논문 요약
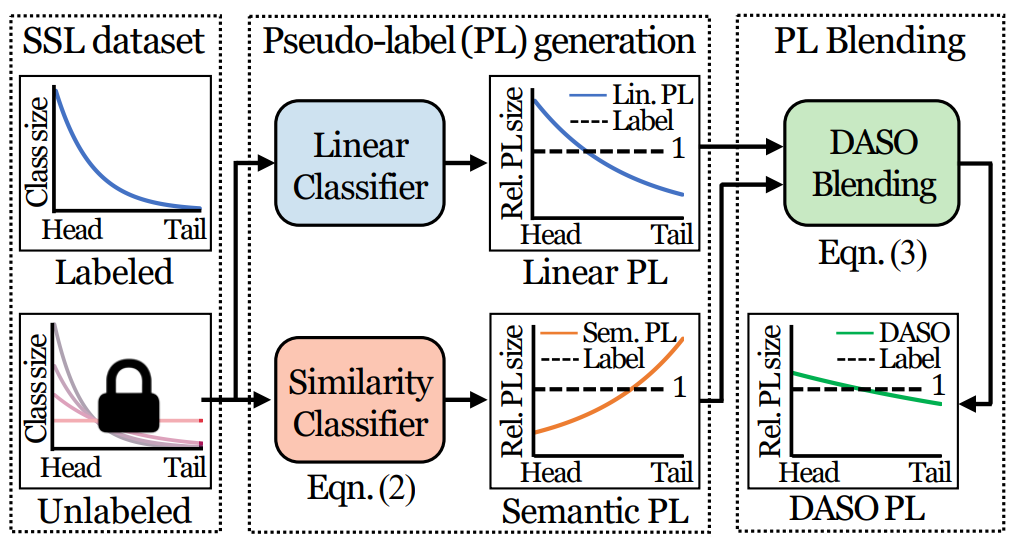
잘 가공된 labeled data와 unlabeled data는 분포차이(class distribution mismatch)나 편향(class imbalance)가 존재할 수 있다. 본 논문은 이러한 real-world application에서 발생할 수 있는 문제에 대응할 수 있는 프레임워크 Distribution Aware Semantics-Oriented(DASO)를 새롭게 제안하였다. 간단하게 이해한대로 소개하자면 해당 논문은 이러한 문제를 prototype pseudo label과 linear pseudo label을 distribution-aware blending 과정으로 통합한 새로운 pseudo label과 이를 해결할 수 있는 새로운 loss인 Semantic alignment loss를 제안하고 이를 통해 문제를 해결하였다. 또한 해당 제안점들은 기존의 다른 SSL(semi-supervised Learing)에 plug-in 할 수 있어 유용성을 더했다. 자세한 논문 소개는 아래와 같다.
Motivation
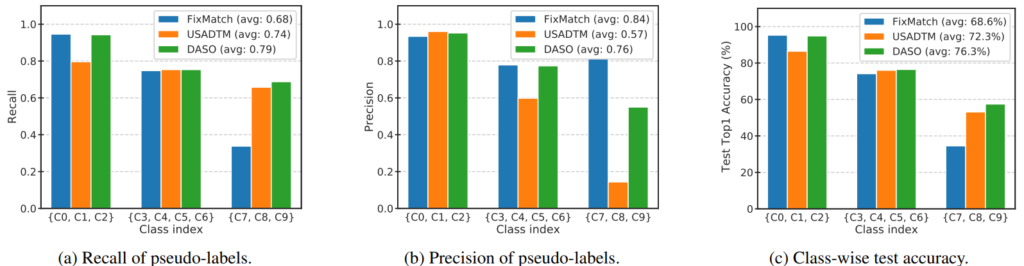
여태까지 semi-supervised learning에서 사용했던 pseudo label의 타입은 2개로 나뉠 수 있다. 논문의 표현을 그대로 사용하자면 linear pseudo label과 semantic pseudo label이다. fixmatch 에서는 각각 soft label과 hard label로 불렀던것 같은데, linear pseudo label은 모델의 예측을 그대로 사용하는 것이고 semantic pseudo label은 prototype과 같이 미리 정의한 class를 pseudo label로 사용하는 것이다. 즉 우리에게 친숙한 개, 고양이 문제에서 분류 모델 A로 생성한linear pseudo label은 (0.7, 0.3)이고 semantic pseudo label은 ‘개’ 인 것이다. 해당 논문에서는 semantic label type의 semi-supervised learning 대표주자로 USADTM[1]을, linear label의 대표주자로는 FixMatch[2]를 선정하여 두 방법론을 비교하였다. FixMatch와 USADTM는 모두 2020년 NIPS에 소개된 방법론이다. 각 논문에 대한 reference 또한 아래 남기겠다. 실험의 결과는 위 [그림1]과 같은데, 두 방법론 모두 class imbalanced 상황에서 소수 클래스에서 성능 하락을 보이긴 했으나 accuracy의 결과를 기준으로 semantic label type이 조금 더 강인했음을 알 수 있다. 그러나 semantic 방법론은 성능 상승의 한계가 있는 걸 알 수 있다. 예를 들어 recall 성능 비교에서 linear type과 제안하는 방법론은 다수 클래스에서는 높은 성능을 보인다. 그러나 semantic type은 그렇지 못하다. 이러한 분석을 기반으로 linear type과 sematic type을 적절히 blending해 상황에 최적인 pseudo label을 만드는 것이 해당 방법론의 하나의 제안점이다.
Method
Method의 소개 순서는 다음과 같다. 1.linear pseudo label 생성하기 / 2.Semantic pseudo label 생성하기 / 3. Distribution-aware blending을 통해 새로운 pseudo label 생성하기 / 4. Semantic alignment loss. 먼저 1, 2번은 기존 SSL 논문과 유사점이 많으며 제안하는 방법론의 최종 Loss는 [수식1]과 같다. 앞의 L_cls + (lambda)L_u 부분은 SSL 모델에 따라 바뀔 수 있으며 본 논문에서는 FixMatch를 base model로 이용하였다. 새롭게 제안하는 타입의 pseudo label은 L_u를 계산할 때 사용되며 L_aling은 semantic alignment loss로 이에 대한 효과는 ablation study의 table 5를 통해 확인할 수 있다.
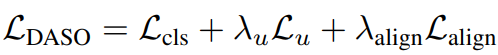
1.linear pseudo label 생성하기
이는 매우 간단하다. 모델에서 임베딩한 feature z를 softmax activation을 통해 각 클래스에 대한 확률 예측값으로 변환한다. 이것이 linear pseudo label이다.
![코드로 이해하는 딥러닝 9] - Softmax Regression(multiple classification)](https://blog.kakaocdn.net/dn/QGFKh/btqPQtew8NG/P5e54TRwt9fZqmXi55866k/img.jpg)
2.Semantic pseudo label 생성하기
sematic pseudo label은 임베딩 된 featre z와 미리 정의된 prototype C와의 유사도 비교를 통해 가장 유사한 prototype을 pseudo label로 한다. 이에 관한 수식은 아래와 같으며 유사도는 cosine 유사도를 이용하나 방법론에 따라 상이할 수 있다.
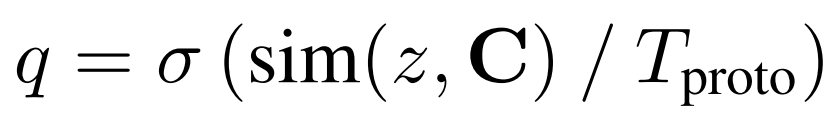
3. Distribution-aware blending을 통해 새로운 pseudo label 생성하기
blending 방식은 다음과 같다. 생성된 pseudo label을 통해 계산된 class distrubution변수인 m_k를 이용해 v를 계산하며 v를 통해 두 type의 pseudo label을 블랜딩한다. p^이 linear type, q^이 semantic type이며 현재 unlabeled data의 class imbalence가 심하면 v_k가 커지기 때문에 pseudo label(p^’)은 semantic type에 가까워 진다.
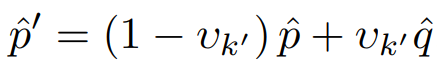
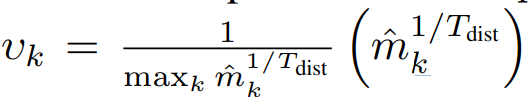
4. Semantic alignment loss.
마지막으로 Semantic alingment loss는 모델이 편향이 있는 데이터에도 강인하게 예측하도록 설계된 변수로 H는 cross entropy loss이다. soft transformatioin된 데이터의 semantic pseudo label과 원본 데이터의 semantic type pseudo label이 가까워지도록 설계되었다.
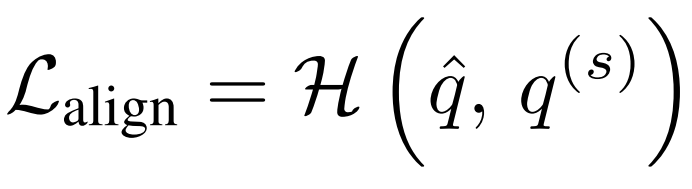
Ablation Study
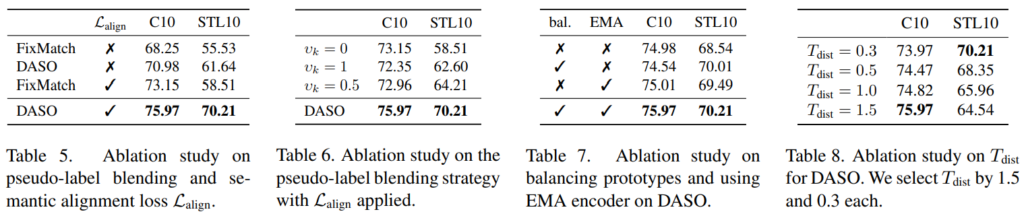
본 논문은 제안하는 방법론의 효과를 ablation study로 증명하였다. 먼저 Table5는 semantic alignment loss의 유용성을 table 6은 제안하는 pseudo label blending 기법에 대한 실험이다. 또한 실험 setting (hyper parameter, pseudo label 생성 encoder의 EMA 사용 여부 등)에 대한 비교실험 또한 table 7, 8을 통해 공개하였다.
Compare with FixMatch
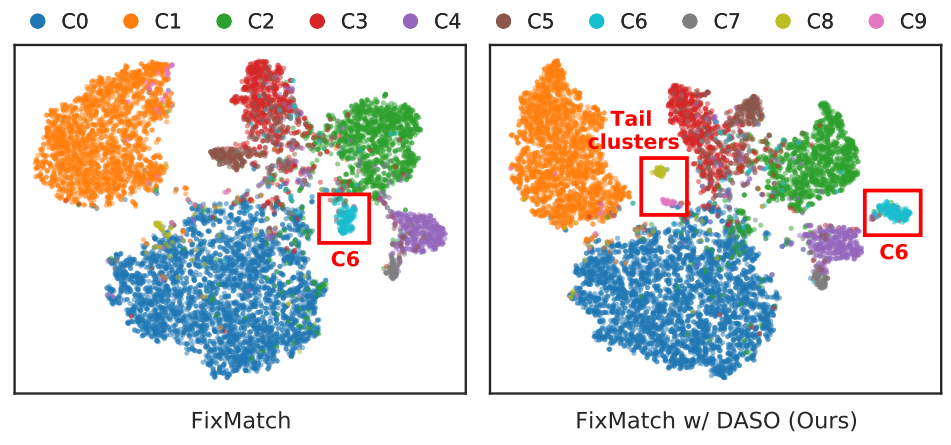
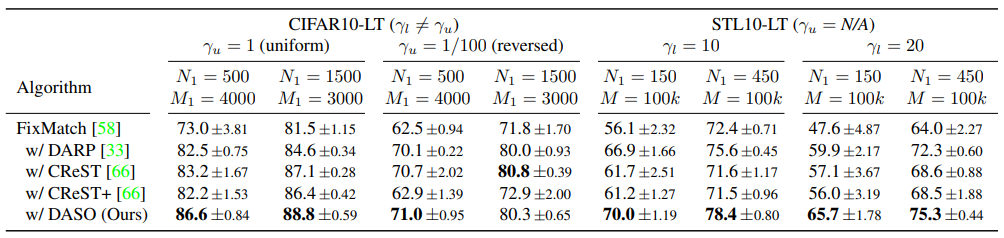
2020 방법론이지만 현재까지 많은 논문에서 SOTA로서 비교되고 있는 FixMatch와의 비교실험을 많이 진행하였다. 아래 [그림2]를 통해 시각적인 비교를 할 수 있는데 tail class인 C8에 대해 제안하는 방법론이 더욱 잘 구분된 feature space clustering을 진행하였음을 확인할 수 있다. FixMatch가 baseline 모델인 만큼 이와의 비교실험을 많이 진행하였는데 [표2]와 같이 class imbalance 상황에서 제안하는 방법론의 (FixMatch 대비) 성능 향상을 확인할 수 있다.
Limitations
논문에서 언급하는 limitations은 다음과 같다. 먼저 hyper parameter의 사용 여부이다. ablation study의 table8과 같이 T_dist와 같은 hyper parameter 변수에 성능이 의존적이며 데이터셋에 따른 튜닝을 진행해야한다.
Reference
[1] Tao Han, Junyu Gao, Yuan Yuan, and Qi Wang. Unsupervised semantic aggregation and deformable template matching for semi-supervised learning. In Advances in Neural Information Processing Systems (NIPS), volume 33, pages 9972–9982, 2020.
[2] Kihyuk Sohn, David Berthelot, Chun-Liang Li, Zizhao Zhang, Nicholas Carlini, Ekin D Cubuk, Alex Kurakin, Han Zhang, and Colin Raffel. Fixmatch: Simplifying semisupervised learning with consistency and confidence. In Advances in Neural Information Processing Systems (NIPS), 2020.