오랜만에 Self-Supervised monocular depth estimation 논문으로 돌아왔습니다. CVPR과 RAL 작성시에는 못찾았었던 논문이라 혹시나 저희가 성능 비교를 못했나 해서 보았지만 큰 문제는 없는 것 같지만… contribution에 문제가 생길 수 도 … 있는 것 같습니다.
이 논문의 contribution은 아래 총 세개며 다음과 같습니다.
- image를 이용한 Depth estimation은 영상 속 수직 상에 있는 정보를 중요하게 여져진다는 기존 연구의 분석을 토대로 수직정보의 다양성을 늘릴 수 있는 새로운 augmentation을 제안합니다.
- multi scale로 학습하는 기존 방식에서 output들은 일관성이 없고 각자 장단점이 뚜렷다는 특징이 있기 때문에 이러한 특정을 이용해서 recontruction loss가 가장 좋은 pixel만을 학습에 사용하는 Selective Post-Processing(SPP) 모듈을 제안합니다.
- 기존에 decoder에서 만 depth를 예측하던 방법론과 달리 encoder에서도 depth를 예측할 수 있도록 새로운 네트워크를 제안합니다.
- Method
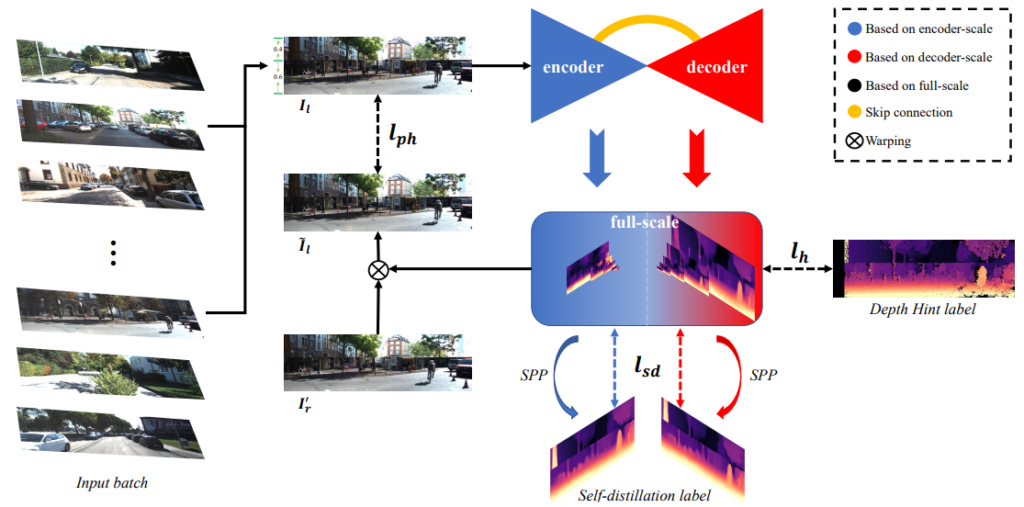
이 논문에서 제안하는 방법론을 요약하면 위 그림과 같습니다. (1) Data grafting을 통해서 영상 두개를 합친다음, (2) 모든 scale에 대해서 depth를 예측한 후 (3) SPP 모듈을 통해서 Self-distilation label을 만들고 loss를 계산합니다. (4) 다음에 모든 scale에 대해서 photometric loss를 계산하고 depth hint 방법론을 이용해 추가적인 학습을 합니다.
Data Grafting
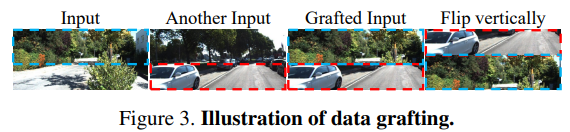
가장 먼저 이 논문의 핵심 contribution인 augmentation 입니다. 위 그림과 같이 특정 비율을 이용해서 두개의 영상을 섞는 방식 입니다 .
기존 monocular depth estimation 같은 경우 overfitting 이 심해서 다양한 augmentation 방법론들이 제안되었습니다. 그렇지만 Self-supervised depth estimation에서 제안하된 방법론은 전무했습니다. 그 이유는 Self-supervised depth estimation의 특이한 학습 방식으로 인해서 영상간에 정확히 매칭이 되야했기 때문에 기존 augmentation 방법론들은 이런 self-supervision의 특징을 깨트리기 때문에 좋은 성능을 보일 수 없었습니다.
이러한 기존 Self-supervision의 특징은 stereo camera를 이용했을 때는 그나마 완화되며 이렇게 완화되는 특징을 강화시키기 위해서 data grafing 을 제안합니다. 위 그림과 같이 두개의 영상을 수직적으로 붙히며 각 영상이 합쳐지는 비율은 무작위 이며 또한 위아래도 무작위로 변경하게 됩니다. 이렇게 무작위로 변경하는 것을 통해서 수직적인 정보만을 보는 모델에 새로운 정보를 주게 되서 성능 향상을 이루게 됩니다.
Full-scale Network
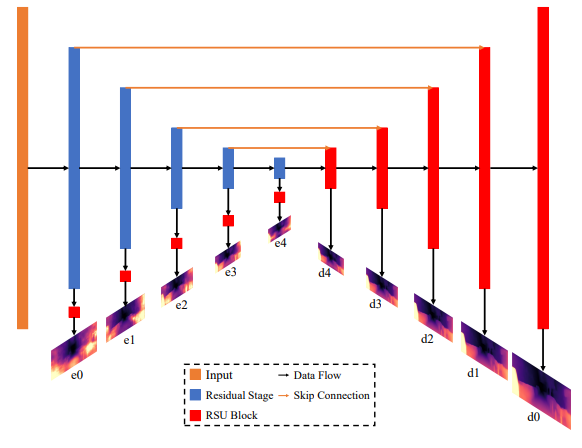
다음 contribution은 full sclae depth map 입니다. decoder에서 예측된 정보는 자세한 정보를 포함하며, encoder에서 나온정보는 보다 추상적인 정보를 포함하기 때문에 이 두 정보를 잘 융합해서 self-distillation 에 적용하기 위해서 위 그림과 같이 모델을 설계했다고 합니다.
Self-distillation
Self-supervised 의 학습은 너무 어려워 추가적인 로스 function 이 많이 제안되고 있습니다. 이 논문에서는 pseudo-label을 생성한 후 pseudo-label로 학습하는 self-distilatillation loss를 제안합니다. 이 때 pseudo-label을 생성하는 방식은 Selective Post-processing 을 제안합니다.
Selective Post-processing 은 여러 디스패리티 스케일에서 각 픽셀의 최적 디스패리티를 필터링하는 것을 목표로 합니다.
multi scale 방식에서 가장 큰 scale이 가장 좋은 성능을 나타내는 것은 아닙니다. ( 이건 저희도 논문을 준비하며 알아낸 사실이며 이 논문에서 성능으로 보여주고 있습니다.)
따라서 모든 스케일에서 픽셀당 가장 좋은 픽셀을 고르기 위해서 recontruction loss 와 depth hint loss를 이용해서 loss 가 가장 작은 pixel들을 골라서 pseudo-lable로 설정합니다.
그 다음 아래 식으로 supervised 방식으로 self-distillation loss를 계산합니다.
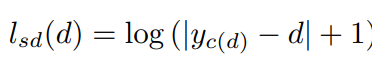
Results
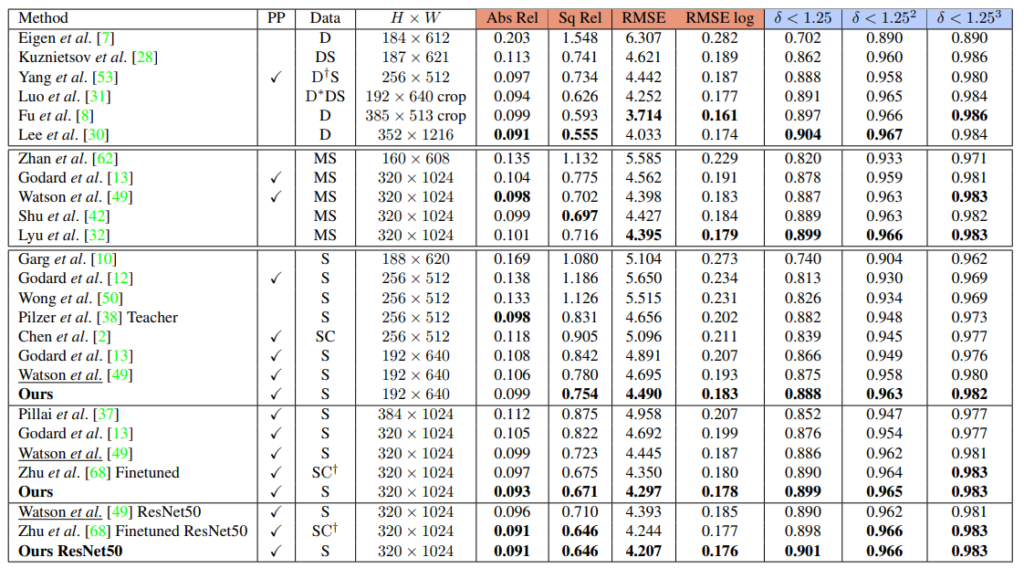
성능 입니다. Stereo 라서 저희랑 비교하기 얘매해서 다행입니다. 성능 향상을 보면 꽤나 높은 성능 향상을 볼 수 있습니다. 근데 PP를 기본 성능으로 넣은건 살짝 괘씸한 것 같습니다.
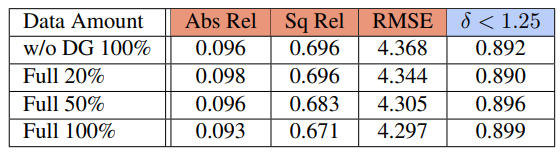
data grafting ablation study 입니다. augmentation을 더욱 강하게 줄수록 준수한 성능향상을 하는 것을 볼 수 있습니다.
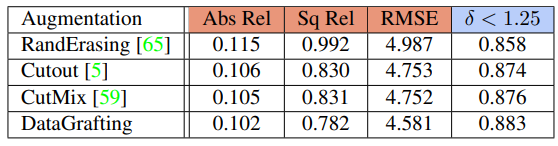
다른 augmentation 방법론과 비교했을때도 높은 향상을 볼 수 있습니다.
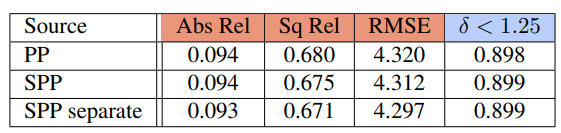
PP는 post processing 방법론이며 성능 향상을 보여줍니다. 그리고 separate는 encoder와 decoder 를 전부 사용했을때 의 성능이며 이것또한 성능 향상이 있습니다.
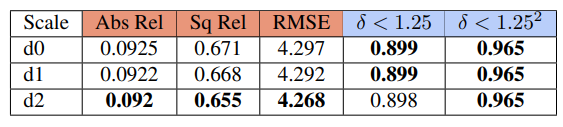
이 표를 통해서 multi scale 이라해서 무조건 성능이 좋다는 게 아니란 것을 증명합니다.
이 외에도 다양한 실험이 추가되어 있긴하지만 이저도면 충분 할 것 같습니다.