최근 데이터셋을 가공을 하면서 Unknown object에 대한 bounding box를 효율적으로 칠 수 있는 방법이 필요해졌습니다. 그래서 여러 방법을 둘러보고 있었는데요. 어차피 자동으로 할 수 없다면, 아래에서 읽는 방법 정도가 최선의 선택인 것 같아서 논문을 한번 읽어봤습니다. point를 찍으면 해당 영역에 대해서 segmentation을 수행해주는 방법론입니다.
Introduction

본 논문에서 다루는 Salient object detection(SOD)는 인간의 attention mechanism을 이용해서 관심 영역을 찾는 것을 목적으로 합니다. 이 연구 분야에서도 많은 연구가 진행되었지만, 결국 최종적인 문제로 정확한 학습을 위해서는 pixel-wise annotation이 필요하다는 문제점, 이 문제점을 우회하려는 방법론들 (image-level label로 학습하거나, noisy label을 이용한 생성 방법론, 라벨링을 빠르게 할 수 있는 방법론 등등) 모두 만족스러운 결과를 얻지는 못했습니다.
이러한 관점에서 봤을 때, 이 논문 저자들은 point supervised saliency detection을 제안합니다. 이 방법론은 [그림 1]과 같이 기존의 scribble annotation(선으로 라벨링)에 비해서 점만 찍으면 되는 간편한 방법론입니다.
그래서 아래와 같은 컨트리뷰션을 가지는데요. 자세한 내용은 방법론을 설명하면서 같이 정리해보겠습니다.
- P-DUTS(논문 저자들이 제안한 새로운 포인트 기반 데이터셋)을 기반으로하여 단일 점 라벨링으로 salient object를 탐지할 수 있는 weakly-supervised salient object detection 프레임워크 제안
- 관심 물체가 아니지만, 탐지된 물체를 필터링 할 수 있는 NonSalient object Suppression(NSS) 제안
- Adaptive flood filling을 결합한, 성능이 좋은 transform-based point supervised SOD 모델 제안
Methodology
Adaptive Flood Filling
가장 흔하게 weakly-supervised dense prediction task에서 pseudo-label을 만들어 학습에 쓰는 방법을 이용합니다. 이러한 방법의 문제점은 모델이 비교적 작은 커버리지를 가진다는 문제점이 있었습니다. 그래서 이 논문에서는 edge를 이용합니다. 단순히 이용하는건 아니고, edge detector를 이용해서 edge를 탐지한 다음에 “Flood Filling”을 수행합니다.
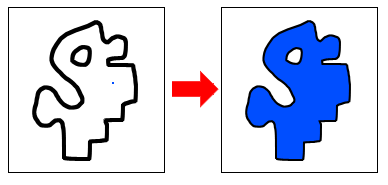
참고로 Flood Filling은 배열에서 어떤 칸이 있을 때 연결된 칸을 찾는 알고리즘입니다. 위의 그림과 같이 작동한다고 보시면 좋을 것 같습니다. Edge에 이러한 Flood Filling을 수행하면, object 안은 채워지고 밖은 비어있는 mask가 만들어지게 됩니다. 문제는 edge가 항상 잘 탐색되는건 아니라서 선에 구멍이 있으면 이미지 전체가 채워지는 문제점이 있는데요.
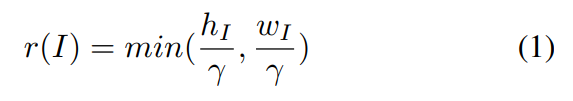
이러한 문제점은 radius r을 기반으로 하는 adpative mask로 이것을 만드는 것으로 해결했습니다. (γ는 하이퍼 파라미터) S = \{S_b,S^i_f | i = 1, ..., N\}라고 i번째 픽셀을 가지는 이미지를 표현할 때, 그럼 이렇게 이미지 영역을 background와 object로 구분할 수 있습니다. (b는 background고 f는 labeled salient object) 그럼 이 구분한 영역에 대한 M^{r(I)}S = C^{r(I)}_{S^1_f}∪· · ·∪C^{r(I)}{S^N_f} ∪ C^{r(I)}{S_b}라는 circle mask를 정의하는데요. (C는 아래쪽 모서리를 중심으로 위쪽 모서리를 반지름으로 사용하는 원을 뜻함)
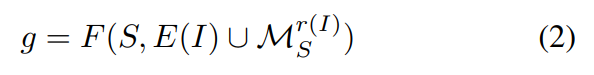
그럼 이제 flood filling을 이용하는 방법에 대한 기본 설명이 끝났습니다. 최종적인 목표는 edge 정보와 점으로 라벨링된 정보를 flood filling을 이용해 보정해서 pseudo label을 만드는 겁니다. [수식 2]는 이러한 라벨 생성 과정을 나타냅니다. F라는 flood filling 함수가 있을 때, 이미지의 GT S와 Edge 정보 E 그리고 circle mask M을 이용해서 pseudo-label을 생성합니다.
알고리즘도 … 있는데 관심 있으신 분들은 참고하시면 좋을 것 같습니다.
Transformer-based Point Supervised SOD Model
Sparse한 라벨 정보만으로 saliency detection을 수행하는데 가장 큰 문제점은 gt로 부터 얻을 수 있는 global information이 부족하다는 문제점이 있습니다. 그래서 이 논문에서는 [그림 1]에서 처럼 점을 2개 찍는데요. 그 포인트 끼리의 self-similarity를 바탕으로 이 문제를 해결했다고 합니다.
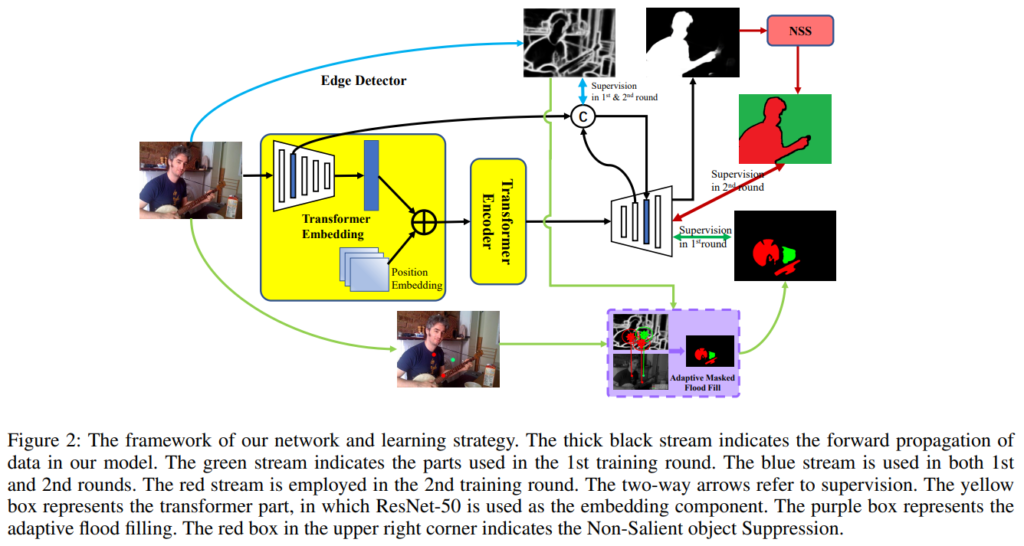
기본적으로 백본의 경우에는 Transformer를 사용하고 있는데요. 중점적으로 볼만한 부분은 Edge-preserving Decoder입니다. [그림 2]와 이 논문 내용(Flood Filling)을 보면, Edge 정보를 살리는 것이 중요한 포인트인데요. 이 과정을 위해 weak annotation을 가지고서 Edge를 잘 살릴 수 있는 모델을 만들었다고 합니다. 추가적인 설명이 있긴 한데, 모델에 대한 깊은 내용이라 관심 있으신 분들은 참고해보시는 것이 좋을 것 같습니다.
Non-Salient object Suppression(NSS)

Sparse한 라벨 정보만으로 weakly supervised 학습을 하면서 생기는 또다른 문제점은 위의 그림을 보면 알 수 있습니다. 보면 빨간색 박스로 표시된 부분들이 관심물체가 아님에도 불구하고, 탐지된 물체들입니다. (모델이 인식하는 물체가 모호해질 수 있음)

그래서 등장한 방법론이 [그림 3]의 a와 b에서 볼 수 있는 NSS입니다. NSS는 non-salient object를 suppress하는 방법론입니다. 주어진 GT 포인트를 확장시켜서 물체를 강조하고, 이를 통해서 non-salient object를 없앤다고 보면 됩니다. (겸사겸사 Edge 정보에 대한 보완도 같이 하는 것 같습니다.)
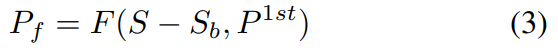
정확하게는 [수식 3]과 같이 작동하는데요. $P^{1st}$는 첫번째 학습 이후에 만들어진 saliency map입니다. (S는 GT 정보 / F는 flood filling) 결국은 Adaptive Flood Filling에서 설명한 내용이랑 좀 겹치긴 해서 이정도만 설명하겠습니다. NSS가 실제로 작동하는 부위는 [그림 3-b]의 검은색 부분을 보면 됩니다.
Loss Function
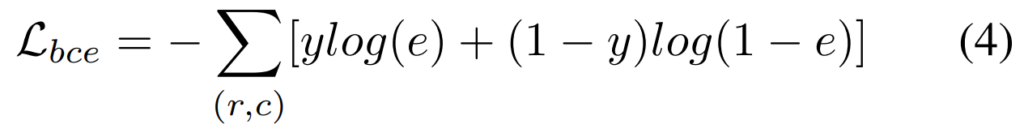
학습은 총 3가지 Loss를 사용합니다. BCE와 PBCE, 그리고 gated RCF Loss 입니다. BCE Loss의 경우에는 Edge-preserving decoder stream에서 사용하고, PBCE와 gated RCF Loss의 경우에는 saliency decoder stream에서 사용하는데요.
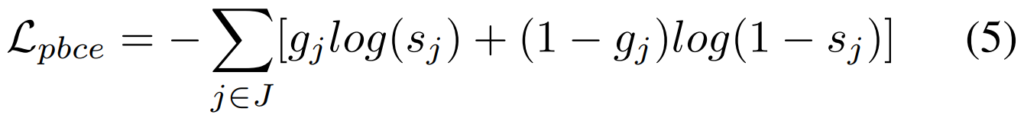
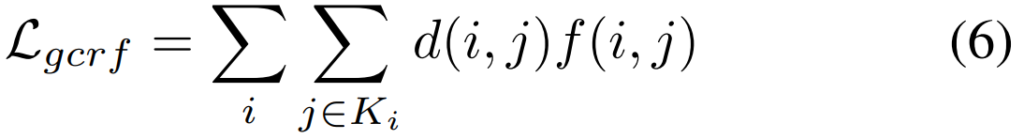
BCE Loss는 흔하니까 넘어가고… PBCE같은 경우에는 partial binary cross entropy loss로, 정보량이 확실한 영역에 대해서 모델이 좀 더 학습을 집중하게 하기 위해 도입했습니다. 그래서 비교를 할 때 보시면 J를 통해 비교를 하는데요. 이 J는 라벨된 영역에 대한 것만 Loss에서 비교하고 있는 것을 볼 수 있습니다. (여기서 라벨링된 영역은 확실하게 물체라고 점이 찍었던 그 영역 혹은 확실하게 백그라운드라고 점을 찍었던 그 영역만 나타냅니다) 그리고 gated CRF같은 경우에는 object structrue와 edge를 잘 살리기 위해 도입했다고 합니다. 여기 d는 L1 loss이고, f는 Gaussian kernel bandwidth filter라고 하네요.
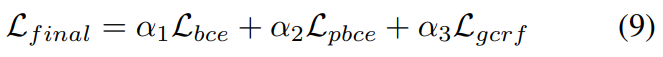
최종적으로는 가중치 알파에 다 1을 넣어서 최종 Loss로 사용했다고 합니다.
Experiments
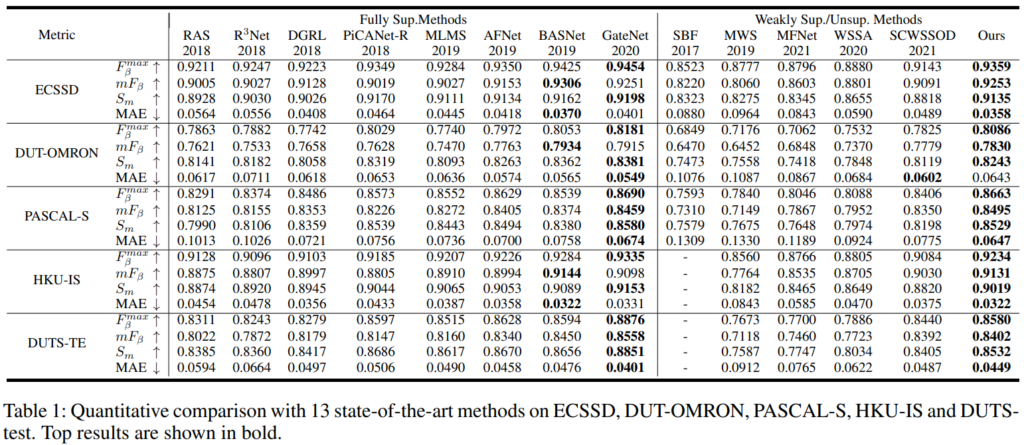
정량적인 결과를 보면 일단 크게 지도학습과 아닌 것으로 나뉘어 있는데요. Unsupervised도 분리를 해야 공정한 평가가 아닌가 싶긴 한데… 아무튼 SCWSSOD 방법론 같은 경우에는 선으로 된 라벨링을 사용하는 wealky supervised 방법론임을 감안하고 성능 차이를 보면 좋을 것 같습니다.

정성적인 결과를 봤을 때도, NSS가 잘 작동해서 관심 물체가 아닌 물체들을 잘 제거하는 모습을 볼 수 있습니다.
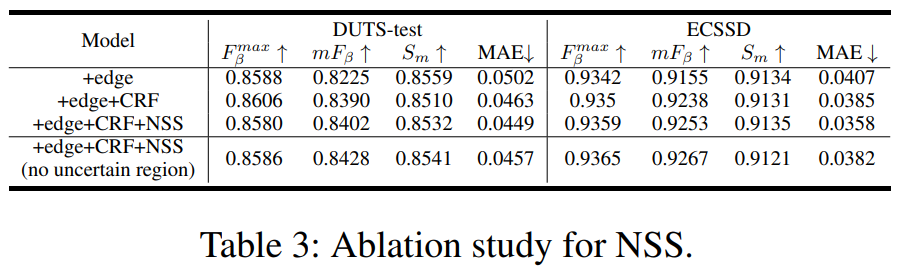
이 부분에 있어서도 NSS가 실제로 성능을 부스팅하는데 유의미한 역할을 하는 것을 실험을 통해서도 확인할 수 있습니다.
안녕하세요 좋은 리뷰 감사합니다.
adaptive flood filling 알고리즘을 적용할 때 생길 수 있는 문제점을 보완하기 위해 adaptive mask를 적용하게 되었다고 하셨습니다. 어떻게 adaptive mask가 작용하여 이미지 전체가 채워지는 문제를 해결해줄 수 있는 것인지 잘 이해가 안되는데 간단하게 추가 설명 해주실 수 있으신가요?
1번 수식을 통해서 circle mask를 만드는데, 이 값을 가중치 같이 사용한다고 생각하시면 될 것 같습니다. 이어지지 않는 선의 edge의 좁은 구멍은 이 가중치 값에 의해 이어진 선으로 보는 방식입니다.
상당히 흥미로운 논문이군요.
한가지 궁금한 점은 지금 해당 방법론의 평가 결과들을 살펴보니 마치 ImageNet과 같이 어떠한 foreground가 메인으로 자리잡는 데이터를 위주로 평가하는 것 같은데, 혹시 도로 주행환경 같이 다양한 foreground가 나오는 복잡한 환경에서의 평가 결과는 따로 없나요?
도로 주행 환경은 너무 복잡해서 아직 이 방법론으로는 어려울 것 같고요. 대부분 ImageNet에서 볼 수 있는 이미지 정도의 레벨이라고 생각하시면 좋을 것 같습니다. 그리고 아마 물체가 여러개인 상황에 작동한다는 보장이 없는 듯 합니다. 결국은 내가 라벨링한 점을 기반으로한 관심 물체를 segmentation하는 것인데, 점을 바탕으로해서 물체가 많아지면 그만큼 학습이 잘 될까라는 의문이 있긴 하네요.
좋은 리뷰 감사합니다.
gt로 부터 얻을 수 있는 global information이 부족하다는 문제점을 해결하고자 점을 2개 찍고, 그 점끼리의 self-similarity를 바탕으로 문제를 해결 했다는 부분에서, self-similarity가 어떤 것인지 알 수 있을까요?
그리고 이 방법론을 현재 하고계시는 annotation에 적용하시 생각이신가요?? 아니면 그냥 지금처럼 계속 진행하실 계획이신가요? ㅎ
단순하게 생각하면 물체와 아닌 영역의 점끼리는 유사도를 계산하면 낮게 나오겠죠? 그러한 맥락에서 비교를 할 때, 다른 이미지의 물체 혹은 배경과 비교하는 것이 아니라 같은 이미지내의 포인트끼리의 비교라서 self-similarity라고 논문 저자가 말하는 것 같습니다. 그리고 annotation은… 시간 나면 해보려고 했는데요. 손이 생각보다 느려서 ㅎ;; 일단 없이 하고 나중에 꼭 필요하다면 이런 방법론을 시도해보려고 합니다.
좋은 리뷰 감사합니다. 점을 통해 annotation을 진행한다고 하셨는데 기존에 이러한 방법론은 없었나요? 없었다면 점의 위치에 따른 성능 변화와 같은 분석이 있는지 궁금합니다.
점은 이게 최초고, 선으로 한 친구는 성능 비교에 보시면 나와있습니다. 점의 위치에 따른 성능 변화에 분석은 없는데요. (라벨링이 이미 되어있는 상태이기 때문) 차이는 없을 겁니다. 왜냐면 점이 어디에 찍히든 edge detector를 통해 나온 edge map을 기반으로 pseudo mask를 만들기 때문에, 그 edge 내의 물체에 찍혀있다면 mask는 동일하게 나오기 때문입니다.