
지난번 리뷰에 이은 Test time adaptation(training)과 관련된 논문을 가져왔습니다. 본 논문을 소개하기 앞서 왜 이 분야의 논문을 읽게 되었냐, 다크데이터에서 적용할 연구 분야이기 때문입니다. 다시 말해, 다크데이터에서 data shift가 발생했을 때 우선순위가 높은 데이터를 먼저 어노테이션 하기 위한 Active Learning을 개선하기 위해서 지금 소개드리는 논문을 읽어보게 되었습니다. 쉽게 도메인 shift에 강인한 데이터를 선별하는 방식에 대해 알아보고 있다고 생각해주시면 좋을 것 같습니다.
제목에서 유추할 수 있듯, Adaptation 관련한 논문인데요. Domain Adaptation과는 약간 다릅니다. 왜냐하면, DA의 경우 Target Dataset과 Source를 동시에 사용하여 학습하는 반면, 본 연구에서 주장하는 Test-Time Adaptation은 Target 데이터의 distribution을 몰라도 타깃 도메인으로 adaptation이 가능합니다.
그렇다면 어떻게 가능한 것인지 지금부터 리뷰를 시작해보도록 하겠습니다.
Tent: Fully Test-time Adaptation by Entropy Minimization
Intro의 경우, 여느 DA 논문과 다름없습니다. 지도학습 모델은 일반화에 어려움이 있어 학습 데이터와 다른 도메인의 데이터에서는 좋은 성능을 내지 못한다는 단점이 있습니다. 따라서 adaptation 을 통해 새로운 데이터셋에서도 좋은 성능을 내는 연구가 필요하다고 합니다.
그래서 저자는 Tent라는 entropy minimization 기법을 사용한 fully test-time adaptation 을 제안합니다. 제안하는 방식은 source data를 사용하지도 않고, supervision도 필요하지 않아서 새로운 데이터셋에도 Availability, Efficiency, Accuracy 3가지를 충족시킬 수 있습니다.
그렇다면 저자가 제안하는 Tent는 무엇이냐? 바로 Test-time 즉, Inference 하는 시간에 데이터의 prediction을 사용하여 모델을 업데이트하자 라는 것입니다. 그렇게 된다면, 데이터의 분포를 전혀 알지 못하는 테스트 데이터셋(즉, Target Dataset)에 adaptation할 수 있기 때문입니다. 제가 바로 앞에서 prediction을 사용하여 모델을 업데이트 한다고 하였습니다. 이 부분과 논문의 제목을 통해 유추하신 분들도 있으시겠지만, 저자는 테스트 하는 동안 모델을 adaptation 시키기 위해 예측값의 entropy를 최소화시키는 방향으로 모델을 업데이트 하게 됩니다.
그렇다면 왜 많고 많은 방법론 중 entropy를 사용하였으냐? 이에 대한 답변으로 저자는 다음과 같이 답변하였는데요, 우선 에러와 shift를 연결하기 위해서라고 합니다. 이게 무슨뜻인지는 아래 그림을 통해 설명드릴 수 잇을 것 같습니다.
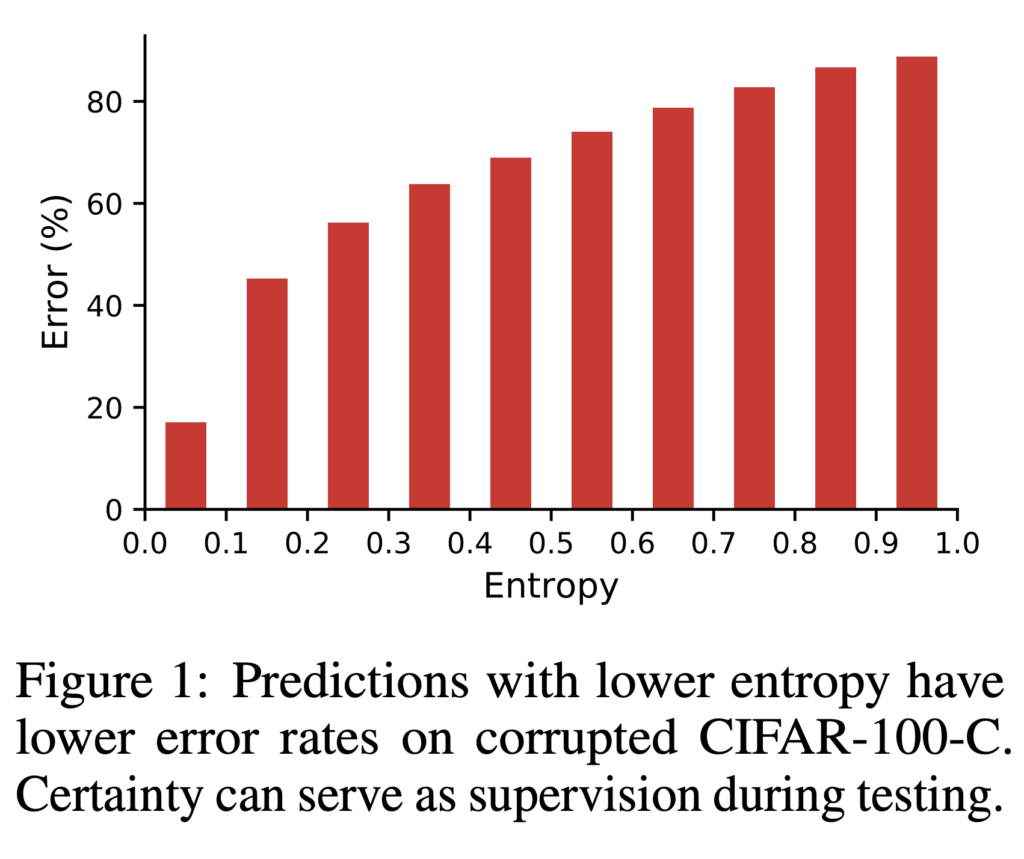
보시면 낮은 엔트로피를 가지는 예측값은 에러 역시 작습니다. 즉, 엔트로피는 에러값과 관련이 있다는 것이죠. 사실 말이 어렵지 단순하게 엔트로피가 낮아야 신뢰도가 높은 예측이다 정도로 이해하시면 될 것 같습니다. 엔트로피랑 에러가 그만큼 관련이 있으니 엔트로피 만으로도 모델을 업데이트 할 수 있다는 것이 저자의 생각이죠.

그리고 저자가 엔트로피를 사용한 두 번째 이유는 또 아래 그림과 함께 설명을 드리겠습니다. 이전 리뷰에서도 corruption 정도에 대해 설명을 드렸었는데요. ImageNet과 CIFAR-10에 단계별 (1-5) Corruption을 적용한 데이터셋을 ImageNet-C, CIFAR-10-C 라고 합니다. 아래 그림이 Corruption의 종류와 예시 이미지입니다. 레벨이 클 수록 이미지의 corruption 정도가 큰 것이고, Test-time adaptation 연구에서는 레벨이 클 수록 shift가 크다고 판단합니다.
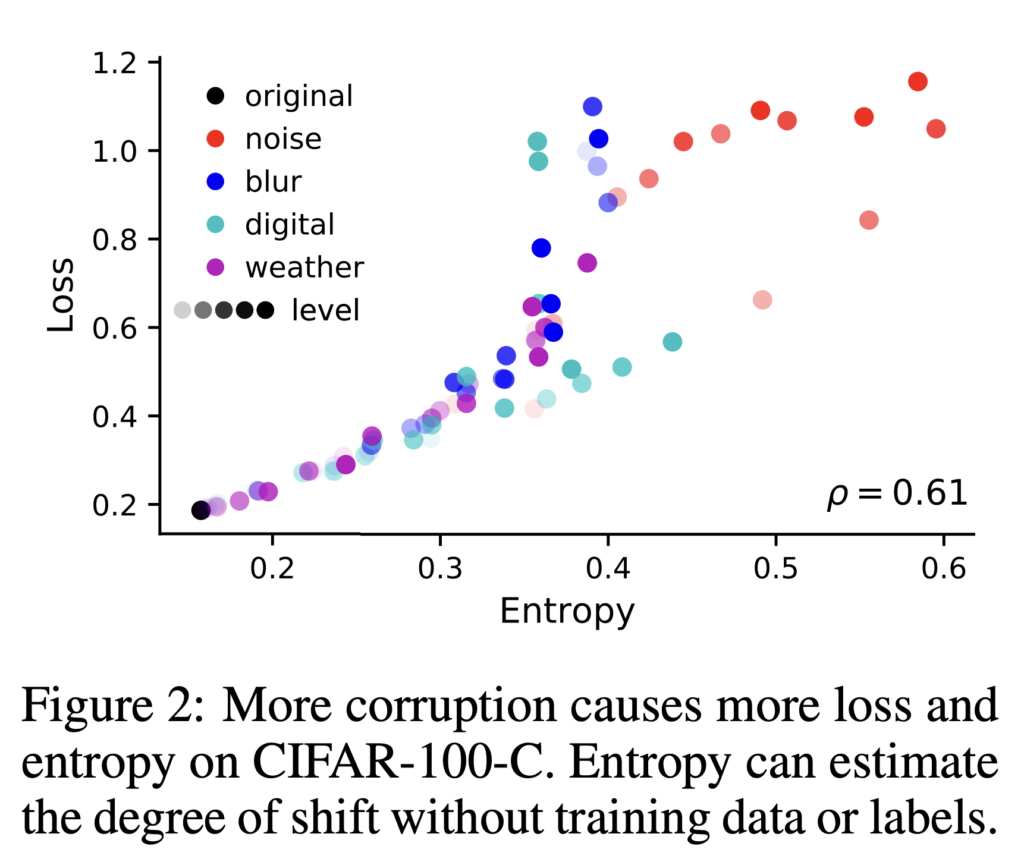
저자 역시 마찬가지로 상단 그림을 통해 엔트로피는 corruption이 많을 수록 커지며, 이는 shift과 관련이 있다는 것으로 판단할 수 있다고 주장하였습니다. (corruption level이 높을수록 entropy, loss 둘 다 linear 한 경향으로 커지는 것을 상단 그림을 통해 확인하실 수 있을 것입니다. 이를 통해 entropy로 corruption/shift 정도를 추정하는 것이 가능하다고 판단하게 된 것이죠) 따라서 corruption level이 증가할수록 이미지 classification의 loss와 상관관계가 있으며 이를 사용한 모델 업데이트가 reasonable 하다는 것이 그 주장이 되겠습니다.
그렇다면 저자가 주장하는 TENT는 기존 DA와는 어떤 차이가 있는지를 알아보도록 하겠습니다.
아래 테이블이 바로 저자가 주장하는 TENT의 차별점인데요, 보시면 Target data (타겟의 라벨 y^t이 아닌 x^t) 만 사용하여 모델을 업데이트할 수 있다는 강점이 있습니다. 즉, adaptation을 하는 동안에는 source data는 일절 사용하지도 의존하지도 않고 오직 Target 데이터만을 사용하게 됩니다. 그게 어떻게 가능할까요?

우선 가장 만만한(?) 익숙한 fine-tuning에 대해 살펴봅시다. pre-train 모델을 불러다가 target data에 대해 fine-tune 하는 것은 다시 말해 지도학습의 확장으로 target data에 대하여 x, y 값을 모두 알아야 합니다. 물론 성능이 좋겠지만… 다시 상기시키자면 우리는 Generalization이 되는 모델을 원합니다. 이에 대응하는 방법론으로 fine-tuning은 약간 거리감이 있죠.
따라서 이에 대항하여 등장한 DA는 간단하게 말하자면 target의 y값을 사용하지 않고 target, source의 데이터 표현을 비슷하게 학습하는 방법론이 됩니다. 그러므로 Loss는 소스에 대한 분류와 소스 데이터-타깃 데이터 표현이 얼마나 비슷한지를 최적화되도록 설계되었습니다. 그렇기 때문에 DA는 종종 source의 x, y에 의존하곤 합니다.
그래서 등장한 제가 지난번 리뷰한 TTT (test-time training)은 test-time에서 target에 대하여 모델을 업데이트 시킨다는 개념을 제안하였습니다. 그런데 TTT에서는 우선 Train 을 변형하여 모델을 최적화한 다음 test 단계에서 모델을 업데이트합니다. 테스트 중 모델을 업데이트에는 y 값이 필요하기에, self-supervised 중 pretext task 기반의 방법론을 사용하여 self-supervised learning 과 main task로 모델을 나누어서 학습을 진행하게 됩니다. 따라서 소스 데이터를 변형하여 이를 제대로 맞추도록 학습하는 self-learning과 소스 데이터에 대한 분류 성능을 향상시키기 위해 소스의 x, y만을 이용하여 모델을 학습합니다. TTT를 정리하자면 학습부터 테스트 과정까지 제안한 것이므로 소스의 분포와 타겟의 데이터까지 필요합니다.
(자세한 방법론이 궁금하신 분은 지난번 TTT 리뷰를 확인해주시기 바랍니다)
지금까지 기존 태스크들과 필요한 데이터와 loss를 함께 알아보았습니다. 그렇다면 TENT는 Loss를 어떻게 설계하길래 타깃에 대한 데이터만 고려할 수 있었을까요? 그 이유는 우선 학습 과정을 변형하지 않았기 때문입니다. 학습 과정을 변형하지 않고, Inference 과정 중에서만 target 데이터에 대하여 모델을 adaptation 하는 방법론을 제안하였기 때문에 더적은 계산량과 데이터를 요구할 수 있던 것이죠.
Method

상단에 보이는 그림이 바로 기존 TTT 모델과의 차이를 가져오는 TENT의 개요입니다. (오른쪽이 TENT) 여기 보시면 빨간색으로 칠한 부분이 학습 시 업데이트 되는 부분으로 생각하시면 좋을 것 같습니다.
TENT는 줄곧 Target 데이터만을 사용하여 모델을 업데이트 시켜 adaptation 시킨다고 얘기하였습니다. 이미 학습이 완료된 모델을 Inference 할 때, unsupervised 방식으로 target 에 대하여 adaptation 시키는 것이기 때문에 Target 데이터 만을 사용한 것입니다.
그렇기 때문에 우선 모델은 지도학습 기반의 확률적이고 미분 가능한 학습을 완료해야한다는 전제가 있습니다.
(이 부분에서 저의 고개를 갸우뚱하게 만든 포인트인데요. 제가 논문을 읽을 때, Source 데이터는 일절 필요없다고 이해하였기 때문이었습니다. 저자가 제안한 것은 인퍼런스 하는 중 모델을 업데이트하는 방식이기 때문에 타겟의 데이터만 필요하다고 주장할 수 있었던 것 같습니다) 학습이 완료된 모델이 확률적이어야 하는 이유는TENT 에서는 엔트로피를 사용하기 때문입니다. ( 엔트로피는 확률을 기반으로 계산되는 것은 다들 알고 계실 겁니다. )
Entropy Objective
여기까지 TENT 라는 방법론을 이해하기 위한 설계 배경 및 concept을 정리하였다는 생각이 듭니다. 그럼 이제 본격적으로 모델을 어떻게 업데이트할 것 인지, Loss는 어떻게 설계되었는지에 대해 말씀드리겠습니다.
우선 초기에도 말씀드렸듯이, 해당 방법론은 Entropy를 Loss 함수로 사용합니다. 이것은 unsupervised 함수이므로 예측값(라벨값이 필요 없)만 필요한데다, 지도학습 기반의 이미 학습이 완료된 모델과도 직접적으로 연관이 있습니다.
이게 무슨소리냐? TENT는 이미 학습이 완료된 모델이 필요하고, 그 모델을 약간씩 변형하여 업데이트를 하는데요. 이 지도학습 기반의 학습이 완료된 모델은 Loss 자체가 Cross-Entropy로 구해지니 테스트에서 구한 엔트로피와도 연관성이 높으므로 업데이트 하는 것이 합리적이라는 것이죠.
반면, TTT에서는 self-supervised 방법론 중 pretext task를 사용하여 모델을 학습하는데요, 이; 과정이 과하게 진행될 경우, 메인 태스크인 분류 성능을 오히려 방해시키기 때문에 업데이트를 제한하거나 혼합하는 방식을 택하곤 합니다. 이는 분류라는 loss와 거리가 먼 self-supervsied 라는 것을 설계하엿기 때문에 서로 상이한 결과가 발생하게 되는 것입니다. 그렇기 때문에 애초에 사전학습된 모델과 연관성이 큰 엔트로피를 쓰는 것이 저자의 주장입니다. 게다가 모델 설계 시 고려해야할 요소가 없다는 것도 장점입니다.
Modulation Parameters (model update)
다음으로 그림에서 보셨듯이, TENT 에서는 학습이 완료된 파라미터 전체를 변형하지 않습니다. 오히려 training에 맞춰진 파라미터로부터 벗어날수도 있다고 합니다. 또한 비선형적이고 고차원적인 함수 및 파라미터로 인해 최적화가 민감하고 비효율적일 수도 있습니다. 따라서 저자는 안정성 및 효율성을 위해 \theta 전체가 아닌 linear ((scales and shifts) 그리고 저차원(chnnel-wise) 적인 파라미터 모듈 업데이트를 제안합니다.
아래 그림이 저자가 제안하는 1) distribution에 의한 normalization 2)파라미터에 의한 transformation을 요약하여 보여줍니다. 저자가 제안하는 방식은 굉장히 간단합니다. 우선 normalization는 입력 x를 평균 µ 및 표준편차 σ을 사용하여 ![]() 적용됩니다. 그 다음 normalization이 완료된 \bar{x}에 대해 scale γ, shift β를 사용하여 Transformation 을 진행합니다.
적용됩니다. 그 다음 normalization이 완료된 \bar{x}에 대해 scale γ, shift β를 사용하여 Transformation 을 진행합니다. ![]()

Experiment
실험은 CIFAR-10/CIFAR-100 및 ImageNet의 corruption과 SVHN에서 MNIST/MNIST-M/USPS domain adaptation 에 대한 평가를 진행하였습니다. 그리고 제안하는 TENT는 ResNet을 백본으로 사용합니다.
우선 Corruption에 의한 성능입니다. CIFAR-10/100-C 그리고 ImageNet-C에 대한 성능은 아래와 같습니다. 왼쪽 테이블 2를 통해 더 적은 데이터만으로도 성능이 크게 향상된 것을 확인하실 수 있습니다. 특히 TTT보다 눈에 띄는 성능 향상을 볼 수 있습니다. 게다가 오른쪽 그림 5는 ImageNet-C에서의 Error 값을 확인할 수 있습니다.
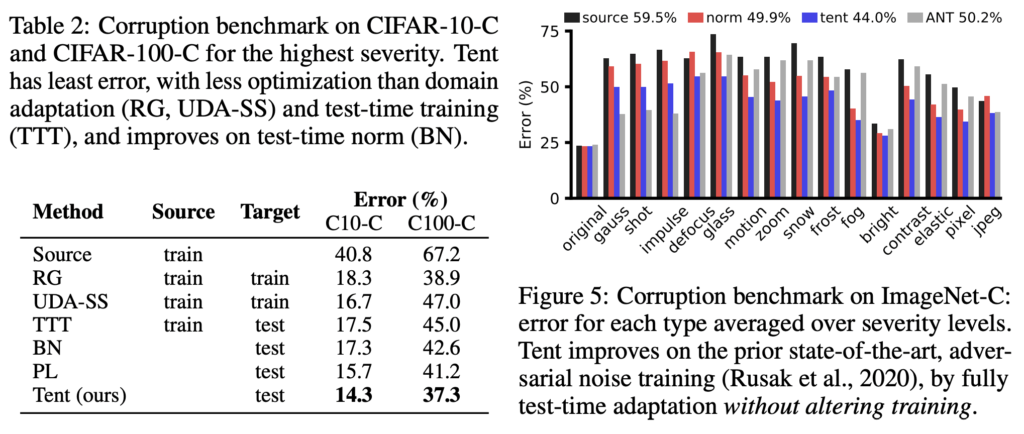
해당 논문의 성능 및 비교한 테이블입니다. 해당 분야가 등장한지 얼마 되지도 않은데다 정확도로는 너무 높지 않아서 보통 에러로 많이 표기한다고 합니다. TENT 의 경우, MNIST에서도 그리고 USPS에서도 상당히 좋은 성능을 내는 것을 확인하실 수 있습니다.
다음으로 SVHN -> MNIST/MNIST-M/USPS 에 대한 실험 결과입니다. 아래 테이블3을 통ㅇ해 MNIST-M을 제외하고 성능 향상 폭이 굉장히 컸다고 합니다.
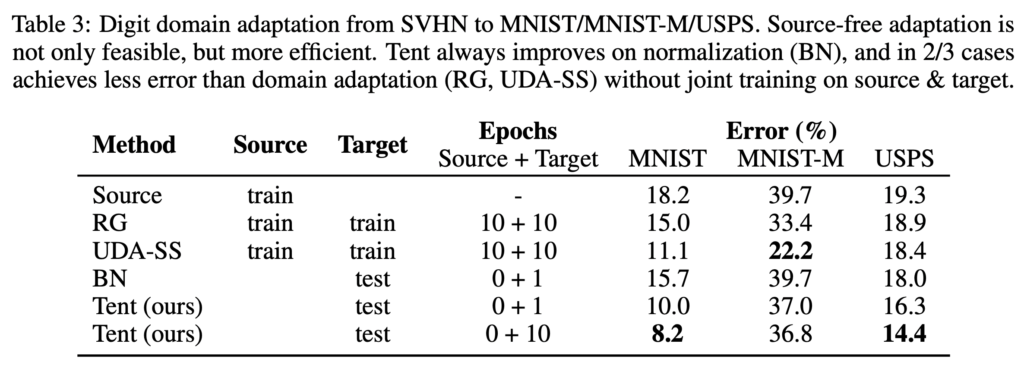
다시 정리하자면 Tent는 엔트로피를 최소화하여 테스트 시간동안 shifted 된 데이터에도 강인하게 동작하기 위한 방법론을 제안하였습니다. 그러나 해당 연구가 등장한지 얼마되지 않아 아직 갈 길이 많이 남아있다는 실험 결과인 것 같습니다.
간단하면서도 상당히 좋은 방법론이라 생각이 들어 2주동안 처음 제시한 근본 논문들을 리뷰하게 되었는데요, 아무래도 다크데이터 과제에 적용할만한 눈에 띄는 성능 향상을 가져올까 라는 의문이 있긴 합니다. 추후에는 해당 논문을 AL에 적용하는 방법을 찾아보면서, 이전 리뷰에서 말씀드린 것처럼 CVPR 2022 논문을 읽어봐야겠습니다.
좋은 리뷰 감사합니다.
이 방법론은 학습이 완료된 모델이 있고, target에 대해 조정하는 adaptation 과정에 대한 제안이라고 이해하면 되나요??
또한, 학습이 완료된 모델이 사전학습된 모델을 의미하는 것이 아니라 source에 대하여 학습이 완료된 모델을 의미하는 것 같은데, 이 경우의 연산량과 일반적인 DA 방식에서 source와 target을 고려하여 adaptation을 수행하는 경우의 연산량을 비교한것인가요?? 이 비교는 공정한(?) 비교인가요??
댓글 감사합니다.
Q1) 네, 지도학습 기반으로 학습이 완료된 모델을 test-time 동안 target에 대해 adaptation 하는 방법론입니다.
Q2) 저도 처음에는 Source를 전혀 사용하지 않는다는 것에서부터 연산량 비교까지 이승현 연구원의 질문에 공감을 하였는데요. 하지만 저자가 주장하는 방법론은 “Test-time에서 동작하는 모델“이기 때문에, 학습 과정부터 재설계한 논문들과는 다르게 연산량이 적다는 것은 사실임을 인정하실 겁니다. 즉, 저자가 제안하는 방법론의 목적 자체가 “학습이 아닌 Inference 과정에서도 모델 업데이트가 가능하다” 이기에 여기에 초점을 두고 논문을 읽어주시면 도움이 될 것 같습니다. 게다가 논문에서 연산량을 다른 방법론들과 직접적으로 비교하는 정량적인 실험도 없고, Test에서만 모델을 업데이트하는 것이므로 상대적으로 연산량이 적다라는 것을 저자가 주장한 것이기에 “공정한 비교인가요?” 에 대한 질문은 성립되지 않는다고 생각합니다. 그리고 추가로 해당 논문의 peer-review에서는 it is easy to apply without any strong assumption/requirement. A clear accept! 라는 점에서 가정이나 추가적인 조건 없이 이미 학습이 완료된 모델이라면 간단하게 적용가능하다는 점을 높게(?) 샀다는 것도 참고하시면 도움이 될 것 같습니다
리뷰 잘 읽었습니다.
한가지 궁금점이 있는데, 기존에 TTT와 같은 방법론은 pretext task를 사전에 정의하여 학습하는 self-supervised learning을 사용하는데 이러한 방법이 기존의 분류 task와는 상이한 목적 함수로 학습되어 원래 풀고자 하는 분야의 성능이 떨어진다고 하셨습니다. 허나 TENT 방법론은 모델이 추론한 값에 대한 엔트로피를 줄여나가는 방향으로 학습하기에 더 좋다고 하셨는데, 그렇다면 해당 방법론은 엔트로피 등을 계산할 수 있는 분류 문제가 아니라면 적용할 수 없는 것인가요??
네 그렇습니다. 실험 역시 classification 외에 semantic segmentation (pixel-wise classification) 정도만 보였습니다. 그래서 그런지 저자는 논문에서 Entropy is general across tasks but limited in scope. 라고 언급하긴 합니다.
안녕하세요 좋은 리뷰 감사합니다.
궁금한 부분이 있는데, 해당 논문은 source data를 사용하지도 않는 방법론이라고 하셨는데, 그렇다면 지난 리뷰 논문인 TTT 와의 차이는 인퍼런스시 train 모델을 변형하는지 하지 않는지에 대한 차이인가요?
감사합니다
크게 얘기하자면 네 그렇습니다.
Tent 에서는 이미 학습이 완료된 모델을 변형(adaptation)하는 것이고,
TTT는 학습하는 방식부터 변형하여 이를 기반으로 Test time에서 모델을 또 업데이트(adaptation) 합니다