
이번에 제가 소개할 논문은 데이터셋 논문으로 센서구성을 위와 같이 구성하였습니다. 그림을 보시면 아시다시피, RGB스테레오, Event 스테레오, GPS, LiDAR 센서를 기반으로 구성한 센서팩을 차량위에 탑재한 것을 볼 수 있습니다.
제가 해당 논문을 읽게된 이유는 이벤트카메라를 이용하여 센서팩을 구성하고, 데이터셋을 취득한 논문에 대해 호기심이 생겼기 때문입니다. 사실 단순한 지적호기심도 있지만, 가동원전 과제에 이벤트카메라 사용가능성에 대한 검토를 하고자하는 목적이기도 합니다.
이벤트 카메라는 세미나에서 김태주연구원이 여러번 소개하여 아마도 다들 컨셉적인면은 익숙할거라고 생각이 됩니다. 간략하게 말씀드리자면, 이벤트카메라에서는 이벤트가 발생할 때만을 캡쳐합니다. 즉, 빛의변화가 감지될때를 이벤트로 감지하며, 이러한 빛의 변화만을 센싱합니다. 예를들어 static한 scene에서 이벤트카메라는 아무런 변화도 감지하지 못하며, dynamic한 moving objects들이나 조도변화가 생기는 경우만을 감지합니다.
좀 더 구체적으로, 논문에서 이야기하는 이벤트카메라의 장점을 정리하여 말씀드리자면, 이벤트카메라는 아래와 같은 장점들이 존재합니다.
- High temporal resolution (microseconds)
- High dynamic range
- Less motion blur
- Sub-millisecond latency
그리고 이러한 장점들이 자율주행에서 매우 중요하다고 주장합니다.
아래에는 논문에서 제시하는 예시사진들을 가지고왔습니다.

위의 그림은 이벤트 카메라의 장점을 보여주는 예시그림입니다. 왼쪽은 event 카메라를 이용하여 취득한 영상이고, 오른쪽은 같은 장면에서 RGB영상입니다. 터널을 통과하거나 밤중 주행환경에서 illumination이 확보가 잘 안되었을때에도 이벤트카메라를 사용하면 사물의 물체정보를 어느정도 잘 감지하는 것을 볼 수 있습니다.
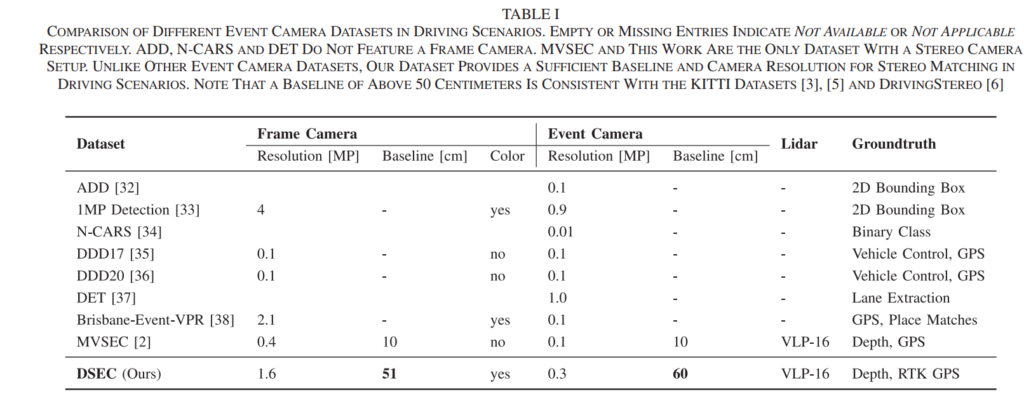
그렇다면 기존에는 이벤트카메라를 이용하여 센서팩을 구성하고, 데이터셋을 취득한 논문들은 없었을까요? 저자에 의하면 위의 Table I과 같이 기존 이벤트카메라 기반의 데이터셋에는 Driving 환경에서 이벤트카메라 및 RGB카메라를 각각 스테레오로 구성한 경우는 거의없다고 합니다. 유일하게 존재하는 비슷한 방법론인 MVSEC에서는 저자가 제안하는 방법론처럼 스테레오 RGB와 스테레오 이벤트카메라를 사용하기는 합니다. 그러나, 해당 방법론은 Resolution이 저자가 제안하는 셋업에 비하여 훨씬 낮다는 단점이 있습니다. 이와 더불어, 카메라사이의 간격인 baseline도 10cm로 작으며, baseline이 작으면 스테레오 셋업에서 disparity 및 depth의 오차가 커진다는 단점이 존재한다고 합니다. 그래서 적절한 baseline을 설정하는 것이 중요한데, 저자는 이미 학자들 사이에서 인정받은 KITTI 데이터셋과 같은 50~60 cm의 baseline을 RGB-스테레오 및 이벤트-스테레오에 각각에 사용하였다고 합니다.
위는 전체적인 하드웨어 스펙입니다. 혹시라도 참고하시라고 가지고 왔습니다.
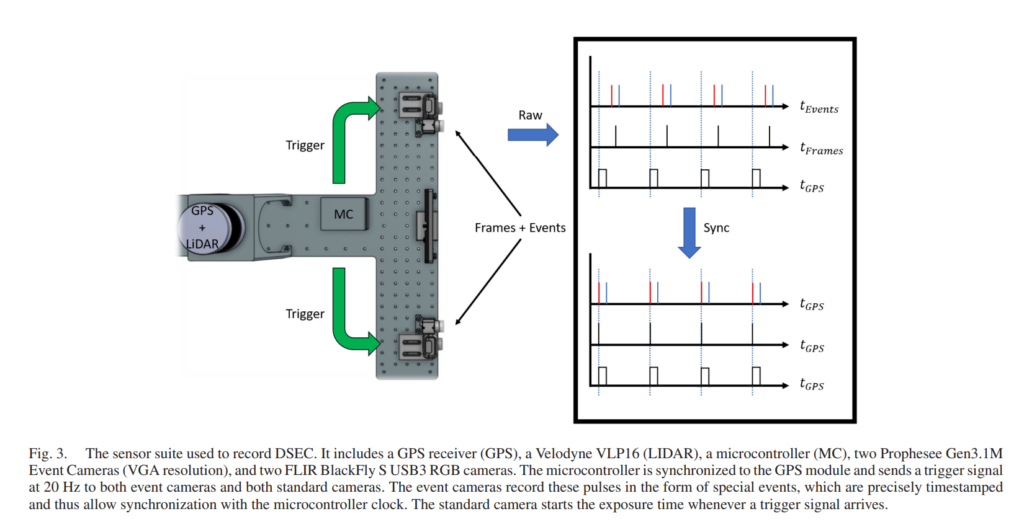
본격적으로 센서를 어떻게 구성하고, 데이터셋을 어떠한 과정으로 취득하였나에 대해서 설명드리겠습니다.
먼저, Fig. 3과 같이 저자는 셋업을 구성하였습니다. 이벤트카메라와 RGB카메라 사이의 간격은 최대하 좁게하여 오차를 줄였고, 스테레오 셋업인 RGB-RGB, Event-Event에서의 각각의 baseline은 KITTI 데이터셋과 비슷한 수준인 51cm, 60cm으로 설정하였습니다.
GPS와 LiDAR센서도 사용하였으며, 마이크로컨트롤러(MC)를 달아서 Trigge 신호를 전달하는 용도로 사용하였습니다.
그렇다면 해당 데이터셋에서는 멀티모달 센서들간의 동기화 및 캘리브레이션 작업은 어떤식으로 수행을 하였을까요?
센서동기화
동기화는 하드웨어레벨에서 purse per second (PPS) 형태의 트리거신호를 전달하는 방식으로 진행됩니다. 구체적으로 PPS는 우선 GPS 리시버에서 나오며, 이후 MC와 LiDAR 센서로 전달됩니다. 그리고 MC에서는 PPS를 받음과 동시에 매초마다 20 pulses의 신호를 RGB카메라와 Event 카메라에 전달합니다.
논문에서 길게 설명하지만, 핵심만 이야기하자면 위의 내용과 같으며, 이는 Fig. 3.에 그림으로 잘 설명이 되어있습니다. 결과론적으로 모든센서들은 GPS 리시버에서 나온 트리거신호를 중심으로 20Hz로 동기화가 됩니다.
카메라 캘리브레이션

일반적인 멀티모달센서간의 캘리브레이션과 동일하게, 해당 연구에서도 체커보드판을 이용하여 멀티모달 센서간의 캘리브레이션을 수행하였습니다. 기존 방법들과 마찬가지로, 동일한 체커보드판을 동시에 촬영하여, 코너점들을 마킹하는 방식으로 캘리브레이션을 수행하였으며, Kalibr라고 불리우는 툴을 사용하였다고 합니다.
다만, 센서 구성에 이벤트카메라 영상이 포함되었기 때문에 일반적인 카메라캘리브레이션과 조금 특별한점이 있습니다. Fig. 4.을 보시면 왼쪽은 Event 카메라로 취득한 영상데이터이며, 오른쪽은 해당 영상데이터를 이용하여 체커보드판을 reconstruction한 모습입니다. 그림을 보시면 아시다시피 이벤트카메라는 코너점들이 명확하게 표기가 되지 않습니다. 따라서, reconstructed된 이미지를 이용하여 캘리브레이션 하였다고 합니다.
다만, 개인적으로 어떻게 이벤트카메라에 checkerboard의 라인들이 검출이 되었는지 궁금하네요… 논문에서 언급되는거 같진 않습니다.
카메라-라이다 캘리브레이션
카메라-라이다 캘리브레이션은 CAD모델을 이용하여 initial estimate를 구한 상태에서 ICP알고리즘을 통해 refinement하는 방식으로 진행됩니다. 이는 6DoF Pose Estimation task에서 6D Pose를 라벨링하는 방식과 비슷합니다. 좀 더 자세한 과정은 아래와 같습니다.
• Compute a local pointcloud from the Lidar measurements.
• Compute the 3D pointcloud resulting from running the SGM [42] algorithm on the rectified image pair.
• Align the stereo and Lidar pointcloud with a modified version of point-to-plane ICP [43] that only optimizes for rotation. We do not require ICP to optimize for translation because the translation can be accurately retrieved from
the CAD model.
Ground Truth Depth Generation

앞에서 캘리브레이션 과정을 통해서 구한 intrinsic, extrinsic 파라미터와 LiDAR센서로 부터 얻은 포인트정보는 GT depth map을 구하는데 사용됩니다. 이때, Single 라이다센서는 sparse하기 때문에 여러번 accumulate 해서 사용하며, 위의 Fig. 5와 같습니다.
그 과정을 설명드리자면, 우선 포인트클라우드 데이터를 각각의 scene으로부터 뽑아서 acculmulate 시켜 사용합니다. 그리고 그러한 포인트클라우드 정보를 그대로 사용하는 것이 아닌 스테레오 카메라로 부터 뽑은 disparity map을 이용하여 추가적인 refinement합니다. 이렇게 filtering하는 방식은 KITTI depth와 DrivingStereo dataset에서도 사용하는 방법이라고 합니다. 좀 더 구체적으로 저자는 해당 과정을 아래와 같이 정리하여 설명합니다.
• Accumulate a local Lidar pointcloud for each view.
• Generate a disparity map from the rectified image pair using SGM [42] which is not affected by moving objects.
• The lidar pointcloud is projected into the camera frame. Only the 3D points are retained that correspond to a
disparity value close enough to the disparity at that pixel estimated by SGM. We remove 3D points further away
than 50 meters to maintain an accurately filtered map.
• The filtered Lidar pointcloud is subsequently projected into the left event and frame cameras to generate the
groundtruth disparity maps at 10 Hz.

Fig. 6은 예시사진입니다. 주석이 좀 헷갈리게 작성되어있는거 같은데, 1열과 2열이 1쌍이고, 3열과 4열이 한쌍으로 각각 이벤트카메라로 취득한 영상과 RGB영상에 corresponding하는 disparity map들 입니다.
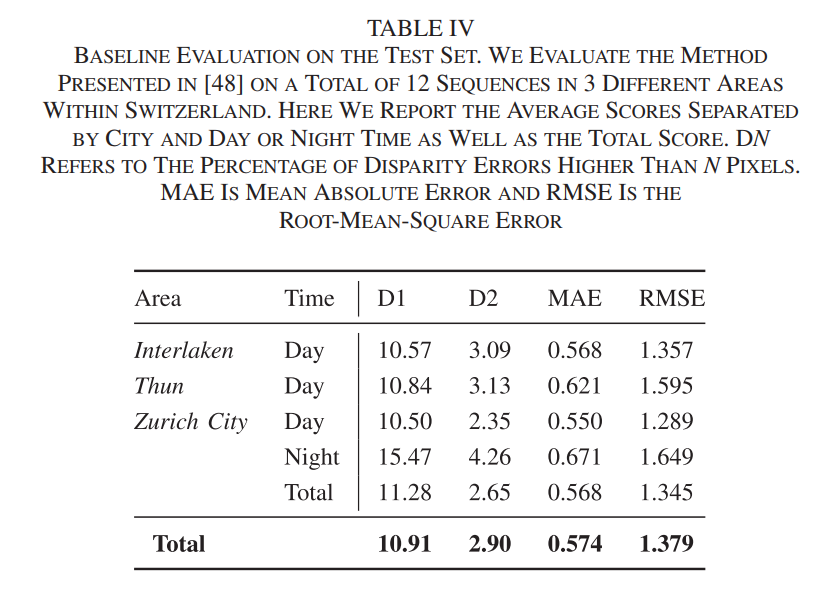
the voxel grid representation 베이스라인 모델을 이용하여 해당 데이터셋을 test셋에서 평가해보았을때 위와같이 나왔다고 합니다.
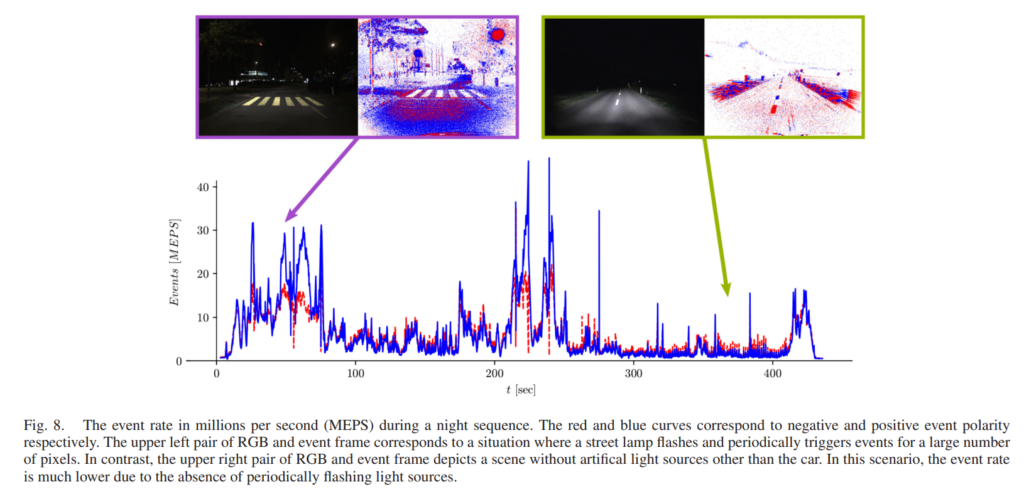
위의 그림은 이벤트발생과 상응하는 예시 사진들인데요. 개인적으로 event가 엄청나게 적게 발생할때는 event camera 영상을 어떤식으로 처리해야할지 궁금하네요.
이상 리뷰마치겠습니다.
좋은 논문 리뷰 감사합니다.
어떻게 하다보니 같은 논문을 봤네요 ㅋㅋㅋㅋㅋㅋ
몇가지 궁금한 점이 있어 질문 드리게습니다.
1. 이번에 처음으로 이벤트 카메라 관련 논문을 보신걸로 알고 있습니다. 어쩌다가 해당 논문을 리뷰하게 되었나요?
2. 실내에서 이벤트 카메라를 사용해도 좋을까요?
3. 6D pose dataset 제작시, 이벤트 카메라를 추가하는 것도 고려 중에 있습니다. 이에 대해서는 어떻게 생각하시나요?
++ 이벤트 카메라에 사용되는 캘브판은 반복해서 반짝이는 LED를 이용한다고 합니다. 그리고 Fig 8에서 다뤄지는 부분이 굉장히 흥미로운 부분인 것 같습니다. 밤에는 노이즈가 강해지고 특히 반복적으로 반짝이는 신호등이 있는 경우 순간적으로 많은 이벤트가 발생한다고 합니다. 이런 케이스가 아웃라이어로 대두될 가능성이 높기 때문에 추후 데이터 수집에 있어 고려해야할 부분(오히려 추가하거나 배제하거나)이라고 생각합니다.
1. Event Camera에 대한 지식이없어서 관련논문 한편 읽어볼까? 하는 마음에 찾아서 읽게되었습니다.
2. 사용한적이 없어서 잘 모르겠습니다. 다만, 개인적인 생각으론 driving scene처럼 dynamic한 경우에만 효과적이지 않을까 싶습니다.
3. 개인적으론 회의적입니다. grasping task자체가 보통은 robot이 움직이지 않는상태에서 정지된 물체를 잡기 때문에 event camera에 큰 변화가 있을지 싶네요.