

오늘 소개 드릴 논문은 Pattern Recognition이라는 저널에 publish된 “A multi-embedding neural model for incident video retrieval” 이라는 paper 입니다. 가장 최근에 Q1 저널에서 나온 video retrieval 논문이라 상당히 흥미를 가지고 본 논문이지만, 다 읽은 후에는 몇 가지가 아쉬운 논문이였습니다. 어떤 부분이 아쉬운지에 대해 간단하게 논문 설명을 드리면서 서술하도록 하겠습니다.
1. Method
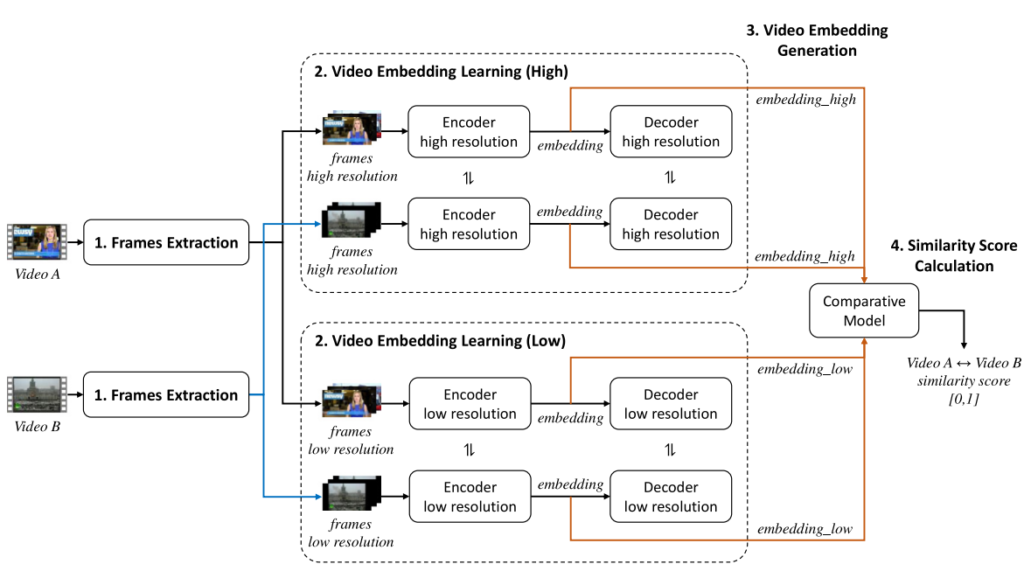
제안된 방식은 두 비디오 간의 유사도를 계산하는 것이 목적인 video retrieval task를 해결하기 위해 Fig 2와 같이 네가지 블록의 구조를 나타냅니다. 먼저, 첫번째 블록인 Frame Extraction에서는 한 비디오에서 프레임을 샘플링합니다. 두번째 블록인 Video Embedding Learning (High-Low)과 세번째 블록인 Video Embedding Generation에서는 high resolution과 low resolution의 frame들을 입력으로 Encoder-Decoder 구조를 통해 학습합니다. 마지막으로 Similarity Score Calculation 블록은 두 비디오 간의 유사도를 측정합니다. 아래에서 각 블록에 대해 자세하게 설명드리도록 하겠습니다.
1.1 Frame extraction
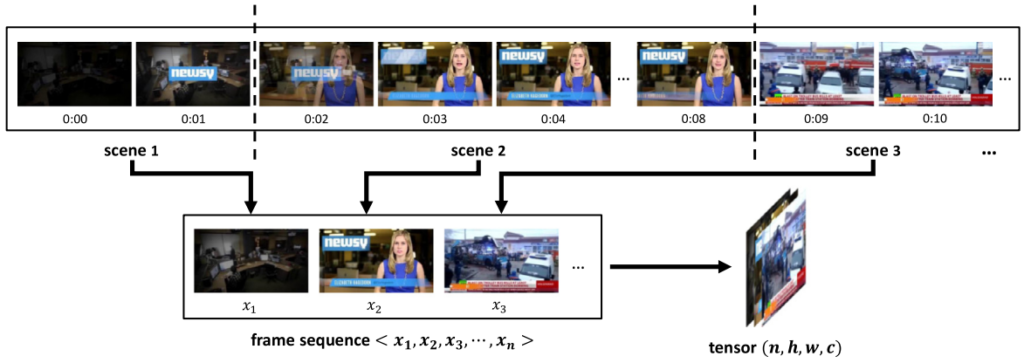
Frame extraction 블록에서는 주어진 비디오에서 프레임을 샘플링할 때 uniform or random으로 샘플링 하는 대신, scene 변화에 따라, 즉 한 shot 마다 하나의 프레임을 샘플링 합니다. Scene의 변화를 알기 위해 PySceneDetect 오픈소스를 사용하였다고 하며, 나눠진 shot의 가운데 프레임이 샘플링 되었습니다. 이렇게 샘플링 된 프레임을 concat 하여 4-D의 입력(샘플링 수 x HWC)이 생성됩니다.
1.2 Video embedding learning
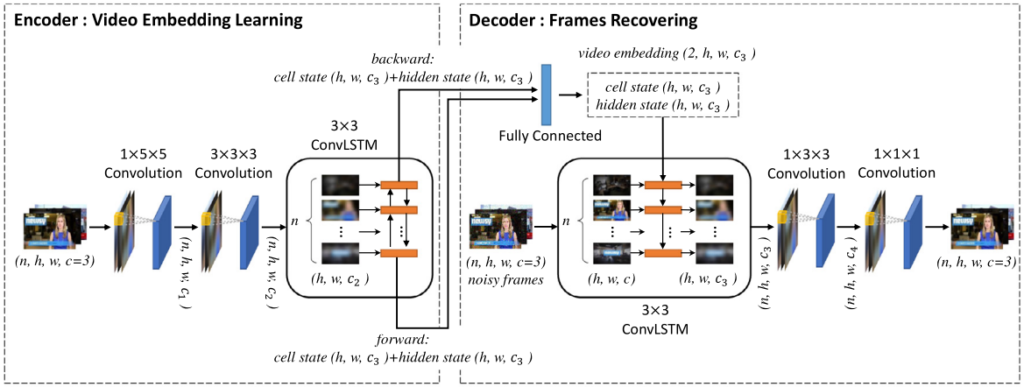
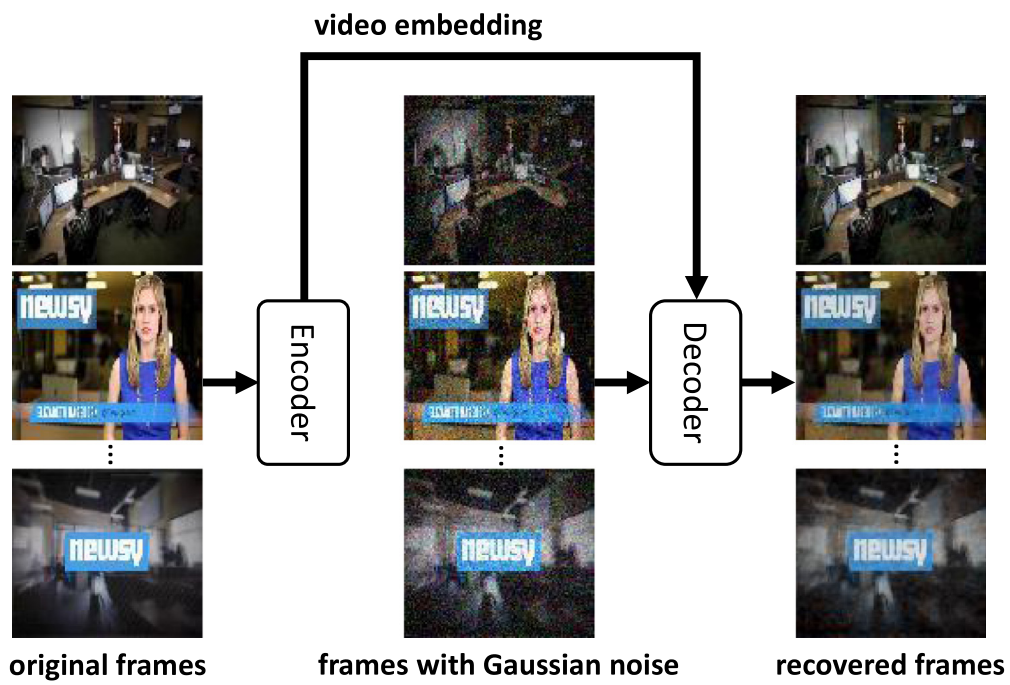
해당 블록에서는 앞서 샘플링된 프레임을 입력으로 Encoder-Decoder 구조를 학습시키게 됩니다. Encoder는 ConvLSTM 구조로 convolution연산을 통해 feature를 추출하고 이 feature들을 순차적으로 LSTM 연산하여 하나의 embedding된 feature를 생성 합니다. Decoder에서는 앞서 embedding된 하나의 feature를 LSTM의 state로, 노이즈가 가해진 샘플링된 프레임을 LSTM의 입력으로 두고 노이즈가 없는 프레임으로 recover 시키는 연산이 진행됩니다. Decoder에서 recover된 프레임들과 노이즈가 없는 프레임 간의 MSE를 통해 해당 블록만 단독적으로 학습됩니다.
1.3 Video embedding generation
두번째 블록의 학습이 다 끝난 뒤, 한 비디오를 입력으로 넣었을 때 Encoder를 통해 하나의 embedding된 feature를 얻을 수 있게 됩니다. 이에 더불어 다양한 스케일에서 비디오 프레임을 이해하고자 다른 크기의 스케일로 프레임을 resize한 뒤, 같은 프로세스를 통해 embedding된 feature를 추출하게 되며, 스케일의 종류는 원본을 포함해 두가지를 사용하였다고합니다.
1.4 Similarity score calculation
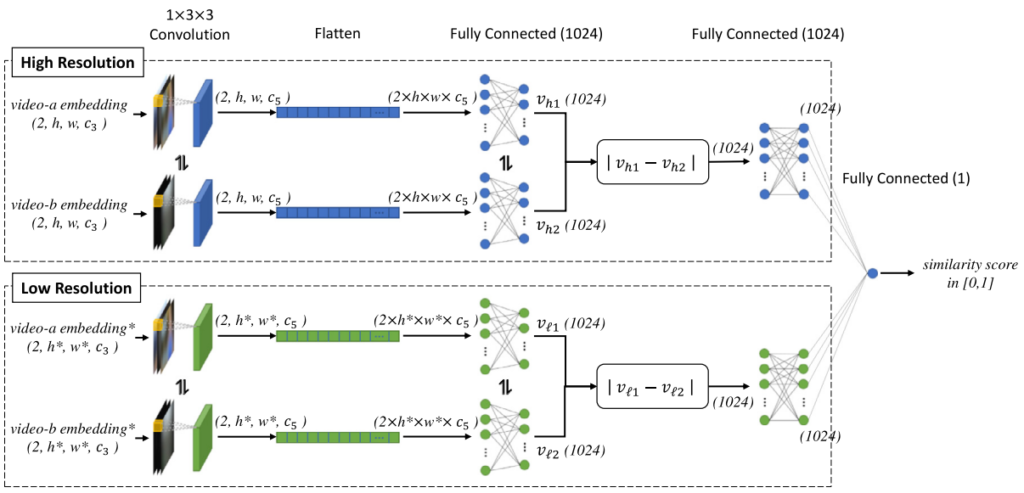
앞선 과정들을 토대로 두 비디오에서 각각 두 가지 스케일의 embedding feature를 추출한 뒤, 이번 블록에서는 이들을 입력으로 score를 계산하기 위해 학습과정이 진행됩니다. 각 feature들은 flatten된 후 FC Layer를 통해 1024차원으로 축소되며, 두 비디오의 같은 스케일 embedding feature 끼리 L1 distance를 계산하게 됩니다. 이후 다시 FC Layer를 거치고 나온 두 feature를 concat하여 2048차원의 feature를 생성하고 여기에 또다시 FC Layer를 거쳐 1차원의 score를 생성합니다. 해당 블록은 1차원의 score와 두 비디오가 연관 되었는지 아닌지에 대한 binary label 사이의 BCE Loss를 통해 독립적으로 학습됩니다.
2. Experiments
2.1 Experiments Setting
- FIVR 200k
Database는 225960개 Query는 100개로 구성된 video retrieval 데이터 셋이지만, 해당 논문에서는 일부만 다운로드 가능해 Database의 경우 63,247개 Query는 36개로 실험하였다고 합니다.
- CC_WEB_VIDEO
이 데이터 셋은 Database 12,790개 Query는 24개로 구성된 video retrieval 데이터 셋이며, 그대로 사용하였다고 합니다.
- EVVE
이 데이터 셋은 2,375개의 Database와 620개의 Query로 구성되어 있으나, 이 경우에도 마찬가지로 다운로드를 받을 수 없어 1,732개의 Database와 377개의 Query만으로 실험하였다고 합니다.
2.2 Implementation Details
리뷰에서 implementation detail을 작성하는 것을 선호하지 않지만, 학습과정에서 사용한 label에 대해 간단히 설명드려야 이후 내용을 이해하는데에 도움이 될 것 같아 필요한 부분만 작성하고자 합니다. 네번째 블록을 학습하기 위한 binary label을 생성할 때, FIVR-200k에 존재하는 video-level의 relation을 사용하였는데, relevant한 관계 (label=1)가 irrelevant한 관계 (label=0)에 비하면 개수가 적어, 1-label pair는 랜덤 복제, 0-label pair는 랜덤선택 하여 그 비율을 맞추었다고합니다.
2.3 Ablation Studies

Table 1은 FIVR-200k에서 학습시 1:1로 맞추어둔 1-label pair와 0-label pair의 비율에서 개수를 2배 (2:2), 4배 (4:4)로 늘렸을 때 성능입니다. Uni는 resize된 프레임 입력 없이 두번째 블록까지 학습된 feature로 성능 평가한 결과 이고, Multi-1은 두번째 블록 학습 후 세번째 블록에서 언급했듯 두 종류 스케일로 feature를 뽑아 성능 평가한 결과이고, Multi-2는 네번째 블록에서와 같이 유사도 계산하는 부분까지 학습한 뒤의 성능입니다.
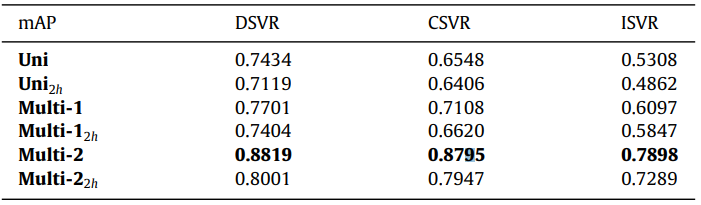
Table 2는 FIVR-200K에서 Uni, Multi-1, Multi-2에 대해 2h 옵션에 대한 성능입니다. Uni에 대한 2h 옵션은 기존 프레임 샘플링시 한 shot의 중앙 프레임 대신 첫번째 프레임과 마지막 프레임 두 개를 샘플링 하는 방식이며, Multi-1과 Multi-2에 대한 2h 옵션은 보다 작은 스케일로 샘플링 시 한 shot의 중앙 프레임 대신 첫번째 프레임과 마지막 프레임 두 개를 샘플링 하는 방식입니다.

Table 3는 서로 다른 두 종류의 스케일에 대한 성능 입니다.
2.4 Comparisons
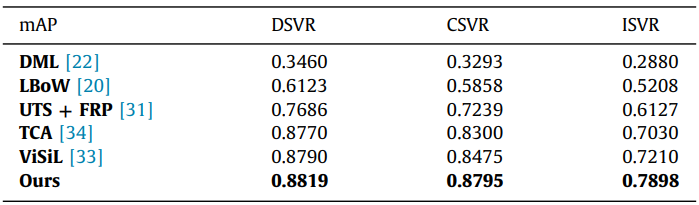
Table 4는 FIVR-200k에서 benchmark한 결과입니다. TCA와 UTS를 제외한 나머지 방법들은 다운받을 수 있었던 비디오 들에 대해 re-evaluation되었다고합니다. 나머지 두 방법은 논문에 적혀있는 성능으로 리포팅되었습니다.
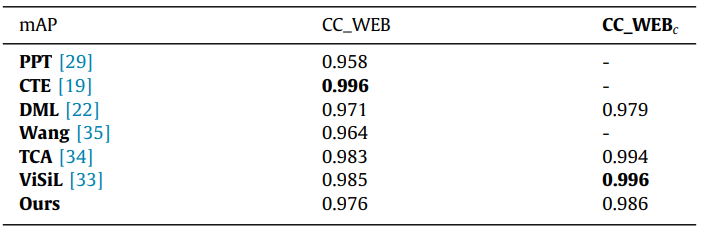
Table 5는 CC_WEB_VIDEO에 대한 benchmark로, 모든 방법론이 논문에 적혀 있는 성능으로 리포팅 되었습니다.

Table 6은 EVVE에 대한 성능이며, ViSiL은 re-evaluate되었고 나머지는 논문에 적혀있는 성능으로 리포팅되었습니다.
3. 아쉬운점
사실 처음에는 성능도 어느정도 높고 Encoder-Decoder 구조를 사용한 video retrieval 방법론은 처음이라 흥미롭게 보았습니다. 그러나, 실험부분에서 reasonable 못한 부분을 발견하였습니다.
우선, FIVR-200K에서 다운로드 받지 못한 비디오 관련해서, FIVR-200K는 youtube link로 비디오를 제공하기 때문에 다운로드 받지 못한 비디오가 생긴다는 점은 알고 있습니다. 그러나, 저자에게 연락하면 빠르게 답장을 받을 수 있음과 동시에 full 데이터 셋을 다 받을 수 있는데 그러지 않고 상당히 적은 양의 비디오로 실험했다는 점에서 다른 방법론과 비교가 가능할지 의문이 들긴 합니다. 실험에 사용한 데이터 셋 크기는 DB-약 60000개, QR-36개로 실제로는 FIVR-5K보다 사용하는 Query수가 적습니다. 그리고, 몇몇 query는 상당히 관련된 비디오를 찾기 어려워 성능을 깎아먹는 반면, 몇몇 query는 매우 쉬운 경향을 보이는데, 어떤 query를 사용했는지 밝히지 못한 점이 아쉽습니다. 물론, 적은 양이라도 re-evaluation한 타 방법론에 대해서는 어찌저찌 비교가 가능할 수 있겠지만, Full set을 사용하여 논문에 성능을 기재한 타 방법론과의 비교는 위와 같은 이유로 상당히 reasonable하지 못해 보입니다.
그리고, 학습 방식과 관련하여, FIVR-200K에서 retrieval 성능 평가 시에는 통상적으로 여러 방법론들이 VCDB에서 학습 후 FIVR-200K에서는 평가만을 하고 있습니다. VCDB에서 학습이 불가능할 경우, 아예 학습을 하지 않고 평가만으로 비교한다고 밝히게 됩니다. 그러나, 해당 논문에서는 어떤 데이터 셋에서 학습했는지 직접적으로 밝히지 않았으며, implementation detail에서 1-label pair와 0-label pair의 비율을 맞추었다고 서술한 것으로 볼 때, FIVR-200K에서 학습한 것이라 추정됩니다. 물론 Database에 속하는 비디오에서만 학습했다면, Database라는 것 자체가 실제 상황에서 모델러가 가지고 있다고 가정되기 때문에 아예 말이 되지 않는다고 생각하지는 않지만, 타 방법과 비교하기에는 적절치 못하며 꼭 그 성능을 넣고 싶었을 경우 VCDB에서 학습을 한 성능도 밝혀야하지 않았을까 싶습니다. 단순히 이렇게 평가한 방식은 심지어 re-evaluation된 타방법과 비교했을 때도 reasonable 하지 못하게 됩니다.
크게 위 두 가지 이외에도 자잘하게 아쉬운 것들이 있었지만, 위 두 가지가 가장 크게 아쉬웠던 것들이고 실험을 한 가정 자체가 reasonable 하지 않기 때문에 해당 논문에서 소개한 실험의 분석을 오늘 리뷰에 적지 않았습니다. 개인적으로는 Pattern Recognition이 좋은 저널이라 생각하여 기대하고 읽은 논문인데, 리딩을 마치고 나서 든 생각은 리뷰어가 리뷰를 대충 했거나 이 분야를 모르는 사람이 리뷰를 하여 운이 좋게 publish된 논문이 아닌가 싶습니다.
4. Reference
[1] https://www.sciencedirect.com/science/article/pii/S0031320322002886
retireval 논문들이 나오는건 좋은데 최근 나오는 것들은 하나씩 다 뭔가 부족하네요. FIVR도 논문 저자한테 요청했으면 분명 줬을텐데… 실험 보면 re-evaluation 성능이랑 아닌 것도 같이 쓰는 것도 이상하고요. 샘플링 방식도 오픈소스. encoder-decoder도 다른 방법론에서 차이가 하나도 없어보이고 컨트리뷰션으로 뭘 주장해서 붙었을까 신기하네요. 다만 PySceneDetect가 정말 예시처럼 scene을 잘 나눠두면 uniform sampling 대신 써보는 것도 좋지 않을까 생각이 드네요. 잘 읽었습니다!
좋은 리뷰 감사합니다.
1. 리뷰에서 말씀해주신대로 “다양한 스케일에서 비디오 프레임을 이해하고자 다른 크기의 스케일로 프레임을 resize”하여 high/low resolution으로 나뉘어 학습이 진행되는 것으로 이해했습니다. 그렇다면 왜 다양한 스케일에서 비디오 프레임을 이해하는 것이 의미 있는 것인가요? 단순 resize가 어떤 효과를 가져오는 것인지 궁금합니다.
2. FIVR 200K에 대한 성능에서 TCA와 UTS는 왜 가지고 있는 dataset에 대해서라도 re-evaluate를 하지 않았는지에 대한 이유가 논문에 나와있나요?
리뷰 잘 읽었습니다. FIVR를 부분적으로만 사용해서 평가했다는 것은 꽤나 흥미로운(?) 논문인 것 같습니다. 일단 그와는 별개로 몇가지 궁금한 것이 있는데
1. PysceneDetector가 정말로 Shot을 잘 구분하는 지에 대한 통계나 실험이 혹시 있나요? FIVR 데이터들이 워낙 복잡하다 보니, 이게 이상적으로 Scene들을 딱딱 구분할 수 있는지는 의문이 드네요.
2. Video embedding learning 에서 Encoder Decoder를 통한 학습을 제안하였는데 보통 metric learning 방식으로 feature의 representation을 학습하는 대신에 본 논문에서는 Decoder를 통한 reconstruction으로 feature의 representation을 학습했다고 이해하면 될까요?