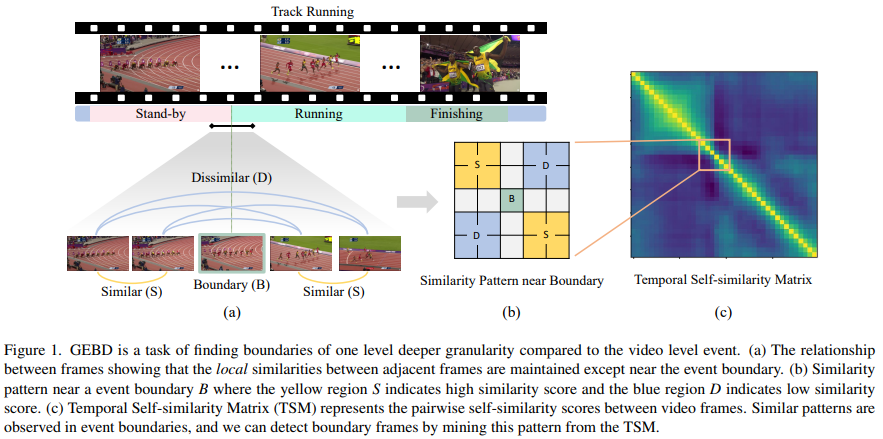
그래서 이 논문에서는 [그림 1]에서 볼 수 있듯이 self-similarity를 기반으로 이벤트의 경계를 찾습니다. 대략적인 그림인데, 같은 이벤트 끼리는 비슷하고 서로 다른 이벤트 끼리는 다르다는 간단한 사실을 metric learning에 적용하는 것이죠.
그래서 contribution을 정리해보면 아래와 같습니다.
- Self-Similarity Matrix의 특성이 GEBD와 잘 어울린다는 것을 발견하고, 이러한 방법론을 GEBD에서 사용할 것을 제안함
- TSM이 찾아낼 수 있는 boundary pattern을 이용하여, 분할 정복에 기반을 둔 Recursive TSM Parsing (RTP) 알고리즘 제안
- RTP에 적용 가능한 BoCo Loss를 제안하여, 비지도 학습 방법론에서 좋은 성능을 보임
Proposed Method
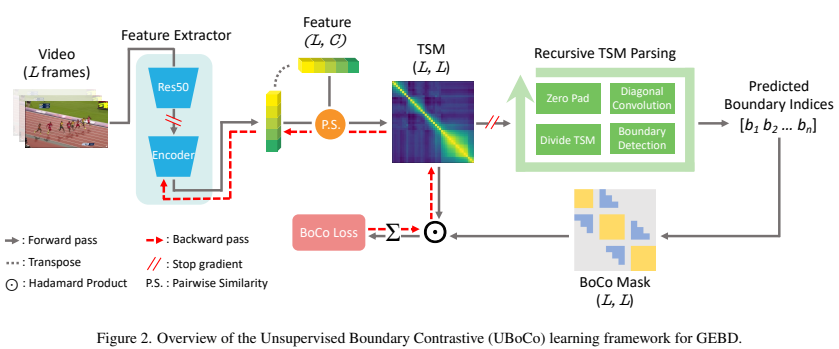
기존의 pretrained된 모델의 한계점을 이야기 한 만큼 그 문제를 해결하기 위해서 extra encoder를 도입해서 사용한 것 같습니다. ( [그림 2]를 보면 학습하는 영역이 딱 그 부분에 걸칩니다. ) 그리고 이렇게 나온 feature를 바탕으로 TSM(Temporal Self-similarity Matrix)모듈에서 self-similarity를 바탕으로 pseudo label을 만들어서 학습을 수행합니다. 그리고 RTP(Recursive TSM Parsing) 모듈을 통해서 이벤트 경계를 찾아내고 이 찾은 값을 바탕으로 BoCo Mask를 만들어서 BoCo Loss에서 TSM과 사용합니다.
Unsupervised Boundary Contrastive Learning
Recursive TSM Parsing
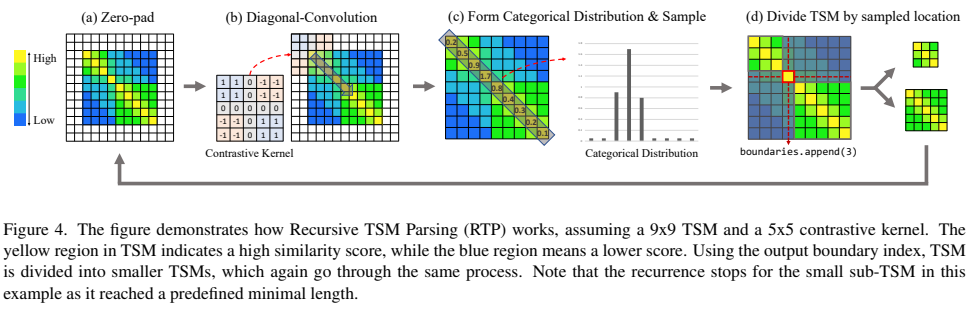
사실 그림이 되게 깔끔하게 잘 그려져 있어서 그림만 봐도 이해가 잘 가는데요. 그래서 흐름은 그림으로 보는게 좋을 것 같고, 각 단계별로 중요한 부분만 정리하겠습니다.
(a) Zero-pad는 대각선의 시작점과 끝점은 이벤트 경계면이 아닐 확률이 높다는 것에서 착안해서 추가된 부분입니다. RTP가 최초로 실행될 때는 이 대각선의 양끝은 비디오의 시작/종료 지점이겠죠? 그 결과를 바탕으로 비디오가 분할되더라도, 그 분할된 세그먼트에서의 시작/종료는 이벤트의 시작 혹은 종료 지점일 확률이 높습니다. 이런 흐름으로 생각해보면 zero-pad를 추가함으로써 이 영역들에 대해 이벤트의 경계일 확률을 줄여주는 역할을 수행합니다.
(b) 에서 사용하는 Kernel의 패턴은 일반적으로 관측되는 boundary의 패턴을 matrix로 만들어서 사용합니다. 그리고 (c)에서의 점수는 높으면 경계일 확률이 높은데요. 특정 threshold를 두고 사용하는 것은 아니고, top k% score를 가진 영역을 선택합니다. (근데… 논문에 k가 어딨는지 모르겠네요.)
그럼 top k% score를 선택해서 비디오를 분할하는 것을 무한히 반복하는건 아니고, 종료 조건이 두가지 있습니다.
- TSM의 크기가 미리 정의된 T_1보다 작을 경우
- 예측된 점수들의 최대/최소의 차이가 T_2보다 작을 경우
위의 종료 조건을 만족할 경우에는 끝납니다.
Boundary Contrastive Loss
여기까지 내용에서 우리는 RTP가 어떻게 경계면을 예측하는지를 알았습니다. 사실 정확하게는 학습 과정이기 때문에 이벤트의 경계를 학습하기 위한 방법을 본거죠. [그림 2]를 보면 이 RTP를 통해 나온 boundary indices를 BoCo Mask라는 것으로 보내고 BoCo Loss를 계산하는 것을 볼 수 있습니다.
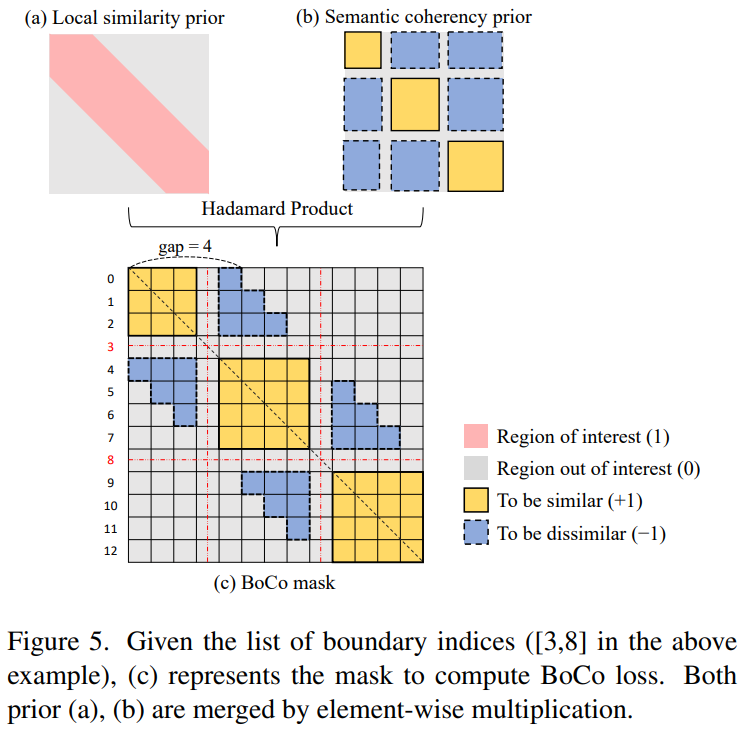
이 BoCo Mask는 [그림 1]에서 확인한, boundary pattern을 이용해서 이 작업을 수행합니다. 이 유사도 패턴을 기반으로 [그림 5]의 (b)와 같은 패턴이 만들어집니다. 그리고 self-similarity 에서 집중적으로 모델이 학습해야할 부분은 가까이 있는 프레임들 끼리의 관계입니다. 그래서 비교적 멀리 있는 프레임은 학습할 필요도 없습니다. 이러한 논리에 따라 [그림 5]의 (a)와 같은 패턴이 만들어집니다. 그리고 이 두 패턴을 합치면 BoCo Mask가 만들어지죠.
이러한 Boundary Contrastive Loss에서는 BoCo Mask를 통해 Metric learning을 하는데요. 복잡한 방법들도 있겠지만, 여기서는 유사해야하는 영역(노란색 영역)과 유사하지 않아야 하는 영역(파란색 영역)의 평균 값을 계산하는 방법을 사용했습니다.
Boundary Contrastive Loss
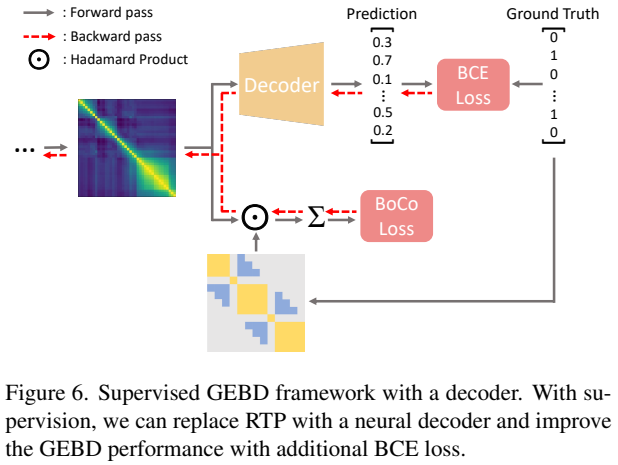
주 방법론은 비지도학습 방법론이지만, 지도학습 방법론으로 전환도 가능합니다. 기존의 RTP가 psuedo GT를 만들어서 학습에 이용했다면, 여기서는 그 GT를 진짜 GT로 대체하기만 하면 됩니다. 이를 위해서 RTP를 decoder로 대체하고, BCE Loss를 통해 예측값과 GT를 직접적으로 비교합니다.
Experiments
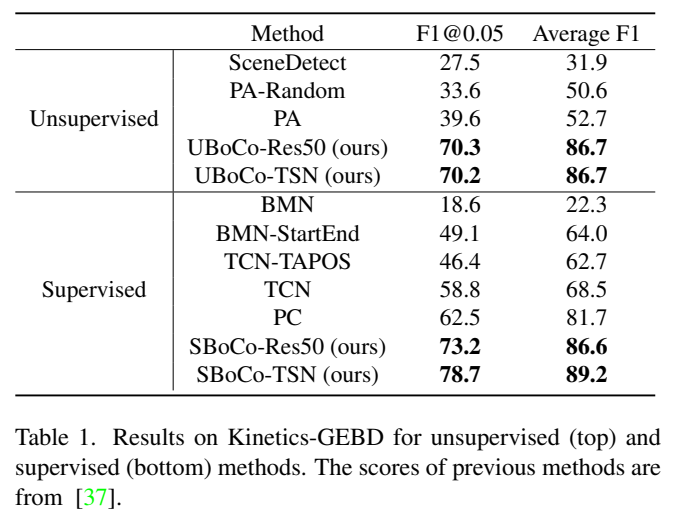
이 논문에서 비교하는 방법론은 전부 베이스라인으로 제시되었던 방법론입니다. 제가 이전에 리뷰했던 또다른 GEBD 논문의 방법론이 지도학습 기반인데 avg F1이 86.5라는 것을 감안해도… 이 논문에서 보여주는 성능이 꽤 좋은 것을 알 수 있습니다.
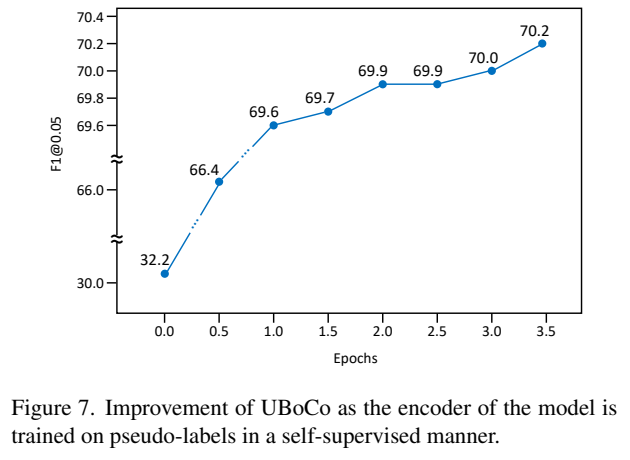
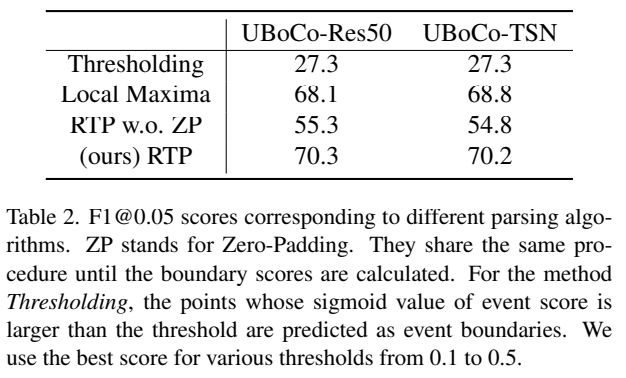
그리고 [그림 7]과 [그림 2]는 Psuedo label을 만드는 것에 따른 성능 비교 실험입니다. Self-similarity를 이용해서 학습을 함으로써, encode가 만들어내는 TSM이 정밀하게 만들어지기 때문에 성능이 오르는 것을 볼 수 있습니다. 또한 [표 2]를 통해서 이 TSM에서 계산되는 boundary score를 어떻게 고를지에 대한 비교 실험도 있는데요. zero padding을 붙이는 것의 효과가 생각보다 크다는 것을 확인할 수 있었습니다.

실제 정성적인 결과를 보면 위와 같습니다. Action/Shot/Object가 변하는 시점에 라벨링이 되어있는데요. RTP가 종료조건을 만족하기전까지, 계속해서 찾은 이벤트의 경계점들을 모두 더해 최종 예측값으로 반환하는 것을 볼 수 있습니다.
Conclusion
생각보다 복잡한 장면에 대해서도 이벤트를 잘 나눠주는 것을 볼 수 있습니다. 성능이 조금 더 좋아지고 처리 속도에 문제만 없다면, 거의 모든 비디오 방법론에서 적용해볼만한 방법이지 않을까 싶습니다.
좋은 리뷰 감사합니다.
두가지 질문이 있습니다.
“Kernel의 패턴은 일반적으로 관측되는 boundary의 패턴을 matrix로 만들어서 사용”한다고 하셨는데, 그럼 이 matrix가 그림의 Conrastive Kernel의 값으로 정해져있는 값이 맞나요??
또한 Boundary Contrastive Loss에 대한 그림을 보면 노란 영역은 유사해야하는 영역이고, 파란 영역은 유사히지 않아야 하는 영역으로 보이는데, 노란색의 각 부분을 나눠서 각각이 유사하도록 하는건지 궁금합니다.
네 matrix는 [그림 1]에서 볼 수 있듯이 이벤트의 경계지점에서 발생되는 패턴이 존재하는데, 이 패턴을 바탕으로 해서 정해진 값을 사용합니다. 영역은 각각 나누는건 아니고 색깔별로는 함께 평균 내서 사용합니다. 더 복잡한 방법도 있지만, 여러가지를 감안해서 지금 방법도 충분히 성능이 나온다고 하네요.