갑자기 왠 Text 논문을 들고왔나… 싶을 수도 있지만 지난주에 작성한 ArcFace 논문에 이어 DOLG의 AS 시간입니다. DOLG에서 orthogonal projection을 통해 local feature를 global feature에 투영시키는데 어떻게 그런 방법을 생각했을까 싶어서 citation을 찾아보니 이 논문을 기반으로 하고 있어서 한번 읽어봤습니다.
Introduction
다른 부분은 다 넘어가고 projection에 관련된 부분을 한번 집중적으로 봐봅시다. 왜 이러한 것이 필요했을까요? 이 논문에서 다루는 것은 text classification입니다. 그중에서도 sentiment text classification을 수행하는데요. 이러한 곳에서 쓰이는 문장을 잘 생각해보면 구별력이 있는 단어도 없지만 일반적으로 쓰이는 단어도 있습니다. (Good/Bad는 확실한 차이가 있지만, picture/price 등과 같은 일반 명사들로 생각하면 됩니다.) 그래서 이 논문에서는 feature projection 을 이용해서 이러한 feature의 표현력을 향상시킬 수 있는 네트워크인 FP-Net(Feature Purification Network)를 제안합니다.
FP-Net
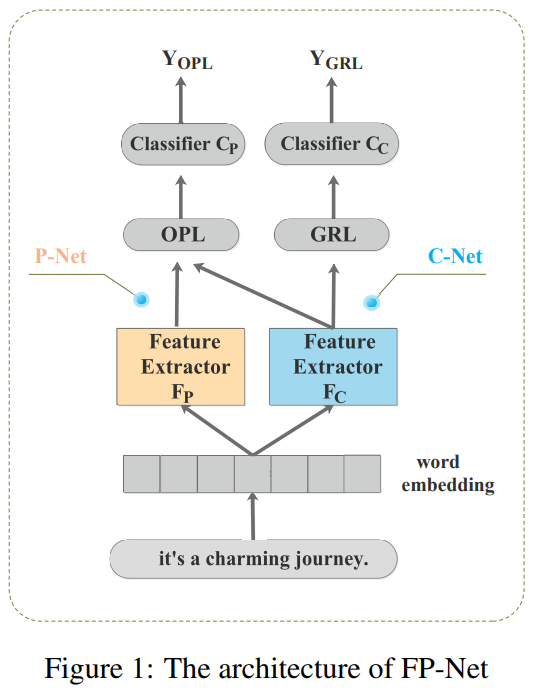
FP-Net은 P-Net과 C-Net으로 구성되어 있습니다. 그리고 약어들이 많이 등장하니 미리 짚고 넘어가자면, OPL은 Orthogonal Projection Layer이고 GRL은 Gradient Reverse Layer의 약자입니다. P-Net은 classification을 위해 purified feature를 계산하고, C-Net은 common feature를 추출합니다.
- purified feature == common feature의 영향력을 제거하여 보다 특징적인 semantic한 정보를 가진 feature
- common feature == 다른 클래스와 구분되지 않는 feature (일반 명사 단어들)
P-Net과 C-Net 모두 공통적으로 feature를 추출하기 위해서는 일반적인 CNN extractor를 사용합니다. 논문 저자가 말하기를 어떤 모델도 여기에 쓰일 수 있다고 말하고 실제로 실험도 다양한 백본으로 실험합니다. 물론 같은 모델을 쓰긴 쓰는데, weight는 공유하지 않습니다.
C-Net module
C-Net이 common feature를 추출한다고 말씀드렸는데요. 이 common feature는 모든 클래스에서 공유되는 feature입니다. 그럼 이 모듈을 어떻게 학습하냐… 바로 GRL을 사용합니다. 어디서 사용하는가 싶어 찾아보니 domain adaptation에서 특정 layer의 gradient의 방향을 반대로 바꾸고 싶다면 이 GRL을 사용한다고 합니다. 이 GRL은 feature extractor F_c의 gradient 학습 방향을 반대로 바꾸어줍니다.
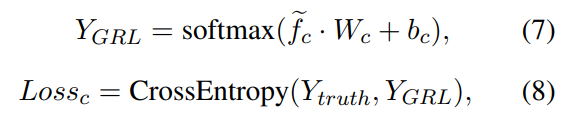
GRL의 출력값이 \tilde{f_c}라고 할 때 위와 같이 학습을 수행합니다. 그림에서 Classifier가 붙어있어서 이것도 분류에 쓰나? 싶었겠지만 실제로는 GRL의 출력값과 GT 값을 비교하면서 common feature를 학습하는데 쓰인다고 합니다.
P-Net module

P-Net은 purified feature를 계산한다고 말씀드렸는데요. 이 “순수한” feature를 계산하기 위해서 orthogonal의 특성을 이용합니다. 기본적으로는 common feature에 직교하는 pure feautre를 만드는데요. 이 과정을 통해서 분류에 필요한 특성만을 보존하고 있는 feature를 만든다고 합니다. (그림에서 보면 traditional feature를 common feature에 투영시키고, 직교시켜서 pure feature를 만듭니다.)
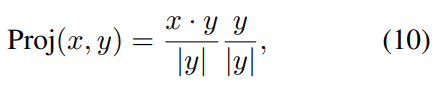
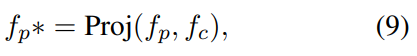
그럼 어떻게 투영시키는지도 알아야겠죠? OPL은 tradition feature f_p를 f_c에 투영합니다. 이 과정을 common feature vector에 대한 제약 조건으로 볼 수 있습니다. (1단계 : traditional feature를 common feature에 투영)
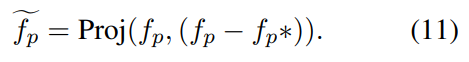
그런 다음에 이 f_p와 f_p*을 이용해서 orthogonal projection을 수행합니다. 앞서서 제약조건으로 볼 수 있다고 했는데요. 이 제약조건 때문에 f_p*는 common information만 포함한 상태입니다. 여기서 orthogonal projection을 수행하면, 논문 저자들이 주장하는대로 common feature의 영향력이 제거되고 purified feature를 얻을 수 있게 됩니다. (2단계 : 투영된 \tilde{f_p}를 common feature에 orthogonal projection해서 pure feature를 만듬)
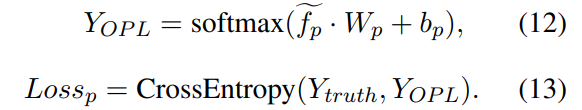
마지막으로 이 OPL도 C-Net에서 본 것과 동일하게 학습합니다. 추가적으로 이 P-Net과 C-Net은 동시에 학습됩니다. 백본은 동일한 모델을 사용해도 옵티마이저는 서로 다른 것을 사용하는데요. P-Net은 Adam을, C-Net은 Moment SGD를 사용합니다.
Experiments
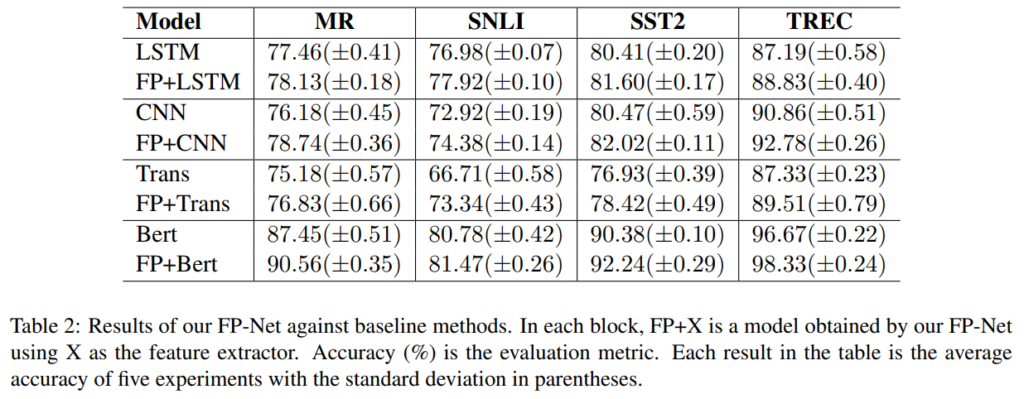
실험에 사용된 데이터셋들은 전부 텍스트 감정 인식 데이터셋입니다. 베이스라인으로 텍스트 감정 인식에서 흔하게 쓰일 법한 기본적인 모델 4가지에 FP-Net을 붙인 것을 실험했습니다. 모든 경우에 FP-Net을 붙였을 경우 성능이 오르는 것을 확인할 수 있는데요. 아예 다른 방법론과의 비교가 없어서 성능이 좋은건지는 모르겠습니다. 사실 이 방법론만 보면 FP-Net에서 제안한 방법론이 정말로 효율적인가도 의문이 드는데요.
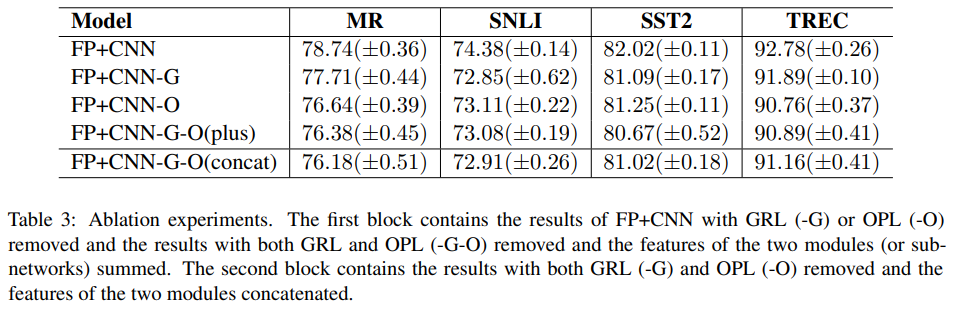
그런 사람들을 위한 추가 실험이 또 있습니다. [표3]은 GRL과 OPL 각각을 제외할 경우 성능이 어떻게 변하는지를 보여줍니다. OPL이 GRL만 단독으로 있었을 때 보다 성능 향상의 폭이 큰 것을 볼 수 있는데요. (-G의 경우가 OPL만 있는 경우) 이러한 결과들을 통해 Common feature를 GRL에서 학습하고, OPL에도 이것이 영향을 미쳐서 보다 차별적인 특징을 학습했다고 볼 수 있을 것 같습니다.
Conclusion
2주 정도는 DOLG에서 아이디어를 얻은 논문들을 추가로 읽어봤는데요. 아예 다른 분야들 같은데도 이렇게 가져와서 적용하는게 참 신기하네요. 좀 더 넓은… 시야를 가져야겠습니다.
traditional feature가 어떤건가요?
common feature의 영향력을 제거하여 보다 특징적인 semantic한 정보를 가진 feature라고는 하는데, 그냥 일반적인 CNN feature라고 봐도 좋을 것 같습니다. 여기서는 그냥 이름을 그렇게 부르는 것 같습니다.