본 논문은 Reinforce learning 기반으로 sematic segmentatio을 위한 active learning을 진행하기 위한 방법론 이다. Semantic segmentation은 ground truth를 생성하기 위해 많은 cost가 발생하는 task 중 하나이다. labeling cost를 최소화 하기 위해 어떠한 방식으로 active learning을 진행하였는지 살펴보자.
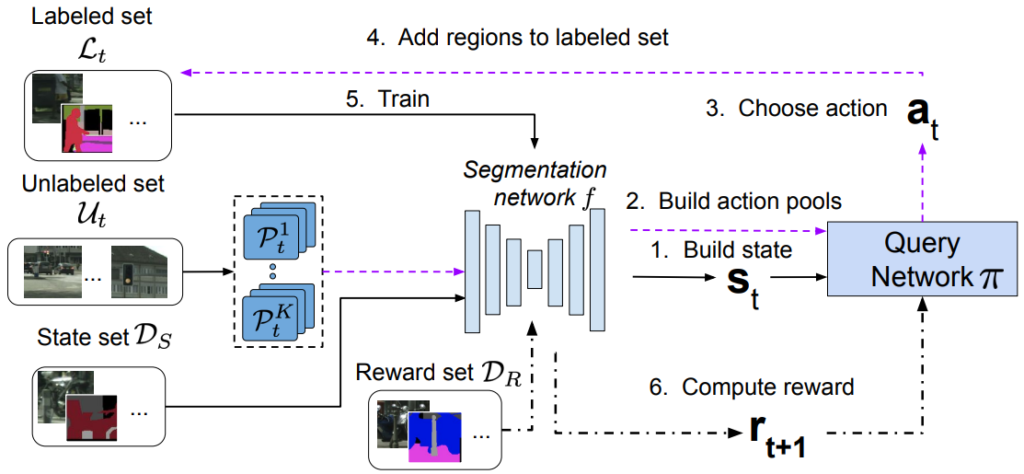
그렇다면 labeling cost를 줄이기 위해 어떻게 segmentation task에 active learning을 적용했을까? 그 예시는 [그림1]과 같다. 데이터 pool에서 small informative image regions을 찾고, 해당 부분의 labeling을 요청하여 labeled pool을 채우는 것이다. 이를 통해 이미지 단위로 가치 있는 이미지를 선정하여 발생하는 정보량의 적은 부분에 대한 labeling 을 줄일 수 있으며 segmentation task의 고질적인 문제인 categries unbalanced 문제도 해결할 수 있다.

이제 간단하게 소개를 마쳤으니 더욱 구체적인 method에 대해 소개하겠습니다. 전체적인 흐름은 [그림2]와 같다. 우선 데이터셋에 대한 명칭부터 정리하면 다음과 같다. 쿼리 네트워크(labeling을 요청할 쿼리를 찾아내는 네트워크)인 π를 학습시키기 위해 labeled data는 4가지(편의상 아래첨자를 그냥 연이어 씀. DT, DV, DR, DS)로 나누어 진다. DT는 labeled data 전체를 의미하며 다음의 3가지(DV, DR, DS)는 이의 subset 이다. DS는 강화학습에서 MDP(마르코프 결정 과정, Markov Decision Process)의 state를 모델링하기 위해 쓰이며(즉, 초기화 단계에 쓰이며), π는 DV에 의해 evaluated 된다. 또한 DR은 segmentation network인 f를 이에 대해 평가하여 reward signal을 얻기 위해 사용한다.
데이터셋의 정의는 위와 같으며 방법론의 흐름은 아래와 같다. 해당 방법론은 에이전트인 쿼리 네트워크(π)를 학습시키기 위해 e번의 에피소드 학습을 진행한다.
- 먼저, DS를 이용하여 초기 state moeling을 진행한다. (segmentation model(f)을 초기학습하는 것으로 이해하면 된다)
- 다음으로 연산량을 줄이기 위해 unlabeled pool(UT)에서 uniformly from으로 샘플링하여 K개의 pools PKt(t는 에피소드 반복 횟수)를 생성한다. 각 pool(P1t, P2t … PKt)에 대해 π를 통해 sub-action representation인 at(t는 에피소드 반복횟수)를 생성한다.
- 각 sub-action인 at마다 하나의 region인 xt를 선정한다. 즉 하나의 pool 당 하나의 region을 선택하게 되므로 총 K개의 영역이 선택 된다.
- 선택된 영역은 labeling 되도록 요청되며, 이는 labeled set(L(t+1))에 포함된다. (L(t+1)=Lt+(t에서 선택된K개의 영역))
- 업데이트된 labeled set을 이용하여 segmentation model(f(t+1))을 학습시킨다.
- 이후 agent(π)는 DR에 대한 ft와 f(t+1)의 성능차이를 reward로 받게 된다.
- 위와 같은 학습 과정(에피소드)을 반복하여 π에 대한 강화학습을 진행한다.
- 실험
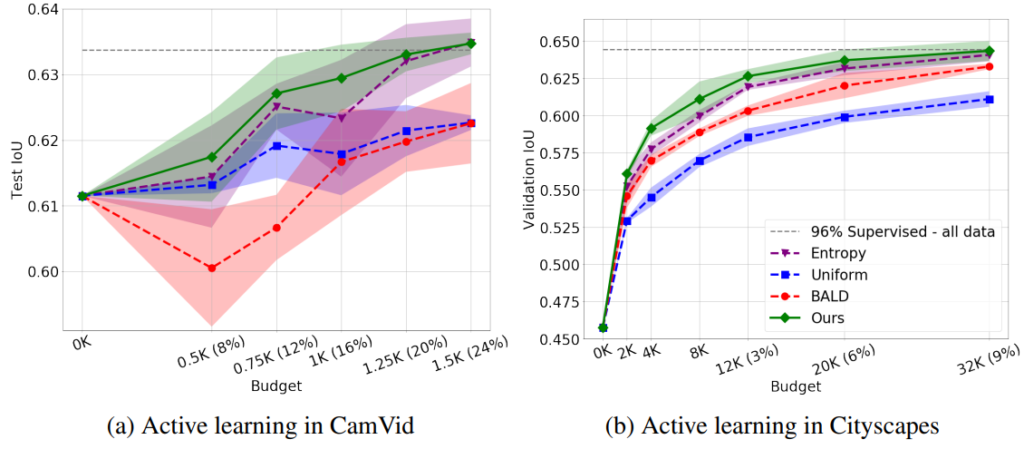
실험은 CamVid, Cityscapes 데이터셋을 기준으로 진행하였으며 이에 대한 실험결과는 아래와 같다. 2020년도에 발표된 해당 논문은 제안하는 방법론(Ours)을 uniform random sampling방식(U, Uniform), uncertainty sampling method(H, Entropy, pixel-wise Shannon entropy), pixel-wise BALD(B, Houlsby 2011, Gal 2017)와 비교하였으며 동일한 labeled data 사용량을 기준으로 비교하였을때 제안하는 방법론의 우월성을 보였다.
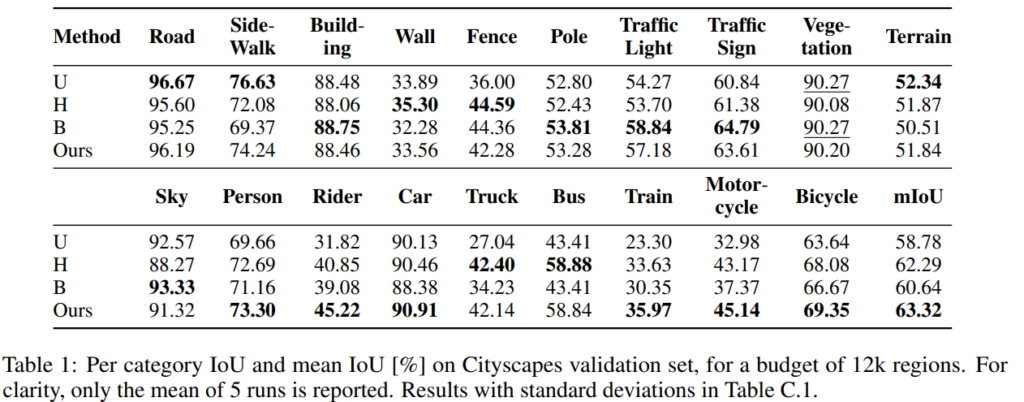
또한 Cityscapes 데이터에 대해 분류별 예측에 대한 정확도를 [표1]에 리포팅 하였으며, 리포팅 된 19개의 분류 중, 6개의 클래스에서 특히 우월성을 보였고 mIOU에서는 63.32로 비교하는 방법론 중 가장 좋은 성능을 보였다.
본 논문은 segmentation task에 active learning을 적용한 논문으로 데이터셋의 labeling 비용을 효율적으로 줄였다. 특히 이미지 단위가 아닌 영역단위로 데이터의 가치판단을 진행하였다는 점이 신선했다.
semantic segmentation 도 다크데이터에서 사용해야하는 건가요?