오늘 제가 리뷰할 논문은 TSP입니다. 이미 황유진 연구원님과 임근택 연구원님께서 해당 논문에 대한 리뷰를 작성해주셨지만, 현재 ActivityNet 데이터셋에 대한 TSP feature를 추출하는 실험중에 있어 다시 한 번 자세히 읽고 리뷰를 작성해보았습니다.
Introduction
먼저 저자들이 제기한 문제점을 살펴보겠습니다.
비디오는 이미지보다 훨씬 더 많은 정보량을 포함하고 있고, 각 비디오의 길이도 서로 다릅니다. 그렇기 때문에 모든 픽셀을 다 살펴보며 여러 task를 진행할 수 있는 이미지와 다르게, 비디오는 비디오 전체를 인코딩하는 것이 비효율적이라는 특성을 갖습니다.
이 논문은 2020년에 게재되었는데, 그 당시 비디오 도메인의 Temporal Action Localiztion(TAL) task에서 SOTA 방법론들은 이러한 비효율성을 극복하기 위해 사전 학습된 인코더로부터 추출되어있는 video feature를 가져다 여러 task에 적용하게 됩니다.
바로 이 때 사용한 사전 학습된 인코더에 문제를 제기하는데, 이 인코더는 Trimmed Action Classification(TAC) task에서 사용되는 큰 dataset인 Kinetics, Sports-1M으로 사전 학습된 인코더입니다.
TAC와 TAL의 근본적인 차이로부터 저자가 제시한 문제점이 발생합니다. TAC는 trimmed video에 등장하는 action이 어떤 행동인지 분류하는 task이고, TAL task는 untrimmed video를 대상으로 action이 몇 초부터 몇 초에 존재하는지 예측하는 temporal localization과 그 action의 label까지 분류하는 task입니다.
trimmed video와 untrimmed video의 차이점에 대해 추가적인 설명을 드리자면, TAC task에서 trimmed video의 길이가 10초이고 action label이 swimming이라면 0초부터 10초까지 전부 swimming action이 등장합니다. 반면에 TAL task의 untrimmed video는 trimmed video와 다르게 영상에 background로 분류되는 부분이 존재하고, 그로 인해 한 비디오의 길이가 훨씬 길다는 특성을 가집니다.
이렇게 TAC와 TAL은 목적이 서로 다른 task인데, TAC task에서 사용되는 dataset으로 사전 학습된 인코더로부터 추출한 feature를 TAL task에 사용하는 것은 temporally-insensitive하다는 단점을 가지게 됩니다.
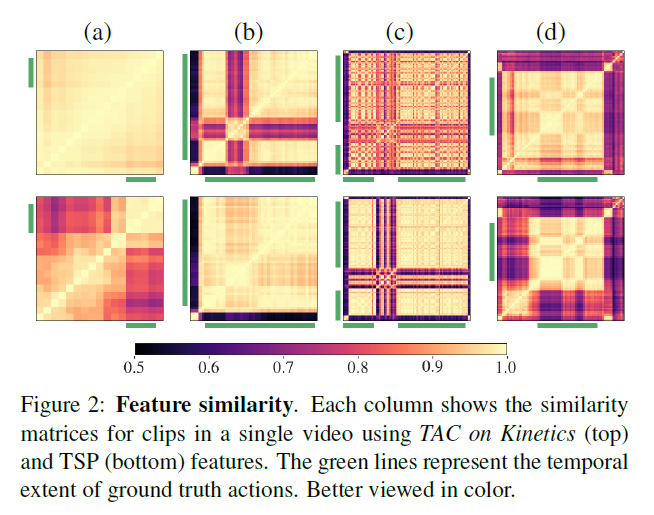
feature가 temporally insensitive 하다는 것은 하나의 untrimmed video 내 존재하는 foreground(action)과 background로부터 추출한 feature의 구별력이 떨어짐을 의미합니다.(그림 1) 이것은 temporal localization task에서는 부정적인 영향을 줄 수도 있는데요, 이러한 문제를 해결하기 위해 비디오의 시간 축과 관련 있는, 즉 비디오 전체 흐름 속에서 foreground와 background를 구분할 줄 아는 인코더를 학습시켜야 할 것입니다.
Technical Approach
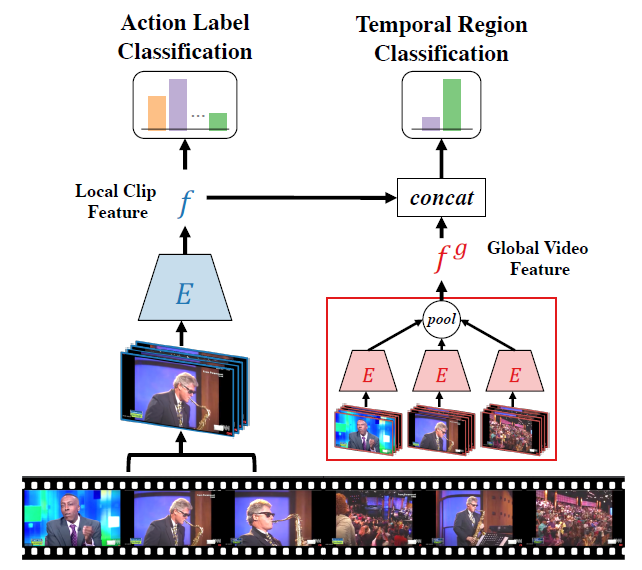
그렇다면 앞서 정의한 문제들을 어떻게 해결할 수 있을까요? TSP 방식의 feature는 untrimmed video의 foreground clip, background clip, global video feature(GVF)를 모두 사용해 학습한 인코더로부터 추출됩니다.
좋은 인코더는 두 가지 조건을 갖춰야 하는데, 첫 번째 조건은 클립에 포함되는 action이 어떤 label인지 잘 구별해낼 수 있어야 하는 것이고 두 번째 조건은 클립이 foreground인지 background인지 잘 구별해내야 하는 것입니다.
input clip이 들어왔을 때 단순히 그 클립의 action label이 무엇일까에 관한 feature를 추출하는 것이 아닌 클립을 포함하는 비디오 속에서 그 클립이 어디에 있는지, context까지 포함하는 feature를 추출할 수 있는 방향으로 인코더를 학습시키겠다는 것이 TSP의 목적입니다.
Input data
temporal annotation이 존재하는 untrimmed video로 인코더를 학습시킵니다. untrimmed video가 입력으로 들어왔을 때, 3*L*H*W의 고정된 크기를 갖는 클립 X를 샘플링합니다. 3은 RGB 3채널, H, W는 각각 프레임의 height와 width, L은 하나의 클립이 갖는 프레임의 개수를 의미합니다.
클립 X에 대해 temporal annotation에 따라 2가지 라벨 y^c, y^r을 할당해줍니다.
- y^c: C개의 action 중 몇 번 action인지 나타내는 action class label
- y^r: foreground인지 background인지 나타내는 binary temporal region label
Local and global feature encoding
TSP가 어떤 파이프라인으로 효과적인 encoder를 학습시키는지 살펴보겠습니다.(그림 2)
인코더 E를 통해 클립 X를 크기 F의 local feature vector f로 인코딩해줍니다. 이 때 인코더 E는 kinetics dataset으로 사전 학습된 ResNet3D 또는 R(2+1)D 중 하나에 해당합니다.
또한 하나의 untrimmed video에 속하는 클립들의 집합을 {X_i}라고 할 때, {X_i}에 속하는 모든 클립을 각각 E를 통해 인코딩한 후 maxpooling을 수행함으로써 하나의 비디오의 전체 context를 내포하고 있는 global video feature(GVF) f^g를 얻게 됩니다.
짧은 클립 X만을 학습에 사용한다면 비디오 속에서 X가 어떤 context를 가지는지 판단하기 어려운데, X와 f^g를 합쳐 사용함으로써 X가 foreground에 속하는지, background에 속하는지에 대한 정보를 줄 수 있습니다.
Two classification heads
앞서 X에 할당했던 두 개의 라벨에 대해 각각 하나씩 classification head를 갖습니다.
- W^c: F*C 크기의 FC Layer. F는 feature size, C는 전체 action class의 개수
어떤 action인지에 대한 분류기 역할 - W^r: 2F*2 크기의 FC Layer. F는 local feature와 GVF를 concat한 feature의 size, 2는 클립이 foreground인지 background인지에 대한 binary class
action인지 아닌지에 대한 분류기 역할
Loss
각 클립 X에 대한 loss는 아래와 같이 계산됩니다.
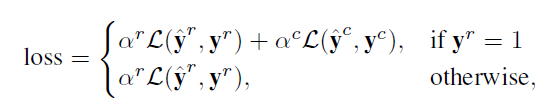
L은 cross-entropy loss이고 클립이 foreground라면 action class에 관한 loss도 함께 더해 계산해주고, background라면 region label에 대한 loss만 계산해줍니다.
Experiments

그림 3을 통해 알 수 있듯 논문에서는 다양한 조건들 속 TSP의 효과를 확인할 수 있었습니다.
Task에 따른 성능 측정
3가지 task에서 TSP feature를 사용했을 때와 기존 TAC feature를 사용했을 때의 측정된 성능을 보겠습니다. 인코더는 R(2+1)D-34, task 별 알고리즘은 각각 순서대로 G-TAD, BMN, BMT을 사용했다고 합니다.

모든 task에서 TSP feature를 사용한 것이 TAC feature를 사용했을 때보다 더 좋은 성능을 기록한 것을 확인할 수 있습니다. TSP feature를 추출할 때 GVF를 사용하지 않았음에도 모든 task에서 TAC feature보다 성능이 높은 것으로 보아 학습 시 negative sample인 background를 함께 주는 것이 성능 향상에 굉장히 효과적이었던 것으로 이해할 수 있겠습니다. 또한 모든 task에 대해 TSP feature가 성능 향상을 보였으므로 일반적으로 TSP가 localization task에 더 효과적인 feature임을 알 수 있습니다.
Encoder에 따른 성능 측정
각 feature를 추출한 후 G-TAD 알고리즘으로 ActivityNet dataset의 Temporal Action Localization task를 수행했을 때 어떤 인코더를 사용하였는지에 따른 성능 비교입니다.

ActivityNet에 대한 TAL 성능을 측정한 것이므로 당연히 Kinetics보다 ActivityNet TAC feature가 전반적으로 높은 성능을 보일 것임을 예상할 수 있었습니다. 따라서 그보다는 ActivityNet TAC feature로 사전학습된 인코더로부터의 feature와 ActivityNet TSP feature로 사전학습된 인코더로부터의 feature 간의 성능을 비교해보면 TSP feature가 꽤나 더 높은 성능을 보이는 것을 확인할 수 있었습니다. 결론적으로 TSP feature가 확실히 temporal localization task에 더 적합하다는 것을 알 수 있습니다.
나머지 실험들도 마찬가지로 여러 dataset이나 알고리즘에 대해 TSP feature가 일반성을 가진다는 것을 보여줍니다.
Conclusion
논문에는 제가 리뷰에 작성한 것보다 훨씬 더 다양하고 많은 방법론들과의 비교 실험과 분석이 포함되어 있으니 궁금하신 분들은 참고하시면 좋을 것 같습니다.
논문을 읽으며 이론적으로 어렵거나 대단한 방법론이 들어가있진 않다고 느껴졌습니다. 또한 저자가 제기한 문제에 대해 생각해보았을 때는 어떻게 보면 당연하게 개선되어야 할 문제로 받아들였습니다.
하지만 잘 생각해보니 이러한 아이디어를 떠올려내기 위해서는 그 순간 해당 분야의 연구가 어디까지 어떻게 이루어졌는지 전반적으로 파악하고 있어야 할 뿐만 아니라 아이디어에 대한 철저한 실험과 분석을 통해 본인의 아이디어가 맞다는 것을 입증하는 과정까지 있어야한다는 것을 다시 한 번 느꼈습니다. 저도 새로운 아이디어를 구상해볼 수 있게 될 때까지 계속해서 비디오 분야의 논문을 읽어나가야겠습니다.
리뷰 잘 읽었습니다. 궁금한 것은 아니고, 이러한 고민을 했으면 좋겠다는 생각에 댓글을 답니다.
1. 결국 Localization Task에 적합한 사전학습 방법을 제안한다고는 했지만 사전학습의 Task는 Classification으로 진행됩니다. 이런 경우에 정말로 Localization에 적합한 사전학습 방법론이라 볼 수 있을까요?
2. TSP는 ActivityNet에 대해서 사전학습을 하고 Downstream Task에 대해서 finetuning을 진행합니다. 이런 경우에는 타 방법론들과 Reasonable한 비교를 할 수 있을까요?
리뷰 잘 봤습니다. temporal locaization에 대한 정의와 그 방법론에 대한 것을 논문에서 다루셨는데요. 결국은 action인지 background인지를 판별하는 크기의 최소 단위가 clip의 크기만큼으로 결정되는 것으로 보입니다. 클립의 크기에 따른 localization 성능 차이에 따른 비교는 없나요?
아직 많은 video 관련 논문을 읽은 것은 아니지만, 통상적으로 한 클립의 크기를 16 frame으로 잡고 방법론을 적용하는 경우가 대부분인 것 같습니다. 논문에 한 클립의 크기를 16 frame으로 지정한 이유나 다양한 clip size에 따른 성능 비교는 언급되어있지 않았습니다.