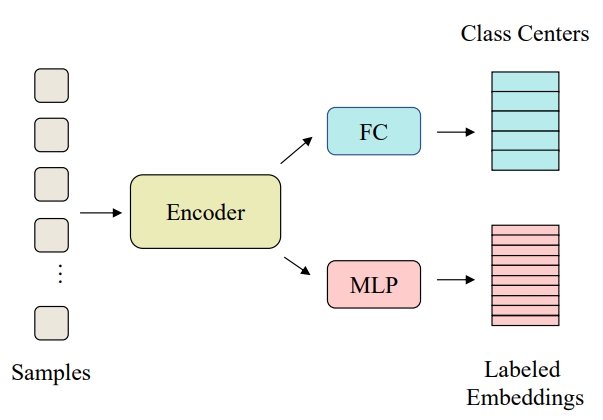
본 논문은 semi-supervised learning 방법론에 관한 논문이다. 본 논문은 semi-supervised 방식의 핵심 접근법 중 하나인 consistency regularization을 instance-level과 semantic-level 로 동시에 적용하였다. 이를 통해 ImageNet 1%와 10%를 이용한 semi-supervised 에서 각각 67.2%, 74.4%의 높은 성능을 거두었다.
- Preliminaries
대부분의 semi-supervised learning 방법론들은 labeled loss(수식1)와 unlabeled loss(수식2)로 구성된다. H가 네트워크를 의미할 때 labeled data는 x의 pair ground truth인 y와 x에 대한 네트워크의 출력값이 같아지도록 학습한다. 또한 unlabeled data는 데이터 x를 약하게 transform한 x^w(w: weak)와 x^s (s: strong)에 대한 네트워크 출력값이 유사해지도록 학습한다. 즉 P^w가 P^s의 pseudo-label이 된다. 이때 (수식2)에서 DA()는 pseudo-label들의 분포 균형을 위한 distribution alignment 과정이다. 즉 pseudo-label로 사용될 P^w를 평균값인 P^w_avg로 조정한 Normalize(p^w/p^w_avg)를 사용하였다. 다른 논문에서는 P^w를 pseudo-label로 사용하기 위해 one-hot version으로 가공하거나 sharpening을 하기도 한다. 해당 과정은 예측값이 지정된 class에 해당하도록 학습하는 과정으로 sematic-level learning에 가깝다.
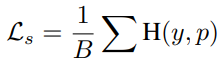
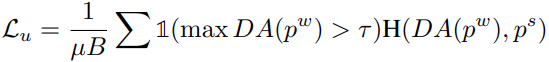
2. Instance Similarity Matching
다음으로 instance-level level의 학습을 진행하는데 해당 과정은 strong augmented view와 weakly augmented view가 같아지도록 학습하는 것으로, 앞선 unlabeled data를 위한 loss와 유사하다고 생각할 수 있지만, 앞선 것은 결국 특정 class를 예측하기 위한 header를 이용하는 것으로 sematic-level learning이다. instance level learning을 위한 loss는 (수식3)과 같은데 weakly augment data에 대한 예측 분포와 strong augment data에 대한 예측 분포가 유사해지도록 학습한다. 이때 각 분포인 q_w와 q_s를 구하는 방법은 수식 4,5와 같으며 sim()은 각 데이터(x)에 대한 모델의 예측(z)에 대해 L2 방식으로 계산한다.
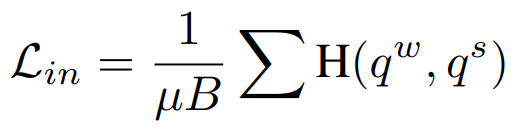
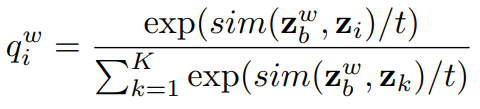
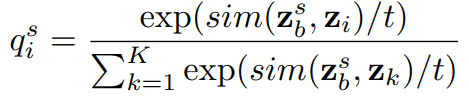
따라서 sematic level과 instance level의 유사도 학습을 진행하는 SimMatch의 loss는 (수식6)과 같다.
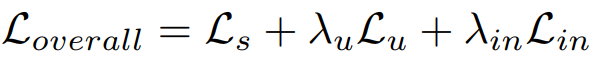
3. Label Propagation through SimMatch
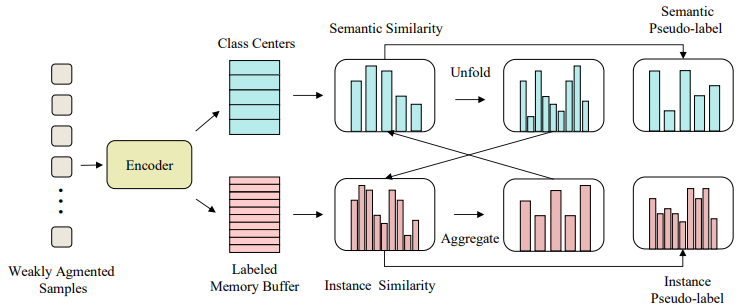
instance level loss는 완전한 ,unsupervised 방식으로 이루어지는데, semi-supervised에서 이는 사용가능한 labeled data의 정보를 버리는것과 마찬가지이다. 이를 개선하기 위해 instance level에서 class 정보를 사용하는 방법과 semantic similarity와 instance similarity간의 상호작용을 가능하도록 하였다.
해당 방법론은 이를 위해 labeled memory buffer를 생성했다. 이는 그림2의 붉은 블럭 부분 처럼 모든 예제를 저장한다. 수식5, 6에서 z_k는 이렇게 저장된 buffer속 데이터 중 하나로 써 각 하나의 class를 의미할 수 있다. 이때 이 instance 를 각 class로 다루는 인코더의 임베딩인 p와 semantic level의 인코더 q가 상호작용 할 수 있도록 unfold 관계가 되도록 한다. 즉, p가 semantic similarity를 q가 instance similarity를 의미할 때, q^w와 p^w간의 관계 보정을 위해서 p^w를 unfold한 p^unfold라고 하면 아래와 같은 관계를 만족하도록 한다.
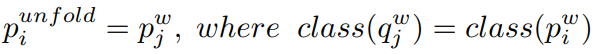
이를 만족하도록 instance-level learning의 q를 다음과 같은 수식으로 보정한다.
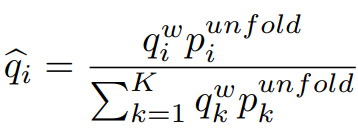
또한 sematic-level의 learning을 위한 p 또한 다음과 같이 보정한다.
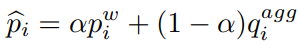
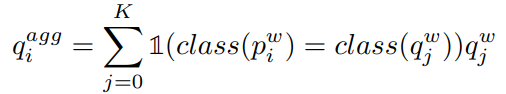
해당 보정은 두 특징값의 앞서 설명한 관계성을 갖게하기 위함이다.
4. 실험 결과
유명 데이터셋에 대해 아래와 같이 기존 방법론 대비 SOTA의 성능을 거두었다.
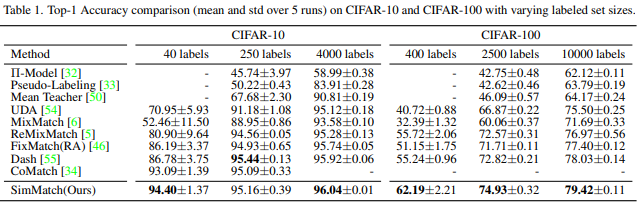
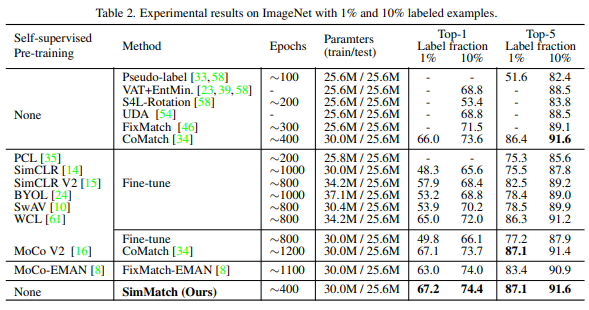
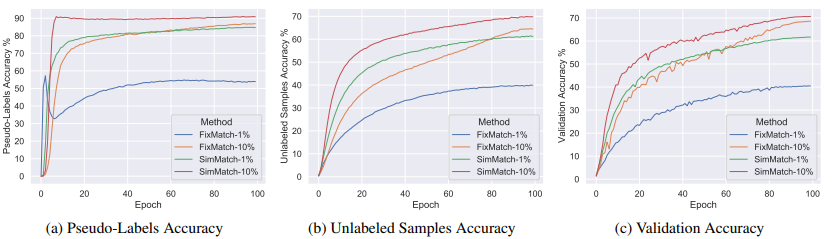
또한 semi-supervised 분야에서 2019년에 나왔지만 높은 성능을 보이는 fixmatch와 비교했을때 다음과 같은 차이를 보이며 방법론의 우수성을 보였다.
좋은 리뷰 감사합니다.
결국 SimMatch 가 FixMatch를 능가한 것으로 보이네요. 그런데 그 두 방법론의 가장 큰 차이라고 한다면 무엇일까요? 왜 성능을 능가하였고, 혹시 우리가 돌릴 수 있는 것인지… 궁금해지네요!