오늘 리뷰할 논문은 RGB-D를 인풋으로 detection을 하는 그런 논문입니다.
해당 논문에서는 2D에서 확장하여 3D centroid를 구합니다.
3D centroid라고 한다면, 3D 좌표계상에서 물체의 중심점이라고 생각하시면 됩니다. 이때, Uniform한 밀도를 가졌다고 가정한다면 centroid는 무게중심과 동일합니다.
해당 논문에서는 코드를 공개 안 하고 있으며, 논문에서 사용한 데이터셋 또한 비공개입니다. 그럼에도 불구하고 해당 논문을 읽게된 이유는 이번에 작성중인 논문이 indoor 상황에서의 person detection이며, 해당 논문도 비슷한 주제를 다루고 있기 때문입니다. 다만, 차이점이라고 한다면, 저희 논문에서는 RGB-D 카메라를 사용하지않고, R-T-R-T 스테레오 카메라를 사용합니다. 개인적으로 느끼기에 driving scene에서의 pedestrian detection에 대한 연구는 활발히 진행되어왔으나, indoor 상황에서의 pedestrian detection 연구는 많지 않은거 같네요. 해당논문은 intralogisitics에서 촬영한 real 데이터셋을 사용하고있는데, 저희가 작업중인 논문에서 사용한 데이터셋하고 환경이 유사하네요.
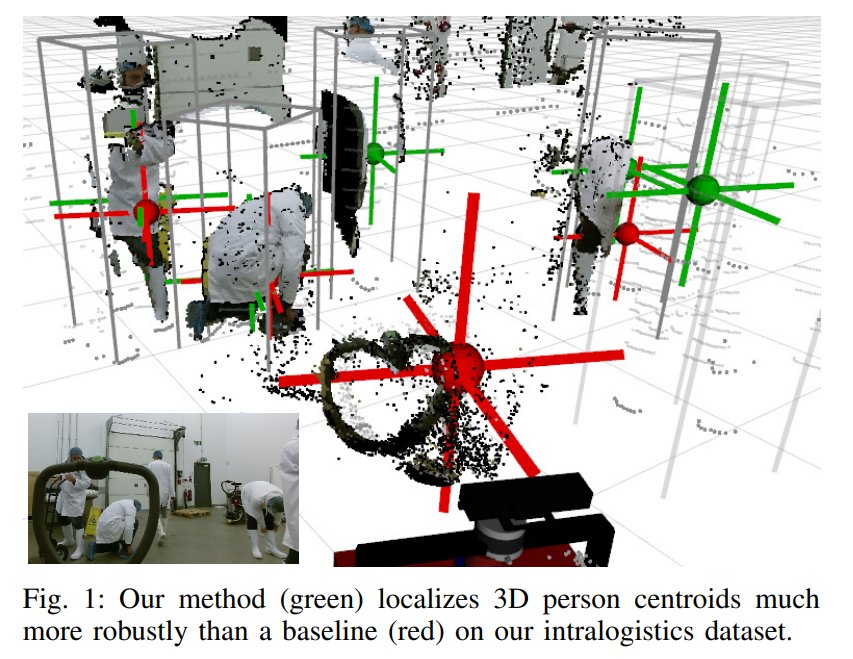
먼저 결과를 말씀드리면, 위의 그림과같이 2D detection에서 끝나는게 아니라 RGB-D 카메라로 취득한 뎁스맵 상에서 물체의 centroid를 추가적으로 regression합니다.
본 논문에서 주장하는 contributions는 아래와 같습니다.
- We demonstrate that accurate 3D localization under partial occlusion is an unsolved issue, which is an
important aspect e.g. for human detection in robotics. - We are, to our best knowledge, the first to propose an RGB-D fusion strategy for the fast YOLO v3 onestage detector, with an accompanying transfer learning strategy that leverages existing large-scale 2D datasets.
- Via heavy domain randomization, we are able to learn end-to-end regression of 3D human centroids from a
synthetically rendered multi-person RGB-D dataset. - We find that standard 2D crop/expansion augmentations are unsuitable for depth data, and propose a geometrically more accurate variant that accounts for the resulting shift of focal length.
- On our challenging real-world RGB-D dataset from the intralogistics domain, our method outperforms existing
baselines in 3D person detection without requiring additional hand-annotated 3D groundtruth for training.
요약하자면,
- 2D detection에서 끝나는게 아니라 3D centroid 까지 구하였다.
- RGB-D 카메라로 부터 얻은 depth정보를 활용하기 위해 YOLOv3를 최초로 변형하여 사용하였다.
- 기존 YOLOV3 알고리즘에서 사용하는 augmentation 기법을 depth센서를 추가한 셋업에 맞게 변형하여 사용하였다.
정도가 될 수 있겠네요.
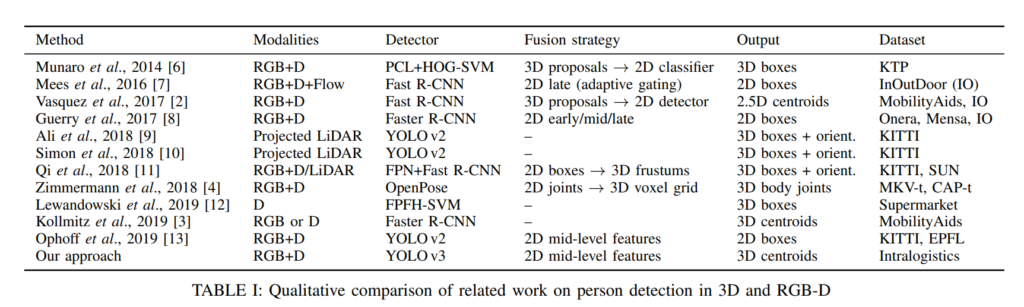
위에 표처럼 저자는 pedestrian detection 대표적인 방법들을 정리하였습니다. 가장 눈에 띄는 것은 dataset중에서 Intralogisitics는 한 개 밖에 없네요. 마침 저희가 작성중인 논문에서 사용하는 커스텀 데이터셋과 도메인이 겹치네요.

좀 특이한점은 해당 논문에서는 위의 그림처럼 시뮬레이션상에서의 synthetic dataset과 오른쪽 그림처럼 real dataset을 둘다 사용했다는 점 입니다. synthetic dataset에서 학습하고 real 데이터셋으로 fine-tune한듯하네요.
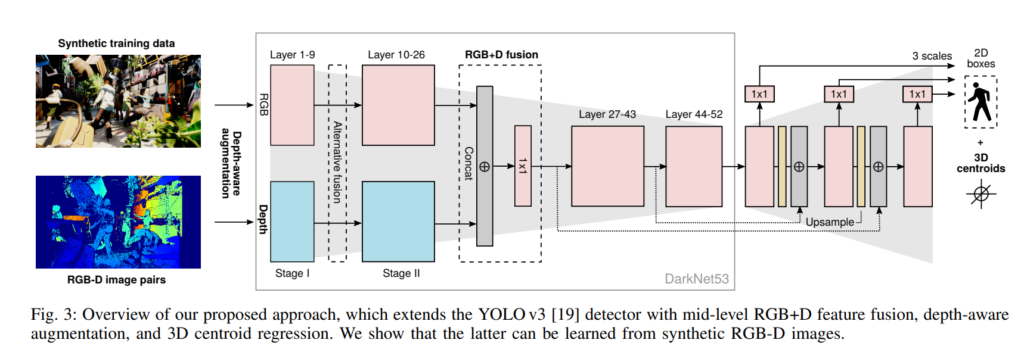
전체적인 아키텍쳐는 위와같이 구성하였습니다. YOLOv3를 베이스로 하였으며, RGB-D image를 추가로 사용하였습니다. 그리고 output에서는 3D centroid에 대하여 추가로 regression합니다. 사실 크게 어려울게 없고, Halfway Fusion하고 컨셉이 비슷합니다. 다만 output에서 3D centroid를 아웃풋으로 가지며, RGB-D depth를 GT로 regression 하여 학습합니다.
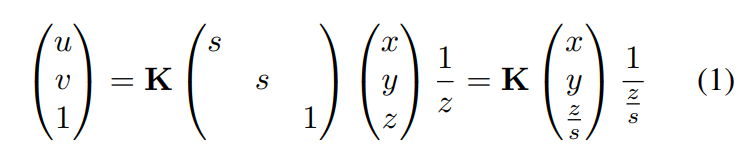
다만 YOLOv3에서 사용하는 augmentation 중에서 zoom in & zoom out을 그대로 사용하면 focal 이 변하기 때문에 depth도 같이 변경하여주는 depth-aware augmentation을 제안하여 사용합니다. 위에 수식에서 z는 depth, s는 zoom할때의 scale factor를 의미하고, K는 카메라매트릭스 입니다. Zoom in&out augmentation을 적용하였을때, s가 변하게 되는데 이때 z도 같이 변화를 주어서 focal이 변하는 것을 막은 augmentation 기법입니다. (참고사항으로 YOLOv3에서는 zoom in & out할때 s*s를 crop하여 zoom in or out합니다. aspect ratio가 1이므로 파라미터는 s만 존재합니다.)

centroid를 regression할 때의 loss는 직관적으로 RGB-D 카메라로부터 얻은 depth를 사용하였고, l1 loss를 이용하였을때 가장 성능이 좋았다고 합니다. 그리고 (2) 수식은 YOLOv3에서 사용하는 loss term과 비슷하기 때문에 제가작성한 YOLOv3 리뷰를 읽어보시면 이해하는데 도움이 될거 같습니다. 간략하게 설명드리자면, 모든 픽셀의 left top corner를 기준으로 anchor box를 형성하여 regression하는데 이때, 각 픽셀마다 regression하는 offset값을 0~1 사이로 바운딩 시킵니다. 마찬가지 원리로 centroid를 regression할 때도, offset 값을 0~1사이로 바운딩 시켜서 사용하였습니다.
개인적으로 생각하기에 YOLOv3 이후에도 많은 YOLO시리즈가 나왔고, 해당 sigmoid를 활용하여 0~1로 offset의 범위를 제한하는 방식은 0일때와 1일때를 표현할 수 없으므로 이를 개선한 논문이 있었는데 해당 논문에서 사용한 방식을 적용해봐도 좋을거같습니다.
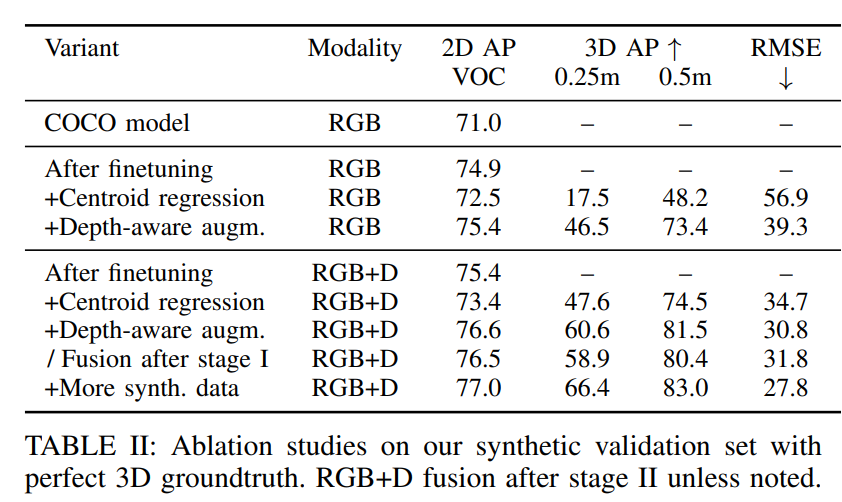
ablation study 결과입니다. experiment setup에서 데이터셋에관한 설명이 나오는데 무인지게차AGV 2대에서 실제로 데이터셋을 촬영하였다고 합니다. RGB-D 센서로는 Kinetec v2를 사용하였고, 촬영한 장소는 2 warehouses, small food factory, robotics lab, warehouse shelves 등으로 구성하였다고 합니다. indoor에서의 pedestrian detection에 대한 연구가 드문데 레퍼런스로 사용하기 좋은 논문인거 같습니다. ICRA라는 좋은 학회에 나온 논문이기도 하구요.
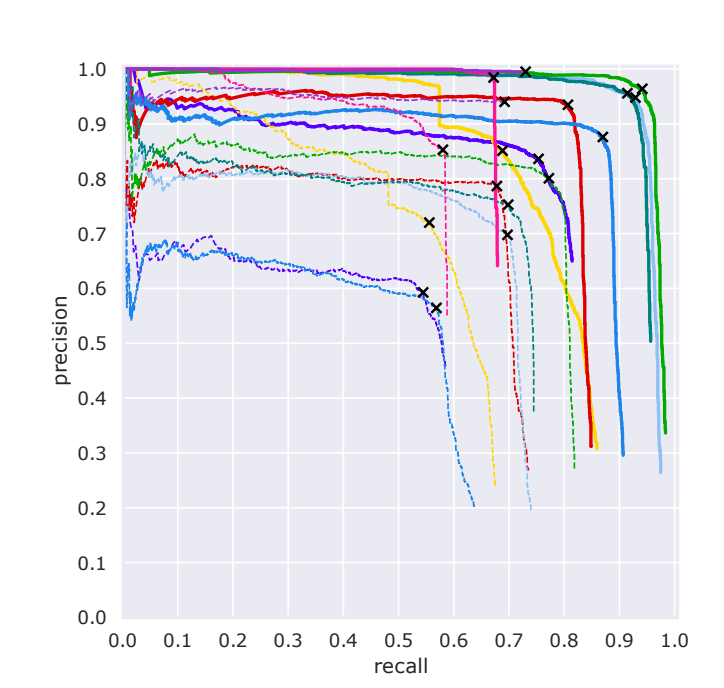
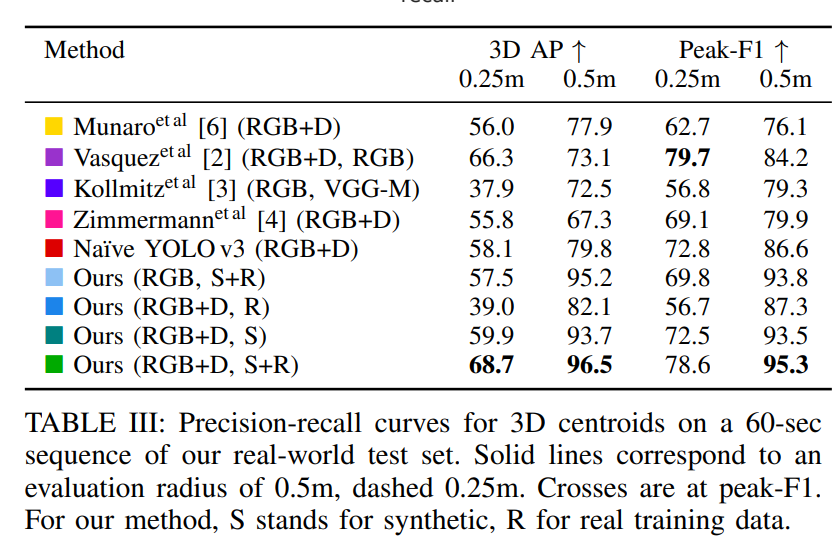
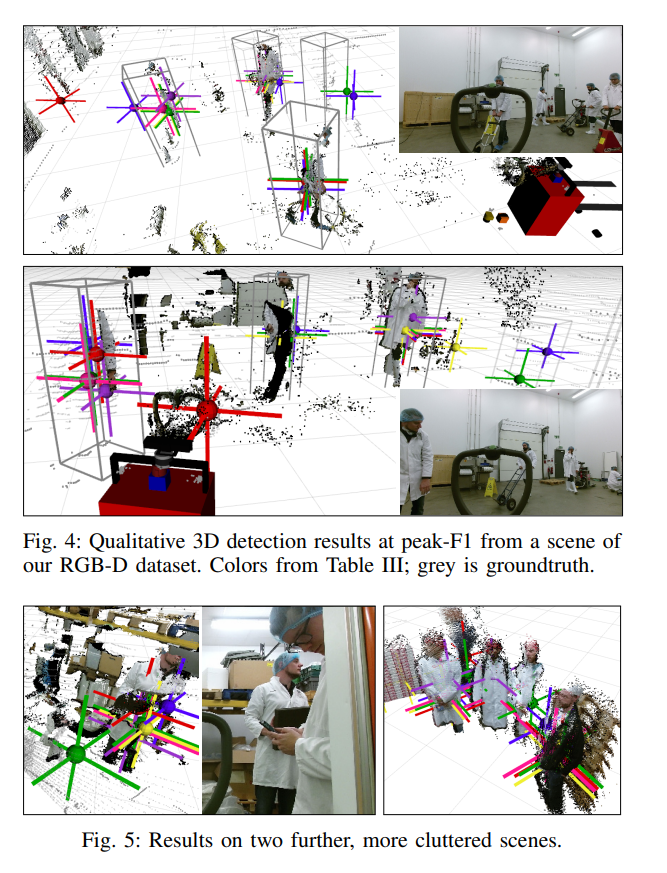
실험 결과에 대해서는 직관적이라 굳이 설명드릴 부분이 없을거 같습니다. 혹시 이해안가거나 궁금하신 부분이 있으면 질문에 남겨주시면 답변해드리겠습니다.
이번에 리뷰한 논문은 2020 ICRA에 발표된 논문으로 해당 저자는 2021에 IROS에도 논문을 제출하였습니다. 그리고 그 논문에서는 과연 Pedestrian detection을 할때, 환경마다 어떠한 센서조합을 사용하는 것이 정답일까에 대한 분석을 하였습니다. 기회가 되면 해당 논문도 리뷰해보는 시간을 가지면 좋을거같네요.
이상 리뷰마치겠습니다.
데이터셋 찍은 사진을 보니 뭔가 연구원들이 열심히 찍은 느낌이 드네요 ㅎㅎ… 궁금한 점은 그림 1의 앞으로 몸을 접고있는 사람의 케이스를 보면 실제 사람의 박스는 다른 사람들의 절반정도로 되어보이는데 box는 크게 그려져 있거든요. 이러한 것처럼 중심점만 사용하게 되면 사람의 모습에 따라 잘못된 중심점을 GT로 사용하고 있을 것 같은데, 이에 대한 내용은 논문에 없나요?