localization의 성능을 높이기 위한 논문을 찾아보다 읽게 된 논문입니다.
visual localization 과정은 쿼리 이미지와 가장 유사한 이미지를 데이터베이스에서 찾은 후, 데이터베이스와 쿼리를 이용하여 pose를 추정하는 방법론입니다.
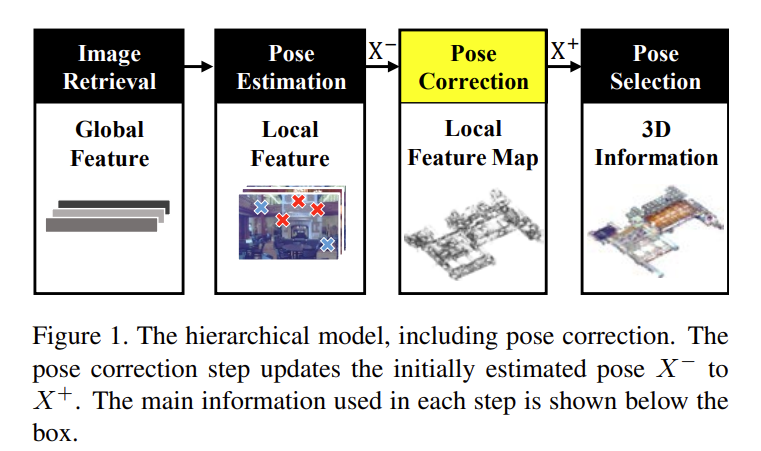
해당 논문은 localization 데이터베이스의 이미지 희소성에 의해 발생하는 문제를 해결하기 위해 pose estimation 이후에 pose correction이라는 과정을 추가하여 정확도를 높이는 방식을 제안하였습니다. 이때 데이터베이스의 이미지 희소성에 의해 발생하는 view-difference문제를 정의하고, 처음으로 다루었다고 합니다.

그림2의 (a)의 상황처럼 DB와 Query 이미지의 실제 위치가 멀리 떨어져 있는 경우, 활용할 수 있는 local feature가 적어지고 이로인에 부정확한 포즈를 예측(X^-)하게 된다고 합니다. 이때 local feature들을 X^-로 reconstruct하여(그림(c)의 LF(X^-)) inlier feature를 증가시켜줍니다. 이후 reconstruct된 feature를 이용하여 다시 포즈를 예측(X^+)하여 보다 정확한 pose를 추정하도록 해주는 하는 것을 Pose Correction 모듈이라 합니다.
Visual Localization with Pose Correction
1. Baseline
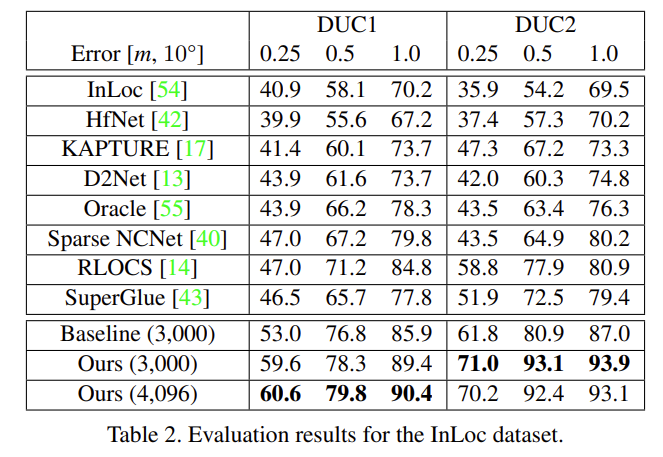
해당 논문은 InLoc[InLoc: Indoor visual localization with dense matching and view synthesis. In CVPR, 2018.]을 baseline으로 하였습니다.
- image retreival: NetVLAD를 이용한 top-K_1 검색
- pose estimation: superPoint와 SuperGlue, PnPRANSAC을 이용한 topK_2 pose 예측
- PV: DenseRootSIFT를 이용하여 topK_2 중 best pose 선택
2. Key limitations in the baseline
DB 내의 이미지를 기반으로 pose를 추정해야 하는데, DB에 있는 이미지가 sparse하다는 한계로 인해 view-difference 및 selectionof reliable coandidate와 관련된 문제가 발생한다고 합니다.
- view-difference 문제란, 촬영된 DB내의 이미지간의 간격에 의해 발생하는 문제로, 그림2에서 설명한 문제를 의미합니다.
- 또한 selectionof reliable coandidate와 관련된 문제란 query 이미지와 검색된 이미지의 overlap되는 부분이 작을 경우, true positive 후보의 local feature의 inlier 개수가 false positive 후보보다 적을 수 있다는 문제입니다.
3. Pose correction
Pose Correction은 앞서 설명한 문제점을 피하기 위해 추가한 과정으로 1) X^-에서 X^+로 변환하는 과정과, 2) 더욱 신뢰도 높은 후보를 뽑는 과정으로 구성됩니다.
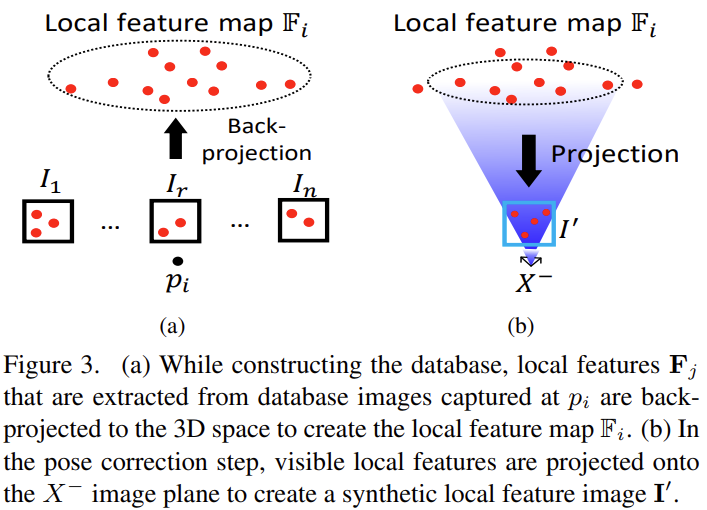
- 그림3에서 확인할 수 있듯이, 위치 p_i에 대하여 n개의 scan-view 이미지를 이용하여 local feature map\mathbb{F}_i=\left\{^{p_i}\mathbf{F}_j|j=1,2,...,n\right\}를 생성합니다. 이후 \mathbb{F}_i를 image plan X^-로 projection 시켜줍니다.이때 synthetic local feature image \mathbf{I}^\prime도 만들어집니다. \mathbf{I}^\prime로 투영되었던 local feature들과 query 이미지들에 SuperGlue를 이용하여 matching을 수행한 뒤, 2D-3D 대응점을 이용하여 PnP RANSAC 알고리즘을 이용하여 업데이트 된 pose X^+를 구합니다.
- 그리고 2D-3D 대응점들을 이용하여 K_2 후보를 재정렬하여 K_3를 만듭니다.
pose correction은 query와 유사한 view를 가지는 X^-를 추정하여 view-difference 문제를 해결하므로 proximity를 가지고 여러 이미지들을 통해 local feature를 추출하므로 풍부한 feature를 가진다는 점에서 pose estimate 과정과 차이가 있습니다.
4. Extended pose correction
특징을 활용하고 정확도를 높이기 위해 pose correction에 대하여 확장시킨 내용입니다.
Divided matching
이미지를 상하좌우 영역으로 분할하여 각 영역에서 feature matching을 수행할 경우 공간적으로 더 큰 영역에 분포하는 inlier들을 찾을 수 있다고 합니다. 이러한 방식은 두 이미지의 view가 상당히 유사해야 잘 작동하므로 DB 이미지가 조밀할 경우에 유용하다고 합니다.
Inter-pose matching
pose correction이 풍부한 feature를 갖는다는 속성을 활용하여 여러 \mathbb{F}_i를 이용하여 inter-pose mathcing을 제안하였다고 합니다. 여러 \mathbb{F}_i를 함께 활용하여 co-visibility를 고려할 수 있다고 합니다. 오목한 구조나 복잡한 부분에서 occlusion이 생길 경우 iter-pose matching을 이용하면 여러 위치에서 얻어진 local feature로 인해 올바른 위치를 찾는데 도움이 된다고 합니다.
Filtering process
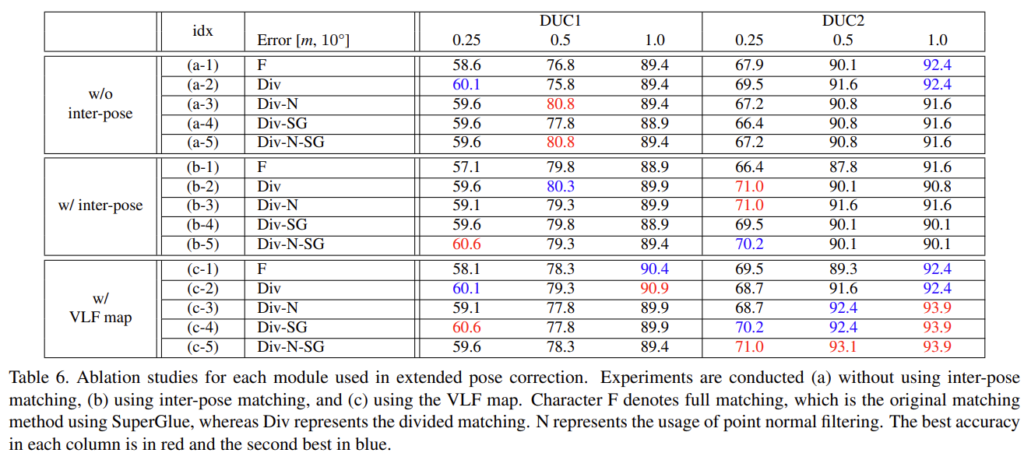
pose correction과정에는 occlusion이 고려되지 않으므로 \mathbf{I}^\prime로 projection되는 local feature를 줄이는 것이 도움이 된다고 합니다. 이를 위해 VLF(virtual local feature) map에 전처리 및 point normal filtering을 적용하는 2가지 방식을 제안하였다고 합니다.
- VLF map은 가상 위치 p^{\prime}_l을 추가하고 p^{\prime}_l에서 볼 수 있는 feature를 찾아 \mathbb{F}를 확장시킵니다. 이를 통해 DB의 sparsity를 줄이고 추론시에 보이지 않는 local feature가 \mathbf{I}^{\prime}로 투영되는 것을 막아줍니다.
- point normal filtering은 local feature의 정규 점과 X^-의 방향벡터 사이의 코사인 distance를 기반으로 보이지 않는feature를 제거한다고 합니다.
두가지 필터링은 선택적으로 적용할 수 있지만, 적용할 경우 효과적이라는 것을 실험을 통해 확인할 수 있습니다.
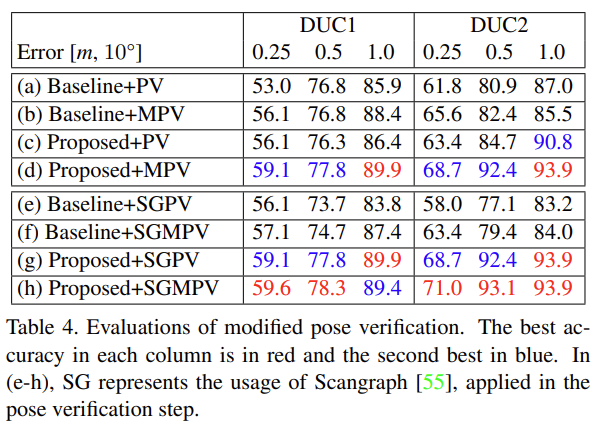
5. Modified pose verification
PV는 후보들 중 가장 적절한 Pose를 구하는 단계로, MPV는 PV를 수정하여 제안한 내용입니다. query 이미지와 비교하기 부적절 렌더링된 이미지의 outlier pixel을 제거하는 방식으로 그림 4를 통해 pose를 잘 찾은 예를 확인하실 수 있습니다.

outlier pixel을 제거하고 유효한 점만을 남기기 위해 작고 고립된 영역들을 제거하는합니다. 이후 중앙값을 이용하던 유사도 평가방식을 수정하여 중앙값 아래 값들의 평균값을 이용함으로써 upper outlier 값을 제거합니다. 이는 쿼리와 렌더링된 이미지의 유사한 영역의 전체 점수를 나타내고, dynamic한 feature나 조명 변화에 따른 영향을 줄일 수 있습니다.
그림 4를 통해 설명하자면, 동일한 후보들에 대해 PV와 MPV는 다른 top1 이미지를 선택하였고, 각 이미지에 대한 PV와 MPV error map을 확인해보면(error map이 낮은 걸 top1으로 선택한것임) (c)를 통해 MPV가 sparse한 점들을 제거한 것을 확인할 수 있고 (f)를 통해 열린 문과 같이 변화를 주는 영역에 대해 낮은 가중치를 가지는 것을 확인할 수 있습니다.
Experiment
Dataset
InLoc 데이터셋의 7-scenes, 12-scenes데이터를 이용하였다고 합니다. 그러나 이 데이터는 non-dynamic하고 작은 공간이므로 적합하지 않아 InLoc 외의 M-site 데이터셋으로도 평가하였다고 합니다.
- InLoc 데이터는 10k 이미지와 depth 데이터를 제공하고, 여러 건물의 여러 층을 포함하였다고 합니다. 또한, textureless공간과 반복적인 영역, 조도 변화, occlussion이 심한 영역, 많은 dynamic feature가 포함되어있어 어려운 데이터셋입니다. 329개의 query 이미지로 되어있습니다.
- M-site 데이터는 25k 이미지와 depth 데이터로 구성되어있습니다.(LiDAR와 360° 카메라로 촬영됨) 대규모 indoor 공간으로 featureless이고 유사한 장소로 구성되었습니다. 472장의 query 이미지로 구성되어있습니다.
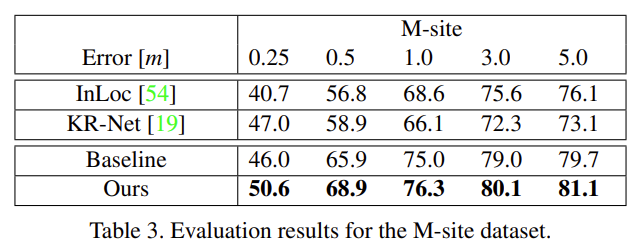
Modified pose verification
MPV를 적용하였을 때의 결과로 대부분의 경우 PV보다 MPV를 적용하였을 때 성능이 좋은 것을 확인할 수 있습니다.
Pose correction
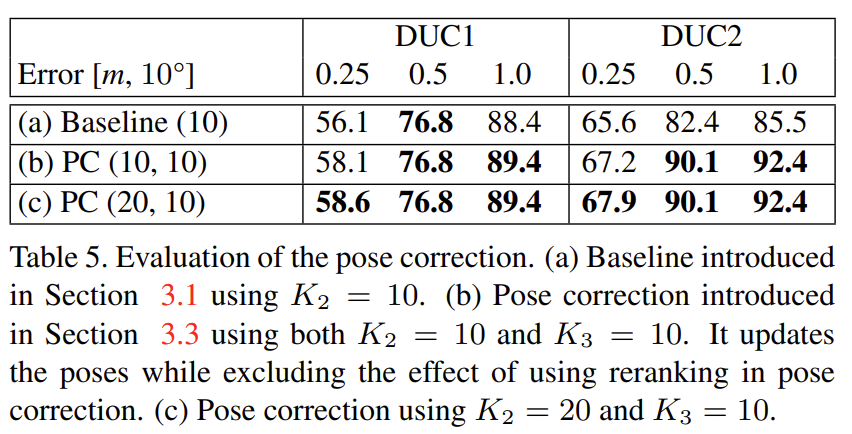

그림5는 정성적 결과로 Baseline과 Pose Correction을 수행한 결과를 비교했을 때 pose correction의 query와 rendered view가 더 유사한 것을 확인할 수 있습니다. 이때 초록색 점은 X^-와 X^+를 추정하기 위해 사용되는 feature들을 의미합니다다. (a) 사용된 feature가 더 적은 영역에서 나타나고, (b) 반복된 패턴으로 인해 baseline에 해당하는 rendered view가 부정확한 것을 확인할 수 있습니다.(가운데의 문 부분을 봤을 때 훨씬 앞으로 이동한 후의 이미지로 보이는 것을 알 수 있다.) (c) 회전 정도의 차이를 확인할 수 있습니다.
좋은 리뷰 감사합니다.
그런데 혹시 정확히 어떤 상황을 view difference 라고 하나요?
성능을 개선시키고자 하는 데이터에서 정의하신 view difference 가 발생하는건가요?
저장되어있는 데이터베이스를 기반으로 카메라의 위치를 추정하는 것이 localization의 목표입니다.
이때 데이터베이스를 구성하는 이미지가 촬영된 위치가 sparse하여 발생하는 문제로, 쿼리와 가장 유사한 이미지가(예측이 아니라 실제로 가장 유사한 이미지라 했을 때도) 그림2의 (a)에서 확인할 수 있듯이 위치상으로도 차이가 많이나고, 그림2의 (b)에서 확인할 수 있듯이 영상적으로도 차이가 나는 것을 view-difference라고 정의하였습니다.
사용하는 데이터도 동일한 문제가 발생한다고 판단하여(데이터셋의 특성상 일정 간격을 두고 촬영된 이미지가 DB에 저장되므로 sparse하다고 판단) 해당 방법론을 적용해보려 하였습니다.