
저는 이번에 다크데이터 과제를 위해 읽어본 논문입니다. test time에서 모델을 업데이트한다는 컨셉으로, 최근 CVPR 2022에서도 이와 비슷한 컨셉으로 self-supervised learning 방법론이 게재되어 다음 리뷰는 그 논문이 될 것 같습니다.
Test-Time Training with Self-Supervision for Generalization under Distribution Shifts

Introduction
본 논문에서는 예측 모델의 성능을 개선하기 위해 test-time training(adaption)이라는 방식을 제안합니다. test-time training이란 test의 경우 레이블이 없기 때문에, 이를 self-supervised learning으로 전환하여 prediction하기 전에 모델의 파라미터를 업데이트 하는 방식입니다.
왜 이런 방식을 제안했을까요? 바로 domain adaptation 연구가 등장한 배경과 비슷하다고 생각하시면 좋을 것 같습니다. 지도 학습 기반의 방법론은 아무래도 테스트 데이터와 다른 분포를 보인다면 성능 차이가 많이 나기도 합니다. 따라서 학습과 평가 데이터 사이의 도메인 갭을 줄이기 위해서 domain adaptation 연구가 등장하였습니다. 그러나 본 논문에서는 test 하는 동안 모델을 업데이트 시켜 일반화를 할 수 있는 새로운 관점인 test 동안에서의 업데이트 방식을 제안합니다.
이 방법을 제안한 motivation은 self-supervised learning에서 시작되었습니다. 테스트에서는 레이블이 없으니, 이 테스트 동안에서 모델을 업데이트하는 것은 어려운 일이었습니다. 그러나 이 문제를 self-supervised learning으로 전환하여 테스트 샘플 x에서 pretext task라는 보조적인 학습법을 추가하여 모델을 학습합니다. 여기서는 이미지를 회전시키는 augmentation을 통해 모델의 회전 각도를 맞추는 것을 pretext task로 설정하였습니다.
(pretext task 에 대해서는 지난 리뷰에서 자세히 다루었으니 궁금하신 분들은 해당 리뷰를 참고 바랍니다.)
따라서 본 논문을 정리하자면 다음과 같습니다; 지도학습 기반의 방법론은 다른 데이터셋에서도 잘 동작하는 일반화에는 어렵다는 한계가 있기 때문에, test-time에서 모델을 test dataset에 대해 업데이트를 함으로써 train과 test 데이터 사이의 갭을 극복하고자 하였습니다. 그러나 test 데이터셋에는 라벨이 없어 기존 지도학습 학습법으로는 업데이트하는 데에 문제가 있으니, pretext task 로 전환하여 업데이트하는 self-learning 기반의 방법론을 제안하였습니다.
Method
앞서 pretext task를 언급하였는데요, 본 논문에서 모델을 학습하는 방식을 main task과 self-supervised auxiliary task로 나누었습니다. 여기서 main task는 claasification이라면 classification, object detection 이라면 object detection이 됩니다.
그렇다면 self-supervised auxiliary task는 무엇일까요? 기존 지도학습 기반의 방법론에 대해 생각해봅시다. test-time 에서 모델을 업데이트하기 위해서는 loss를 구해내야하는데, 그러기 위해서는 당연히 라벨이 필요합니다. 그러나 test 데이터는 라벨이 없으니, 이를 극복하기 위해 self-learning 기반의 보조 태스크가 사용됩니다. (이게 바로 제가 intro에서 언급한 pretext task 입니다. pretext task가 흔하게 사용되는 용어이기도 합니다)
가령 이미지 x에 대해 0, 90, 180 그리고 270로 회전시킨 augmentation을 만들면 몇도를 회전했는지에 대해 알고 있으니 모델을 회전 각도를 맞추는 문제로 전환하여 이미지의 표현력을 학습하는 것이죠. 이렇게되면 test-time 에서도 정답값을 만들어 loss를 계산해낼 수 있게됩니다.
따라서 본 논문에서는 이 auxiliary task를 함께 사용하여 일부 파라미터를 공유하는 Y구조의 모델을 제안하게 됩니다. 아래 \theta_e가 Y-structure 중 main과 self task가 공유하는 파라미터이고, \theta_s는 self-supervised task 그리고 \theta_m은 main task 학습 시 업데이트 되는 파라미터가 됩니다.
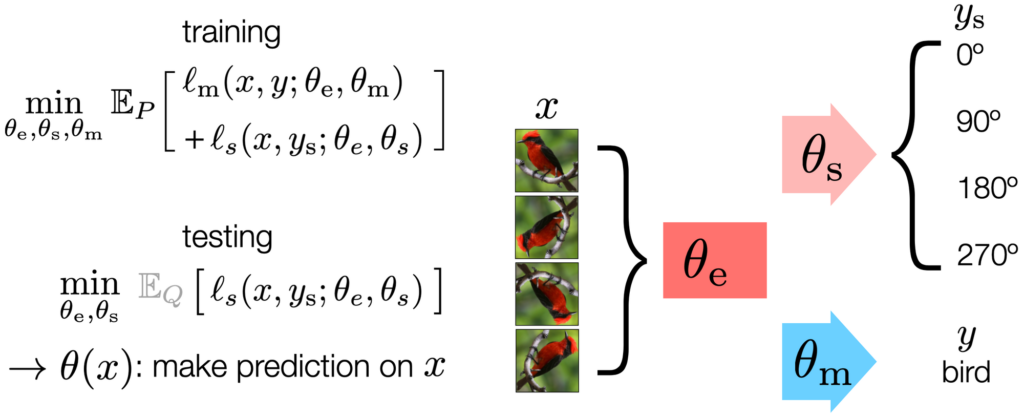
모델의 구조에서도 볼 수 있듯, 학습은 multi-task learning으로 진행됩니다. 모델은 학습 데이터의 분포인 P로부터 main과 self-supervised learning 이 동시에 학습되는 것이죠. 이를 위해 loss는 아래 equation 으로 수정하였다고 합니다.
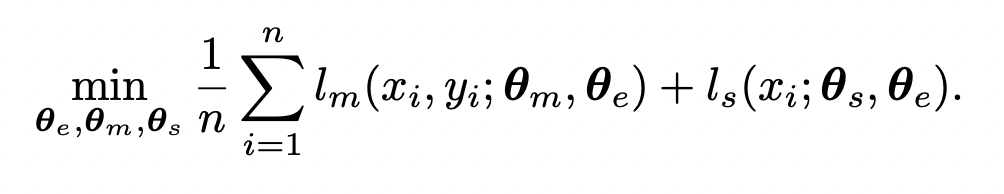
참고) 기존 standard test error를 변형하여 본 논문에서 제안하는 test 에러는 다음과 같습니다. Test-Time Training에서는 expected loss 를 수정하여 레이블은 보지 않고 파라미터 θ가 테스트 입력 x에 의존하게 됩니다.
- θ : model parameters
- l : loss function
- Q : test distribution
- \mathbb{E}_Q: the standard test error 로 Q에 의해 계산
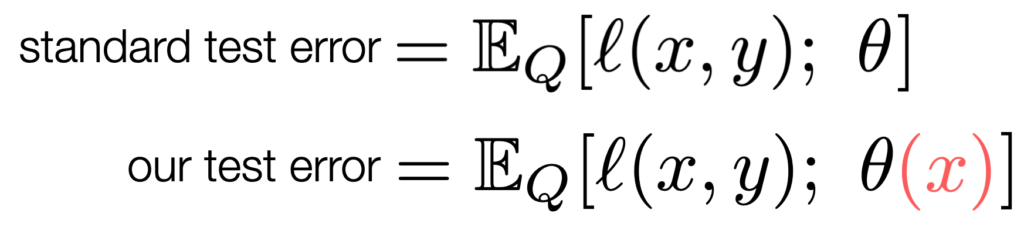
즉, test-time training 에서는 x에 대한 auxiliary task loss를 최소화하여 공유하는 파라미터인 \theta_e를 fine-tune 하게 됩니다. 추가로 data augmentation 역시 train 도중 수행한 것과 동일한 transformation을 사용하였다고 합니다.
Online Test-Time Training
이제 본 논문의 메인이 되는 부분인데요, 바로 test 도중에 모델을 업데이트하는 online test-time training에서는 test 로 들어오는 x에 대해 매번 업데이트하지 않습니다. test sample x_t에 대해서 \theta는 이전 샘플 x_(t-1)에서 업데이트된 \theta(x_{t-1}) 로 초기화됩니다. 이를 통해 \theta(x_t)는 x_t뿐만 아니라 x_1~x_t-1에서 사용한 분포 정보를 활용할 수 있다는 장점이 있습니다.
Experiments
네트워크로는 ResNets 을 사용하였으며, 데이터셋은 CIFAR-10(26-layer)과 ImageNet(18-layer)을 사용합니다. 실험은 classification과 object detection에 대해 수행되었습니다.
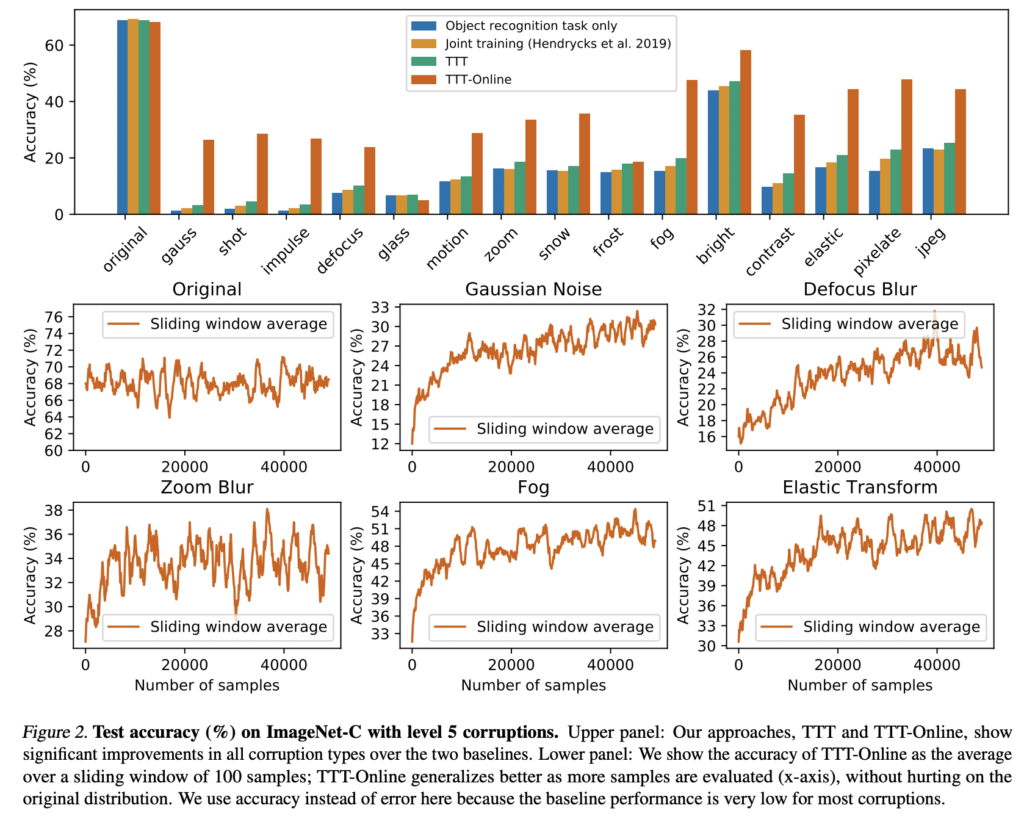
본 논문에서는 Corrupted 이미지를 사용합니다. d아래 ImageNet에 대하여 여러 버전의 corrupted를 시도한 결과를 나타냅니다. 이 왜곡을 각각의 데이터에 수행한 결과를 ImageNet-C 그리고 CIFAR-10-C라고 말합니다.

가장 먼저 classification에 대한 실험입니다. train으로는 원본 데이터를, 그리고 test 로는 ImageNet-C 혹은 CIFAR-10-C를 사용합니다. Online Test-Time Training에서는 전체 테스트 세트를 이미지의 스트림으로 받아들이고, 도착하는 대로 각 이미지를 온라인 방식으로 업데이트하고 테스트하는 방식입니다, 아래 Figure.1이 가장 심각한 corrupted 인 레벨 5에 대한 실험 결과인데요, 모든 corruped 에 대해서 성능이 많이 향상된 것을 볼 수 있었습니다.
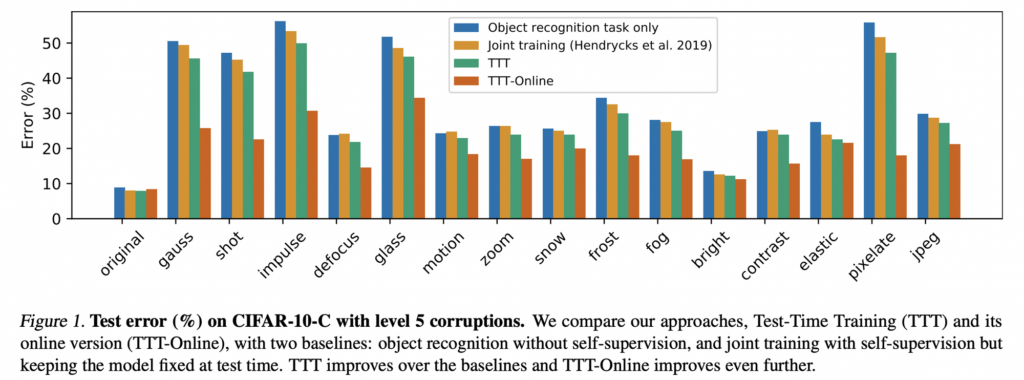
특히 제안하는 방법은 학습을 진행할수록 지속적으로 성능이 향상되었습니다. 아래 Image-Net 에 대한 결과를 확인해보면 알 수 있습니다. 대부분의 corrupted 에서기본적인 성능이 매우 낮기 때문에 여기서는 accuracy 에 대해 리포팅한다고 하였습니다.,.,,,, CIFAR-10과 비슷한 경향을 보이며 특히 Online버전이 크게 향상된 것을 확ㅇ니할 수 있었습니다.
아무래도 본 논문은 test-time training의 근본이 되는 논문이다 보니 이후 내용은 어떻게 이 방법론이 성능 향상을 가져왔는지에 대한 수식적 증명이 많았습니다. 논문을 완벽히 이해하는 데는 어려움이 있었으나 아이디어 자체는 간단하여 이를 어떻게 적용해야할지 (특히 MoCo에 이 방법론을 붙힌 CVPR 2022논문을 보면서) 고민해봐야겠습니다.